







原文:RealPython
Python 的“in”和“not in”操作符:检查成员资格
Python 的 in 和 not in 运算符允许您快速确定一个给定值是否是值集合的一部分。这种类型的检查在编程中很常见,在 Python 中通常被称为成员测试。因此,这些算子被称为隶属算子。
在本教程中,您将学习如何:
- 使用
in和not in操作符执行成员测试 - 使用不同数据类型的
in和not in - 与
operator.contains()、一起工作,相当于in操作员的功能 - 在你的自己的班级中为
in和not in提供支持
为了充分利用本教程,您将需要 Python 的基础知识,包括内置数据类型,如列表、元组、范围、字符串、集合和字典。您还需要了解 Python 生成器、综合和类。
源代码: 点击这里下载免费的源代码,你将使用它们用in和not in在 Python 中执行成员测试。
Python 成员测试入门
有时,您需要找出一个值是否存在于一个值集合中。换句话说,您需要检查给定的值是否是值集合的成员。这种检查通常被称为会员资格测试。
可以说,执行这种检查的自然方式是迭代这些值,并将它们与目标值进行比较。你可以借助一个 for循环和一个条件语句来完成这个任务。
考虑下面的is_member()函数:
>>> def is_member(value, iterable):
... for item in iterable:
... if value is item or value == item:
... return True
... return False
...
这个函数有两个参数,目标值value和一组值,通常称为iterable。循环在iterable上迭代,同时条件语句检查目标value是否等于当前值。注意,该条件使用is检查对象标识,或者使用相等运算符(==)检查值相等。这些测试略有不同,但互为补充。
如果条件为真,那么函数返回 True,退出循环。这种提前返回短路的循环操作。如果循环结束而没有任何匹配,那么函数返回False:
>>> is_member(5, [2, 3, 5, 9, 7])
True
>>> is_member(8, [2, 3, 5, 9, 7])
False
对is_member()的第一次调用返回True,因为目标值5是当前列表[2, 3, 5, 9, 7]的成员。对该函数的第二次调用返回False,因为8不在输入值列表中。
像上面这样的成员资格测试在编程中是如此普遍和有用,以至于 Python 有专门的操作符来执行这些类型的检查。您可以通过下表了解隶属运算符:
| 操作员 | 描述 | 句法 |
|---|---|---|
T2in | 如果目标值是值集合中的,则返回True。否则返回False。 | value in collection |
T2not in | 如果目标值是给定值集合中的而不是,则返回True。否则返回False。 | value not in collection |
与布尔运算符一样,Python 通过使用普通的英语单词而不是潜在的混淆符号作为运算符来提高可读性。
**注意:**当in 关键字在for循环语法中作为成员操作符时,不要将它与in关键字混淆。它们有完全不同的含义。in操作符检查一个值是否在一个值集合中,而for循环中的in关键字表示您想要从中提取的 iterable。
和其他很多运算符一样,in和not in都是二元运算符。这意味着你可以通过连接两个操作数来创建表达式。在这种情况下,它们是:
- **左操作数:**要在值集合中查找的目标值
- **右操作数:**可以找到目标值的值的集合
成员资格测试的语法如下所示:
value in collection
value not in collection
在这些表达式中,value可以是任何 Python 对象。同时,collection可以是能够保存值集合的任何数据类型,包括列表、元组、字符串、集合和字典。它也可以是实现.__contains__()方法的类,或者是明确支持成员测试或迭代的用户定义的类。
如果您正确使用了in和not in操作符,那么您用它们构建的表达式将总是计算出一个布尔值。换句话说,这些表达式将总是返回True或False。另一方面,如果你试图在不支持成员测试的东西中找到一个值,那么你将得到一个 TypeError 。稍后,您将了解更多关于支持成员测试的 Python 数据类型。
因为成员运算符总是计算为布尔值,Python 将它们视为布尔运算符,就像 and 、 or 和 not 运算符一样。
现在您已经知道了什么是成员资格操作符,是时候学习它们如何工作的基础知识了。
Python 的in操作符
为了更好地理解in操作符,您将从编写一些小的演示示例开始,这些示例确定给定值是否在列表中:
>>> 5 in [2, 3, 5, 9, 7]
True
>>> 8 in [2, 3, 5, 9, 7]
False
第一个表达式返回True,因为5出现在数字列表中。第二个表达式返回False,因为8不在列表中。
根据in操作符文档,类似value in collection的表达式相当于下面的代码:
any(value is item or value == item for item in collection)
包装在对 any() 的调用中的生成器表达式构建了一个布尔值列表,该列表是通过检查目标value是否具有相同的身份或者是否等于collection中的当前item而得到的。对any()的调用检查是否有任何一个结果布尔值为True,在这种情况下,函数返回True。如果所有的值都是False,那么any()返回False。
Python 的not in操作符
not in成员操作符做的正好相反。使用这个操作符,您可以检查给定值是否不在值集合中:
>>> 5 not in [2, 3, 5, 9, 7]
False
>>> 8 not in [2, 3, 5, 9, 7]
True
在第一个例子中,您得到了False,因为5在[2, 3, 5, 9, 7]中。在第二个例子中,您得到了True,因为8不在值列表中。这种消极的逻辑看起来像绕口令。为了避免混淆,请记住您正在尝试确定值是否是给定值集合的而不是部分。
注意:not value in collection构造与value not in collection构造的工作原理相同。然而,前一种结构更难阅读。因此,你应该使用not in作为单个运算符,而不是使用not来否定in的结果。
通过对成员操作符如何工作的快速概述,您已经准备好进入下一个层次,学习in和not in如何处理不同的内置数据类型。
使用不同 Python 类型的in和not in
所有内置的序列——比如列表、元组、 range 对象和字符串——都支持使用in和not in操作符进行成员测试。像集合和字典这样的集合也支持这些测试。默认情况下,字典上的成员操作检查字典是否有给定的键。但是,字典也有显式的方法,允许您对键、值和键值对使用成员操作符。
在接下来的几节中,您将了解对不同的内置数据类型使用in和not in的一些特殊之处。您将从列表、元组和range对象开始。
列表、元组和范围
到目前为止,您已经编写了一些使用in和not in操作符来确定一个给定值是否存在于一个现有的值列表中的例子。对于这些例子,你已经明确地使用了list对象。因此,您已经熟悉了成员资格测试如何处理列表。
对于元组,成员运算符的工作方式与列表相同:
>>> 5 in (2, 3, 5, 9, 7)
True
>>> 5 not in (2, 3, 5, 9, 7)
False
这里没有惊喜。这两个例子的工作方式都与以列表为中心的例子相同。在第一个例子中,in操作符返回True,因为目标值5在元组中。在第二个示例中,not in返回相反的结果。
对于列表和元组,成员操作符使用一个搜索算法,该算法迭代底层集合中的项目。因此,随着 iterable 变长,搜索时间也成正比增加。使用大 O 符号,你会说对这些数据类型的成员操作具有的时间复杂度为 O(n) 。
如果您对range对象使用in和not in操作符,那么您会得到类似的结果:
>>> 5 in range(10)
True
>>> 5 not in range(10)
False
>>> 5 in range(0, 10, 2)
False
>>> 5 not in range(0, 10, 2)
True
当涉及到range对象时,使用成员测试乍一看似乎是不必要的。大多数情况下,您会事先知道结果范围内的值。但是,如果您使用的range()带有在运行时确定的偏移量呢?
注意:创建range对象时,最多可以传递三个参数给range()。这些论点是start、stop和step。它们定义了开始范围的次数,范围必须停止生成值的次数,以及生成值之间的步长。这三个参数通常被称为偏移。
考虑以下示例,这些示例使用随机数来确定运行时的偏移量:
>>> from random import randint
>>> 50 in range(0, 100, randint(1, 10))
False
>>> 50 in range(0, 100, randint(1, 10))
False
>>> 50 in range(0, 100, randint(1, 10))
True
>>> 50 in range(0, 100, randint(1, 10))
True
在您的机器上,您可能会得到不同的结果,因为您正在使用随机范围偏移。在这些具体示例中,step是唯一变化的偏移量。在实际代码中,start和stop偏移量也可以有不同的值。
对于range对象,成员测试背后的算法使用表达式(value - start) % step) == 0计算给定值的存在,这取决于用来创建当前范围的偏移量。这使得成员测试在操作range对象时非常有效。在这种情况下,你会说他们的时间复杂度是 O(1) 。
**注意:**列表、元组和range对象有一个.index()方法,返回给定值在底层序列中第一次出现的索引。此方法对于在序列中定位值非常有用。
有些人可能认为他们可以使用方法来确定一个值是否在一个序列中。但是,如果值不在序列中,那么.index()会引发一个 ValueError :
>>> (2, 3, 5, 9, 7).index(8)
Traceback (most recent call last):
...
ValueError: tuple.index(x): x not in tuple
您可能不想通过引发异常来判断一个值是否在一个序列中,因此您应该使用成员操作符而不是.index()来达到这个目的。
请记住,成员测试中的目标值可以是任何类型。测试将检查该值是否在目标集合中。例如,假设您有一个假想的应用程序,其中用户使用用户名和密码进行身份验证。你可以有这样的东西:
# users.py
username = input("Username: ")
password = input("Password: ")
users = [("john", "secret"), ("jane", "secret"), ("linda", "secret")]
if (username, password) in users:
print(f"Hi {username}, you're logged in!")
else:
print("Wrong username or password")
这是一个幼稚的例子。不太可能有人会这样处理他们的用户和密码。但是该示例显示目标值可以是任何数据类型。在这种情况下,您使用一个字符串元组来表示给定用户的用户名和密码。
下面是代码在实践中的工作方式:
$ python users.py
Username: john
Password: secret
Hi john, you're logged in!
$ python users.py
Username: tina
Password: secret
Wrong username or password
在第一个例子中,用户名和密码是正确的,因为它们在users列表中。在第二个示例中,用户名不属于任何注册用户,因此身份验证失败。
在这些例子中,重要的是要注意数据在登录元组中的存储顺序是至关重要的,因为在元组比较中像("john", "secret")这样的东西不等于("secret", "john"),即使它们有相同的条目。
在本节中,您已经探索了一些示例,这些示例展示了带有常见 Python 内置序列的成员运算符的核心行为。然而,还有一个内置序列。是的,弦乐!在下一节中,您将了解在 Python 中成员运算符如何处理这种数据类型。
字符串
Python 字符串是每个 Python 开发者工具箱中的基本工具。像元组、列表和范围一样,字符串也是序列,因为它们的项或字符是顺序存储在内存中的。
当需要判断目标字符串中是否存在给定的字符时,可以对字符串使用in和not in操作符。例如,假设您使用字符串来设置和管理给定资源的用户权限:
>>> class User:
... def __init__(self, username, permissions):
... self.username = username
... self.permissions = permissions
...
>>> admin = User("admin", "wrx")
>>> john = User("john", "rx")
>>> def has_permission(user, permission):
... return permission in user.permissions
...
>>> has_permission(admin, "w")
True
>>> has_permission(john, "w")
False
User类有两个参数,一个用户名和一组权限。为了提供权限,您使用一个字符串,其中w表示用户拥有写权限,r表示用户拥有读权限,x表示执行权限。注意,这些字母与您在 Unix 风格的文件系统权限中找到的字母相同。
has_permission()中的成员测试检查当前user是否有给定的permission,相应地返回True或False。为此,in操作符搜索权限字符串来查找单个字符。在这个例子中,您想知道用户是否有写权限。
但是,您的权限系统有一个隐藏的问题。如果用空字符串调用函数会发生什么?这是你的答案:
>>> has_permission(john, "")
True
因为空字符串总是被认为是任何其他字符串的子字符串,所以类似于"" in user.permissions的表达式将返回True。根据谁有权访问您的用户权限,这种成员资格测试行为可能意味着您的系统存在安全漏洞。
您还可以使用成员运算符来确定一个字符串是否包含一个子字符串:
>>> greeting = "Hi, welcome to Real Python!"
