







原文:RealPython
Python heapq 模块:使用堆和优先级队列
堆和优先级队列是鲜为人知但非常有用的数据结构。对于许多涉及在数据集中寻找最佳元素的问题,它们提供了一个易于使用且高效的解决方案。Python heapq模块是标准库的一部分。它实现了所有的低级堆操作,以及堆的一些高级公共用途。
一个优先级队列是一个强大的工具,可以解决各种各样的问题,如编写电子邮件调度程序、在地图上寻找最短路径或合并日志文件。编程充满了优化问题,目标是找到最佳元素。优先级队列和 Python heapq模块中的函数通常可以对此有所帮助。
在本教程中,您将学习:
- 什么是堆和优先级队列以及它们之间的关系
- 使用堆可以解决什么样的问题
- 如何使用 Python
heapq模块解决那些问题
本教程是为那些熟悉列表、字典、集合和生成器并且正在寻找更复杂的数据结构的 python 们准备的。
您可以通过从下面的链接下载源代码来学习本教程中的示例:
获取源代码: 点击此处获取源代码,您将使用在本教程中了解 Python heapq 模块。
什么是堆?
堆是具体的数据结构,而优先级队列是抽象的数据结构。抽象的数据结构决定了接口,而具体的数据结构定义了实现。
堆通常用于实现优先级队列。它们是实现优先级队列抽象数据结构的最流行的具体数据结构。
具体的数据结构也规定了性能保证。性能保证定义了结构的大小和操作花费的时间之间的关系。理解这些保证可以让您预测当输入的大小改变时程序将花费多少时间。
数据结构、堆和优先级队列
抽象数据结构规定了操作和它们之间的关系。例如,优先级队列抽象数据结构支持三种操作:
- is_empty 检查队列是否为空。
- add_element 向队列中添加一个元素。
- pop_element 弹出优先级最高的元素。
优先级队列通常用于优化任务执行,目标是处理优先级最高的任务。任务完成后,它的优先级降低,并返回到队列中。
确定元素的优先级有两种不同的约定:
- 最大的元素具有最高的优先级。
- 最小的元素具有最高的优先级。
这两个约定是等价的,因为您总是可以颠倒有效顺序。例如,如果你的元素由数字组成,那么使用负数将会颠倒约定。
Python heapq模块使用第二种约定,这通常是两种约定中更常见的一种。在这个约定下,最小的元素具有最高的优先级。这听起来可能令人惊讶,但它通常非常有用。在您稍后将看到的真实例子中,这种约定将简化您的代码。
**注意:**Pythonheapq模块,以及一般的堆数据结构不是设计来允许查找除最小元素之外的任何元素。对于按大小检索任何元素,更好的选择是二叉查找树。
具体数据结构实现抽象数据结构中定义的操作,并进一步指定性能保证。
优先级队列的堆实现保证了推送(添加)和弹出(移除)元素都是对数时间操作。这意味着做 push 和 pop 所需的时间与元素数量的以 2 为底的对数成正比**。**
对数增长缓慢。以 15 为底的对数大约是 4,而以 1 万亿为底的对数大约是 40。这意味着,如果一个算法在 15 个元素上足够快,那么它在 1 万亿个元素上只会慢 10 倍,而且可能仍然足够快。
在任何关于性能的讨论中,最大的警告是这些抽象的考虑比实际测量一个具体的程序和了解瓶颈在哪里更没有意义。一般的性能保证对于对程序行为做出有用的预测仍然很重要,但是这些预测应该得到证实。
堆的实现
堆将优先级队列实现为完整二叉树。在二叉树中,每个节点最多有两个子节点。在一棵完全二叉树中,除了可能是最深的一层之外,所有层在任何时候都是满的。如果最深层次是不完整的,那么它的节点将尽可能地靠左。
完整性属性意味着树的深度是元素数量的以 2 为底的对数,向上取整。下面是一个完整二叉树的例子:

在这个特殊的例子中,所有级别都是完整的。除了最深的节点之外,每个节点正好有两个子节点。三个级别总共有七个节点。3 是 7 的以 2 为底的对数,向上取整。
基层的单个节点被称为根节点。将树顶端的节点称为根可能看起来很奇怪,但这是编程和计算机科学中的常见约定。
堆中的性能保证取决于元素如何在树中上下渗透。这样做的实际结果是,堆中的比较次数是树大小的以 2 为底的对数。
**注意:**比较有时涉及到使用.__lt__()调用用户定义的代码。与在堆中进行的其他操作相比,在 Python 中调用用户定义的方法是一个相对较慢的操作,因此这通常会成为瓶颈。
在堆树中,一个节点中的值总是小于它的两个子节点。这被称为堆属性。这与二叉查找树不同,在后者中,只有左边的节点将小于其父节点的值。
推送和弹出的算法都依赖于临时违反堆属性,然后通过比较和替换单个分支上下来修复堆属性。
例如,为了将一个元素推到一个堆上,Python 会将新节点添加到下一个打开的槽中。如果底层未满,则该节点将被添加到底部的下一个空槽中。否则,创建一个新级别,然后将元素添加到新的底层。
添加节点后,Python 会将其与其父节点进行比较。如果违反了堆属性,则交换节点及其父节点,并从父节点重新开始检查。这种情况一直持续到堆属性成立或到达根为止。
类似地,当弹出最小的元素时,Python 知道,由于堆属性,该元素位于树的根。它用最深层的最后一个元素替换该元素,然后检查是否违反了分支的堆属性。
优先级队列的使用
优先级队列,以及作为优先级队列实现的堆,对于需要寻找某种极端元素的程序非常有用。例如,您可以将优先级队列用于以下任何任务:
- 从 hit data 中获取三个最受欢迎的博客帖子
- 寻找从一个地方到另一个地方的最快方法
- 基于到达频率预测哪辆公共汽车将首先到达车站
您可以使用优先级队列的另一个任务是安排电子邮件。想象一下,一个系统有几种电子邮件,每种邮件都需要以一定的频率发送。一种邮件需要每十五分钟发出一次,另一种需要每四十分钟发出一次。
调度程序可以将这两种类型的电子邮件添加到队列中,并带有一个时间戳来指示下一次需要发送电子邮件的时间。然后,调度程序可以查看时间戳最小的元素——表明它是下一个要发送的元素——并计算发送前要休眠多长时间。
当调度程序唤醒时,它将处理相关的电子邮件,将电子邮件从优先级队列中取出,计算下一个时间戳,并将电子邮件放回队列中的正确位置。
Python heapq模块中作为列表的堆
尽管您看到了前面描述的树型堆,但重要的是要记住它是一棵完整的二叉树。完整性意味着除了最后一层,总是可以知道每一层有多少元素。因此,堆可以作为一个列表来实现。这就是 Python heapq模块所做的事情。
有三个规则确定索引k处的元素与其周围元素之间的关系:
- 它的第一个孩子在
2*k + 1。 - 它的第二个孩子在
2*k + 2。 - 它的父节点在
(k - 1) // 2。
注://符号是整数除法运算符。它总是向下舍入到整数。
上面的规则告诉你如何将一个列表可视化为一个完整的二叉树。请记住,元素总是有父元素,但有些元素没有子元素。如果2*k超出了列表的末尾,那么该元素没有任何子元素。如果2*k + 1是一个有效的索引,而2*k + 2不是,那么这个元素只有一个子元素。
heap 属性意味着如果h是一个堆,那么下面的永远不会是False:
h[k] <= h[2*k + 1] and h[k] <= h[2*k + 2]
如果任何索引超出了列表的长度,它可能会引发一个IndexError,但它永远不会是False。
换句话说,一个元素必须总是小于两倍于其索引加 1 和两倍于其索引加 2 的元素。
下面是一个满足堆属性的列表:

箭头从元素k指向元素2*k + 1和2*k + 2。例如,Python 列表中的第一个元素有索引0,所以它的两个箭头指向索引1和2。注意箭头总是从较小的值到较大的值。这是检查列表是否满足堆属性的方法。
基本操作
Python heapq模块实现了对列表的堆操作。与许多其他模块不同,它没有而不是定义一个自定义类。Python heapq模块有直接作用于列表的函数。
通常,就像上面的电子邮件示例一样,元素将从一个空堆开始,一个接一个地插入到一个堆中。然而,如果已经有一个需要成为堆的元素列表,那么 Python heapq模块包含了用于将列表转换成有效堆的heapify()。
下面的代码使用heapify()将a变成堆:
>>> import heapq
>>> a = [3, 5, 1, 2, 6, 8, 7]
>>> heapq.heapify(a)
>>> a
[1, 2, 3, 5, 6, 8, 7]
你可以检查一下,即使7在8之后,列表a仍然服从堆属性。比如a[2],也就是3,小于a[2*2 + 2],也就是7。
如您所见,heapify()就地修改了列表,但没有对其进行排序。堆不一定要排序才能满足堆属性。然而,因为每个排序列表都满足堆属性,所以在排序列表上运行heapify()不会改变列表中元素的顺序。
Python heapq模块中的其他基本操作假设列表已经是一个堆。值得注意的是,空列表或长度为 1 的列表总是堆。
因为树根是第一个元素,所以不需要专门的函数来非破坏性地读取最小的元素。第一个元素a[0],永远是最小的元素。
为了在保留堆属性的同时弹出最小的元素,Python heapq模块定义了heappop()。
下面是如何使用heappop()弹出一个元素:
>>> import heapq
>>> a = [1, 2, 3, 5, 6, 8, 7]
>>> heapq.heappop(a)
1
>>> a
[2, 5, 3, 7, 6, 8]
该函数返回第一个元素1,并保留a上的堆属性。比如a[1]是5,a[1*2 + 2]是6。
Python heapq模块还包括heappush(),用于将元素推送到堆中,同时保留堆属性。
以下示例显示了将值推送到堆中:
>>> import heapq
>>> a = [2, 5, 3, 7, 6, 8]
>>> heapq.heappush(a, 4)
>>> a
[2, 5, 3, 7, 6, 8, 4]
>>> heapq.heappop(a)
2
>>> heapq.heappop(a)
3
>>> heapq.heappop(a)
4
将4推到堆中后,从堆中取出三个元素。因为2和3已经在堆中,并且比4小,所以它们先被弹出。
Python heapq模块还定义了另外两个操作:
heapreplace()相当于heappop()后跟heappush()。heappushpop()相当于heappush()后跟heappop()。
这些在一些算法中是有用的,因为它们比分别做这两个操作更有效。
高层操作
由于优先级队列经常用于合并排序后的序列,Python heapq模块有一个现成的函数merge(),用于使用堆来合并几个可重复项。merge()假设它的输入 iterables 已经排序,并返回一个迭代器,而不是一个列表。
作为使用merge()的一个例子,这里有一个前面描述的电子邮件调度器的实现:
import datetime
import heapq
def email(frequency, details):
current = datetime.datetime.now()
while True:
current += frequency
yield current, details
fast_email = email(datetime.timedelta(minutes=15), "fast email")
slow_email = email(datetime.timedelta(minutes=40), "slow email")
unified = heapq.merge(fast_email, slow_email)
本例中merge()的输入是无限发电机。赋给变量 unified的返回值也是无限迭代器。这个迭代器将按照未来时间戳的顺序产生要发送的电子邮件。
为了调试并确认代码正确合并,您可以打印要发送的前十封电子邮件:
>>> for _ in range(10):
... print(next(element))
(datetime.datetime(2020, 4, 12, 21, 27, 20, 305358), 'fast email')
(datetime.datetime(2020, 4, 12, 21, 42, 20, 305358), 'fast email')
(datetime.datetime(2020, 4, 12, 21, 52, 20, 305360), 'slow email')
(datetime.datetime(2020, 4, 12, 21, 57, 20, 305358), 'fast email')
(datetime.datetime(2020, 4, 12, 22, 12, 20, 305358), 'fast email')
(datetime.datetime(2020, 4, 12, 22, 27, 20, 305358), 'fast email')
(datetime.datetime(2020, 4, 12, 22, 32, 20, 305360), 'slow email')
(datetime.datetime(2020, 4, 12, 22, 42, 20, 305358), 'fast email')
(datetime.datetime(2020, 4, 12, 22, 57, 20, 305358), 'fast email')
(datetime.datetime(2020, 4, 12, 23, 12, 20, 305358), 'fast email')
请注意fast email是如何每隔15分钟安排一次的,slow email是如何每隔40安排一次的,并且电子邮件被适当地交错,以便它们按照时间戳的顺序排列。
不读取所有输入,而是动态工作。即使两个输入都是无限迭代器,打印前十项也会很快完成。
类似地,当用于合并排序后的序列时,比如按时间戳排列的日志文件行,即使日志很大,也会占用合理的内存量。
堆可以解决的问题
正如你在上面看到的,堆对于递增合并排序的序列是很好的。您已经考虑过的堆的两个应用是调度周期性任务和合并日志文件。然而,还有更多的应用。
堆还可以帮助识别顶部的 T2 或底部的 T4。Python heapq模块有实现这种行为的高级函数。
例如,该代码从 2016 年夏季奥运会的女子 100 米决赛中获取时间作为输入,并打印奖牌获得者或前三名:
>>> import heapq
>>> results="""\
... Christania Williams 11.80
... Marie-Josee Ta Lou 10.86
... Elaine Thompson 10.71
... Tori Bowie 10.83
... Shelly-Ann Fraser-Pryce 10.86
... English Gardner 10.94
... Michelle-Lee Ahye 10.92
... Dafne Schippers 10.90
... """
>>> top_3 = heapq.nsmallest(
... 3, results.splitlines(), key=lambda x: float(x.split()[-1])
... )
>>> print("\n".join(top_3))
Elaine Thompson 10.71
Tori Bowie 10.83
Marie-Josee Ta Lou 10.86
这段代码使用了 Python heapq模块中的nsmallest()。nsmallest()返回 iterable 中的最小元素,并接受三个参数:
n表示返回多少个元素。iterable标识要比较的元素或数据集。key是一个决定如何比较元素的可调用函数。
在这里,key函数通过空格分割该行,获取最后一个元素,并将其转换为一个浮点数。这意味着代码将根据运行时间对行进行排序,并返回运行时间最短的三行。这些对应于三个跑得最快的人,这给了你金牌,银牌和铜牌获得者。
Python heapq模块还包括nlargest(),它有类似的参数,返回最大的元素。这将是有用的,如果你想从标枪比赛中获得奖牌,其中的目标是投掷标枪尽可能远。
如何识别问题
作为优先级队列的实现,堆是解决极端问题的好工具,比如给定指标的最大值或最小值。
还有其他词语表明堆可能有用:
- 最大的
- 最小的
- 最大的
- 最小的
- 最好的
- 最差的
- 顶端
- 底部
- 最高的
- 最低限度
- 最佳的
每当问题陈述表明您正在寻找一些极端的元素时,就有必要考虑一下优先级队列是否有用。
有时优先级队列将只是解决方案的部分,其余部分将是动态编程的某种变体。这是您将在下一节看到的完整示例的情况。动态编程和优先级队列经常一起使用。
示例:查找路径
下面的例子是 Python heapq模块的一个真实用例。这个例子将使用一个经典算法,作为它的一部分,需要一个堆。您可以通过单击下面的链接下载示例中使用的源代码:
获取源代码: 点击此处获取源代码,您将使用在本教程中了解 Python heapq 模块。
想象一个需要在二维迷宫中导航的机器人。机器人需要从左上角的原点出发,到达右下角的目的地。机器人的记忆中有迷宫的地图,所以它可以在出发前规划出整个路径。
目标是让机器人尽快完成迷宫。
我们的算法是 Dijkstra 算法的变体。在整个算法中,有三种数据结构被保持和更新:
-
tentative是一张从原点到某个位置的试探性路径图,pos。这条路径被称为暂定,因为它是已知最短的路径,但它可能会被改进。 -
certain是一组点,对于这些点,tentative映射的路径是确定的最短可能路径。 -
candidates是一堆有路径的位置。堆的排序键是路径的长度。
在每个步骤中,您最多可以执行四个操作:
-
从
candidates弹出一个候选人。 -
将候选人添加到
certain集合。如果候选人已经是certain集合的成员,则跳过接下来的两个动作。 -
查找到当前候选人的最短已知路径。
-
对于当前候选的每个近邻,查看遍历候选是否给出比当前
tentative路径更短的路径。如果是,那么用这个新路径更新tentative路径和candidates堆。
这些步骤循环运行,直到目的地被添加到certain集合。当目的地在certain集合中时,您就完成了。该算法的输出是到目的地的tentative路径,现在certain是最短的可能路径。
顶层代码
现在您已经理解了算法,是时候编写代码来实现它了。在实现算法本身之前,写一些支持代码是有用的。
首先,你需要导入Pythonheapq模块:
import heapq
您将使用 Python heapq模块中的函数来维护一个堆,这将帮助您在每次迭代中找到已知路径最短的位置。
下一步是将地图定义为代码中的变量:
map = """\
.......X..
.......X..
....XXXX..
..........
..........
"""
该地图是一个三重引用字符串,显示机器人可以移动的区域以及任何障碍。
虽然更现实的场景是从文件中读取地图,但出于教学目的,使用这个简单的地图在代码中定义变量更容易。代码可以在任何地图上工作,但是在简单的地图上更容易理解和调试。
该图经过优化,便于代码的人类读者理解。点(.)足够亮,看起来是空的,但它的优点是显示了允许区域的尺寸。X位置标记机器人无法通过的障碍物。
支持代码
第一个函数将把地图转换成更容易用代码解析的形式。parse_map()获取地图并对其进行分析:
def parse_map(map):
lines = map.splitlines()
origin = 0, 0
destination = len(lines[-1]) - 1, len(lines) - 1
return lines, origin, destination
该函数获取一个映射并返回一个包含三个元素的元组:
lines列表origindestination
这使得剩余的代码能够处理为计算机设计的数据结构,而不是为人类的视觉扫描能力设计的数据结构。
可以通过(x, y)坐标来索引lines列表。表达式lines[y][x]返回两个字符之一的位置值:
- 点(
".") 表示该位置为空。 - 字母
"X"表示位置是障碍。
当你想找到机器人可以占据的位置时,这将是有用的。
函数is_valid()计算给定的(x, y)位置是否有效:
def is_valid(lines, position):
x, y = position
if not (0 <= y < len(lines) and 0 <= x < len(lines[y])):
return False
if lines[y][x] == "X":
return False
return True
该函数有两个参数:
lines是把地图看成一列线条。position是要检查的位置,作为指示(x, y)坐标的二元组整数。
为了有效,位置必须在地图的边界内,而不是障碍物。
该函数通过检查lines列表的长度来检查y是否有效。该函数接下来检查x是否有效,确保它在lines[y]内。最后,现在你知道两个坐标都在地图内,代码通过查看这个位置的字符并将字符与"X"进行比较来检查它们是否是障碍。
另一个有用的助手是get_neighbors(),它查找一个位置的所有邻居:
def get_neighbors(lines, current):
x, y = current
for dx in [-1, 0, 1]:
for dy in [-1, 0, 1]:
if dx == 0 and dy == 0:
continue
position = x + dx, y + dy
if is_valid(lines, position):
yield position
该函数返回当前位置周围的所有有效位置。
get_neighbors()小心避免将某个位置标识为自己的邻居,但它允许对角邻居。这就是为什么dx和dy中至少有一个不能为零,但是两个都不为零也没关系。
最后一个助手函数是get_shorter_paths(),它寻找更短的路径:
def get_shorter_paths(tentative, positions, through):
path = tentative[through] + [through]
for position in positions:
if position in tentative and len(tentative[position]) <= len(path):
continue
yield position, path
get_shorter_paths()产生以through为最后一步的路径比当前已知路径短的位置。
get_shorter_paths()有三个参数:
tentative是将一个位置映射到最短已知路径的字典。positions是一个可迭代的位置,您要将路径缩短到该位置。through是这样一个位置,通过它也许可以找到一条到positions的更短的路径。
假设从through开始一步就可以到达positions中的所有元素。
功能get_shorter_paths()检查使用through作为最后一步是否会为每个位置创建更好的路径。如果一个位置没有已知的路径,那么任何路径都是较短的。如果有一条已知的路径,那么只有当它的长度更短时,你才会产生新的路径。为了让get_shorter_paths()的 API 更容易使用,yield的一部分也是更短的路径。
所有的帮助函数都被写成纯函数,这意味着它们不修改任何数据结构,只返回值。这使得遵循核心算法变得更加容易,核心算法完成所有的数据结构更新。
核心算法代码
概括地说,您正在寻找起点和终点之间的最短路径。
您保留三份数据:
certain是某些职位的设定。candidates是堆候选人。tentative是一个将节点映射到当前最短已知路径的字典。
如果您能确定最短的已知路径是最短的可能路径,则位置在certain中。如果目的地在certain集合中,那么到目的地的最短已知路径无疑是最短的可能路径,并且您可以返回该路径。
candidates的堆由最短已知路径的长度组织,并在 Python heapq模块中的函数的帮助下进行管理。
在每一步,你看着候选人与最短的已知路径。这是用heappop()弹出堆的地方。到这个候选者没有更短的路径——所有其他路径都经过candidates中的某个其他节点,并且所有这些路径都更长。正因为如此,目前的候选人可以标上certain。
然后查看所有没有被访问过的邻居,如果遍历当前节点是一种改进,那么使用heappush()将它们添加到candidates堆中。
函数find_path()实现了该算法:
1def find_path(map):
2 lines, origin, destination = parse_map(map)
3 tentative = {origin: []}
4 candidates = [(0, origin)]
5 certain = set()
6 while destination not in certain and len(candidates) > 0:
7 _ignored, current = heapq.heappop(candidates)
8 if current in certain:
9 continue
10 certain.add(current)
11 neighbors = set(get_neighbors(lines, current)) - certain
12 shorter = get_shorter_paths(tentative, neighbors, current)
13 for neighbor, path in shorter:
14 tentative[neighbor] = path
15 heapq.heappush(candidates, (len(path), neighbor))
16 if destination in tentative:
17 return tentative[destination] + [destination]
18 else:
19 raise ValueError("no path")
find_path()接收一个map作为字符串,并返回从原点到目的地的路径作为位置列表。
这个函数有点长且复杂,所以让我们一次一点地来看一下:
-
第 2 行到第 5 行设置了循环将查看和更新的变量。你已经知道了一条从原点到自身的路径,这条路径是空的,长度为 0。
-
第 6 行定义了循环的终止条件。如果没有
candidates,那么没有路径可以缩短。如果destination在certain,那么到destination的路径不能再短了。 -
第 7 行到第 10 行使用
heappop()得到一个候选者,如果它已经在certain中就跳过这个循环,否则将这个候选者添加到certain。这确保了每个候选项最多被循环处理一次。 -
第 11 行到第 15 行使用
get_neighbors()和get_shorter_paths()寻找到邻近位置的更短路径,并更新tentative字典和candidates堆。 -
第 16 行到第 19 行处理返回正确的结果。如果找到了路径,那么函数将返回它。虽然计算路径而不计算最终位置使得算法的实现更简单,但是返回路径并以为目的地是一个更好的 API。如果找不到路径,则会引发异常。
将函数分解成不同的部分可以让你一次理解一部分。
可视化代码
如果该算法实际上被机器人使用,那么机器人可能会在它应该经过的位置列表中表现得更好。然而,为了使结果对人类来说更好看,可视化他们会更好。
show_path()在地图上绘制路径:
def show_path(path, map):
lines = map.splitlines()
for x, y in path:
lines[y] = lines[y][:x] + "@" + lines[y][x + 1 :]
return "\n".join(lines) + "\n"
该函数将path和map作为参数。它返回一个新地图,路径由 at 符号("@")指示。
运行代码
最后,您需要调用函数。这可以通过 Python 交互式解释器来完成。
以下代码将运行该算法并显示漂亮的输出:
>>> path = find_path(map)
>>> print(show_path(path, map))
@@.....X..
..@....X..
...@XXXX..
....@@@@@.
.........@
首先你得到从find_path()开始的最短路径。然后你把它传递给show_path()来渲染一个标有路径的地图。最后,你print()把地图以标准输出。
路径向右移动一步,然后向右下斜移几步,再向右移几步,最后向右下斜移一步。
恭喜你!您已经使用 Python heapq模块解决了一个问题。
这类寻路问题可以通过动态规划和优先级队列的组合来解决,在工作面试和编程挑战中很常见。例如,2019 年出现的代码包括一个问题,可以用这里描述的技术解决。
结论
你现在知道了什么是堆和优先级队列数据结构,以及它们在解决什么样的问题时有用。您学习了如何使用 Python heapq模块将 Python 列表用作堆。您还学习了如何使用 Python heapq模块中的高级操作,比如merge(),它在内部使用堆。
在本教程中,您已经学会了如何:
- 使用 Python
heapq模块中的低级函数来解决需要堆或优先级队列的问题 - 使用 Python
heapq模块中的高级函数来合并已排序的可迭代对象或查找可迭代对象中最大或最小的元素 - 认识到堆和优先级队列可以帮助解决的问题
- 预测使用堆的代码的性能
凭借您对堆和 Python heapq模块的了解,您现在可以解决许多问题,这些问题的解决方案取决于找到最小或最大的元素。要了解您在本教程中看到的示例,您可以从下面的链接下载源代码:
获取源代码: 点击此处获取源代码,您将使用在本教程中了解 Python heapq 模块。*******
Python 直方图绘制:NumPy、Matplotlib、Pandas 和 Seaborn
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: Python 直方图绘制:NumPy、Matplotlib、Pandas & Seaborn
在本教程中,您将具备制作产品质量、演示就绪的 Python 直方图的能力,并拥有一系列选择和功能。
如果您对 Python 和 statistics 有入门中级知识,那么您可以将本文作为使用 Python 科学堆栈中的库(包括 NumPy、Matplotlib、 Pandas 和 Seaborn)在 Python 中构建和绘制直方图的一站式商店。
直方图是一个很好的工具,可以快速评估几乎所有观众都能直观理解的概率分布。Python 为构建和绘制直方图提供了一些不同的选项。大多数人通过直方图的图形表示来了解直方图,它类似于条形图:
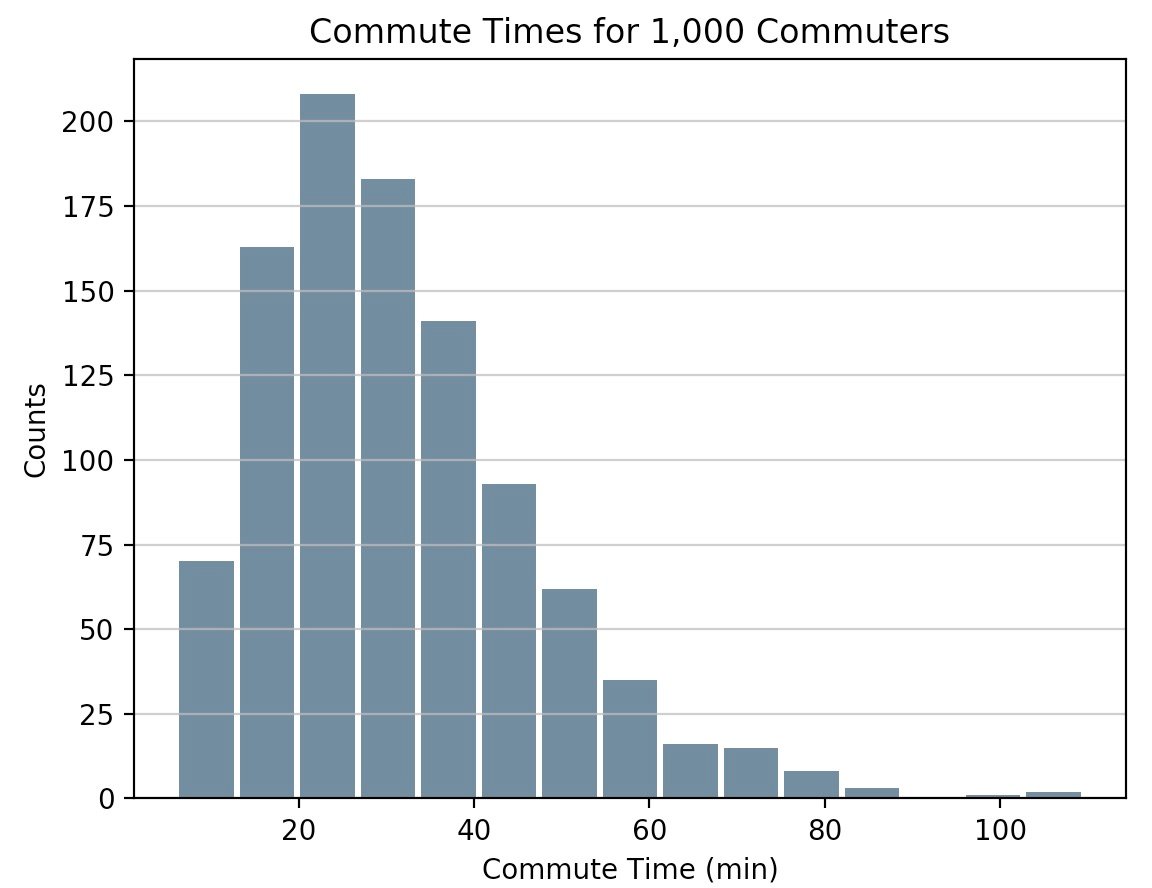
这篇文章将引导你创建类似上面的情节以及更复杂的情节。以下是您将涉及的内容:
- 用纯 Python 构建直方图,不使用第三方库
- 使用 NumPy 构建直方图以汇总底层数据
- 使用 Matplotlib、Pandas 和 Seaborn 绘制结果直方图
**免费奖金:**时间短?点击这里获得一份免费的两页 Python 直方图备忘单,它总结了本教程中解释的技术。
纯 Python 的直方图
当您准备绘制直方图时,最简单的方法是不要考虑柱,而是报告每个值出现的次数(频率表)。Python 字典非常适合这项任务:
>>> # Need not be sorted, necessarily
>>> a = (0, 1, 1, 1, 2, 3, 7, 7, 23)
>>> def count_elements(seq) -> dict:
... """Tally elements from `seq`."""
... hist = {}
... for i in seq:
... hist[i] = hist.get(i, 0) + 1
... return hist
>>> counted = count_elements(a)
>>> counted
{0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}
count_elements()返回一个字典,将序列中的唯一元素作为键,将它们的频率(计数)作为值。在seq的循环中,hist[i] = hist.get(i, 0) + 1说,“对于序列中的每个元素,将它在hist中的对应值增加 1。”
事实上,这正是 Python 标准库中的collections.Counter类所做的,该类的子类化了一个 Python 字典并覆盖了它的.update()方法:
>>> from collections import Counter
>>> recounted = Counter(a)
>>> recounted
Counter({0: 1, 1: 3, 3: 1, 2: 1, 7: 2, 23: 1})
通过测试两者之间的相等性,您可以确认您的手工函数实际上做了与collections.Counter相同的事情:
>>> recounted.items() == counted.items()
True
技术细节:上面count_elements()的映射默认为一个更加高度优化的 C 函数,如果它可用的话。在 Python 函数count_elements()中,你可以做的一个微优化是在 for 循环之前声明get = hist.get。这将把一个方法绑定到一个变量,以便在循环中更快地调用。
作为理解更复杂的函数的第一步,从头构建简化的函数可能会有所帮助。让我们利用 Python 的输出格式进一步重新发明一个 ASCII 直方图:
def ascii_histogram(seq) -> None:
"""A horizontal frequency-table/histogram plot."""
counted = count_elements(seq)
for k in sorted(counted):
print('{0:5d} {1}'.format(k, '+' * counted[k]))
该函数创建一个排序频率图,其中计数表示为加号(+)的计数。在字典上调用 sorted() 会返回一个排序后的键列表,然后使用counted[k]访问每个键对应的值。要了解这一点,您可以使用 Python 的random模块创建一个稍大的数据集:
>>> # No NumPy ... yet
>>> import random
>>> random.seed(1)
>>> vals = [1, 3, 4, 6, 8, 9, 10]
>>> # Each number in `vals` will occur between 5 and 15 times.
>>> freq = (random.randint(5, 15) for _ in vals)
>>> data = []
>>> for f, v in zip(freq, vals):
... data.extend([v] * f)
>>> ascii_histogram(data)
1 +++++++
3 ++++++++++++++
4 ++++++
6 +++++++++
8 ++++++
9 ++++++++++++
10 ++++++++++++
在这里,您模拟从vals开始拨弦,频率由freq(一个发生器表达式)给出。产生的样本数据重复来自vals的每个值一定的次数,在 5 到 15 之间。
注意 : random.seed() 用于播种或初始化random使用的底层伪随机数发生器( PRNG )。这听起来可能有点矛盾,但这是一种让随机数据具有可重复性和确定性的方法。也就是说,如果你照原样复制这里的代码,你应该得到完全相同的直方图,因为在播种生成器之后第一次调用random.randint()将使用 Mersenne Twister 产生相同的“随机”数据。
从基础开始构建:以 NumPy 为单位的直方图计算
到目前为止,您一直在使用最好称为“频率表”的东西。但是从数学上来说,直方图是区间(区间)到频率的映射。更专业的说,可以用来近似基础变量的概率密度函数( PDF )。
从上面的“频率表”开始,真正的直方图首先“分类”值的范围,然后计算落入每个分类的值的数量。这就是 NumPy 的 histogram()函数所做的事情,它也是你稍后将在 Python 库中看到的其他函数的基础,比如 Matplotlib 和 Pandas。
考虑从拉普拉斯分布中抽取的一个浮点样本。该分布比正态分布具有更宽的尾部,并且具有两个描述性参数(位置和比例):
>>> import numpy as np
>>> # `numpy.random` uses its own PRNG.
>>> np.random.seed(444)
>>> np.set_printoptions(precision=3)
>>> d = np.random.laplace(loc=15, scale=3, size=500)
>>> d[:5]
array([18.406, 18.087, 16.004, 16.221, 7.358])
在这种情况下,您处理的是一个连续的分布,单独计算每个浮点数,直到小数点后无数位,并没有多大帮助。相反,您可以对数据进行分类或“分桶”,并对落入每个分类中的观察值进行计数。直方图是每个条柱内值的结果计数:
>>> hist, bin_edges = np.histogram(d)
>>> hist
array([ 1, 0, 3, 4, 4, 10, 13, 9, 2, 4])
>>> bin_edges
array([ 3.217, 5.199, 7.181, 9.163, 11.145, 13.127, 15.109, 17.091,
19.073, 21.055, 23.037])
这个结果可能不是直接直观的。 np.histogram() 默认使用 10 个大小相等的仓,并返回频率计数和相应仓边的元组。它们是边缘,在这种意义上,将会比直方图的成员多一个箱边缘:
>>> hist.size, bin_edges.size
(10, 11)
技术细节:除了最后一个(最右边的)箱子,其他箱子都是半开的。也就是说,除了最后一个 bin 之外的所有 bin 都是[包含,不包含],最后一个 bin 是[包含,不包含]。
NumPy 如何构造的一个非常简洁的分类如下:
>>> # The leftmost and rightmost bin edges
>>> first_edge, last_edge = a.min(), a.max()
>>> n_equal_bins = 10 # NumPy's default
>>> bin_edges = np.linspace(start=first_edge, stop=last_edge,
... num=n_equal_bins + 1, endpoint=True)
...
>>> bin_edges
array([ 0\. , 2.3, 4.6, 6.9, 9.2, 11.5, 13.8, 16.1, 18.4, 20.7, 23\. ])
上面的例子很有意义:在 23 的峰峰值范围内,10 个等间距的仓意味着宽度为 2.3 的区间。
从那里,该功能委托给 np.bincount() 或 np.searchsorted() 。bincount()本身可以用来有效地构建您在这里开始的“频率表”,区别在于包含了零出现的值:
>>> bcounts = np.bincount(a)
>>> hist, _ = np.histogram(a, range=(0, a.max()), bins=a.max() + 1)
>>> np.array_equal(hist, bcounts)
True
>>> # Reproducing `collections.Counter`
>>> dict(zip(np.unique(a), bcounts[bcounts.nonzero()]))
{0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}
注意 : hist这里实际上使用的是宽度为 1.0 的面元,而不是“离散”计数。因此,这只对计算整数有效,而不是像[3.9, 4.1, 4.15]这样的浮点数。
用 Matplotlib 和 Pandas 可视化直方图
现在你已经看到了如何用 Python 从头开始构建直方图,让我们看看其他的 Python 包如何为你完成这项工作。 Matplotlib 通过围绕 NumPy 的histogram()的通用包装器,提供开箱即用的可视化 Python 直方图的功能:
import matplotlib.pyplot as plt
# An "interface" to matplotlib.axes.Axes.hist() method
n, bins, patches = plt.hist(x=d, bins='auto', color='#0504aa',
alpha=0.7, rwidth=0.85)
plt.grid(axis='y', alpha=0.75)
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('My Very Own Histogram')
plt.text(23, 45, r'$\mu=15, b=3$')
maxfreq = n.max()
# Set a clean upper y-axis limit.
plt.ylim(ymax=np.ceil(maxfreq / 10) * 10 if maxfreq % 10 else maxfreq + 10)
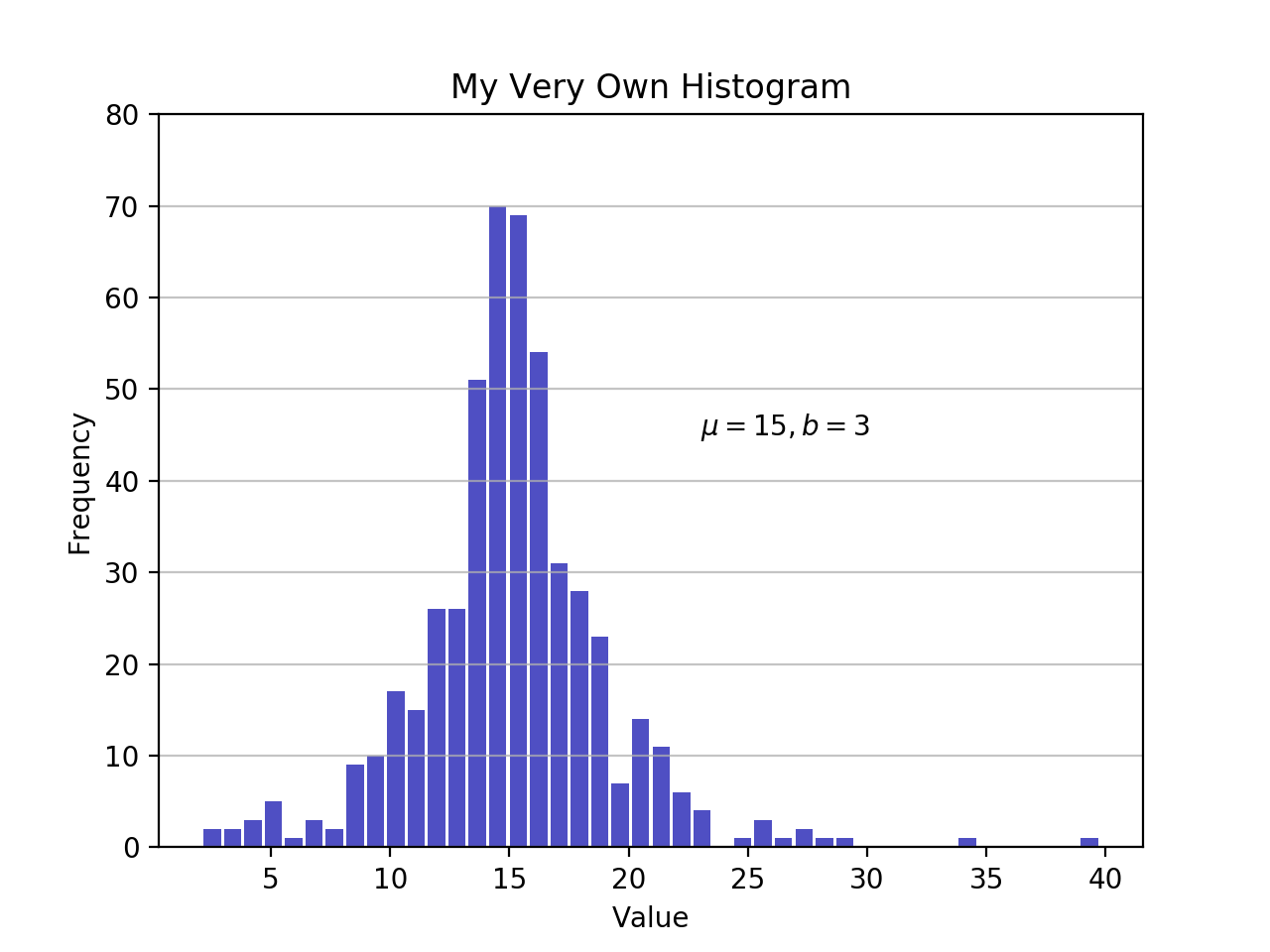
如前所述,直方图在 x 轴上使用其条边,在 y 轴上使用相应的频率。在上图中,传递bins='auto'在两个算法之间选择,以估计“理想”的箱数。在高层次上,该算法的目标是选择一个能够生成最忠实的数据表示的条柱宽度。关于这个主题的更多信息,可能会变得非常专业,请查看 Astropy 文档中的选择直方图仓。
在 Python 的科学堆栈中,熊猫的Series.histogram() 使用matplotlib.pyplot.hist() 绘制输入序列的 Matplotlib 直方图:
import pandas as pd
# Generate data on commute times.
size, scale = 1000, 10
commutes = pd.Series(np.random.gamma(scale, size=size) ** 1.5)
commutes.plot.hist(grid=True, bins=20, rwidth=0.9,
color='#607c8e')
plt.title('Commute Times for 1,000 Commuters')
plt.xlabel('Counts')
plt.ylabel('Commute Time')
plt.grid(axis='y', alpha=0.75)
pandas.DataFrame.histogram()类似,但为数据帧中的每列数据生成一个直方图。
绘制核密度估计值(KDE)
在本教程中,从统计学的角度来说,您一直在使用样本。无论数据是离散的还是连续的,它都被假定为来自一个总体,该总体具有仅由几个参数描述的真实、精确的分布。
核密度估计(KDE)是一种估计样本中随机变量的概率密度函数(PDF)的方法。KDE 是一种数据平滑的手段。
坚持使用熊猫库,你可以使用plot.kde()创建和覆盖密度图,它对Series和DataFrame对象都可用。但首先,让我们生成两个不同的数据样本进行比较:
>>> # Sample from two different normal distributions
>>> means = 10, 20
>>> stdevs = 4, 2
>>> dist = pd.DataFrame(
... np.random.normal(loc=means, scale=stdevs, size=(1000, 2)),
... columns=['a', 'b'])
>>> dist.agg(['min', 'max', 'mean', 'std']).round(decimals=2)
a b
min -1.57 12.46
max 25.32 26.44
mean 10.12 19.94
std 3.94 1.94
现在,要在相同的 Matplotlib 轴上绘制每个直方图:
fig, ax = plt.subplots()
dist.plot.kde(ax=ax, legend=False, title='Histogram: A vs. B')
dist.plot.hist(density=True, ax=ax)
ax.set_ylabel('Probability')
ax.grid(axis='y')
ax.set_facecolor('#d8dcd6')