>>> "Hi" in greeting
True
>>> "Hi" not in greeting
False
>>> "Hello" in greeting
False
>>> "Hello" not in greeting
True
对于字符串数据类型,如果substring是string的一部分,类似于substring in string的表达式就是True。否则,表情就是False。
**注意:**与列表、元组和range对象等其他序列不同,字符串提供了一个.find()方法,您可以在现有字符串中搜索给定的子字符串时使用这个方法。
例如,您可以这样做:
>>> greeting.find("Python")
20
>>> greeting.find("Hello")
-1
如果子串存在于底层字符串中,那么.find()返回子串在字符串中开始的索引。如果目标字符串不包含子字符串,那么结果是得到-1。因此,像string.find(substring) >= 0这样的表达式相当于一个substring in string测试。
然而,成员测试可读性更强,也更明确,这使得它在这种情况下更可取。
在字符串上使用成员资格测试时要记住的重要一点是,字符串比较是区分大小写的:
>>> "PYTHON" in greeting
False
这个成员测试返回False,因为字符串比较是区分大小写的,大写的"PYTHON"在greeting中不存在。要解决这种区分大小写的问题,您可以使用 .upper() 或 .lower() 方法来规范化所有字符串:
>>> "PYTHON".lower() in greeting.lower()
True
在这个例子中,您使用.lower()将目标子字符串和原始字符串转换成小写字母。这种转换在隐式字符串比较中不区分大小写。
发电机
生成器函数和生成器表达式创建内存高效的迭代器,称为生成器迭代器。为了提高内存效率,这些迭代器按需生成条目,而不需要在内存中保存完整的值序列。
实际上,生成器函数是一个函数,它在函数体中使用了 yield 语句。例如,假设您需要一个生成器函数,它接受一组数字并返回一个迭代器,该迭代器从原始数据中生成平方值。在这种情况下,您可以这样做:
>>> def squares_of(values):
... for value in values:
... yield value ** 2
...
>>> squares = squares_of([1, 2, 3, 4])
>>> next(squares)
1
>>> next(squares)
4
>>> next(squares)
9
>>> next(squares)
16
>>> next(squares)
Traceback (most recent call last):
...
StopIteration
这个函数返回一个生成器迭代器,根据需要生成平方数。可以使用内置的 next() 函数从迭代器中检索连续值。当生成器迭代器被完全消耗完时,它会引发一个StopIteration异常,告知不再有剩余的值。
您可以在生成器函数上使用成员操作符,如squares_of():
>>> 4 in squares_of([1, 2, 3, 4])
True
>>> 9 in squares_of([1, 2, 3, 4])
True
>>> 5 in squares_of([1, 2, 3, 4])
False
当您将in操作符与生成器迭代器一起使用时,它将按预期工作,如果值出现在迭代器中,则返回True,否则返回False。
然而,在检查生成器的成员资格时,需要注意一些事情。一个生成器迭代器将只产生每个项目一次。如果你消耗了所有的条目,那么迭代器将被耗尽,你将无法再次迭代它。如果您只使用生成器迭代器中的一些项,那么您只能迭代剩余的项。
当您在生成器迭代器上使用in或not in时,操作符将在搜索目标值时消耗它。如果值存在,那么操作符将消耗所有值,直到目标值。其余的值在生成器迭代器中仍然可用:
>>> squares = squares_of([1, 2, 3, 4])
>>> 4 in squares
True
>>> next(squares)
9
>>> next(squares)
16
>>> next(squares)
Traceback (most recent call last):
...
StopIteration
在这个例子中,4在生成器迭代器中,因为它是2的平方。因此,in返回True。当你使用next()从square中检索一个值时,你得到9,它是3的平方。该结果确认您不再能够访问前两个值。您可以继续调用next(),直到当生成器迭代器用尽时,您得到一个StopIteration异常。
同样,如果值不在生成器迭代器中,那么操作符将完全消耗迭代器,您将无法访问它的任何值:
>>> squares = squares_of([1, 2, 3, 4])
>>> 5 in squares
False
>>> next(squares)
Traceback (most recent call last):
...
StopIteration
在这个例子中,in操作符完全消耗了squares,返回了False,因为目标值不在输入数据中。因为生成器迭代器现在已经用完了,所以用squares作为参数调用next()会引发StopIteration。
还可以使用生成器表达式创建生成器迭代器。这些表达式使用与列表理解相同的语法,但是用圆括号(())代替了方括号([])。您可以将in和not in操作符用于生成器表达式的结果:
>>> squares = (value ** 2 for value in [1, 2, 3, 4])
>>> squares
<generator object <genexpr> at 0x1056f20a0>
>>> 4 in squares
True
>>> next(squares)
9
>>> next(squares)
16
>>> next(squares)
Traceback (most recent call last):
...
StopIteration
squares 变量现在保存由生成器表达式产生的迭代器。这个迭代器从输入的数字列表中产生平方值。来自生成器表达式的生成器迭代器与来自生成器函数的生成器迭代器工作方式相同。因此,当您在成员资格测试中使用它们时,同样的规则也适用。
当您在生成器迭代器中使用in和not in操作符时,会出现另一个关键问题。当您使用无限迭代器时,这个问题可能会出现。下面的函数返回一个产生无限整数的迭代器:
>>> def infinite_integers():
... number = 0
... while True:
... yield number
... number += 1
...
>>> integers = infinite_integers()
>>> integers
<generator object infinite_integers at 0x1057e8c80>
>>> next(integers)
0
>>> next(integers)
1
>>> next(integers)
2
>>> next(integers)
3
>>> next(integers)
infinite_integers()函数返回一个生成器迭代器,存储在integers中。这个迭代器按需产生值,但是记住,将会有无限个值。因此,在这个迭代器中使用成员操作符不是一个好主意。为什么?好吧,如果目标值不在生成器迭代器中,那么你会遇到一个无限循环,这将使你的执行挂起。
字典和集合
Python 的成员操作符也可以处理字典和集合。如果您直接在字典上使用in或not in操作符,那么它将检查字典是否有给定的键。你也可以使用 .keys() 的方法来做这个检查,它更明确地表达了你的意图。
您还可以检查给定值或键值对是否在字典中。要做这些检查,可以分别使用 .values() 和 .items() 方法:
>>> likes = {"color": "blue", "fruit": "apple", "pet": "dog"}
>>> "fruit" in likes
True
>>> "hobby" in likes
False
>>> "blue" in likes
False
>>> "fruit" in likes.keys()
True
>>> "hobby" in likes.keys()
False
>>> "blue" in likes.keys()
False
>>> "dog" in likes.values()
True
>>> "drawing" in likes.values()
False
>>> ("color", "blue") in likes.items()
True
>>> ("hobby", "drawing") in likes.items()
False
在这些例子中,您直接在您的likes字典上使用in操作符来检查"fruit"、"hobby"和"blue"键是否在字典中。注意,即使"blue"是likes中的一个值,测试也返回False,因为它只考虑键。
接下来,使用.keys()方法得到相同的结果。在这种情况下,显式的方法名称会让阅读您代码的其他程序员更清楚您的意图。
要检查像"dog"或"drawing"这样的值是否出现在likes中,您可以使用.values()方法,该方法返回一个带有底层字典中的值的视图对象。类似地,要检查一个键值对是否包含在likes中,可以使用.items()。请注意,目标键-值对必须是两项元组,键和值按此顺序排列。
如果使用的是集合,那么成员运算符就像处理列表或元组一样工作:
>>> fruits = {"apple", "banana", "cherry", "orange"}
>>> "banana" in fruits
True
>>> "banana" not in fruits
False
>>> "grape" in fruits
False
>>> "grape" not in fruits
True
这些例子表明,您还可以通过使用成员运算符in和not in来检查一个给定值是否包含在一个集合中。
现在您已经知道了in和not in操作符是如何处理不同的内置数据类型的,是时候通过几个例子将这些操作符付诸实践了。
将 Python 的in和not in操作符付诸实施
用in和not in进行成员测试是编程中非常常见的操作。您将在许多现有的 Python 代码库中找到这类测试,并且也将在您的代码中使用它们。
在接下来的小节中,您将学习如何用成员测试替换基于 or 操作符的布尔表达式。因为成员测试在您的代码中很常见,所以您还将学习如何使这些测试更有效。
替换连锁的or操作符
使用成员测试来用几个or操作符替换一个复合布尔表达式是一种有用的技术,它允许您简化代码并使其更具可读性。
要了解这项技术的实际应用,假设您需要编写一个函数,该函数将颜色名称作为一个字符串,并确定它是否是一种原色。为了解决这个问题,您将使用 RGB(红、绿、蓝)颜色模型:
>>> def is_primary_color(color):
... color = color.lower()
... return color == "red" or color == "green" or color == "blue"
...
>>> is_primary_color("yellow")
False
>>> is_primary_color("green")
True
在is_primary_color()中,您使用一个复合布尔表达式,该表达式使用or操作符来检查输入颜色是红色、绿色还是蓝色。即使该功能如预期的那样工作,情况可能会令人困惑,难以阅读和理解。
好消息是你可以用一个简洁易读的成员测试来代替上面的条件:
>>> def is_primary_color(color):
... primary_colors = {"red", "green", "blue"}
... return color.lower() in primary_colors ...
>>> is_primary_color("yellow")
False
>>> is_primary_color("green")
True
现在,您的函数使用in操作符来检查输入颜色是红色、绿色还是蓝色。将一组原色分配给一个适当命名的变量,如primary_colors,也有助于提高代码的可读性。最后的检查现在很清楚了。任何阅读您的代码的人都会立即理解您正试图根据 RGB 颜色模型来确定输入颜色是否是原色。
如果你再看一下这个例子,你会注意到原色已经被存储在一个集合中。为什么?你会在下一节找到你的答案。
编写高效的成员测试
Python 使用一种叫做哈希表的数据结构来实现字典和集合。哈希表有一个显著的特性:在数据结构中寻找任何给定的值需要大约相同的时间,不管表中有多少个值。使用大 O 符号,你会说哈希表中的值查找的时间复杂度为 O(1) ,这使得它们非常快。
现在,哈希表的这个特性与字典和集合上的成员测试有什么关系呢?事实证明,in和not in操作符在操作这些类型时工作非常快。这个细节允许您通过在成员测试中优先使用字典和集合而不是列表和其他序列来优化代码的性能。
要了解集合的效率比列表高多少,请继续创建以下脚本:
# performance.py
from timeit import timeit
a_list = list(range(100_000))
a_set = set(range(100_000))
list_time = timeit("-1 in a_list", number=1, globals=globals())
set_time = timeit("-1 in a_set", number=1, globals=globals())
print(f"Sets are {(list_time / set_time):.2f} times faster than Lists")
这个脚本创建了一个包含十万个值的整数列表和一个包含相同数量元素的集合。然后,脚本计算确定数字-1是否在列表和集合中所需的时间。你预先知道-1不会出现在列表或集合中。因此,在得到最终结果之前,成员操作符必须检查所有的值。
正如您已经知道的,当in操作符在一个列表中搜索一个值时,它使用一个时间复杂度为 O(n) 的算法。另一方面,当in操作符在集合中搜索一个值时,它使用哈希表查找算法,该算法的时间复杂度为 O(1) 。这一事实可以在性能方面产生很大的差异。
使用以下命令从命令行运行您的脚本:
$ python performance.py
Sets are 1563.33 times faster than Lists
尽管您的命令输出可能略有不同,但在这个特定的成员测试中,当您使用集合而不是列表时,它仍然会显示出显著的性能差异。有了列表,处理时间将与值的数量成正比。有了集合,对于任何数量的值,时间都差不多。
该性能测试表明,当您的代码对大型值集合进行成员资格检查时,您应该尽可能使用集合而不是列表。当您的代码在执行过程中执行几个成员测试时,您也将受益于 set。
但是,请注意,仅仅为了执行一些成员测试而将现有列表转换为集合并不是一个好主意。记住把链表转换成集合是一个时间复杂度为 O(n) 的操作。
使用operator.contains()进行成员资格测试
in操作符在 operator 模块中有一个等价的函数,它来自标准库。这个功能叫做 contains() 。它有两个参数——一组值和一个目标值。如果输入集合包含目标值,则返回True:
>>> from operator import contains
>>> contains([2, 3, 5, 9, 7], 5)
True
>>> contains([2, 3, 5, 9, 7], 8)
False
contains()的第一个参数是值的集合,第二个参数是目标值。请注意,参数的顺序不同于常规的成员资格操作,在常规操作中,目标值排在第一位。
当您使用 map() 或 filter() 等工具来处理代码中的可重复项时,这个函数就派上了用场。例如,假设你有一堆笛卡尔坐标点作为元组存储在一个列表中。您想要创建一个只包含不在坐标轴上的点的新列表。使用filter()功能,您可以得出以下解决方案:
>>> points = [
... (1, 3),
... (5, 0),
... (3, 7),
... (0, 6),
... (8, 3),
... (2, 0),
... ]
>>> list(filter(lambda point: not contains(point, 0), points))
[(1, 3), (3, 7), (8, 3)]
在这个例子中,您使用filter()来检索不包含0坐标的点。为此,在 lambda 函数中使用contains()。因为filter()返回一个迭代器,所以您将所有内容都包装在对list()的调用中,将迭代器转换成一个点列表。
尽管上面例子中的结构可以工作,但它相当复杂,因为它意味着导入contains(),在它上面创建一个lambda函数,并调用几个函数。您可以直接使用contains()或not in操作符使用列表理解得到相同的结果:
>>> [point for point in points if not contains(point, 0)]
[(1, 3), (3, 7), (8, 3)]
>>> [point for point in points if 0 not in point]
[(1, 3), (3, 7), (8, 3)]
上面的列表理解比前一个例子中对应的filter()调用更短,并且更具可读性。它们也不太复杂,因为你不需要创建一个lambda函数或者调用list(),所以你减少了知识需求。
支持用户定义类中的成员测试
提供一个 .__contains__() 方法是在您自己的类中支持成员测试的最显式和首选的方式。当你在成员测试中使用你的类的一个实例作为右操作数时,Python 会自动调用这个特殊方法。
您可能只向作为值集合的类添加一个.__contains__()方法。这样,类的用户将能够确定给定值是否存储在类的特定实例中。
举例来说,假设您需要创建一个最小的堆栈数据结构来存储遵循 LIFO(后进先出)原则的值。定制数据结构的一个要求是支持成员测试。因此,您最终编写了下面的类:
# stack.py
class Stack:
def __init__(self):
self.items = []
def push(self, item):
self.items.append(item)
def pop(self):
return self.items.pop()
def __contains__(self, item): return item in self.items
您的Stack类支持堆栈数据结构的两个核心功能。你可以将一个值推到栈顶,从栈顶弹出一个值。请注意,您的数据结构使用了一个list对象来存储和操作实际数据。
您的类也支持使用in和not in操作符的成员测试。为此,该类实现了一个依赖于in操作符本身的.__contains__()方法。
要测试您的类,请继续运行以下代码:
>>> from stack import Stack
>>> stack = Stack()
>>> stack.push(1)
>>> stack.push(2)
>>> stack.push(3)
>>> 2 in stack
True
>>> 42 in stack
False
>>> 42 not in stack
True
您的类完全支持in和not in操作符。干得好!现在,您知道了如何在自己的类中支持成员测试。
注意,如果一个给定的类有一个.__contains__()方法,那么这个类不必是可迭代的,成员操作符也能工作。在上面的例子中,Stack是不可迭代的,操作符仍然工作,因为它们从.__contains__()方法中检索结果。
除了提供一个.__contains__()方法,至少还有两种方法支持用户定义类中的成员测试。如果你的类有一个 .__iter__() 或者一个 .__getitem__() 方法,那么in和not in操作符也可以工作。
考虑下面这个Stack的替代版本:
# stack.py
class Stack:
def __init__(self):
self.items = []
def push(self, item):
self.items.append(item)
def pop(self):
return self.items.pop()
def __iter__(self): yield from self.items
这个.__iter__()特殊方法使得你的类是可迭代的,这足以让成员测试工作。来吧,试一试!
支持成员测试的另一种方法是实现一个.__getitem__()方法,该方法在类中使用从零开始的整数索引来处理索引操作:
# stack.py
class Stack:
def __init__(self):
self.items = []
def push(self, item):
self.items.append(item)
def pop(self):
return self.items.pop()
def __getitem__(self, index): return self.items[index]
当您对底层对象执行索引操作时,Python 会自动调用.__getitem__()方法。在本例中,当您执行stack[0]时,您将获得Stack实例中的第一项。Python 利用.__getitem__()让成员操作符正常工作。
结论
现在您知道了如何使用 Python 的 in 和 not in 操作符来执行成员测试。这种类型的测试允许您检查给定的值是否存在于值集合中,这是编程中非常常见的操作。
在本教程中,您已经学会了如何:
- 使用 Python 的
in和not in操作符运行成员测试 - 使用具有不同数据类型的
in和not in运算符 - 与
operator.contains()、一起工作,相当于in操作员的功能 - 支持自己班级中的
in和not in
有了这些知识,您就可以在代码中使用 Python 的in和not in操作符进行成员测试了。
源代码: 点击这里下载免费的源代码,你将使用它们用in和not in在 Python 中执行成员测试。*****
Python 中的基本输入、输出和字符串格式
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 中的阅读输入和写作输出
对于一个有用的程序,它通常需要通过从用户那里获得输入数据并向用户显示结果数据来与外界进行通信。在本教程中,您将了解 Python 的输入和输出。
输入可以由用户直接通过键盘输入,也可以来自外部资源,如文件或数据库。输出可以直接显示到控制台或 IDE,通过图形用户界面(GUI)显示到屏幕,或者再次显示到外部源。
在本介绍性系列的之前的教程中,您将:
- 比较了编程语言用来实现确定迭代的不同范例
- 了解了 iterables 和 iterators,这两个概念构成了 Python 中明确迭代的基础
- 将它们联系在一起,学习 Python 的 for loops
本教程结束时,你将知道如何:
- 通过内置功能
input()从键盘上接受用户输入 - 用内置函数
print()显示输出到控制台 - 使用 Python f-strings 格式化字符串数据
事不宜迟,我们开始吧!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
从键盘读取输入
程序经常需要从用户那里获取数据,通常是通过键盘输入的方式。在 Python 中实现这一点的一种方法是使用 input() :
input([<prompt>])从键盘上读取一行。(文档
input()功能暂停程序执行,以允许用户从键盘键入一行输入。一旦用户按下 Enter 键,所有键入的字符被读取并作为字符串返回:
>>> user_input = input()
foo bar baz
>>> user_input
'foo bar baz'
请注意,您的返回字符串不包括用户按下 Enter 键时生成的换行符。
如果包含可选的<prompt>参数,那么input()会将其显示为一个提示,以便用户知道应该输入什么:
>>> name = input("What is your name? ")
What is your name? Winston Smith
>>> name
'Winston Smith'
input()总是返回一个字符串。如果你想要一个数字类型,那么你需要用内置的int()、float()或complex()函数将字符串转换成合适的类型:
1>>> number = input("Enter a number: ")
2Enter a number: 50
3>>> print(number + 100) 4Traceback (most recent call last):
5 File "<stdin>", line 1, in <module>
6TypeError: must be str, not int
7
8>>> number = int(input("Enter a number: ")) 9Enter a number: 50
10>>> print(number + 100) 11150
在上面的例子中,第 3 行的表达式number + 100是无效的,因为number是一个字符串,而100是一个整数。为了避免出现这种错误,第 8 行在收集用户输入后立即将number转换成一个整数。这样,第 10 行的计算number + 100有两个整数要相加。正因为如此,对 print() 的调用成功。
**Python 版本注意:**如果您发现自己正在使用 Python 2.x 代码,您可能会发现 Python 版本 2 和 3 的输入函数略有不同。
Python 2 中的raw_input()从键盘读取输入并返回。如上所述,Python 2 中的raw_input()的行为就像 Python 3 中的input()。
但是 Python 2 也有一个函数叫做input()。在 Python 2 中,input()从键盘读取输入,将其作为 Python 表达式进行解析和求值,并返回结果值。
Python 3 没有提供一个函数来完成 Python 2 的input()所做的事情。您可以用表达式eval(input())模仿 Python 3 中的效果。但是,这是一个安全风险,因为它允许用户运行任意的、潜在的恶意代码。
有关eval()及其潜在安全风险的更多信息,请查看 Python eval():动态评估表达式。
使用input(),你可以从你的用户那里收集数据。但是如果你想向他们展示你的程序计算出的任何结果呢?接下来,您将学习如何在控制台中向用户显示输出。
将输出写入控制台
除了从用户那里获取数据,程序通常还需要将数据返回给用户。用 Python 中的 print() 可以将程序数据显示到控制台。
要向控制台显示对象,请将它们作为逗号分隔的参数列表传递给print()。
print(<obj>, ..., <obj>)向控制台显示每个
<obj>的字符串表示。(文档)
默认情况下,print()用一个空格分隔对象,并在输出的末尾附加一个新行:
>>> first_name = "Winston"
>>> last_name = "Smith"
>>> print("Name:", first_name, last_name)
Name: Winston Smith
您可以指定任何类型的对象作为print()的参数。如果一个对象不是一个字符串,那么print()在显示它之前将它转换成一个合适的字符串表示:
>>> example_list = [1, 2, 3]
>>> type(example_list)
<class 'list'>
>>> example_int = -12
>>> type(example_int)
<class 'int'>
>>> example_dict = {"foo": 1, "bar": 2}
>>> type(example_dict)
<class 'dict'>
>>> type(len)
<class 'builtin_function_or_method'>
>>> print(example_list, example_int, example_dict, len)
[1, 2, 3] -12 {'foo': 1, 'bar': 2} <built-in function len>
如你所见,甚至像列表、字典和函数这样的复杂类型也可以用print()显示到控制台。
具有高级功能的打印
print()接受一些额外的参数,对输出的格式提供适度的控制。每一个都是一种特殊类型的论点,叫做关键词论点。在这个介绍性系列的后面,您将会遇到一个关于函数和参数传递的教程,这样您就可以了解更多关于关键字参数的知识。
不过,现在你需要知道的是:
- 关键字参数的形式为
<keyword>=<value>。 - 传递给
print()的任何关键字参数必须出现在末尾,在要显示的对象列表之后。
在下面几节中,您将看到这些关键字参数如何影响由print()产生的控制台输出。
分离打印值
添加关键字参数sep=<str>会导致 Python 通过而不是默认的单个空格:来分隔对象
>>> print("foo", 42, "bar")
foo 42 bar
>>> print("foo", 42, "bar", sep="/")
foo/42/bar
>>> print("foo", 42, "bar", sep="...")
foo...42...bar
>>> d = {"foo": 1, "bar": 2, "baz": 3}
>>> for k, v in d.items():
... print(k, v, sep=" -> ")
...
foo -> 1
bar -> 2
baz -> 3
要将对象挤在一起,中间没有任何空间,请指定一个空字符串("")作为分隔符:
>>> print("foo", 42, "bar", sep="")
foo42bar
您可以使用sep关键字指定任意字符串作为分隔符。
控制换行符
关键字参数end=<str>导致输出由<str>终止,而不是由默认换行符终止:
>>> if True:
... print("foo", end="/")
... print(42, end="/")
... print("bar")
...
foo/42/bar
例如,如果您在一个循环中显示值,您可以使用end使值显示在一行上,而不是单独的行上:
>>> for number in range(10):
... print(number)
...
0
1
2
3
4
5
6
7
8
9
>>> for number in range(10):
... print(number, end=(" " if number < 9 else "\n"))
...
0 1 2 3 4 5 6 7 8 9
您可以使用end关键字将任何字符串指定为输出终止符。
将输出发送到流
print()接受两个额外的关键字参数,这两个参数都会影响函数处理输出流的方式:
-
file=<stream>: 默认情况下,print()将其输出发送到一个名为sys.stdout的默认流,这个流通常相当于控制台。file=<stream>参数使print()将输出发送到由<stream>指定的替代流。 -
flush=True: 通常,print()缓冲其输出,只间歇地写入输出流。flush=True指定 Python 在每次调用print()时强制刷新输出流。
为了完整起见,这里给出了这两个关键字参数。在学习旅程的这个阶段,您可能不需要太关心输出流。
使用格式化字符串
虽然您可以深入了解 Python print()函数,但它提供的控制台输出格式充其量只是初步的。您可以选择如何分离打印的对象,并指定打印行末尾的内容。大概就是这样。
在许多情况下,您需要更精确地控制要显示的数据的外观。Python 提供了几种格式化输出字符串数据的方法。在本节中,您将看到一个使用 Python f-strings 格式化字符串的例子。
注意:****f-string 语法是字符串格式化的现代方法之一。要进行深入讨论,您可能需要查看这些教程:
在 Python 中的格式化字符串输出的教程中,您还将更详细地了解字符串格式化的两种方法,f-strings 和str.format(),该教程在本介绍性系列教程的后面。
在本节中,您将使用 f 字符串来格式化您的输出。假设您编写了一些要求用户输入姓名和年龄的代码:
>>> name = input("What is your name? ")
What is your name? Winston
>>> age = int(input("How old are you? "))
How old are you? 24
>>> print(name)
Winston
>>> print(age)
24
您已经成功地从您的用户那里收集了数据,并且您还可以将其显示回他们的控制台。要创建格式良好的输出消息,可以使用 f 字符串语法:
>>> f"Hello, {name}. You are {age}."
Hello, Winston. You are 24.
string 允许你把变量名放在花括号({})中,把它们的值注入到你正在构建的字符串中。你所需要做的就是在字符串的开头加上字母f或者F。
接下来,假设您想告诉您的用户 50 年后他们的年龄。Python f-strings 允许您在没有太多开销的情况下做到这一点!您可以在花括号之间添加任何 Python 表达式,Python 将首先计算它的值,然后将其注入到您的 f 字符串中:
>>> f"Hello, {name}. In 50 years, you'll be {age + 50}."
Hello, Winston. In 50 years, you'll be 74.
您已经将50添加到从用户处收集的age的值中,并在前面使用int()将其转换为整数。整个计算发生在 f 弦的第二对花括号里。相当酷!