这些方法利用了 SciPy 的 gaussian_kde() ,从而产生看起来更平滑的 PDF。
如果您仔细观察这个函数,您会发现对于 1000 个数据点的相对较小的样本,它是多么接近“真实”的 PDF。下面,你可以先用scipy.stats.norm()构建“解析”分布。这是一个类实例,封装了统计标准正态分布、其矩和描述函数。它的 PDF 是“精确的”,因为它被精确地定义为norm.pdf(x) = exp(-x**2/2) / sqrt(2*pi)。
在此基础上,您可以从该分布中随机抽取 1000 个数据点,然后尝试使用scipy.stats.gaussian_kde()返回 PDF 的估计值:
from scipy import stats
# An object representing the "frozen" analytical distribution
# Defaults to the standard normal distribution, N~(0, 1)
dist = stats.norm()
# Draw random samples from the population you built above.
# This is just a sample, so the mean and std. deviation should
# be close to (1, 0).
samp = dist.rvs(size=1000)
# `ppf()`: percent point function (inverse of cdf — percentiles).
x = np.linspace(start=stats.norm.ppf(0.01),
stop=stats.norm.ppf(0.99), num=250)
gkde = stats.gaussian_kde(dataset=samp)
# `gkde.evaluate()` estimates the PDF itself.
fig, ax = plt.subplots()
ax.plot(x, dist.pdf(x), linestyle='solid', c='red', lw=3,
alpha=0.8, label='Analytical (True) PDF')
ax.plot(x, gkde.evaluate(x), linestyle='dashed', c='black', lw=2,
label='PDF Estimated via KDE')
ax.legend(loc='best', frameon=False)
ax.set_title('Analytical vs. Estimated PDF')
ax.set_ylabel('Probability')
ax.text(-2., 0.35, r'$f(x) = \frac{\exp(-x^2/2)}{\sqrt{2*\pi}}$',
fontsize=12)