**注意:**如果你想了解更多关于使用这种方便的字符串格式化技术,那么你可以更深入地阅读关于 Python 3 的 f-Strings 的指南。
Python f-strings 可以说是在 Python 中格式化字符串的最方便的方式。如果你只想学习一种方法,最好坚持使用 Python 的 f 字符串。然而,这种语法从 Python 3.6 开始才可用,所以如果您需要使用 Python 的旧版本,那么您将不得不使用不同的语法,例如str.format()方法或字符串模运算符。
Python 输入和输出:结论
在本教程中,您学习了 Python 中的输入和输出,以及 Python 程序如何与用户通信。您还研究了一些参数,您可以使用这些参数向输入提示添加消息,或者定制 Python 如何向用户显示输出。
你已经学会了如何:
- 通过内置功能
input()从键盘上接受用户输入 - 用内置函数
print()显示输出到控制台 - 使用 Python f-strings 格式化字符串数据
在这个介绍性系列的下一篇教程中,您将学习另一种字符串格式化技术,并且将更深入地使用 f 字符串。
« Python “for” Loops (Definite Iteration)Basic Input and Output in PythonPython String Formatting Techniques »
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 中的阅读输入和写作输出**
在 Python 中实现接口
接口在软件工程中起着重要的作用。随着应用程序的增长,对代码库的更新和更改变得更加难以管理。通常情况下,您最终会得到看起来非常相似但不相关的类,这可能会导致一些混淆。在本教程中,您将看到如何使用一个 Python 接口来帮助确定应该使用什么类来解决当前的问题。
在本教程中,你将能够:
- 了解接口如何工作以及 Python 接口创建的注意事项
- 理解在像 Python 这样的动态语言中接口是多么有用
- 实现一个非正式的 Python 接口
- 使用
abc.ABCMeta和@abc.abstractmethod实现一个正式的 Python 接口
Python 中的接口处理方式不同于大多数其他语言,它们的设计复杂度也各不相同。在本教程结束时,您将对 Python 数据模型的某些方面有更好的理解,以及 Python 中的接口与 Java、C++和 Go 等语言中的接口的比较。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 接口概述
在高层次上,接口充当设计类的蓝图。像类一样,接口定义方法。与类不同,这些方法是抽象的。一个抽象方法是接口简单定义的方法。它没有实现这些方法。这是由类来完成的,然后实现接口,并赋予接口的抽象方法具体的含义。
与像 Java 、Go 和 C++ 这样的语言相比,Python 的界面设计方法有些不同。这些语言都有一个interface关键字,而 Python 没有。Python 在另一个方面进一步偏离了其他语言。它不需要实现接口的类来定义接口的所有抽象方法。
非正式接口
在某些情况下,您可能不需要正式 Python 接口的严格规则。Python 的动态特性允许你实现一个非正式接口。非正式的 Python 接口是一个定义了可以被覆盖的方法的类,但是没有严格的执行。
在下面的例子中,您将从一个数据工程师的角度出发,他需要从各种不同的非结构化文件类型中提取文本,比如 pdf 和电子邮件。您将创建一个非正式的接口,它定义了在PdfParser和EmlParser具体类中的方法:
class InformalParserInterface:
def load_data_source(self, path: str, file_name: str) -> str:
"""Load in the file for extracting text."""
pass
def extract_text(self, full_file_name: str) -> dict:
"""Extract text from the currently loaded file."""
pass
InformalParserInterface定义了两种方法.load_data_source()和.extract_text()。这些方法已定义但未实现。一旦你创建了从InformalParserInterface继承的具体类,这个实现就会发生。
如您所见,InformalParserInterface看起来和标准 Python 类一样。你依靠鸭打字来通知用户这是一个接口,应该相应地使用。
注:没听说过鸭打字?这个术语说,如果你有一个看起来像鸭子,走路像鸭子,叫声像鸭子的物体,那么它一定是鸭子!要了解更多,请查看鸭子打字。
记住 duck 类型,定义两个实现InformalParserInterface的类。要使用您的接口,您必须创建一个具体的类。一个具体类是接口的子类,提供接口方法的实现。您将创建两个具体的类来实现您的接口。第一个是PdfParser,您将使用它来解析来自 PDF 文件的文本:
class PdfParser(InformalParserInterface):
"""Extract text from a PDF"""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides InformalParserInterface.load_data_source()"""
pass
def extract_text(self, full_file_path: str) -> dict:
"""Overrides InformalParserInterface.extract_text()"""
pass
InformalParserInterface的具体实现现在允许你从 PDF 文件中提取文本。
第二个具体的类是EmlParser,您将使用它来解析来自电子邮件的文本:
class EmlParser(InformalParserInterface):
"""Extract text from an email"""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides InformalParserInterface.load_data_source()"""
pass
def extract_text_from_email(self, full_file_path: str) -> dict:
"""A method defined only in EmlParser.
Does not override InformalParserInterface.extract_text()
"""
pass
InformalParserInterface的具体实现现在允许你从电子邮件文件中提取文本。
到目前为止,您已经定义了InformalPythonInterface的两个具体实现。然而,请注意EmlParser未能正确定义.extract_text()。如果您要检查EmlParser是否实现了InformalParserInterface,那么您会得到以下结果:
>>> # Check if both PdfParser and EmlParser implement InformalParserInterface
>>> issubclass(PdfParser, InformalParserInterface)
True
>>> issubclass(EmlParser, InformalParserInterface)
True
这将返回True,这造成了一点问题,因为它违反了接口的定义!
现在检查PdfParser和EmlParser的方法解析顺序(MRO) 。这将告诉您正在讨论的类的超类,以及它们在执行方法时被搜索的顺序。你可以通过使用邓德方法cls.__mro__来查看一个类的 MRO:
>>> PdfParser.__mro__
(__main__.PdfParser, __main__.InformalParserInterface, object)
>>> EmlParser.__mro__
(__main__.EmlParser, __main__.InformalParserInterface, object)
这种非正式的接口对于只有少数开发人员开发源代码的小项目来说很好。然而,随着项目越来越大,团队越来越多,这可能导致开发人员花费无数时间在代码库中寻找难以发现的逻辑错误!
使用元类
理想情况下,当实现类没有定义接口的所有抽象方法时,您会希望issubclass(EmlParser, InformalParserInterface)返回False。为此,您将创建一个名为ParserMeta的元类。您将覆盖两个 dunder 方法:
.__instancecheck__().__subclasscheck__()
在下面的代码块中,您创建了一个名为UpdatedInformalParserInterface的类,它从ParserMeta元类构建而来:
class ParserMeta(type):
"""A Parser metaclass that will be used for parser class creation.
"""
def __instancecheck__(cls, instance):
return cls.__subclasscheck__(type(instance))
def __subclasscheck__(cls, subclass):
return (hasattr(subclass, 'load_data_source') and
callable(subclass.load_data_source) and
hasattr(subclass, 'extract_text') and
callable(subclass.extract_text))
class UpdatedInformalParserInterface(metaclass=ParserMeta):
"""This interface is used for concrete classes to inherit from.
There is no need to define the ParserMeta methods as any class
as they are implicitly made available via .__subclasscheck__().
"""
pass
现在已经创建了ParserMeta和UpdatedInformalParserInterface,您可以创建您的具体实现了。
首先,创建一个名为PdfParserNew的解析 pdf 的新类:
class PdfParserNew:
"""Extract text from a PDF."""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides UpdatedInformalParserInterface.load_data_source()"""
pass
def extract_text(self, full_file_path: str) -> dict:
"""Overrides UpdatedInformalParserInterface.extract_text()"""
pass
这里,PdfParserNew覆盖了.load_data_source()和.extract_text(),所以issubclass(PdfParserNew, UpdatedInformalParserInterface)应该返回True。
在下一个代码块中,您有了一个名为EmlParserNew的电子邮件解析器的新实现:
class EmlParserNew:
"""Extract text from an email."""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides UpdatedInformalParserInterface.load_data_source()"""
pass
def extract_text_from_email(self, full_file_path: str) -> dict:
"""A method defined only in EmlParser.
Does not override UpdatedInformalParserInterface.extract_text()
"""
pass
在这里,您有一个用于创建UpdatedInformalParserInterface的元类。通过使用元类,您不需要显式定义子类。相反,子类必须定义所需的方法。如果没有,那么issubclass(EmlParserNew, UpdatedInformalParserInterface)将返回False。
在您的具体类上运行issubclass()将产生以下结果:
>>> issubclass(PdfParserNew, UpdatedInformalParserInterface)
True
>>> issubclass(EmlParserNew, UpdatedInformalParserInterface)
False
正如所料,EmlParserNew不是UpdatedInformalParserInterface的子类,因为.extract_text()没有在EmlParserNew中定义。
现在,让我们来看看 MRO:
>>> PdfParserNew.__mro__
(<class '__main__.PdfParserNew'>, <class 'object'>)
如您所见,UpdatedInformalParserInterface是PdfParserNew的超类,但是它没有出现在 MRO 中。这种不寻常的行为是由于UpdatedInformalParserInterface是PdfParserNew的虚拟基类造成的。
使用虚拟基类
在前面的例子中,issubclass(EmlParserNew, UpdatedInformalParserInterface)返回了True,即使UpdatedInformalParserInterface没有出现在EmlParserNew MRO 中。那是因为UpdatedInformalParserInterface是EmlParserNew的一个虚拟基类。
这些子类和标准子类之间的关键区别在于,虚拟基类使用.__subclasscheck__() dunder 方法来隐式检查一个类是否是超类的虚拟子类。此外,虚拟基类不会出现在子类 MRO 中。
看一下这个代码块:
class PersonMeta(type):
"""A person metaclass"""
def __instancecheck__(cls, instance):
return cls.__subclasscheck__(type(instance))
def __subclasscheck__(cls, subclass):
return (hasattr(subclass, 'name') and
callable(subclass.name) and
hasattr(subclass, 'age') and
callable(subclass.age))
class PersonSuper:
"""A person superclass"""
def name(self) -> str:
pass
def age(self) -> int:
pass
class Person(metaclass=PersonMeta):
"""Person interface built from PersonMeta metaclass."""
pass
这里,您有了创建虚拟基类的设置:
- 元类
PersonMeta - 基类
PersonSuper - Python 接口
Person
现在创建虚拟基类的设置已经完成,您将定义两个具体的类,Employee和Friend。Employee类继承自PersonSuper,而Friend隐式继承自Person:
# Inheriting subclasses
class Employee(PersonSuper):
"""Inherits from PersonSuper
PersonSuper will appear in Employee.__mro__
"""
pass
class Friend:
"""Built implicitly from Person
Friend is a virtual subclass of Person since
both required methods exist.
Person not in Friend.__mro__
"""
def name(self):
pass
def age(self):
pass
虽然Friend没有显式继承Person,但是它实现了.name()和.age(),所以Person成为了Friend的虚拟基类。当你运行issubclass(Friend, Person)时,它应该返回True,这意味着Friend是Person的子类。
下面的 UML 图显示了当您在Friend类上调用issubclass()时会发生什么:
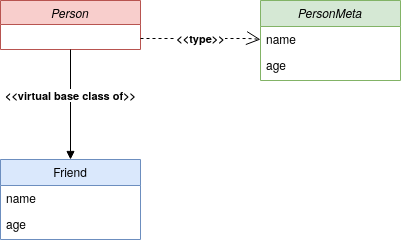
看一看PersonMeta,您会注意到还有另一个名为.__instancecheck__()的 dunder 方法。该方法用于检查是否从Person接口创建了Friend的实例。当你使用isinstance(Friend, Person)时,你的代码将调用.__instancecheck__()。
正式接口
非正式接口对于代码基数小、程序员数量有限的项目非常有用。然而,非正式接口对于大型应用程序来说是错误的。为了创建一个正式的 Python 接口,你将需要 Python 的abc模块中的一些工具。
使用abc.ABCMeta
为了强制抽象方法的子类实例化,您将利用 Python 的内置模块 abc 中的ABCMeta。回到您的UpdatedInformalParserInterface接口,您创建了自己的元类ParserMeta,用被覆盖的 dunder 方法.__instancecheck__()和.__subclasscheck__()。
您将使用abc.ABCMeta作为元类,而不是创建自己的元类。然后,您将覆盖.__subclasshook__()来代替.__instancecheck__()和.__subclasscheck__(),因为它创建了这些 dunder 方法的更可靠的实现。
使用.__subclasshook__()
下面是使用abc.ABCMeta作为元类的FormalParserInterface的实现:
import abc
class FormalParserInterface(metaclass=abc.ABCMeta):
@classmethod
def __subclasshook__(cls, subclass):
return (hasattr(subclass, 'load_data_source') and
callable(subclass.load_data_source) and
hasattr(subclass, 'extract_text') and
callable(subclass.extract_text))
class PdfParserNew:
"""Extract text from a PDF."""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides FormalParserInterface.load_data_source()"""
pass
def extract_text(self, full_file_path: str) -> dict:
"""Overrides FormalParserInterface.extract_text()"""
pass
class EmlParserNew:
"""Extract text from an email."""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides FormalParserInterface.load_data_source()"""
pass
def extract_text_from_email(self, full_file_path: str) -> dict:
"""A method defined only in EmlParser.
Does not override FormalParserInterface.extract_text()
"""
pass
如果在PdfParserNew和EmlParserNew上运行issubclass(),那么issubclass()将分别返回True和False。
使用abc注册一个虚拟子类
一旦导入了abc模块,就可以通过使用.register()元方法直接注册一个虚拟子类。在下一个例子中,您将接口Double注册为内置__float__类的虚拟基类:
class Double(metaclass=abc.ABCMeta):
"""Double precision floating point number."""
pass
Double.register(float)
你可以看看使用.register()的效果:
>>> issubclass(float, Double)
True
>>> isinstance(1.2345, Double)
True
通过使用.register()元方法,您已经成功地将Double注册为float的虚拟子类。
一旦你注册了Double,你就可以用它作为类装饰器来将装饰类设置为虚拟子类:
@Double.register
class Double64:
"""A 64-bit double-precision floating-point number."""
pass
print(issubclass(Double64, Double)) # True
decorator register 方法帮助您创建自定义虚拟类继承的层次结构。
通过注册使用子类检测
当你组合.__subclasshook__()和.register()时,你必须小心,因为.__subclasshook__()优先于虚拟子类注册。为了确保注册的虚拟子类被考虑在内,您必须将NotImplemented添加到.__subclasshook__() dunder 方法中。FormalParserInterface将更新为以下内容:
class FormalParserInterface(metaclass=abc.ABCMeta):
@classmethod
def __subclasshook__(cls, subclass):
return (hasattr(subclass, 'load_data_source') and
callable(subclass.load_data_source) and
hasattr(subclass, 'extract_text') and
callable(subclass.extract_text) or
NotImplemented)
class PdfParserNew:
"""Extract text from a PDF."""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides FormalParserInterface.load_data_source()"""
pass
def extract_text(self, full_file_path: str) -> dict:
"""Overrides FormalParserInterface.extract_text()"""
pass
@FormalParserInterface.register
class EmlParserNew:
"""Extract text from an email."""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides FormalParserInterface.load_data_source()"""
pass
def extract_text_from_email(self, full_file_path: str) -> dict:
"""A method defined only in EmlParser.
Does not override FormalParserInterface.extract_text()
"""
pass
print(issubclass(PdfParserNew, FormalParserInterface)) # True
print(issubclass(EmlParserNew, FormalParserInterface)) # True
因为您已经使用了注册,所以您可以看到EmlParserNew被视为FormalParserInterface接口的虚拟子类。这不是你想要的,因为EmlParserNew不会覆盖.extract_text()。请谨慎注册虚拟子类!
使用抽象方法声明
抽象方法是由 Python 接口声明的方法,但它可能没有有用的实现。抽象方法必须由实现相关接口的具体类重写。
要在 Python 中创建抽象方法,需要在接口的方法中添加@abc.abstractmethod decorator。在下一个例子中,您更新了FormalParserInterface以包含抽象方法.load_data_source()和.extract_text():
class FormalParserInterface(metaclass=abc.ABCMeta):
@classmethod
def __subclasshook__(cls, subclass):
return (hasattr(subclass, 'load_data_source') and
callable(subclass.load_data_source) and
hasattr(subclass, 'extract_text') and
callable(subclass.extract_text) or
NotImplemented)
@abc.abstractmethod
def load_data_source(self, path: str, file_name: str):
"""Load in the data set"""
raise NotImplementedError
@abc.abstractmethod
def extract_text(self, full_file_path: str):
"""Extract text from the data set"""
raise NotImplementedError
class PdfParserNew(FormalParserInterface):
"""Extract text from a PDF."""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides FormalParserInterface.load_data_source()"""
pass
def extract_text(self, full_file_path: str) -> dict:
"""Overrides FormalParserInterface.extract_text()"""
pass
class EmlParserNew(FormalParserInterface):
"""Extract text from an email."""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides FormalParserInterface.load_data_source()"""
pass
def extract_text_from_email(self, full_file_path: str) -> dict:
"""A method defined only in EmlParser.
Does not override FormalParserInterface.extract_text()
"""
pass
在上面的例子中,您最终创建了一个正式的接口,当抽象方法没有被覆盖时,它会引发错误。因为PdfParserNew正确地覆盖了FormalParserInterface抽象方法,所以PdfParserNew实例pdf_parser不会引发任何错误。但是,EmlParserNew会引发一个错误:
>>> pdf_parser = PdfParserNew()
>>> eml_parser = EmlParserNew()
Traceback (most recent call last):
File "real_python_interfaces.py", line 53, in <module>
eml_interface = EmlParserNew()
TypeError: Can't instantiate abstract class EmlParserNew with abstract methods extract_text
如您所见, traceback 消息告诉您还没有覆盖所有的抽象方法。这是您在构建正式 Python 接口时所期望的行为。
其他语言界面
接口出现在许多编程语言中,并且它们的实现因语言而异。在接下来的几节中,您将比较 Python 与 Java、C++和 Go 中的接口。
Java
与 Python 不同, Java 包含一个interface关键字。按照文件解析器的例子,用 Java 声明一个接口,如下所示:
public interface FileParserInterface { // Static fields, and abstract methods go here ... public void loadDataSource(); public void extractText(); }
现在您将创建两个具体的类,PdfParser和EmlParser,来实现FileParserInterface。为此,您必须在类定义中使用implements关键字,如下所示:
public class EmlParser implements FileParserInterface { public void loadDataSource() { // Code to load the data set } public void extractText() { // Code to extract the text } }
继续您的文件解析示例,一个全功能的 Java 接口应该是这样的:
import java.util.*; import java.io.*; public class FileParser { public static void main(String[] args) throws IOException { // The main entry point } public interface FileParserInterface { HashMap<String, ArrayList<String>> file_contents = null; public void loadDataSource(); public void extractText(); } public class PdfParser implements FileParserInterface { public void loadDataSource() { // Code to load the data set } public void extractText() { // Code to extract the text } } public class EmlParser implements FileParserInterface { public void loadDataSource() { // Code to load the data set } public void extractText() { // Code to extract the text } } }
如您所见,Python 接口在创建过程中比 Java 接口提供了更多的灵活性。
C++
像 Python 一样,C++使用抽象基类来创建接口。在 C++中定义接口时,使用关键字virtual来描述应该在具体类中覆盖的方法:
class FileParserInterface { public: virtual void loadDataSource(std::string path, std::string file_name); virtual void extractText(std::string full_file_name); };
当您想要实现接口时,您将给出具体的类名,后跟一个冒号(:),然后是接口的名称。下面的示例演示了 C++接口的实现:
class PdfParser : FileParserInterface { public: void loadDataSource(std::string path, std::string file_name); void extractText(std::string full_file_name); }; class EmlParser : FileParserInterface { public: void loadDataSource(std::string path, std::string file_name); void extractText(std::string full_file_name); };
Python 接口和 C++接口有一些相似之处,因为它们都利用抽象基类来模拟接口。
转到
虽然 Go 的语法让人想起 Python,但是 Go 编程语言包含了一个interface关键字,就像 Java 一样。让我们在 Go 中创建fileParserInterface:
type fileParserInterface interface { loadDataSet(path string, filename string) extractText(full_file_path string) }
Python 和 Go 的一个很大的区别就是 Go 没有类。更确切地说,Go 类似于 C ,因为它使用struct关键字来创建结构。一个结构类似于一个类,因为一个结构包含数据和方法。然而,与类不同的是,所有的数据和方法都是公开访问的。Go 中的具体结构将用于实现fileParserInterface。
下面是 Go 如何使用接口的一个例子:
package main type fileParserInterface interface { loadDataSet(path string, filename string) extractText(full_file_path string) } type pdfParser struct { // Data goes here ... } type emlParser struct { // Data goes here ... } func (p pdfParser) loadDataSet() { // Method definition ... } func (p pdfParser) extractText() { // Method definition ... } func (e emlParser) loadDataSet() { // Method definition ... } func (e emlParser) extractText() { // Method definition ... } func main() { // Main entrypoint }
与 Python 接口不同,Go 接口是使用 structs 和显式关键字interface创建的。
结论
当你创建接口时,Python 提供了很大的灵活性。非正式的 Python 接口对于小型项目非常有用,在这些项目中,您不太可能对方法的返回类型感到困惑。随着项目的增长,对正式 Python 接口的需求变得更加重要,因为推断返回类型变得更加困难。这确保了实现接口的具体类覆盖了抽象方法。
现在你可以:
- 理解接口如何工作以及创建 Python 接口的注意事项
- 理解像 Python 这样的动态语言中接口的用途
- 用 Python 实现正式和非正式的接口
- 将 Python 接口与 Java、C++和 Go 等语言中的接口进行比较
既然您已经熟悉了如何创建 Python 接口,那么在您的下一个项目中添加一个 Python 接口来看看它的实际用途吧!*****
Python 实践问题:解析 CSV 文件
原文:https://realpython.com/python-interview-problem-parsing-csv-files/
你是一名开发人员,在即将到来的面试之前,你在寻找一些使用逗号分隔值(CSV)文件的练习吗?本教程将引导您完成一系列 Python CSV 实践问题,帮助您做好准备。
本教程面向中级 Python 开发人员。它假设一个Python 的基础知识和处理 CSV 文件。和其他练习题教程一样,这里列出的每个问题都有问题描述。您将首先看到问题陈述,然后有机会开发您自己的解决方案。
在本教程中,您将探索:
- 编写使用 CSV 文件的代码
- 用 pytest 做测试驱动开发
- 讨论您的解决方案和可能的改进
- 内置 CSV 模块和熊猫之间的权衡
通过单击下面的链接,您可以获得本教程中遇到的每个问题的单元测试失败的框架代码:
获取源代码: 单击此处获取源代码,您将在本教程中使用来练习解析 CSV 文件。
Python CSV 解析:足球比分
你的第一个问题是关于英超联赛的排名。解决这个不需要什么专门的足球知识,Python 就行!
当你解决问题时,试着为每一点功能编写更多的单元测试,然后编写功能以通过测试。这就是所谓的测试驱动开发,这是一个展示你的编码和测试能力的好方法!
问题描述
对于这一轮的问题,坚持标准库csv模块。稍后你会用熊猫再拍一次。这是你的第一个问题:
找出最小目标差值
编写一个程序,在命令行上输入文件名并处理 CSV 文件的内容。内容将是英格兰超级联赛赛季末的足球排名。你的程序应该确定那个赛季哪个队的净胜球最少。
CSV 文件的第一行是列标题,随后的每一行显示一个团队的数据:
`Team,Games,Wins,Losses,Draws,Goals For,Goals Against Arsenal,38,26,9,3,79,36`标有
Goals For和Goals Against的栏包含该赛季各队的总进球数。(所以阿森纳进了 79 个球,对他们进了 36 个球。)写个程序读取文件,然后打印出
Goals For和Goals Against相差最小的队伍名称。用 pytest 创建单元测试来测试你的程序。
框架代码中提供了一个单元测试,用于测试您稍后将看到的问题陈述。您可以在编写解决方案时添加更多内容。还有两个 pytest 夹具给定:
# test_football_v1.py
import pytest
import football_v1 as fb
@pytest.fixture
def mock_csv_data():
return [
"Team,Games,Wins,Losses,Draws,Goals For,Goals Against",
"Liverpool FC, 38, 32, 3, 3, 85, 33",
"Norwich City FC, 38, 5, 27, 6, 26, 75",
]
@pytest.fixture
def mock_csv_file(tmp_path, mock_csv_data):
datafile = tmp_path / "football.csv"
datafile.write_text("\n".join(mock_csv_data))
return str(datafile)
第一个 fixture 提供了一个由字符串组成的列表,这些字符串模仿真实的 CSV 数据,第二个 fixture 提供了一个由测试数据支持的文件名。字符串列表中的每个字符串代表测试文件中的一行。
**注意:**此处的解决方案将有一组非详尽的测试,仅证明基本功能。对于一个真实的系统,你可能想要一个更完整的测试套件,可能利用参数化。
请记住,所提供的装置只是一个开始。在设计解决方案的每个部分时,添加使用它们的单元测试!
问题解决方案
这里讨论一下 Real Python 团队达成的解决方案,以及团队是如何达成的。
**注意:**记住,在您准备好查看每个 Python 练习问题的答案之前,不要打开下面折叠的部分!
乐谱解析的怎么样了?你准备好看到真正的 Python 团队给出的答案了吗?