这是一个更大的代码块,所以让我们花点时间来了解几个关键行:
- SciPy 的
stats子包允许您创建表示分析分布的 Python 对象,您可以从中采样以创建实际数据。所以dist = stats.norm()代表一个正常的连续随机变量,你用dist.rvs()从中生成随机数。 - 为了评估分析 PDF 和高斯 KDE,您需要一个分位数数组
x(高于/低于平均值的标准偏差,表示正态分布)。stats.gaussian_kde()表示一个估计的 PDF,在这种情况下,您需要对一个数组进行评估,以产生视觉上有意义的东西。 - 最后一行包含一些 LaTex ,它与 Matplotlib 很好地集成在一起。
与 Seaborn 的别样选择
让我们再加入一个 Python 包。Seaborn 有一个displot()函数,可以一步绘制出单变量分布的直方图和 KDE。使用早期的 NumPy 数组d:
import seaborn as sns
sns.set_style('darkgrid')
sns.distplot(d)

上面的调用产生了一个 KDE。还可以选择为数据拟合特定的分布。这不同于 KDE,它由通用数据的参数估计和指定的分布名称组成:
sns.distplot(d, fit=stats.laplace, kde=False)

同样,请注意细微的差别。在第一种情况下,你估计一些未知的 PDF 在第二种情况下,你需要一个已知的分布,并根据经验数据找出最能描述它的参数。
熊猫里的其他工具
除了它的绘图工具,Pandas 还提供了一个方便的.value_counts()方法来计算 Pandas 的非空值的直方图Series:
>>> import pandas as pd
>>> data = np.random.choice(np.arange(10), size=10000,
... p=np.linspace(1, 11, 10) / 60)
>>> s = pd.Series(data)
>>> s.value_counts()
9 1831
8 1624
7 1423
6 1323
5 1089
4 888
3 770
2 535
1 347
0 170
dtype: int64
>>> s.value_counts(normalize=True).head()
9 0.1831
8 0.1624
7 0.1423
6 0.1323
5 0.1089
dtype: float64
在其他地方, pandas.cut() 是将值绑定到任意区间的便捷方式。假设您有一些关于个人年龄的数据,并希望明智地对它们进行分类:
>>> ages = pd.Series(
... [1, 1, 3, 5, 8, 10, 12, 15, 18, 18, 19, 20, 25, 30, 40, 51, 52])
>>> bins = (0, 10, 13, 18, 21, np.inf) # The edges
>>> labels = ('child', 'preteen', 'teen', 'military_age', 'adult')
>>> groups = pd.cut(ages, bins=bins, labels=labels)
>>> groups.value_counts()
child 6
adult 5
teen 3
military_age 2
preteen 1
dtype: int64
>>> pd.concat((ages, groups), axis=1).rename(columns={0: 'age', 1: 'group'})
age group
0 1 child
1 1 child
2 3 child
3 5 child
4 8 child
5 10 child
6 12 preteen
7 15 teen
8 18 teen
9 18 teen
10 19 military_age
11 20 military_age
12 25 adult
13 30 adult
14 40 adult
15 51 adult
16 52 adult
令人高兴的是,这两个操作最终都利用了 Cython 代码,这使它们在速度上具有竞争力,同时保持了灵活性。
好吧,那我应该用哪个?
至此,您已经看到了许多用于绘制 Python 直方图的函数和方法可供选择。他们如何比较?简而言之,没有“一刀切”以下是到目前为止您所涉及的函数和方法的回顾,所有这些都与用 Python 分解和表示分布有关:
| 你有/想 | 考虑使用 | 注意事项 |
|---|---|---|
| 包含在列表、元组或集合等数据结构中的简单整数数据,并且您希望在不导入任何第三方库的情况下创建 Python 直方图。 | Python 标准库中的 collections.Counter() 提供了一种从数据容器中获取频率计数的快速而简单的方法。 | 这是一个频率表,所以它不像“真正的”直方图那样使用宁滨的概念。 |
| 大量数据,并且您想要计算表示仓和相应频率的“数学”直方图。 | NumPy 的 np.histogram() 和 np.bincount() 对数值计算直方图值和相应的面元边缘很有用。 | 更多信息,请查看 np.digitize() 。 |
熊猫的Series或DataFrame对象中的表格数据。 | 熊猫法如Series.plot.hist()DataFrame.plot.hist()Series.value_counts()cut(),还有Series.plot.kde()DataFrame.plot.kde()。 | 查看熊猫可视化文档获取灵感。 |
| 从任何数据结构创建高度可定制、微调的图。 | pyplot.hist() 是一个广泛使用的直方图绘制函数,使用np.histogram(),是熊猫绘制函数的基础。 | Matplotlib,尤其是它的面向对象框架,非常适合微调直方图的细节。这个界面可能需要一点时间来掌握,但最终可以让您非常精确地安排任何可视化。 |
| 预先封装的设计和集成。 | Seaborn 的 distplot() ,用于结合直方图和 KDE 图或绘制分布拟合图。 | 本质上是“包装器周围的包装器”,它在内部利用 Matplotlib 直方图,而 Matplotlib 直方图又利用 NumPy。 |
**免费奖金:**时间短?点击这里获得一份免费的两页 Python 直方图备忘单,它总结了本教程中解释的技术。
您也可以在真正的 Python 材料页面上找到这篇文章的代码片段,它们都在一个脚本中。
至此,祝你在野外创建直方图好运。希望上面的某个工具能满足你的需求。无论你做什么,只是不要用饼状图。
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: Python 直方图绘制:NumPy、Matplotlib、Pandas & Seaborn**
皮托尼斯塔的假日愿望清单
又到了一年中每个人都希望得到最后一分钟礼物的时候了。无论你是 Python 开发者的朋友还是你自己,如果你想得到一些特别的东西,我有一个完美的愿望清单。为了给 Pythonistas 找到最好的礼物,我已经在网上搜遍了,并向我真正的 Python 作者同事进行了投票。
我将这些建议分为五类:
- 好的理由
- 学习资源
- Python swag
- 五金器具
- 小玩意儿
为慈善事业捐款
任何人都能收到的最好的礼物是给予别人的感觉。无论您是想自己捐款还是以他人的名义捐款,这里有一些与 Python 相关的优秀组织可以使用捐款:
-
Python 软件基金会(PSF) :维护 Python 的官方组织,每年举办 Python 大会
-
Django 软件基金会(DSF) :维护 Django(我们最喜欢的网络应用框架)的官方组织
-
PyLadies :致力于帮助更多女性成为 Python 开源社区的参与者和领导者的组织
捐赠你的钱并不是帮助 Python 社区的唯一方法。你也可以作为志愿者贡献你的时间。
Python 学习资源
我认为能给予的最好礼物之一是知识。想好好阅读一下 Python 相关的内容吗?查看最好的 Python 书籍,收集大量的 Python 相关书籍。也许你想要一些更互动的东西?查看在真蟒T5 的课程!
学习 Python 最好的方法之一就是向大师们学习。一张 PyCon 2019 的门票将是最大的学习礼物:三天的课程、演示、编码挑战,以及与 Python 代码梦想者的交流!这将是持续给予的终极礼物。你还会得到一整年都可以用的礼品袋。
蟒蛇贴纸、t 恤和咖啡杯…哦,我的天!
我们是 Pythonistas,为什么不展示一下我们最爱的编程语言呢!我喜欢在我的笔记本电脑上炫耀我对 Python 的热爱。

如果你不喜欢贴纸,那么一件运动衫或 t 恤可能会更好。也别忘了你的旧咖啡杯。它可能也需要升级。

想要有真正 Python 标志的东西吗?他们也为你提供了保障。
硬件
随着技术每天都在进步,每个程序员都需要升级他们的硬件。这可能是因为你的硬盘空间快用完了,键盘磨损了,或者只是想找点乐子。(或者你想要更高级的。每个人都喜欢挑战,对吗?)这是我这一季推荐去看看的硬件。
外部硬盘
无论您有一个庞大的代码库还是运行数百个 Docker 图像,您都可能很快耗尽空间来完成所有工作。好消息是硬盘容量的成本几乎在不断下降!另外,通过 USB 3.0,它几乎与内置硬盘一样快,甚至更快。不到 60 美元就能获得 2 TB 的便携空间!需要更大的吗?对于贵一倍多一点的价格,可以得到 8 TB !如果可以的话,我建议坚持使用希捷和西部数据这样的品牌。
新型机械键盘
作为开发人员,我们在电脑上 99%的时间都在使用键盘。这意味着拥有适合自己的键盘非常重要。不知道买什么?在机械键盘分部的人们创造了一个伟大的机械键盘指南。
推荐键盘就像推荐内衣一样:你永远不知道别人会有什么感觉,所以我强烈建议你看看上面的指南。但是如果你想要我的意见,我使用的并且认为手感最好的键盘是微软 Sculpt Ergo 键盘。

耳机
让我们面对现实吧:没有什么比带着你最喜欢的音乐进入状态,然后埋头研究你的代码库更好的了。那么,为什么不确保你得到一副好的耳机呢?我爱我的 Beyerdynamic DT 770 Pro 耳机,无法想象没有它们的编码。当你买耳机的时候,我推荐使用这个有用的指南,它是由耳机分栏的热心人创建的。

小工具
有新玩具玩总是很有趣,我们 Python 开发者有很多选择。在这里,我们收集了我们最喜欢的使用 Python 的小工具。
树莓派
让我们从一个小馅饼开始——也就是树莓派。您可以用树莓派做很多事情,包括以下内容:
- 自动化你的花园
- 实现家居自动化
- 建造一个老派的游戏中心
- 集群计算
- 这么多!
其起价仅为 35 美元,令人惊讶的是,您将获得一个多核、蓝牙和 WiFi 功能的设备!我强烈建议买一个工具包开始。

开源漫游者
说到树莓派,创建自己的火星科学实验室怎么样!火星探测器的创造者美国宇航局喷气推进实验室(JPL)已经创建了一个使用树莓 Pi 的火星科学实验室探测器的开源副本。
这款车价格不菲(约 2500 美元),不适合心脏不好的人,因为它需要单独购买每个零件,然后组装整个漫游者。不要担心编程的漫游者虽然。这已经是 JPL 用 Python 写的了!如果价格和难度没有吓退你,那么这对于任何想学习机器人技术的人来说都是一份伟大的礼物。

Anki 的 Vector 和 Cozmo 机器人
如果制作自己的机器人似乎有点令人生畏,那么请查看 Vector 和 Cozmo。Vector 是“好机器人”,它可以帮助做很多事情,比如厨房定时器、自拍或告诉你天气将会如何。如果这还不够,还有 Python 软件开发包(SDK) 可以让你完全定制 Vector!
如果你是编程新手,或者想教别人如何给机器人编程,那么 Cozmo 可以满足你。有了完整的 Python SDK 和一个更简单的选项,这个机器人对于初学者和经验丰富的程序员来说是一个很好的选择。

DJI 无人机
有点厌倦了被卡在地上?坐飞机怎么样?DJI 有多种版本的无人机,你可以使用他们的软件手动或自动飞行。如果他们没有您正在寻找的特性,不如检查一下 SDK,自己动手做吧!DJI 有很多无人机可供选择,但我已经盯上了泰洛,因为它更便宜,而且有一个更容易使用的 Python 库。