在解决这个问题的过程中,该团队通过编写并多次重写代码,提出了几个解决方案。在面试中,你通常只有一次机会。在实时编码的情况下,您可以使用一种技术来解决这个问题,那就是花一点时间来讨论您现在可以使用的其他实现选项。
解决方案 1
您将研究这个问题的两种不同的解决方案。您将看到的第一个解决方案运行良好,但仍有改进的空间。您将在这里使用测试驱动开发(TDD)模型,因此您不会首先查看完整的解决方案,而只是查看解决方案的整体计划。
将解决方案分成几个部分允许您在编写代码之前为每个部分编写单元测试。这是该解决方案的大致轮廓:
- 在生成器中读取并解析 CSV 文件的每一行。
- 计算给定线的队名和分数差。
- 求最小分数差。
让我们从第一部分开始,一次一行地读取和解析文件。您将首先为该操作构建测试。
读取并解析
给定问题的描述,您提前知道列是什么,所以您不需要输出中的第一行标签。您还知道每一行数据都有七个字段,因此您可以测试您的解析函数是否返回一个行列表,每一行都有七个条目:
# test_football_v1.py
import pytest
import football_v1 as fb
# ...
def test_parse_next_line(mock_csv_data):
all_lines = [line for line in fb.parse_next_line(mock_csv_data)]
assert len(all_lines) == 2
for line in all_lines:
assert len(line) == 7
您可以看到这个测试使用了您的第一个 pytest fixture,它提供了一个 CSV 行列表。这个测试利用了 CSV 模块可以解析一个列表对象或者一个文件对象的事实。这对于您的测试来说非常方便,因为您还不必担心管理文件对象。
测试使用一个列表理解来读取从parse_next_line()开始的所有行,这将是一个生成器。然后,它断言列表中的几个属性:
- 列表中有两个条目。
- 每个条目本身是一个包含七个项目的列表。
现在您有了一个测试,您可以运行它来确认它是否运行以及它是否如预期的那样失败:
$ pytest test_football_v1.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 1 item
test_football_v1.py F [100%]
=================================== FAILURES ===================================
_______________________________ test_parse_next_line ___________________________
mock_csv_data = ['Team,Games,Wins,Losses,Draws,Goals For,Goals Against', ....
def test_parse_next_line(mock_csv_data ):
> all_lines = [line for line in fb.parse_next_line(mock_csv_data)]
E AttributeError: module 'football_v1' has no attribute 'parse_next_line'
test_football_csv.py:30: AttributeError
=========================== short test summary info ============================
FAILED test_football_v1.py::test_parse_next_line - AttributeError: module 'fo...
============================== 1 failed in 0.02s ===============================
测试失败是因为parse_next_line()是未定义的,考虑到您还没有编写它,这是有意义的。当你知道测试会失败时运行测试会给你信心,当测试最终通过时,你所做的改变就是修复它们的原因。
**注意:**上面的 pytest 输出假设您有一个名为football_v1.py的文件,但是它不包含函数parse_next_line()。如果你没有这个文件,你可能会得到一个错误提示ModuleNotFoundError: No module named 'football_v1'。
接下来你要写缺失的parse_next_line()。这个函数将是一个生成器,返回文件中每一行的解析版本。您需要添加一些代码来跳过标题:
# football_v1.py
import csv
def parse_next_line(csv_file):
for line in csv.DictReader(csv_file):
yield line
该函数首先创建一个csv.DictReader(),它是 CSV 文件的迭代器。DictReader使用标题行作为它创建的字典的关键字。文件的每一行都用这些键和相应的值构建了一个字典。这个字典是用来创建您的生成器的。
现在用您的单元测试来尝试一下:
$ pytest test_football_v1.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 1 item
test_football_v1.py . [100%]
============================== 1 passed in 0.01s ===============================
太棒了。您的第一个功能块正在工作。您知道您添加的代码是使测试通过的原因。现在你可以进入下一步,计算给定线的分数差。
计算微分
该函数将获取由parse_next_line()解析的值列表,并计算分数差Goals For - Goals Against。这就是那些具有少量代表性数据的测试装置将会有所帮助的地方。您可以手动计算测试数据中两条线的差异,得到利物浦足球俱乐部的差异为 52,诺里奇城足球俱乐部的差异为 49。
这个测试将使用您刚刚完成的生成器函数从测试数据中提取每一行:
# test_football_v1.py
import pytest
import football_v1 as fb
# ...
def test_get_score_difference(mock_csv_data):
reader = fb.parse_next_line(mock_csv_data)
assert fb.get_name_and_diff(next(reader)) == ("Liverpool FC", 52)
assert fb.get_name_and_diff(next(reader)) == ("Norwich City FC", 49)
首先创建刚刚测试过的生成器,然后使用next()遍历两行测试数据。 assert语句测试每个手工计算的值是否正确。
和以前一样,一旦有了测试,就可以运行它以确保它失败:
$ pytest test_football_v1.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 2 items
test_football_v1.py .F [100%]
=================================== FAILURES ===================================
__________________________ test_get_score_difference ___________________________
mock_csv_data = ['Team,Games,Wins,Losses,Draws,Goals For,Goals Against', ...
def test_get_score_difference(mock_csv_data):
reader = fb.parse_next_line(mock_csv_data)
> team, diff = fb.get_name_and_diff(next(reader))
E AttributeError: module 'football_v1' has no attribute 'get_name_and ...
test_football_v1.py:38: AttributeError
=========================== short test summary info ============================
FAILED test_football_v1.py::test_get_score_difference - AttributeError: modul...
========================= 1 failed, 1 passed in 0.03s ==========================
现在测试已经就绪,看看get_name_and_diff()的实现。由于DictReader为您将 CSV 值放入字典中,您可以从每个字典中检索团队名称并计算目标差异:
# football_v1.py
def get_name_and_diff(team_stats):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
return team_stats["Team"], diff
您可以把它写成一行程序,但是把它分成几个清晰的字段可能会提高可读性。它还可以使调试这段代码变得更容易。如果你在面试中现场编码,这些都是很好的提点。表明你对可读性有所考虑会有所不同。
现在您已经实现了这个功能,您可以重新运行您的测试:
$ pytest test_football_v1.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 2 items
test_football_v1.py .F [100%]
=================================== FAILURES ===================================
__________________________ test_get_score_difference ___________________________
mock_csv_data = ['Team,Games,Wins,Losses,Draws,Goals For,Goals Against', ...
def test_get_score_difference(mock_csv_data):
reader = fb.parse_next_line(mock_csv_data)
assert fb.get_name_and_diff(next(reader)) == ("Liverpool FC", 52)
> assert fb.get_name_and_diff(next(reader)) == ("Norwich City FC", 49)
E AssertionError: assert ('Norwich City FC', -49) == ('Norwich City FC'...
E At index 1 diff: -49 != 49
E Use -v to get the full diff
test_football_v1.py:40: AssertionError
=========================== short test summary info ============================
FAILED test_football_v1.py::test_get_score_difference - AssertionError: asser...
========================= 1 failed, 1 passed in 0.07s ==========================
哎呦!这是不对的。该函数返回的差值不应为负。还好你写了测试!
您可以通过在返回值上使用 abs() 来更正:
# football_v1.py
def get_name_and_diff(team_stats):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
return team_stats["Team"], abs(diff)
你可以在函数的最后一行看到它现在调用了abs(diff),所以你不会得到负数的结果。现在用您的测试来尝试这个版本,看看它是否通过:
$ pytest test_football_v1.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 2 items
test_football_v1.py .. [100%]
============================== 2 passed in 0.01s ===============================
那好多了。如果你想找到净胜球差距最小的球队,你就需要差距的绝对值。
查找最小值
对于您的最后一块拼图,您需要一个函数,它使用您的生成器获取 CSV 文件的每一行,并使用您的函数返回每一行的球队名称和得分差异,然后找到这些差异的最小值。对此的测试是框架代码中给出的总体测试:
# test_football_v1.py
import pytest
import football_v1 as fb
# ...
def test_get_min_score(mock_csv_file):
assert fb.get_min_score_difference(mock_csv_file) == (
"Norwich City FC",
49,
)
您再次使用提供的 pytest fixtures,但是这一次您使用mock_csv_file fixture 来获取一个文件的文件名,该文件包含您到目前为止一直在使用的相同的测试数据集。该测试调用您的最终函数,并断言您手动计算的正确答案:诺维奇城队以 49 球的比分差距最小。
至此,您已经看到在被测试的函数实现之前测试失败了,所以您可以跳过这一步,直接跳到您的解决方案:
# football_v1.py
def get_min_score_difference(filename):
with open(filename, "r", newline="") as csv_file:
min_diff = 10000
min_team = None
for line in parse_next_line(csv_file):
team, diff = get_name_and_diff(line)
if diff < min_diff:
min_diff = diff
min_team = team
return min_team, min_diff
该函数使用上下文管理器打开给定的 CSV 文件进行读取。然后它设置min_diff和min_team变量,您将使用它们来跟踪您在遍历列表时找到的最小值。你在10000开始最小差异,这对于足球比分似乎是安全的。
然后,该函数遍历每一行,获取团队名称和差异,并找到差异的最小值。
当您针对测试运行此代码时,它会通过:
$ pytest test_football_v1.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 3 items
test_football_v1.py ... [100%]
============================== 3 passed in 0.03s ===============================
恭喜你!您已经找到了所述问题的解决方案!
一旦你做到了这一点,尤其是在面试的情况下,是时候检查你的解决方案,看看你是否能找出让代码更可读、更健壮或更 T2 的变化。这是您将在下一部分中执行的操作。
解决方案 2:重构解决方案 1
从整体上看一下你对这个问题的第一个解决方案:
# football_v1.py
import csv
def parse_next_line(csv_file):
for line in csv.DictReader(csv_file):
yield line
def get_name_and_diff(team_stats):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
return team_stats["Team"], abs(diff)
def get_min_score_difference(filename):
with open(filename, "r", newline="") as csv_file:
min_diff = 10000
min_team = None
for line in parse_next_line(csv_file):
team, diff = get_name_and_diff(line)
if diff < min_diff:
min_diff = diff
min_team = team
return min_team, min_diff
从整体上看这段代码,有一些事情需要注意。其中之一是get_name_and_diff()并没有做那么多。它只从字典中取出三个字段并减去。第一个函数parse_next_line()也相当短,似乎可以将这两个函数结合起来,让生成器只返回球队名称和分数差。
您可以将这两个函数重构为一个名为get_next_name_and_diff()的新函数。如果你跟随本教程,现在是一个很好的时机将football_v1.py复制到football_v2.py并对测试文件做类似的操作。坚持您的 TDD 过程,您将重用您的第一个解决方案的测试:
# test_football_v2.py
import pytest
import football_v2 as fb
# ...
def test_get_min_score(mock_csv_file):
assert fb.get_min_score_difference(mock_csv_file) == (
"Norwich City FC",
49,
)
def test_get_score_difference(mock_csv_data):
reader = fb.get_next_name_and_diff(mock_csv_data) assert next(reader) == ("Liverpool FC", 52) assert next(reader) == ("Norwich City FC", 49) with pytest.raises(StopIteration): next(reader)
第一个测试test_get_min_score()保持不变,因为它测试的是最高级别的功能,这是不变的。
其他两个测试函数合并成一个函数,将返回的项目数和返回值的测试合并成一个测试。它借助 Python 内置的next()直接使用从get_next_name_and_diff()返回的生成器。
下面是将这两个非测试函数放在一起时的样子:
# football_v2.py
import csv
def get_next_name_and_diff(csv_file):
for team_stats in csv.DictReader(csv_file):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
yield team_stats["Team"], abs(diff)
这个函数看起来确实像前面的函数挤在一起。它使用csv.DictReader(),而不是产生从每一行创建的字典,只产生团队名称和计算的差异。
虽然就可读性而言,这并不是一个巨大的改进,但它将允许您在剩余的函数中做一些其他的简化。
剩下的功能get_min_score_difference(),也有一定的改进空间。手动遍历列表以找到最小值是标准库提供的功能。幸运的是,这是顶级功能,所以您的测试不需要更改。
如上所述,您可以使用 min() 从标准库中找到列表或 iterable 中的最小项。“或可迭代”部分很重要。您的get_next_name_and_diff()生成器符合可迭代条件,因此min()将运行生成器并找到最小结果。
一个问题是get_next_name_and_diff()产生了(team_name, score_differential)个元组,并且您想要最小化差值。为了方便这个用例,min()有一个关键字参数,key。您可以提供一个函数,或者在您的情况下提供一个 lambda ,来指示它将使用哪些值来搜索最小值:
# football_v2.py
def get_min_score_difference(filename):
with open(filename, "r", newline="") as csv_data:
return min(get_next_name_and_diff(csv_data), key=lambda item: item[1])
这种变化将代码压缩成一个更小、更 Pythonic 化的函数。用于key的λ允许min()找到分数差的最小值。对新代码运行 pytest 表明,它仍然解决了上述问题:
$ pytest test_football_v2.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 3 items
test_football_v2.py ... [100%]
============================== 3 passed in 0.01s ===============================
以这种方式花时间检查和重构代码在日常编码中是一个很好的实践,但在面试环境中可能实用,也可能不实用。即使你觉得在面试中没有时间或精力来完全重构你的解决方案,花一点时间向面试官展示你的想法也是值得的。
当你在面试时,花一分钟指出,“这些功能很小——我可以合并它们,”或者,“如果我推动这个显式循环,那么我可以使用min()功能”,这将向面试官展示你知道这些事情。没有人在第一次尝试时就能得出最优解。
面试中另一个值得讨论的话题是边角案例。解决方案能处理坏的数据线吗?像这样的主题有助于很好的测试,并且可以在早期发现很多问题。有时候在面试中讨论这些问题就足够了,有时候回去重构你的测试和代码来处理这些问题是值得的。
你可能还想讨论问题的定义。特别是这个问题有一个不明确的规范。如果两个队有相同的差距,解决方案应该是什么?您在这里看到的解决方案选择了第一个,但也有可能返回全部,或者最后一个,或者其他一些决定。
这种类型的模糊性在实际项目中很常见,因此认识到这一点并将其作为一个主题提出来可能表明您正在思考超越代码解决方案的问题。
既然您已经使用 Python csv模块解决了一个问题,那么就用一个类似的问题再试一次。
Python CSV 解析:天气数据
你的第二个问题看起来和第一个很相似。使用类似的结构来解决它可能是个好主意。一旦你完成了这个问题的解决方案,你将会读到一些重构重用代码的想法,所以在工作中要记住这一点。
问题描述
这个问题涉及到解析 CSV 文件中的天气数据:
最高平均温度
编写一个程序,在命令行上输入文件名并处理 CSV 文件的内容。内容将是一个月的天气数据,每行一天。
您的程序应该确定哪一天的平均温度最高,其中平均温度是当天最高温度和最低温度的平均值。这通常不是计算平均温度的方法,但在这个演示中是可行的。
CSV 文件的第一行是列标题:
`Day,MaxT,MinT,AvDP,1HrP TPcn,PDir,AvSp,Dir,MxS,SkyC,MxR,Mn,R AvSLP 1,88,59,74,53.8,0,280,9.6,270,17,1.6,93,23,1004.5`日期、最高温度和最低温度是前三列。
用 pytest 编写单元测试来测试你的程序。
与足球比分问题一样,框架代码中提供了测试问题陈述的单元测试:
# test_weather_v1.py
import pytest
import weather_v1 as wthr
@pytest.fixture
def mock_csv_data():
return [
"Day,MxT,MnT,AvT,AvDP,1HrP TPcn,PDir,AvSp,Dir,MxS,SkyC,MxR,Mn,R AvSLP",
"1,88,59,74,53.8,0,280,9.6,270,17,1.6,93,23,1004.5",
"2,79,63,71,46.5,0,330,8.7,340,23,3.3,70,28,1004.5",
]
@pytest.fixture
def mock_csv_file(tmp_path, mock_csv_data):
datafile = tmp_path / "weather.csv"
datafile.write_text("\n".join(mock_csv_data))
return str(datafile)
再次注意,给出了两个装置。第一个提供模拟真实 CSV 数据的字符串列表,第二个提供由测试数据支持的文件名。字符串列表中的每个字符串代表测试文件中的一行。
请记住,所提供的装置只是一个开始。在设计解决方案的每个部分时添加测试!
问题解决方案
这里讨论一下真正的 Python 团队达成了什么。
**注意:**记住,在你准备好查看这个 Python 练习题的答案之前,不要打开下面折叠的部分!
您将在这里看到的解决方案与前面的解决方案非常相似。您看到了上面略有不同的一组测试数据。这两个测试函数基本上与足球解决方案相同:
# test_weather_v1.py
import pytest
import weather_v1 as wthr
# ...
def test_get_max_avg(mock_csv_file):
assert wthr.get_max_avg(mock_csv_file) == (1, 73.5)
def test_get_next_day_and_avg(mock_csv_data):
reader = wthr.get_next_day_and_avg(mock_csv_data)
assert next(reader) == (1, 73.5)
assert next(reader) == (2, 71)
with pytest.raises(StopIteration):
next(reader)
虽然这些测试是好的,但是当你更多地思考问题并在你的解决方案中发现 bug 时,添加新的测试也是好的。这里有一些新的测试,涵盖了你在上一个问题结束时想到的一些极限情况:
# test_weather_v1.py
import pytest
import weather_v1 as wthr
# ...
def test_no_lines():
no_data = []
for _ in wthr.get_next_day_and_avg(no_data):
assert False
def test_trailing_blank_lines(mock_csv_data):
mock_csv_data.append("")
all_lines = [x for x in wthr.get_next_day_and_avg(mock_csv_data)]
assert len(all_lines) == 2
for line in all_lines:
assert len(line) == 2
def test_mid_blank_lines(mock_csv_data):
mock_csv_data.insert(1, "")
all_lines = [x for x in wthr.get_next_day_and_avg(mock_csv_data)]
assert len(all_lines) == 2
for line in all_lines:
assert len(line) == 2
这些测试包括传入空文件的情况,以及 CSV 文件中间或结尾有空行的情况。文件的第一行有坏数据的情况更有挑战性。如果第一行不包含标签,数据是否仍然满足问题的要求?真正的 Python 解决方案假定这是无效的,并且不对其进行测试。
对于这个问题,代码本身不需要做太大的改动。和以前一样,如果你正在你的机器上处理这些解决方案,现在是复制football_v2.py到weather_v1.py的好时机。
如果您从足球解决方案开始,那么生成器函数被重命名为get_next_day_and_avg(),调用它的函数现在是get_max_avg():
# weather_v1.py
import csv
def get_next_day_and_avg(csv_file):
for day_stats in csv.DictReader(csv_file):
day_number = int(day_stats["Day"])
avg = (int(day_stats["MxT"]) + int(day_stats["MnT"])) / 2
yield day_number, avg
def get_max_avg(filename):
with open(filename, "r", newline="") as csv_file:
return max(get_next_day_and_avg(csv_file), key=lambda item: item[1])
在这种情况下,你稍微改变一下get_next_day_and_avg()。您现在得到的是一个代表天数并计算平均温度的整数,而不是团队名称和分数差。
调用get_next_day_and_avg()的函数已经改为使用 max() 而不是min(),但仍然保持相同的结构。
针对这段代码运行新的测试显示了使用标准库中的工具的优势:
$ pytest test_weather_v1.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 5 items
test_weather_v1.py ..... [100%]
============================== 5 passed in 0.05s ===============================
新函数通过了您添加的新空行测试。那个人会帮你处理那些案子。您的测试运行没有错误,您有一个伟大的解决方案!
在面试中,讨论你的解决方案的性能可能是好的。对于这里的框架代码提供的小数据文件,速度和内存使用方面的性能并不重要。但是如果天气数据是上个世纪的每日报告呢?这个解决方案会遇到内存问题吗?有没有办法通过重新设计解决方案来解决这些问题?
到目前为止,这两种解决方案具有相似的结构。在下一节中,您将看到重构这些解决方案,以及如何在它们之间共享代码。
Python CSV 解析:重构
到目前为止,您看到的两个问题非常相似,解决它们的程序也非常相似。一个有趣的面试问题可能是要求你重构这两个解决方案,找到一种共享代码的方法,使它们更易于维护。
问题描述
这个问题和前面两个有点不同。对于本节,从前面的问题中提取解决方案,并对它们进行重构,以重用常见的代码和结构。在现实世界中,这些解决方案足够小,以至于这里的重构工作可能不值得,但它确实是一个很好的思考练习。
问题解决方案
这是真正的 Python 团队完成的重构。
**注意:**记住,在你准备好查看这个 Python 练习题的答案之前,不要打开下面折叠的部分!
从查看这两个问题的解决方案代码开始。不算测试,足球解决方案有两个函数长:
# football_v2.py
import csv
def get_next_name_and_diff(csv_file):
for team_stats in csv.DictReader(csv_file):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
yield team_stats["Team"], abs(diff)
def get_min_score_difference(filename):
with open(filename, "r", newline="") as csv_data:
return min(get_next_name_and_diff(csv_data), key=lambda item: item[1])
类似地,平均温度解由两个函数组成。相似的结构指出了需要重构的领域:
# weather_v1.py
import csv
def get_next_day_and_avg(csv_file):
for day_stats in csv.DictReader(csv_file):
day_number = int(day_stats["Day"])
avg = (int(day_stats["MxT"]) + int(day_stats["MnT"])) / 2
yield day_number, avg
def get_max_avg(filename):
with open(filename, "r", newline="") as csv_file:
return max(get_next_day_and_avg(csv_file), key=lambda item: item[1])
在比较代码时,有时使用diff工具来比较每个代码的文本是很有用的。不过,您可能需要从文件中删除额外的代码来获得准确的图片。在这种情况下,文件字符串被删除。当你diff这两个解决方案时,你会发现它们非常相似:
--- football_v2.py 2021-02-09 19:22:05.653628190 -0700 +++ weather_v1.py 2021-02-09 19:22:16.769811115 -0700 @@ -1,9 +1,10 @@ -def get_next_name_and_diff(csv_file): - for team_stats in csv.DictReader(csv_file): - diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"]) - yield team_stats["Team"], abs(diff) +def get_next_day_and_avg(csv_file): + for day_stats in csv.DictReader(csv_file): + day_number = int(day_stats["Day"]) + avg = (int(day_stats["MxT"]) + int(day_stats["MnT"])) / 2 + yield day_number, avg -def get_min_score_difference(filename): - with open(filename, "r", newline="") as csv_data: - return min(get_next_name_and_diff(csv_data), key=lambda item: item[1]) +def get_max_avg(filename): + with open(filename, "r", newline="") as csv_file: + return max(get_next_day_and_avg(csv_file), key=lambda item: item[1])
除了函数和变量的名称,还有两个主要区别:
- 足球解得出
Goals For和Goals Against的差值,而天气解得出MxT和MnT的平均值。 - 足球解决方案找到结果的
min(),而天气解决方案使用max()。
第二个区别可能不值得讨论,所以让我们从第一个开始。
这两个发生器功能在结构上是相同的。不同的部分通常可以描述为“获取一行数据并从中返回两个值”,这听起来像一个函数定义。
如果你重新编写足球解决方案来实现这个功能,它会让程序变得更长:
# football_v3.py
import csv
def get_name_and_diff(team_stats):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
return team_stats["Team"], abs(diff)
def get_next_name_and_diff(csv_file):
for team_stats in csv.DictReader(csv_file):
yield get_name_and_diff(team_stats)
虽然这段代码比较长,但它提出了一些有趣的观点,值得在采访中讨论。有时候当你重构时,让代码更易读会导致代码更长。这里的情况可能不是这样,因为很难说将这个函数分离出来会使代码更具可读性。
然而,还有另外一点。有时为了重构代码,您必须降低代码的可读性或简洁性,以使公共部分可见。这绝对是你要去的地方。
最后,这是一个讨论单一责任原则的机会。在高层次上,单一责任原则声明您希望代码的每一部分,一个类,一个方法,或者一个函数,只做一件事情或者只有一个责任。在上面的重构中,您将从每行数据中提取值的职责从负责迭代csv.DictReader()的函数中抽出。
如果你回头看看你在上面足球问题的解决方案 1 和解决方案 2 之间所做的重构,你会看到最初的重构将parse_next_line()和get_name_and_diff()合并成了一个函数。在这个重构中,你把它们拉了回来!乍一看,这似乎是矛盾的,因此值得更仔细地研究。
在第一次重构中,合并两个功能很容易被称为违反单一责任原则。在这种情况下,在拥有两个只能一起工作的小函数和将它们合并成一个仍然很小的函数之间有一个可读性权衡。在这种情况下,合并它们似乎使代码更具可读性,尽管这是主观的。
在这种情况下,您出于不同的原因将这两个功能分开。这里的分裂不是最终目标,而是通往你目标的一步。通过将功能一分为二,您能够在两个解决方案之间隔离和共享公共代码。
对于这样一个小例子,这种分割可能是不合理的。然而,正如您将在下面看到的,它允许您有更多的机会共享代码。这种技术将一个功能块从一个函数中提取出来,放入一个独立的函数中,通常被称为提取方法技术。一些ide 和代码编辑器提供工具来帮助你完成这个操作。
此时,您还没有获得任何东西,下一步将使代码稍微复杂一些。你将把get_name_and_diff()传递给生成器。乍一看,这似乎违反直觉,但它将允许您重用生成器结构:
# football_v4.py
import csv
def get_name_and_diff(team_stats):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
return team_stats["Team"], abs(diff)
def get_next_name_and_diff(csv_file, func):
for team_stats in csv.DictReader(csv_file):
yield func(team_stats)
def get_min_score_difference(filename):
with open(filename, "r", newline="") as csv_data:
return min( get_next_name_and_diff(csv_data, get_name_and_diff), key=lambda item: item[1], )
这看起来像是一种浪费,但是有时候重构是一个将解决方案分解成小块以隔离不同部分的过程。尝试对天气解决方案进行同样的更改:
# weather_v2.py
import csv
def get_day_and_avg(day_stats):
day_number = int(day_stats["Day"])
avg = (int(day_stats["MxT"]) + int(day_stats["MnT"])) / 2
return day_number, avg
def get_next_day_and_avg(csv_file, func):
for day_stats in csv.DictReader(csv_file):
yield func(day_stats)
def get_max_avg(filename):
with open(filename, "r", newline="") as csv_file:
return max(
get_next_day_and_avg(csv_file, get_day_and_avg),
key=lambda item: item[1],
)
这使得两个解决方案看起来更加相似,更重要的是,突出了两者之间的不同之处。现在,两种解决方案之间的差异主要包含在传入的函数中:
--- football_v4.py 2021-02-20 16:05:53.775322250 -0700 +++ weather_v2.py 2021-02-20 16:06:04.771459061 -0700 @@ -1,19 +1,20 @@ import csv -def get_name_and_diff(team_stats): - diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"]) - return team_stats["Team"], abs(diff) +def get_day_and_avg(day_stats): + day_number = int(day_stats["Day"]) + avg = (int(day_stats["MxT"]) + int(day_stats["MnT"])) / 2 + return day_number, avg -def get_next_name_and_diff(csv_file, func): - for team_stats in csv.DictReader(csv_file): - yield func(team_stats) +def get_next_day_and_avg(csv_file, func): + for day_stats in csv.DictReader(csv_file): + yield func(day_stats) -def get_min_score_difference(filename): - with open(filename, "r", newline="") as csv_data: - return min( - get_next_name_and_diff(csv_data, get_name_and_diff), +def get_max_avg(filename): + with open(filename, "r", newline="") as csv_file: + return max( + get_next_day_and_avg(csv_file, get_day_and_avg), key=lambda item: item[1], )
一旦到了这一步,您可以将生成器函数重命名为更通用的名称。您还可以将它移动到自己的模块中,这样您就可以在两个解决方案中重用该代码:
# csv_parser.py
import csv
def get_next_result(csv_file, func):
for stats in csv.DictReader(csv_file):
yield func(stats)
现在您可以重构每个解决方案来使用这个公共代码。这是足球解决方案的重构版本:
# football_final.py
import csv_reader
def get_name_and_diff(team_stats):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
return team_stats["Team"], abs(diff)
def get_min_score_difference(filename):
with open(filename, "r", newline="") as csv_data:
return min(
csv_reader.get_next_result(csv_data, get_name_and_diff),
key=lambda item: item[1],
)
天气解决方案的最终版本虽然相似,但在问题需要的地方有所不同:
# weather_final.py
import csv_parser
def get_name_and_avg(day_stats):
day_number = int(day_stats["Day"])
avg = (int(day_stats["MxT"]) + int(day_stats["MnT"])) / 2
return day_number, avg
def get_max_avg(filename):
with open(filename, "r", newline="") as csv_file:
return max(
csv_parser.get_next_result(csv_file, get_name_and_avg),
key=lambda item: item[1],
)
您编写的单元测试可以被拆分,这样它们可以分别测试每个模块。
虽然这种特殊的重构导致了更少的代码,但是思考一下——并且在面试的情况下,讨论一下——这是否是一个好主意是有好处的。对于这一组特殊的解决方案,它可能不是。这里共享的代码大约有十行,而这些行只使用了两次。此外,这两个问题总体上相当不相关,这使得组合解决方案有点不太明智。
然而,如果你必须做四十个符合这个模型的操作,那么这种类型的重构可能是有益的。或者,如果你分享的生成器函数很复杂,很难得到正确的结果,那么它也将是一个更大的胜利。
这些都是面试时讨论的好话题。然而,对于像这样的问题集,您可能想讨论处理 CSV 文件时最常用的包:pandas。你现在会看到的。
Python CSV 解析:熊猫
到目前为止,您在解决方案中使用了标准库中的csv.DictReader类,这对于这些相对较小的问题来说效果很好。
对于更大的问题, pandas 包可以以极好的速度提供很好的结果。你的最后一个挑战是用熊猫重写上面的足球程序。
问题描述
这是本教程的最后一个问题。对于这个问题,你将使用熊猫重写足球问题的解决方案。pandas 解决方案看起来可能与只使用标准库的解决方案不同。
问题解决方案
这里讨论了团队达成的解决方案以及他们是如何达成的。
**注意:**记住,在您准备好查看每个 Python 练习问题的答案之前,不要打开下面折叠的部分!
这个 pandas 解决方案的结构不同于标准库解决方案。不使用生成器,而是使用 pandas 来解析文件并创建一个数据帧。
由于这种差异,您的测试看起来相似,但略有不同:
# test_football_pandas.py
import pytest
import football_pandas as fb
@pytest.fixture
def mock_csv_file(tmp_path):
mock_csv_data = [
"Team,Games,Wins,Losses,Draws,Goals For,Goals Against",
"Liverpool FC, 38, 32, 3, 3, 85, 33",
"Norwich City FC, 38, 5, 27, 6, 26, 75",
]
datafile = tmp_path / "football.csv"
datafile.write_text("\n".join(mock_csv_data))
return str(datafile)
def test_read_data(mock_csv_file):
df = fb.read_data(mock_csv_file)
rows, cols = df.shape
assert rows == 2
# The dataframe df has all seven of the cols in the original dataset plus
# the goal_difference col added in read_data().
assert cols == 8
def test_score_difference(mock_csv_file):
df = fb.read_data(mock_csv_file)
assert df.team_name[0] == "Liverpool FC"
assert df.goal_difference[0] == 52
assert df.team_name[1] == "Norwich City FC"
assert df.goal_difference[1] == 49
def test_get_min_diff(mock_csv_file):
df = fb.read_data(mock_csv_file)
diff = fb.get_min_difference(df)
assert diff == 49
def test_get_team_name(mock_csv_file):
df = fb.read_data(mock_csv_file)
assert fb.get_team(df, 49) == "Norwich City FC"
assert fb.get_team(df, 52) == "Liverpool FC"
def test_get_min_score(mock_csv_file):
assert fb.get_min_score_difference(mock_csv_file) == (
"Norwich City FC",
49,
)
这些测试包括三个动作:
- 读取文件并创建数据帧
- 求最小微分
- 找到与最小值相对应的队名
这些测试与第一个问题中的测试非常相似,所以与其详细检查测试,不如关注解决方案代码,看看它是如何工作的。您将从一个名为read_data()的函数开始创建数据帧:
1# football_pandas.py
2import pandas as pd
3
4def read_data(csv_file):
5 return (
6 pd.read_csv(csv_file)
7 .rename(
8 columns={
9 "Team": "team_name",
10 "Goals For": "goals",
11 "Goals Against": "goals_allowed",
12 }
13 )
14 .assign(goal_difference=lambda df: abs(df.goals - df.goals_allowed))
15 )
哇!这是一行函数的一堆代码。像这样将方法调用链接在一起被称为使用流畅接口,这在处理 pandas 时相当常见。一个数据帧上的每个方法返回一个DataFrame对象,所以你可以将方法调用链接在一起。
理解这样的代码的关键是,如果它跨越多行,从左到右、从上到下地理解它。
在这种情况下,从第 6 行的 pd.read_csv() 开始,它读取 CSV 文件并返回初始的DataFrame对象。
第 7 行的下一步是在返回的数据帧上调用 .rename() 。这将把数据帧的列重命名为将作为属性工作的名称。你关心的三个栏目改名为team_name、goals、goals_allowed。一会儿你会看到如何访问它们。
从.rename()返回的值是一个新的 DataFrame,在第 14 行,您调用它的 .assign() 来添加一个新列。该列将被称为goal_difference,并且您提供一个 lambda 函数来为每一行计算它。同样,.assign()返回它被调用的DataFrame对象,该对象用于该函数的返回值。
注意: pandas 为您将在这个解决方案中使用的每个列名提供了属性。这产生了良好的、可读的结果。然而,它确实有一个潜在的陷阱。
如果属性名与 pandas 中的 DataFrame 方法冲突,命名冲突可能会导致意外的行为。如果您有疑问,您可以随时使用 .loc[] 来访问列值。
您的解决方案中的下一个函数展示了一些神奇熊猫可以提供的功能。利用 pandas 将整个列作为一个对象进行寻址并在其上调用方法的能力。在这个实例中,您调用 .min() 来查找该列的最小值:
# football_pandas.py
def get_min_difference(parsed_data):
return parsed_data.goal_difference.min()
熊猫提供了几个类似于.min()的功能,可以让你快速有效地操纵行和列。
你的解决方案的下一部分是找到与最小分数差相对应的队名。get_team()再次使用流畅的编程风格将单个数据帧上的多个调用链接在一起:
# football_pandas.py
def get_team(parsed_data, min_score_difference):
return (
parsed_data.query(f"goal_difference == {min_score_difference}")
.reset_index()
.loc[0, "team_name"]
)
在这个函数中,您调用 .query() ,指定您想要的行中的goal_difference列等于您之前找到的最小值。从.query()返回的值是一个新的 DataFrame,具有相同的列,但只有那些匹配查询的行。
由于 pandas 管理查询索引的一些内部机制,需要下一个调用 .reset_index() ,以便于访问这个新数据帧的第一行。一旦索引被重置,您调用.loc[]来获取行0和team_name列,这将从第一行返回匹配最小分数差的球队名称。
最后,您需要一个函数将所有这些放在一起,并返回球队名称和最小差异。和这个问题的其他解决方案一样,这个函数叫做get_min_score_difference():
# football_pandas.py
def get_min_score_difference(csv_file):
df = read_data(csv_file)
min_diff = get_min_difference(df)
team = get_team(df, min_diff)
return team, min_diff
这个函数使用前面的三个函数将团队名称和最小差异放在一起。
这就完成了你的熊猫版足球节目。它看起来不同于其他两种解决方案:
# football_pandas.py
import pandas as pd
def read_data(csv_file):
return (
pd.read_csv(csv_file)
.rename(
columns={
"Team": "team_name",
"Goals For": "goals",
"Goals Against": "goals_allowed",
}
)
.assign(goal_difference=lambda df: abs(df.goals - df.goals_allowed))
)
def get_min_difference(parsed_data):
return parsed_data.goal_difference.min()
def get_team(parsed_data, min_score_difference):
return (
parsed_data.query(f"goal_difference == {min_score_difference}")
.reset_index()
.loc[0, "team_name"]
)
def get_min_score_difference(csv_file):
df = read_data(csv_file)
min_diff = get_min_difference(df)
team = get_team(df, min_diff)
return team, min_diff
既然你已经看到了一个基于熊猫的解决方案,思考一下这个解决方案比你看到的其他解决方案更好或更差是一个好主意。这种类型的讨论可以在面试中提出来。
这里的 pandas 解决方案比标准库版本稍长,但是如果目标是这样的话,当然可以缩短。对于像这样的小问题来说,熊猫可能有点小题大做了。然而,对于更大、更复杂的问题,花费额外的时间和复杂性引入 pandas 可以节省大量的编码工作,并且比直接使用 CSV 库更快地提供解决方案。
这里要讨论的另一个角度是,你正在进行的项目是否有或被允许有外部依赖性。在一些项目中,引入熊猫这样的额外项目可能需要大量的政治或技术工作。在这种情况下,标准库解决方案会更好。
结论
这一套 Python CSV 解析练习题到此结束!您已经练习了如何将 Python 技能应用于 CSV 文件,并且还花了一些时间来思考可以在面试中讨论的折衷方案。然后,您查看了重构解决方案,既从单个问题的角度,也从两个解决方案中重构公共代码的角度。
除了解决这些问题,你还学了:
- 用
csv.DictReader()类编写代码 - 利用熊猫解决 CSV 问题
- 在面试中讨论你的解决方案
- 谈论设计决策和权衡
现在,您已经准备好面对 Python CSV 解析问题,并在采访中讨论它了!如果您有任何问题或者对其他 Python 实践问题有任何建议,请随时在下面的评论区联系我们。祝你面试好运!
请记住,您可以通过单击下面的链接下载这些问题的框架代码:
获取源代码: 单击此处获取源代码,您将在本教程中使用来练习解析 CSV 文件。***


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