Pythonic 节日快乐
无论你决定给你或你的 Python 开发者朋友买什么,一定要享受这个假期,继续使用 Python!我现在准备在我的亚马逊购物车上推 checkout,并告诉我的妻子#PythonMadeMeDoIt。***
用 Python 探索 HTTPS
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 探索 Python 中的 HTTPS 和密码学
你有没有想过为什么你可以通过互联网发送你的信用卡信息?你可能已经注意到了浏览器中网址上的https://,但是它是什么,它是如何保证你的信息安全的**?或者,您可能想要创建一个 Python HTTPS 应用程序,但您并不确定这意味着什么。你如何确定你的网络应用是安全的?*
*您可能会惊讶地发现,回答这些问题并不一定要成为安全专家!在本教程中,您将了解到保证互联网通信安全的各种因素。您将看到 Python HTTPS 应用程序如何保护信息安全的具体示例。
在本教程中,您将学习如何:
- 监控和分析网络流量
- 应用密码术保护数据安全
- 描述公钥基础设施(PKI) 的核心概念
- 创建您自己的认证机构
- 构建一个 Python HTTPS 应用
- 识别常见的 Python HTTPS 警告和错误
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
什么是 HTTP?
在深入研究 HTTPS 及其在 Python 中的使用之前,理解它的父代 HTTP 很重要。这个首字母缩写代表超文本传输协议,当你在你最喜欢的网站上冲浪时,它是大多数通信的基础。更具体地说,HTTP 是一个用户代理,比如你的网络浏览器,与一个网络服务器,比如 realpython.com 的通信的方式。下面是 HTTP 通信的简图:
*
此图显示了计算机如何与服务器通信的简化版本。以下是每个步骤的细目分类:
- 你告诉你的浏览器去
http://someserver.com/link。 - 您的设备和服务器建立了一个 TCP 连接。
- 你的浏览器发送一个 HTTP 请求到服务器。
- 服务器接收 HTTP 请求并解析它。
- 服务器用一个 HTTP 响应来响应。
- 您的计算机接收、解析并显示响应。
这个分解抓住了 HTTP 的基础。您向服务器发出请求,服务器返回响应。虽然 HTTP 不需要 TCP,但它需要一个可靠的底层协议。实际上,这几乎总是 TCP over IP(尽管谷歌正试图创造一个替代物】。如果你需要复习,那么看看 Python 中的套接字编程(指南)。
就协议而言,HTTP 是最简单的协议之一。它被设计用来通过互联网发送内容,比如 HTML、视频、图像等等。这是通过 HTTP 请求和响应完成的。HTTP 请求包含以下元素:
- 方法描述了客户端想要执行的动作。静态内容的方法通常是
GET,尽管也有其他可用的方法,比如POST、HEAD和DELETE。 - 路径向服务器指示你想要请求的网页。比如这个页面的路径是
/python-https。 - 版本是几个 HTTP 版本之一,如 1.0、1.1 或 2.0。最常见的大概是 1.1。
- 标题帮助描述服务器的附加信息。
- 主体向服务器提供来自客户端的信息。虽然这个字段不是必需的,但是一些方法通常有一个主体,比如
POST。
这些是您的浏览器用来与服务器通信的工具。服务器用 HTTP 响应来响应。HTTP 响应包含以下元素:
- 版本标识 HTTP 版本,通常与请求的版本相同。
- 状态码表示请求是否成功完成。有不少状态码。
- 状态消息提供了帮助描述状态代码的人类可读消息。
- 头允许服务器用关于请求的附加元数据来响应。这些与请求头的概念相同。
- 正文承载内容。从技术上讲,这是可选的,但通常它包含一个有用的资源。
这些是 HTTP 的构造块。如果您有兴趣了解更多关于 HTTP 的知识,那么您可以查看一个概述页面来更深入地了解该协议。
什么是 HTTPS?
现在您对 HTTP 有了更多的了解,什么是 HTTPS 呢?好消息是,你已经知道了!HTTPS 代表超文本传输协议安全。从根本上说,HTTPS 是与 HTTP 相同的协议,但是增加了通信安全的含义。
HTTPS 没有重写它所基于的任何 HTTP 基础。相反,HTTPS 由通过加密连接发送的常规 HTTP 组成。通常,这种加密连接是由 TLS 或 SSL 提供的,它们是在信息通过网络发送之前加密信息的加密协议。
注意: TLS 和 SSL 是极其相似的协议,尽管 SSL 正在被淘汰,TLS 将取而代之。这些协议的区别超出了本教程的范围。知道 TLS 是 SSL 更新更好的版本就足够了。
那么,为什么要创造这种分离呢?为什么不把复杂性引入 HTTP 协议本身呢?答案是便携性。保护通信安全是一个重要而困难的问题,但是 HTTP 只是需要安全性的众多协议之一。在各种各样的应用中还有数不清的其他例子:
- 电子邮件
- 即时消息
- VoIP(网络电话)
还有其他的!如果这些协议中的每一个都必须创建自己的安全机制,那么世界将变得更加不安全,更加混乱。上述协议经常使用的 TLS 提供了一种保护通信安全的通用方法。
注意:这种协议分离是网络中的一个常见主题,以至于它有了一个名字。 OSI 模型代表了从物理介质一直到页面上呈现的 HTML 的通信!
您将在本教程中学习的几乎所有信息不仅适用于 Python HTTPS 应用程序。您将学习安全通信的基础知识,以及它如何具体应用于 HTTPS。
为什么 HTTPS 很重要?
安全通信对于提供安全的在线环境至关重要。随着世界上越来越多的地方(包括银行和医疗保健网站)走向在线,开发人员创建 Python HTTPS 应用程序变得越来越重要。同样,HTTPS 只是 TLS 或 SSL 上的 HTTP。TLS 旨在防止窃听者窃取隐私。它还可以提供客户端和服务器的身份验证。
在本节中,您将通过执行以下操作来深入探究这些概念:
- 创建一个 Python HTTPS 服务器
- 与您的 Python HTTPS 服务器通信
- 捕捉这些通信
- 分析那些消息
我们开始吧!
创建示例应用程序
假设你是一个叫做秘密松鼠的很酷的 Python 俱乐部的领导者。松鼠是秘密的,需要一个秘密的信息来参加他们的会议。作为领导者,你选择秘密信息,每次会议都会改变。不过,有时候,你很难在会议前与所有成员见面,告诉他们这个秘密消息!你决定建立一个秘密服务器,成员们可以自己看到秘密信息。
注意:本教程中使用的示例代码是而不是为生产设计的。它旨在帮助您学习 HTTP 和 TLS 的基础知识。**请勿将此代码用于生产。**以下许多例子都有糟糕的安全实践。在本教程中,您将了解 TLS,以及它可以帮助您更加安全的一种方式。
您已经学习了一些关于真实 Python 的教程,并决定使用一些您知道的依赖项:
要安装所有这些依赖项,可以使用 pip :
$ pip install flask uwsgi requests
安装完依赖项后,就可以开始编写应用程序了。在名为server.py的文件中,您创建了一个烧瓶应用程序:
# server.py
from flask import Flask
SECRET_MESSAGE = "fluffy tail"
app = Flask(__name__)
@app.route("/")
def get_secret_message():
return SECRET_MESSAGE
每当有人访问你的服务器的/路径时,这个 Flask 应用程序将显示秘密消息。这样一来,您可以在您的秘密服务器上部署应用程序并运行它:
$ uwsgi --http-socket 127.0.0.1:5683 --mount /=server:app
这个命令使用上面的 Flask 应用程序启动一个服务器。你在一个奇怪的端口上启动它,因为你不想让人们能够找到它,并为自己如此鬼鬼祟祟而沾沾自喜!您可以通过在浏览器中访问http://localhost:5683来确认它正在工作。
因为秘密松鼠中的每个人都知道 Python,所以你决定帮助他们。你写一个名为client.py的脚本来帮助他们获取秘密信息:
# client.py
import os
import requests
def get_secret_message():
url = os.environ["SECRET_URL"]
response = requests.get(url)
print(f"The secret message is: {response.text}")
if __name__ == "__main__":
get_secret_message()
只要设置了SECRET_URL环境变量,这些代码就会打印出秘密消息。在这种情况下,SECRET_URL就是127.0.0.1:5683。所以,你的计划是给每个俱乐部成员的秘密网址,并告诉他们保持它的秘密和安全。
虽然这可能看起来没问题,但请放心,它不是!事实上,即使你把用户名和密码放在这个网站上,它仍然是不安全的。但是即使你的团队设法保证了 URL 的安全,你的秘密信息仍然不安全。为了说明为什么您需要了解一点监控网络流量的知识。为此,您将使用一个名为 Wireshark 的工具。
设置 Wireshark
Wireshark 是一款广泛用于网络和协议分析的工具。这意味着它可以帮助您了解网络连接上发生了什么。安装和设置 Wireshark 对于本教程来说是可选的,但是如果您愿意的话,请随意。下载页面有几个可用的安装程序:
- macOS 10.12 及更高版本
- 64 位 Windows installer
- Windows installer 32 位
如果您使用的是 Windows 或 Mac,那么您应该能够下载适当的安装程序并按照提示进行操作。最后,您应该有一个运行的 Wireshark。
如果你在基于 Debian 的 Linux 环境下,那么安装会有点困难,但是仍然是可能的。您可以使用以下命令安装 Wireshark:
$ sudo add-apt-repository ppa:wireshark-dev/stable
$ sudo apt-get update
$ sudo apt-get install wireshark
$ sudo wireshark
您应该会看到类似这样的屏幕:
随着 Wireshark 的运行,是时候分析一些流量了!
看到你的数据不安全
你当前的客户端和服务器的运行方式是不安全的 T2。HTTP 会将所有内容以明文形式发送给任何人。这意味着,即使有人没有你的SECRET_URL,他们仍然可以看到你做的一切,只要他们可以监控你和服务器之间的任何设备上的流量。
这对你来说应该是比较恐怖的。毕竟,你不希望其他人出现在你的秘密会议上!你可以证明这是真的。首先,如果您的服务器没有运行,请启动它:
$ uwsgi --http-socket 127.0.0.1:5683 --mount /=server:app
这将在端口 5683 上启动您的 Flask 应用程序。接下来,您将在 Wireshark 中开始数据包捕获。此数据包捕获将帮助您查看进出服务器的所有流量。首先在 Wireshark 上选择 Loopback:lo 接口;

您可以看到 Loopback:lo 部分被突出显示。这将指示 Wireshark 监控该端口的流量。您可以做得更好,并指定您想要捕获哪个端口和协议。您可以在捕获过滤器中键入port 5683,在显示过滤器中键入http:
绿色方框表示 Wireshark 对您键入的过滤器满意。现在,您可以通过单击左上角的鳍开始捕获:
单击此按钮将在 Wireshark 中生成一个新窗口:

这个新窗口相当简单,但是底部的信息显示<live capture in progress>,这表明它正在工作。不要担心没有显示,因为这是正常的。为了让 Wireshark 报告任何事情,您的服务器上必须有一些活动。要获取一些数据,请尝试运行您的客户端:
$ SECRET_URL="http://127.0.0.1:5683" python client.py
The secret message is: fluffy tail
在执行了上面的client.py代码后,您现在应该会在 Wireshark 中看到一些条目。如果一切顺利,您将会看到两个条目,如下所示:

这两个条目代表发生的通信的两个部分。第一个是客户端对服务器的请求。当你点击第一个条目时,你会看到大量的信息:
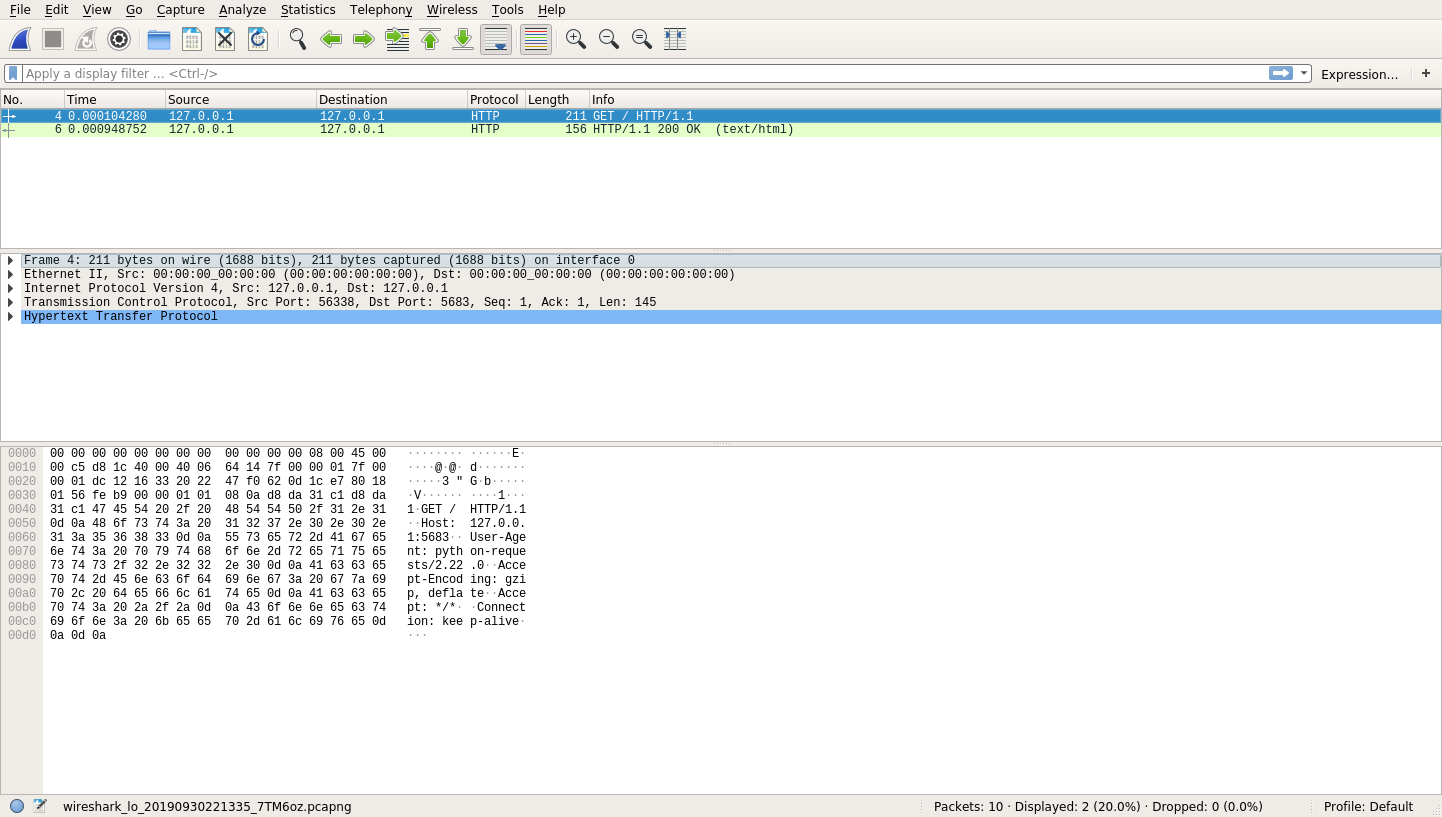
信息量真大!在顶部,仍然有 HTTP 请求和响应。一旦您选择了这些条目中的一个,您将看到中间和底部一行填充了信息。
中间一行提供了 Wireshark 能够为所选请求识别的协议的明细。这种分解允许您探究 HTTP 请求中实际发生了什么。下面是 Wireshark 在中间一行从上到下描述的信息的简要总结:
- **物理层:**这一行描述用于发送请求的物理接口。在您的情况下,这可能是环回接口的接口 ID 0 (lo)。
- **以太网信息:**这一行显示的是第二层协议,包括源 MAC 地址和目的 MAC 地址。
- IPv4: 这一行显示源和目的 IP 地址(127.0.0.1)。
- TCP: 这一行包括所需的 TCP 握手,以便创建可靠的数据管道。
- HTTP: 这一行显示 HTTP 请求本身的信息。
当您展开超文本传输协议层时,您可以看到构成 HTTP 请求的所有信息:
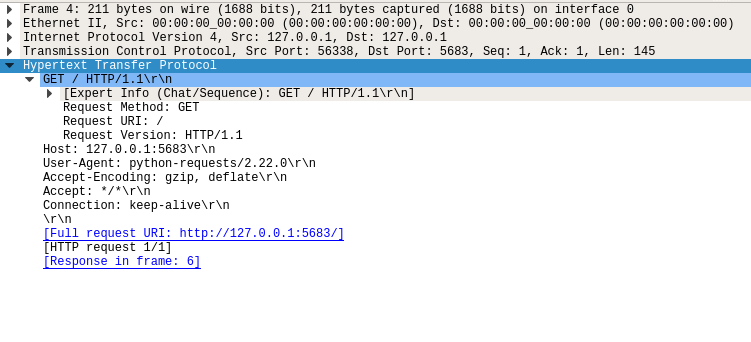
下图显示了脚本的 HTTP 请求:
- 方法:
GET - 路径:
/ - 版本:
1.1 - 表头:
Host: 127.0.0.1:5683``Connection: keep-alive等 - **正文:**无正文
您将看到的最后一行是数据的十六进制转储。您可能会注意到,在这个十六进制转储中,您实际上可以看到 HTTP 请求的各个部分。那是因为你的 HTTP 请求是公开发送的。但是回复呢?如果您单击 HTTP 响应,您将看到类似的视图:
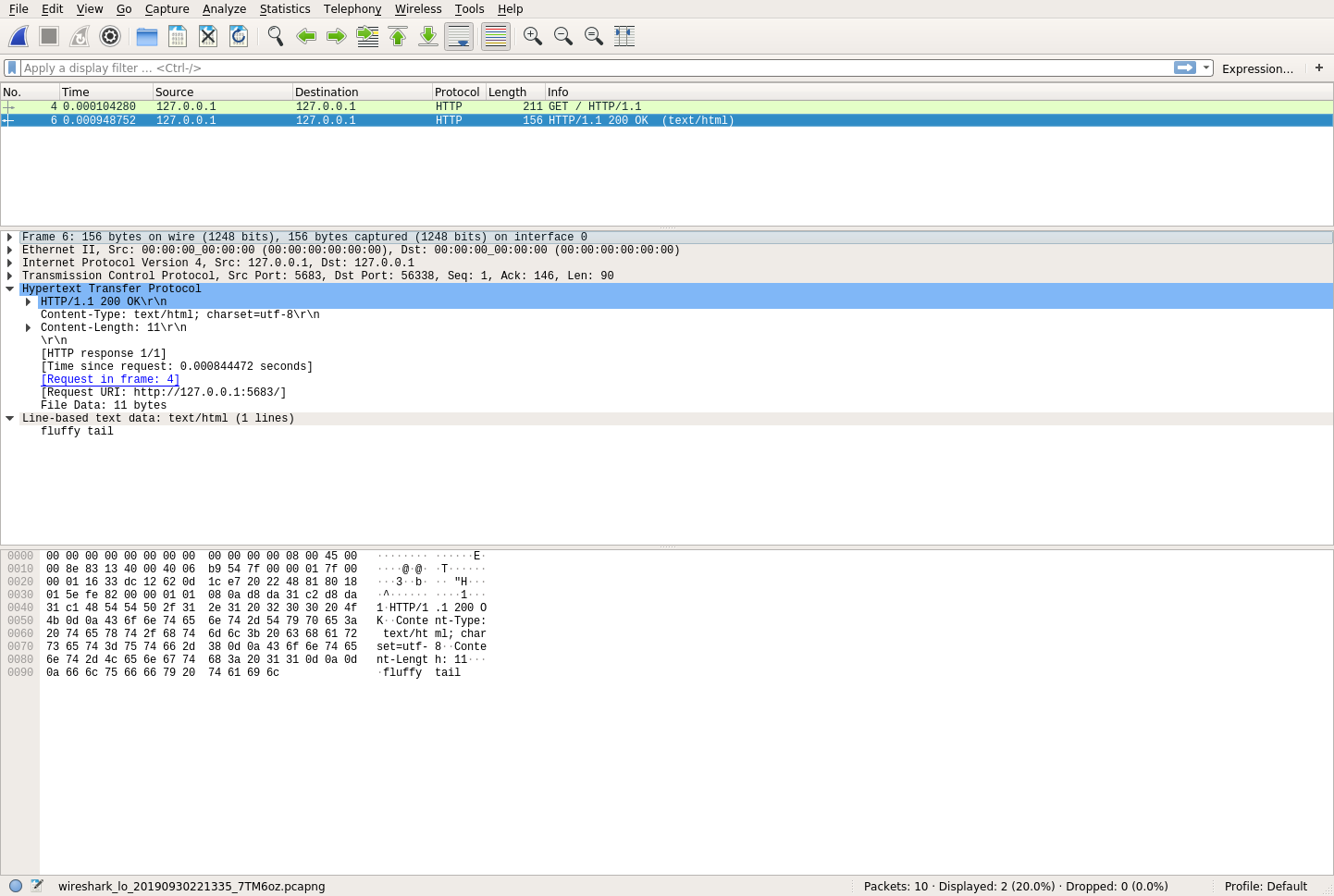
同样,你有相同的三个部分。如果你仔细看十六进制转储,那么你会看到纯文本的秘密消息!这对秘密松鼠来说是个大问题。这意味着任何有一些技术知识的人都可以很容易地看到这种流量,如果他们感兴趣的话。那么,如何解决这个问题呢?答案是密码学。
密码学有什么帮助?
在本节中,您将学习一种保护数据安全的方法,即创建您自己的加密密钥,并在您的服务器和客户端上使用它们。虽然这不是您的最后一步,但它将帮助您为如何构建 Python HTTPS 应用程序打下坚实的基础。
了解密码学基础知识
密码术是一种保护通信免受窃听者或对手攻击的方法。另一种说法是,你获取普通信息,称为明文,并将其转换为加密文本,称为密文。
起初,加密技术可能令人生畏,但是基本概念非常容易理解。事实上,你可能已经练习过密码学了。如果你曾经和你的朋友有过秘密语言,并且在课堂上用它来传递笔记,那么你就练习过密码学。(如果您还没有这样做,请不要担心,您即将这样做。)
不知何故,你需要把字符串 "fluffy tail"转换成不知所云的东西。一种方法是将某些字符映射到不同的字符上。一种有效的方法是将字符在字母表中向后移动一个位置。这样做看起来会像这样:
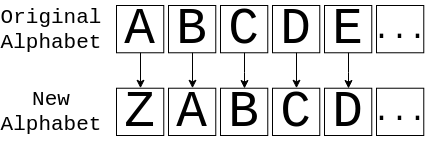
这张图片向你展示了如何从原来的字母表转换到新的字母表,然后再转换回来。所以,如果你有消息ABC,那么你实际上会发送消息ZAB。如果你把这个应用到"fluffy tail",那么假设空间保持不变,你得到ekteex szhk。虽然它并不完美,但对于任何看到它的人来说,它可能看起来像是胡言乱语。
恭喜你!你已经创造了密码学中所谓的密码,它描述了如何将明文转换成密文,以及如何将密文转换成明文。在这种情况下,你的密码是用英语描述的。这种特殊类型的密码被称为替代密码。从根本上来说,这与恩尼格玛机中使用的密码是同一类型的,尽管版本要简单得多。
现在,如果你想给秘密松鼠传递信息,你首先需要告诉它们要移动多少个字母,然后给它们编码的信息。在 Python 中,这可能如下所示:
CIPHER = {"a": "z", "A": "Z", "b": "a"} # And so on
def encrypt(plaintext: str):
return "".join(CIPHER.get(letter, letter) for letter in plaintext)
这里,您已经创建了一个名为encrypt()的函数,它将获取明文并将其转换为密文。想象一下,你有一本字典 CIPHER,里面有所有的字符。同样,你可以创建一个decrypt():
DECIPHER = {v: k for k, v in CIPHER.items()}
def decrypt(ciphertext: str):
return "".join(DECIPHER.get(letter, letter) for letter in ciphertext)
该功能与encrypt()相反。它将密文转换成明文。在这种形式的密码中,用户需要知道一个特殊的密钥来加密和解密消息。对于上面的例子,那个键是1。也就是说,密码指示您应该将每个字母向后移动一个字符。密钥对保密非常重要,因为任何有密钥的人都可以很容易地解密你的信息。
**注意:**虽然你可以用它来加密,但它还是不够安全。这种密码使用频率分析很快就能破解,而且对秘密松鼠来说太原始了。
在现代,加密技术要先进得多。它依靠复杂的数学理论和计算机科学来保证安全。虽然这些密码背后的数学问题超出了本教程的范围,但是基本概念仍然是相同的。你有一个描述如何将明文转换成密文的密码。
你的替代密码和现代密码之间唯一真正的区别是,现代密码在数学上被证明是无法被窃听者破解的。现在,让我们看看如何使用你的新密码。
在 Python HTTPS 应用程序中使用加密技术
幸运的是,你不必成为数学或计算机科学的专家来使用密码学。Python 还有一个secrets模块,可以帮助你生成加密安全的随机数据。在本教程中,你将学习一个名为 cryptography 的 Python 库。它在 PyPI 上可用,所以您可以用 pip 安装它:
$ pip install cryptography
这将把cryptography安装到你的虚拟环境中。安装了cryptography之后,你现在可以通过使用 Fernet 方法以一种数学上安全的方式加密和解密东西。
回想一下,您的密码中的密钥是1。同样,您需要为 Fernet 创建一个正确工作的密钥:
>>> from cryptography.fernet import Fernet
>>> key = Fernet.generate_key()
>>> key
b'8jtTR9QcD-k3RO9Pcd5ePgmTu_itJQt9WKQPzqjrcoM='
在这段代码中,您已经导入了Fernet并生成了一个密钥。密钥只是一堆字节,但是保持密钥的秘密和安全是非常重要的。就像上面的替换例子一样,任何拥有这个密钥的人都可以很容易地解密你的消息。
注意:在现实生活中,你会把这把钥匙保管得非常安全。在这些例子中,看到密钥是有帮助的,但是这是不好的做法,尤其是当你把它发布在公共网站上的时候!换句话说,不要使用你在上面看到的那把钥匙来保护你的安全。
这个键的行为与前面的键非常相似。它需要转换成密文,再转换回明文。现在是有趣的部分了!您可以像这样加密邮件:
>>> my_cipher = Fernet(key)
>>> ciphertext = my_cipher.encrypt(b"fluffy tail")
>>> ciphertext
b'gAAAAABdlW033LxsrnmA2P0WzaS-wk1UKXA1IdyDpmHcV6yrE7H_ApmSK8KpCW-6jaODFaeTeDRKJMMsa_526koApx1suJ4_dQ=='
在这段代码中,您创建了一个名为my_cipher的 Fernet 对象,然后您可以用它来加密您的消息。请注意,您的秘密消息"fluffy tail"需要是一个bytes对象才能加密。加密后,您可以看到ciphertext是一个很长的字节流。
多亏了 Fernet,没有密钥就无法操纵或读取这些密文!这种类型的加密要求服务器和客户端都可以访问密钥。当双方要求相同的密钥时,这被称为对称加密。在下一节中,您将看到如何使用这种对称加密来保护您的数据安全。
确保您的数据安全
现在,您已经了解了 Python 中的一些密码学基础知识,您可以将这些知识应用到您的服务器中。创建一个名为symmetric_server.py的新文件:
# symmetric_server.py
import os
from flask import Flask
from cryptography.fernet import Fernet
SECRET_KEY = os.environb[b"SECRET_KEY"]
SECRET_MESSAGE = b"fluffy tail"
app = Flask(__name__)
my_cipher = Fernet(SECRET_KEY)
@app.route("/")
def get_secret_message():
return my_cipher.encrypt(SECRET_MESSAGE)
这段代码结合了您的原始服务器代码和您在上一节中使用的Fernet对象。现在使用 os.environb 将关键点从环境中读取为bytes对象。随着服务器的退出,您现在可以专注于客户端。将以下内容粘贴到symmetric_client.py:
# symmetric_client.py
import os
import requests
from cryptography.fernet import Fernet
SECRET_KEY = os.environb[b"SECRET_KEY"]
my_cipher = Fernet(SECRET_KEY)
def get_secret_message():
response = requests.get("http://127.0.0.1:5683")
decrypted_message = my_cipher.decrypt(response.content)
print(f"The codeword is: {decrypted_message}")
if __name__ == "__main__":
get_secret_message()
同样,这是经过修改的代码,将您的早期客户端与Fernet加密机制结合起来。get_secret_message()执行以下操作:
- 向您的服务器发出请求。
- 从响应中获取原始字节。
- 尝试解密原始字节。
- 打印解密后的消息。
如果您同时运行服务器和客户端,那么您将看到您成功地加密和解密了您的秘密消息:
$ uwsgi --http-socket 127.0.0.1:5683 \
--env SECRET_KEY="8jtTR9QcD-k3RO9Pcd5ePgmTu_itJQt9WKQPzqjrcoM=" \
--mount /=symmetric_server:app
在这个调用中,您再次在端口 5683 上启动服务器。这一次,您传入一个SECRET_KEY,它必须至少是一个 32 长度的 base64 编码字符串。服务器重新启动后,您现在可以查询它:
$ SECRET_KEY="8jtTR9QcD-k3RO9Pcd5ePgmTu_itJQt9WKQPzqjrcoM=" python symmetric_client.py
The secret message is: b'fluffy tail'
呜哇!您可以加密和解密您的邮件。如果您尝试用无效的SECRET_KEY运行这个,那么您将得到一个错误:
$ SECRET_KEY="AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA=" python symmetric_client.py
Traceback (most recent call last):
File ".../cryptography/fernet.py", line 104, in _verify_signature
h.verify(data[-32:])
File ".../cryptography/hazmat/primitives/hmac.py", line 66, in verify
ctx.verify(signature)
File ".../cryptography/hazmat/backends/openssl/hmac.py", line 74, in verify
raise InvalidSignature("Signature did not match digest.")
cryptography.exceptions.InvalidSignature: Signature did not match digest.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "symmetric_client.py", line 16, in <module>
get_secret_message()
File "symmetric_client.py", line 11, in get_secret_message
decrypted_message = my_cipher.decrypt(response.content)
File ".../cryptography/fernet.py", line 75, in decrypt
return self._decrypt_data(data, timestamp, ttl)
File ".../cryptography/fernet.py", line 117, in _decrypt_data
self._verify_signature(data)
File ".../cryptography/fernet.py", line 106, in _verify_signature
raise InvalidToken
cryptography.fernet.InvalidToken
所以,你知道加密和解密是有效的。但是安全吗?嗯,是的,它是。为了证明这一点,您可以回到 Wireshark,使用与以前相同的过滤器开始新的捕获。完成捕获设置后,再次运行客户端代码:
$ SECRET_KEY="8jtTR9QcD-k3RO9Pcd5ePgmTu_itJQt9WKQPzqjrcoM=" python symmetric_client.py
The secret message is: b'fluffy tail'
您又一次成功地发出了 HTTP 请求和响应,您再次在 Wireshark 中看到这些消息。因为秘密消息只在响应中传输,所以您可以单击它来查看数据:
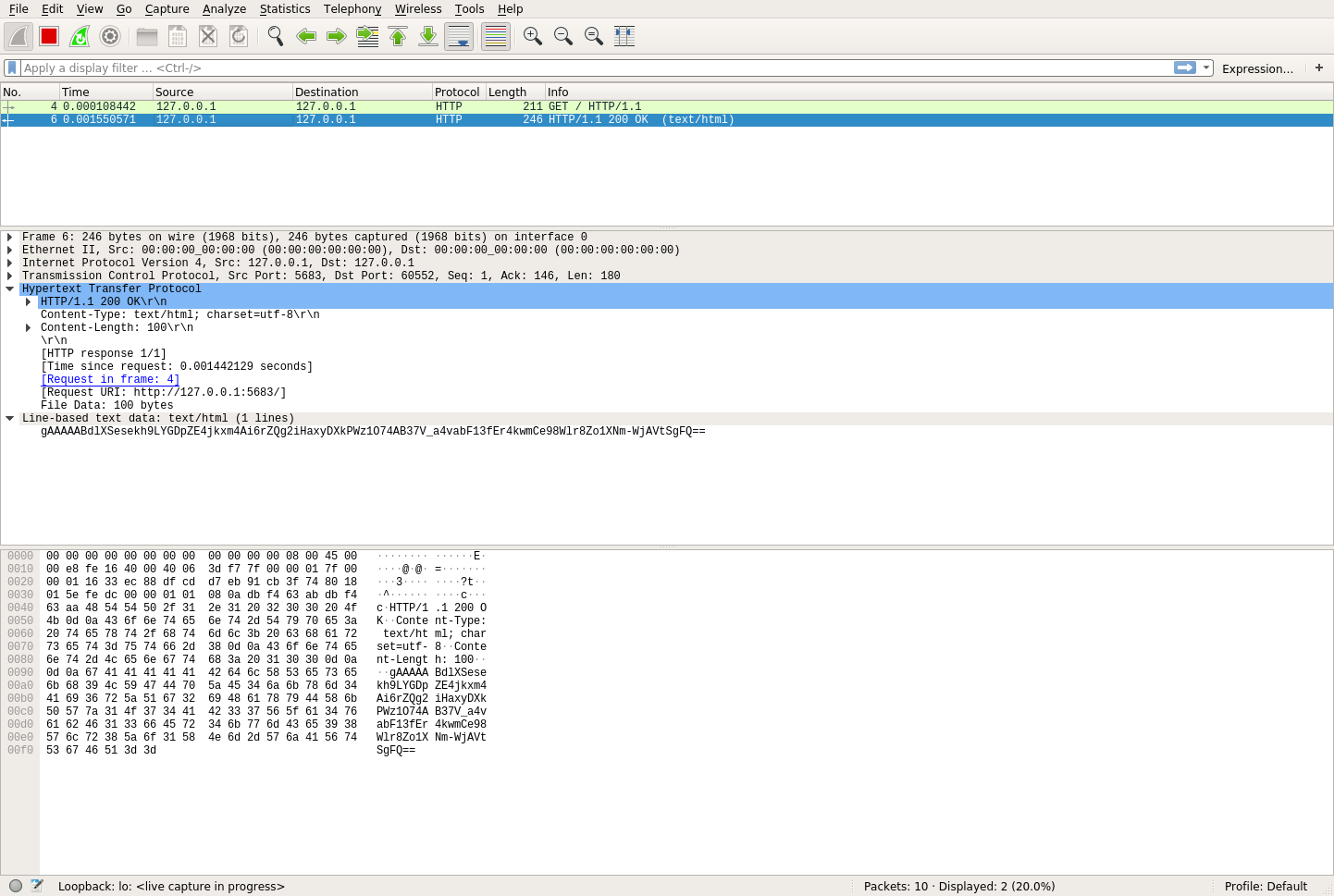
在这张图片的中间一行,您可以看到实际传输的数据:
gAAAAABdlXSesekh9LYGDpZE4jkxm4Ai6rZQg2iHaxyDXkPWz1O74AB37V_a4vabF13fEr4kwmCe98Wlr8Zo1XNm-WjAVtSgFQ==
厉害!这意味着数据是加密的,窃听者不知道消息的实际内容是什么。不仅如此,这还意味着他们可能会花费大量时间试图暴力破解这些数据,而且他们几乎永远不会成功。
您的数据是安全的!但是请等一下,以前在使用 Python HTTPS 应用程序时,您从来不需要了解任何关于键的知识。这是因为 HTTPS 并不专门使用对称加密。事实证明,共享秘密是一个难题。
为了证明这个概念,在浏览器中导航到http://127.0.0.1:5683,您将看到加密的响应文本。这是因为你的浏览器不知道你的秘密密钥。那么 Python HTTPS 应用程序到底是如何工作的呢?这就是不对称加密发挥作用的地方。
密钥是如何共享的?
在上一节中,您了解了如何使用对称加密来保证数据在互联网上传输时的安全。尽管对称加密是安全的,但它并不是 Python HTTPS 应用程序用来保护数据安全的唯一加密技术。对称加密引入了一些不容易解决的基本问题。
注意:记住,对称加密要求您在客户端和服务器之间有一个共享密钥。不幸的是,安全性的发挥取决于您最薄弱的环节,而在对称加密中,薄弱环节尤其具有灾难性。一旦一个人泄露了密钥,那么每个密钥都会被泄露。可以肯定的是,任何安全系统都会在某个时候受到威胁。
那么,你如何改变你的密钥呢?如果您只有一个服务器和一个客户端,那么这可能是一个快速的任务。然而,随着越来越多的客户端和服务器的出现,需要进行越来越多的协调来有效地更改密钥和保护您的秘密。
而且,你每次都要选择一个新的秘密。在上面的例子中,您看到了一个随机生成的密钥。对你来说,试图让人们记住那把钥匙几乎是不可能的。随着客户机和服务器数量的增加,您可能会使用更容易记忆和猜测的密钥。
如果您可以处理密钥的更改,那么您还有一个问题需要解决。你如何分享你的初始密钥?在秘密松鼠的例子中,您通过物理访问每个成员解决了这个问题。你可以亲自给每个成员这个秘密,并告诉他们要保密,但是记住,有人将是最薄弱的环节。
现在,假设您从另一个物理位置向秘密松鼠添加了一个成员。你如何与这个成员分享这个秘密?每次换钥匙的时候你都让他们带飞机去找你吗?如果你能把秘钥放在你的服务器上并自动共享就好了。不幸的是,这将违背加密的全部目的,因为任何人都可以获得密钥!
当然,你可以给每个人一个初始主密钥来获取秘密信息,但是现在你的问题是以前的两倍。如果你头疼,那就别担心!你不是唯一一个。
你需要的是从未交流过的两方共享一个秘密。听起来不可能,对吧?幸运的是,三个名叫拉尔夫·默克、T2、惠特菲尔德·迪菲和 T4 的人会支持你。他们帮助证明了公钥加密,也就是不对称加密是可能的。
**注:**虽然惠特菲尔德·迪菲和马丁·赫尔曼被广泛认为是第一个发现这一阴谋的人,但在 1997 年,为 GCHQ 工作的三名男子詹姆斯·h·埃利斯、克利福德·考克和马尔科姆·j·威廉森早在七年前就展示了这一能力!
非对称加密允许两个从未交流过的用户共享一个秘密。理解基本原理的最简单的方法之一是使用颜色类比。假设您有以下场景:

在这张图中,你正试图与一只你从未见过的秘密松鼠交流,但间谍可以看到你发送的所有内容。您知道对称加密,并且想要使用它,但是您首先需要共享一个秘密。幸运的是,你们俩都有一把私人钥匙。不幸的是,你不能发送你的私钥,因为间谍会看到它。那你是做什么的?
你需要做的第一件事是和你的搭档就颜色达成一致,比如黄色:

请注意,间谍可以看到共享的颜色,你和秘密松鼠也可以。共享颜色有效地公开。现在,你和秘密松鼠都把你的私人钥匙和共享颜色结合起来:

你的颜色组合成绿色,而秘密松鼠的颜色组合成橙色。你们两个都使用完了共享颜色,现在你们需要彼此共享你们的组合颜色:

你现在有了你的私人钥匙和秘密松鼠的混合颜色。同样,秘密松鼠有他们的私人钥匙和你的组合颜色。你和秘密松鼠很快就把颜色组合起来了。
然而,间谍只有这些混合的颜色。试图找出你的确切的原始颜色是非常困难的,即使给定了最初的共享颜色。间谍将不得不去商店买许多不同的蓝色来尝试。即使这样,也很难知道他们看的是不是正确的绿色。简而言之,你的私钥仍然是私有的。
但是你和秘密松鼠呢?你还是没有组合秘密!这就是你的私钥的来源。如果你把你的私人钥匙和你从秘密松鼠那里得到的混合颜色结合起来,那么你们最终会得到相同的颜色:

现在,你和秘密松鼠有着相同的秘密颜色。您现在已经成功地与一个完全陌生的人共享了一个安全的秘密。这与公钥加密的工作原理惊人地一致。这一系列事件的另一个常见名称是 Diffie-Hellman 密钥交换。密钥交换由以下部分组成:
- 私钥是例子中你的私有颜色。
- 公钥是您共享的组合色。
私钥是你一直保密的东西,而公钥可以和任何人共享。这些概念直接映射到 Python HTTPS 应用程序的真实世界。现在,服务器和客户机有了一个共享的秘密,您可以使用以前的 pal 对称加密来加密所有进一步的消息!
**注意:**公钥加密也依赖于一些数学来进行颜色混合。关于 Diffie-Hellman 密钥交换的维基百科页面有很好的解释,但是深入的解释超出了本教程的范围。
当您通过安全网站(如本网站)进行通信时,您的浏览器和服务器会使用相同的原则建立安全通信:
- 您的浏览器向服务器请求信息。
- 您的浏览器和服务器交换公钥。
- 您的浏览器和服务器生成一个共享私钥。
- 您的浏览器和服务器通过对称加密使用这个共享密钥加密和解密消息。
幸运的是,您不需要实现这些细节。有许多内置的和第三方的库可以帮助您保持客户端和服务器通信的安全。
现实世界中的 HTTPS 是什么样的?
鉴于所有这些关于加密的信息,让我们缩小一点,谈谈 Python HTTPS 应用程序在现实世界中是如何工作的。加密只是故事的一半。访问安全网站时,需要两个主要组件:
- 加密将明文转换成密文,再转换回来。
- 认证验证一个人或一件事是他们所说的那个人或事。
您已经广泛听说了加密是如何工作的,但是身份验证呢?要理解现实世界中的认证,您需要了解公钥基础设施。PKI 在安全生态系统中引入了另一个重要的概念,称为证书。
证书就像互联网的护照。像计算机世界中的大多数东西一样,它们只是文件中的大块数据。一般来说,证书包括以下信息:
- **颁发给:**标识谁拥有证书
- **颁发者:**标识证书的颁发者
- **有效期:**标识证书有效的时间范围
就像护照一样,证书只有在由某个权威机构生成并认可的情况下才真正有用。让你的浏览器知道你在互联网上访问的每个网站的每一个证书是不切实际的。相反,PKI 依赖于一个被称为认证机构(CA) 的概念。
证书颁发机构负责颁发证书。它们被认为是 PKI 中可信任的第三方(TTP)。本质上,这些实体充当证书的有效机构。假设你想去另一个国家,你有一本护照,上面有你所有的信息。外国的移民官员如何知道你的护照包含有效信息?
如果你要自己填写所有信息并签字,那么你要去的每个国家的每个移民官员都需要亲自了解你,并能够证明那里的信息确实是正确的。
另一种处理方式是将你的所有信息发送给一个可信的第三方(TTP) 。TTP 会对你提供的信息进行彻底的调查,核实你的说法,然后在你的护照上签字。这被证明是更实际的,因为移民官员只需要知道可信任的第三方。
TTP 场景是证书在实践中的处理方式。这个过程大概是这样的:
- 创建证书签名请求(CSR): 这就像填写签证信息一样。
- 将 CSR 发送给可信任的第三方(TTP): 这就像将您的信息发送到签证申请办公室。
- **核实您的信息:**TTP 需要核实您提供的信息。例如,请看亚马逊如何验证所有权。
- **生成公钥:**TTP 签署您的 CSR。这就相当于 TTP 签了你的签证。
- **发布验证过的公钥:**这相当于你在邮件中收到了你的签证。
请注意,CSR 以加密方式与您的私钥绑定在一起。因此,所有三种信息——公钥、私钥和证书颁发机构——都以某种方式相关联。这就创建了所谓的信任链,所以你现在有了一个可以用来验证你的身份的有效证书。
大多数情况下,这只是网站所有者的责任。网站所有者将遵循所有这些步骤。在此过程结束时,他们的证书会显示以下内容:
从时间
A到时间B根据Y我是X
这句话是一个证书真正告诉你的全部。变量可以按如下方式填写:
- A 是有效的开始日期和时间。
- B 是有效的结束日期和时间。
- X 是服务器的名称。
- Y 是认证机构的名称。
从根本上说,这就是证书所描述的全部内容。换句话说,有证书并不一定意味着你就是你所说的那个人,只是你得到了Y到同意你就是你所说的那个人。这就是可信第三方的“可信”部分的用武之地。
TTP 需要在客户机和服务器之间共享,以便每个人都对 HTTPS 握手感到满意。您的浏览器附带了许多自动安装的证书颁发机构。要查看它们,请执行以下步骤:
- Chrome: 进入设置>高级>隐私和安全>管理证书>权限。
- **火狐:**进入设置>首选项>隐私&安全>查看证书>权限。
这涵盖了在现实世界中创建 Python HTTPS 应用程序所需的基础设施。在下一节中,您将把这些概念应用到您自己的代码中。您将通过最常见的例子,并成为自己的秘密松鼠认证机构!
Python HTTPS 应用程序看起来像什么?
现在,您已经了解了创建 Python HTTPS 应用程序所需的基本部分,是时候将所有部分逐一整合到您之前的应用程序中了。这将确保服务器和客户端之间的通信是安全的。
在您自己的机器上建立整个 PKI 基础设施是可能的,这正是您将在本节中要做的。没有听起来那么难,放心吧!成为一个真正的证书颁发机构比采取下面的步骤要困难得多,但是你将读到的或多或少都是运行你自己的 CA 所需要的。
成为认证机构
认证中心只不过是一对非常重要的公钥和私钥。要成为一个 CA,您只需要生成一个公钥和私钥对。
**注意:**成为公众使用的 CA 是一个非常艰难的过程,尽管有许多公司都遵循这一过程。然而,在本教程结束时,你将不再是那些公司中的一员!
您的初始公钥和私钥对将是一个自签名证书。你正在生成初始的秘密,所以如果你真的要成为一个 CA,那么这个私钥的安全是非常重要的。如果有人可以访问 CA 的公钥和私钥对,那么他们可以生成一个完全有效的证书,除了停止信任您的 CA 之外,您无法检测到这个问题。
有了这个警告,您可以立即生成证书。首先,您需要生成一个私钥。将以下内容粘贴到名为pki_helpers.py的文件中:
1# pki_helpers.py
2from cryptography.hazmat.backends import default_backend
3from cryptography.hazmat.primitives import serialization
4from cryptography.hazmat.primitives.asymmetric import rsa
5
6def generate_private_key(filename: str, passphrase: str):
7 private_key = rsa.generate_private_key(
8 public_exponent=65537, key_size=2048, backend=default_backend()
9 )
10
11 utf8_pass = passphrase.encode("utf-8")
12 algorithm = serialization.BestAvailableEncryption(utf8_pass)
13
14 with open(filename, "wb") as keyfile:
15 keyfile.write(
16 private_key.private_bytes(
17 encoding=serialization.Encoding.PEM,
18 format=serialization.PrivateFormat.TraditionalOpenSSL,
19 encryption_algorithm=algorithm,
20 )
21 )
22
23 return private_key
generate_private_key()使用 RSA 生成私钥。下面是代码的细目分类:
- 第 2 行到第 4 行导入函数工作所需的库。
- 第 7 行到第 9 行使用 RSA 生成一个私钥。幻数
65537和2048只是两个可能的值。你可以阅读更多关于为什么或者只是相信这些数字是有用的。 - 第 11 行到第 12 行设置用于您的私钥的加密算法。
- 第 14 到 21 行在指定的
filename把你的私钥写到磁盘上。该文件使用提供的密码加密。
成为您自己的 CA 的下一步是生成一个自签名公钥。您可以绕过证书签名请求(CSR ),立即构建公钥。将以下内容粘贴到pki_helpers.py:
1# pki_helpers.py
2from datetime import datetime, timedelta
3from cryptography import x509
4from cryptography.x509.oid import NameOID
5from cryptography.hazmat.primitives import hashes
6
7def generate_public_key(private_key, filename, **kwargs):
8 subject = x509.Name(
9 [
10 x509.NameAttribute(NameOID.COUNTRY_NAME, kwargs["country"]),
11 x509.NameAttribute(
12 NameOID.STATE_OR_PROVINCE_NAME, kwargs["state"]
13 ),
14 x509.NameAttribute(NameOID.LOCALITY_NAME, kwargs["locality"]),
15 x509.NameAttribute(NameOID.ORGANIZATION_NAME, kwargs["org"]),
16 x509.NameAttribute(NameOID.COMMON_NAME, kwargs["hostname"]),
17 ]
18 )
19
20 # Because this is self signed, the issuer is always the subject
21 issuer = subject
22
23 # This certificate is valid from now until 30 days
24 valid_from = datetime.utcnow()
25 valid_to = valid_from + timedelta(days=30)
26
27 # Used to build the certificate
28 builder = (
29 x509.CertificateBuilder()
30 .subject_name(subject)
31 .issuer_name(issuer)
32 .public_key(private_key.public_key())
33 .serial_number(x509.random_serial_number())
34 .not_valid_before(valid_from)
35 .not_valid_after(valid_to)
36 .add_extension(x509.BasicConstraints(ca=True,
37 path_length=None), critical=True)
38 )
39
40 # Sign the certificate with the private key
41 public_key = builder.sign(
42 private_key, hashes.SHA256(), default_backend()
43 )
44
45 with open(filename, "wb") as certfile:
46 certfile.write(public_key.public_bytes(serialization.Encoding.PEM))
47
48 return public_key
这里有一个新函数generate_public_key(),它将生成一个自签名的公钥。下面是这段代码的工作原理:
- 第 2 行到第 5 行是函数工作所需的导入。
- 第 8 行到第 18 行建立关于证书主题的信息。
- 第 21 行使用相同的颁发者和主题,因为这是一个自签名证书。
- 第 24 到 25 行表示该公钥有效的时间范围。在这种情况下,是 30 天。
- 第 28 到 38 行将所有需要的信息添加到一个公钥生成器对象中,然后需要对其进行签名。
- 第 41 到 43 行用私钥签署公钥。
- 第 45 到 46 行将公钥写出到
filename。
使用这两个函数,您可以在 Python 中非常快速地生成您的私钥和公钥对:
>>> from pki_helpers import generate_private_key, generate_public_key
>>> private_key = generate_private_key("ca-private-key.pem", "secret_password")
>>> private_key
<cryptography.hazmat.backends.openssl.rsa._RSAPrivateKey object at 0x7ffbb292bf90>
>>> generate_public_key(
... private_key,
... filename="ca-public-key.pem",
... country="US",
... state="Maryland",
... locality="Baltimore",
... org="My CA Company",
... hostname="my-ca.com",
... )
<Certificate(subject=<Name(C=US,ST=Maryland,L=Baltimore,O=My CA Company,CN=logan-ca.com)>, ...)>
从pki_helpers导入您的助手函数后,您首先生成您的私钥并将其保存到文件ca-private-key.pem。然后,您将这个私钥传递给generate_public_key()来生成您的公钥。在您的目录中,现在应该有两个文件:
$ ls ca*
ca-private-key.pem ca-public-key.pem
恭喜你!您现在有能力成为证书颁发机构。
信任您的服务器
您的服务器变得可信的第一步是生成一个证书签名请求(CSR) 。在现实世界中,CSR 将被发送到实际的认证机构,如 Verisign 或让我们加密。在本例中,您将使用刚刚创建的 CA。
将生成 CSR 的代码从上面粘贴到pki_helpers.py文件中:
1# pki_helpers.py
2def generate_csr(private_key, filename, **kwargs):
3 subject = x509.Name(
4 [
5 x509.NameAttribute(NameOID.COUNTRY_NAME, kwargs["country"]),
6 x509.NameAttribute(
7 NameOID.STATE_OR_PROVINCE_NAME, kwargs["state"]
8 ),
9 x509.NameAttribute(NameOID.LOCALITY_NAME, kwargs["locality"]),
10 x509.NameAttribute(NameOID.ORGANIZATION_NAME, kwargs["org"]),
11 x509.NameAttribute(NameOID.COMMON_NAME, kwargs["hostname"]),
12 ]
13 )
14
15 # Generate any alternative dns names
16 alt_names = [] 17 for name in kwargs.get("alt_names", []): 18 alt_names.append(x509.DNSName(name)) 19 san = x509.SubjectAlternativeName(alt_names) 20
21 builder = ( 22 x509.CertificateSigningRequestBuilder() 23 .subject_name(subject) 24 .add_extension(san, critical=False) 25 ) 26
27 csr = builder.sign(private_key, hashes.SHA256(), default_backend()) 28
29 with open(filename, "wb") as csrfile: 30 csrfile.write(csr.public_bytes(serialization.Encoding.PEM)) 31
32 return csr
在很大程度上,这段代码与您生成原始公钥的方式相同。主要区别概述如下:
- 第 16 行到第 19 行设置备用 DNS 名称,这些名称对您的证书有效。
- 第 21 行到第 25 行生成一个不同的构建器对象,但基本原理和以前一样。你正在为你的企业社会责任建立所有必要的属性。
- 第 27 行用私钥给你的 CSR 签名。
- 第 29 到 30 行以 PEM 格式将您的 CSR 写入磁盘。
您会注意到,为了创建 CSR,您首先需要一个私钥。幸运的是,您可以使用与创建 CA 私钥时相同的generate_private_key()。使用上述函数和前面定义的方法,您可以执行以下操作:
>>> from pki_helpers import generate_csr, generate_private_key
>>> server_private_key = generate_private_key(
... "server-private-key.pem", "serverpassword"
... )
>>> server_private_key
<cryptography.hazmat.backends.openssl.rsa._RSAPrivateKey object at 0x7f6adafa3050>
>>> generate_csr(
... server_private_key,
... filename="server-csr.pem",
... country="US",
... state="Maryland",
... locality="Baltimore",
... org="My Company",
... alt_names=["localhost"],
... hostname="my-site.com",
... )
<cryptography.hazmat.backends.openssl.x509._CertificateSigningRequest object at 0x7f6ad5372210>
在控制台中运行这些步骤后,您应该得到两个新文件:
server-private-key.pem: 你服务器的私钥server-csr.pem: 您的服务器的 CSR
您可以从控制台查看新的 CSR 和私钥:
$ ls server*.pem
server-csr.pem server-private-key.pem
有了这两个文档,您现在可以开始签名您的密钥了。通常,这一步会进行大量的验证。在现实世界中,CA 会确保您拥有my-site.com,并要求您以各种方式证明这一点。
因为在这种情况下您是 CA,所以您可以放弃这个麻烦,创建您自己的经过验证的公钥。为此,您将向您的pki_helpers.py文件添加另一个函数:
1# pki_helpers.py
2def sign_csr(csr, ca_public_key, ca_private_key, new_filename):
3 valid_from = datetime.utcnow()
4 valid_until = valid_from + timedelta(days=30)
5
6 builder = (
7 x509.CertificateBuilder()
8 .subject_name(csr.subject) 9 .issuer_name(ca_public_key.subject) 10 .public_key(csr.public_key()) 11 .serial_number(x509.random_serial_number())
12 .not_valid_before(valid_from)
13 .not_valid_after(valid_until)
14 )
15
16 for extension in csr.extensions: 17 builder = builder.add_extension(extension.value, extension.critical) 18
19 public_key = builder.sign(
20 private_key=ca_private_key, 21 algorithm=hashes.SHA256(),
22 backend=default_backend(),
23 )
24
25 with open(new_filename, "wb") as keyfile:
26 keyfile.write(public_key.public_bytes(serialization.Encoding.PEM))
这段代码看起来与来自generate_ca.py文件的generate_public_key()非常相似。事实上,它们几乎一模一样。主要区别如下:
- 第 8 行到第 9 行基于 CSR 的主题名称,而发布者基于证书颁发机构。
- 10 号线这次从 CSR 获取公钥。在
builder定义的末尾,generate_public_key()中指定这是一个 CA 的行已经被删除。 - 第 16 到 17 行复制 CSR 上设置的任何扩展。
- 第 20 行用 CA 的私钥签署公钥。
下一步是启动 Python 控制台并使用sign_csr()。您需要加载您的 CSR 和 CA 的私钥和公钥。首先加载您的 CSR:
>>> from cryptography import x509
>>> from cryptography.hazmat.backends import default_backend
>>> csr_file = open("server-csr.pem", "rb")
>>> csr = x509.load_pem_x509_csr(csr_file.read(), default_backend())
>>> csr
<cryptography.hazmat.backends.openssl.x509._CertificateSigningRequest object at 0x7f68ae289150>
在这段代码中,你将打开你的server-csr.pem文件,并使用x509.load_pem_x509_csr()创建你的csr对象。接下来,您需要加载 CA 的公钥:
>>> ca_public_key_file = open("ca-public-key.pem", "rb")
>>> ca_public_key = x509.load_pem_x509_certificate(
... ca_public_key_file.read(), default_backend()
... )
>>> ca_public_key
<Certificate(subject=<Name(C=US,ST=Maryland,L=Baltimore,O=My CA Company,CN=logan-ca.com)>, ...)>
你又一次创建了一个可以被sign_csr()使用的ca_public_key对象。“T2”号有方便的“T3”帮忙。最后一步是加载 CA 的私钥:
>>> from getpass import getpass
>>> from cryptography.hazmat.primitives import serialization
>>> ca_private_key_file = open("ca-private-key.pem", "rb")
>>> ca_private_key = serialization.load_pem_private_key(
... ca_private_key_file.read(),
... getpass().encode("utf-8"),
... default_backend(),
... )
Password:
>>> private_key
<cryptography.hazmat.backends.openssl.rsa._RSAPrivateKey object at 0x7f68a85ade50>
这段代码将加载您的私钥。回想一下,您的私钥是使用您指定的密码加密的。有了这三个组件,您现在可以签署您的 CSR 并生成一个经过验证的公钥:
>>> from pki_helpers import sign_csr
>>> sign_csr(csr, ca_public_key, ca_private_key, "server-public-key.pem")
运行此命令后,您的目录中应该有三个服务器密钥文件:
$ ls server*.pem
server-csr.pem server-private-key.pem server-public-key.pem
咻!那是相当多的工作。好消息是,现在您已经有了您的私有和公共密钥对,您不需要修改任何服务器代码就可以开始使用它。
使用原始的server.py文件,运行以下命令来启动全新的 Python HTTPS 应用程序:
$ uwsgi \
--master \
--https localhost:5683,\
logan-site.com-public-key.pem,\
logan-site.com-private-key.pem \
--mount /=server:app
恭喜你!现在,您有了一个支持 Python HTTPS 的服务器,它使用您自己的私有-公共密钥对运行,并由您自己的认证机构进行了签名!
注意:Python HTTPS 认证等式还有另外一面,那就是客户端。也可以为客户端证书设置证书验证。这需要更多的工作,在企业之外并不常见。然而,客户端身份验证可能是一个非常强大的工具。
现在,剩下要做的就是查询您的服务器。首先,您需要对client.py代码进行一些修改:
# client.py
import os
import requests
def get_secret_message():
response = requests.get("https://localhost:5683")
print(f"The secret message is {response.text}")
if __name__ == "__main__":
get_secret_message()
与之前代码的唯一变化是从http到https。如果您尝试运行这段代码,您将会遇到一个错误:
$ python client.py
...
requests.exceptions.SSLError: \
HTTPSConnectionPool(host='localhost', port=5683): \
Max retries exceeded with url: / (Caused by \
SSLError(SSLCertVerificationError(1, \
'[SSL: CERTIFICATE_VERIFY_FAILED] \
certificate verify failed: unable to get local issuer \
certificate (_ssl.c:1076)')))
这是一个非常讨厌的错误信息!这里重要的部分是消息certificate verify failed: unable to get local issuer。这些话你现在应该比较熟悉了。本质上,它是在说:
localhost:5683 给了我一个证书。我检查了它给我的证书的颁发者,根据我所知道的所有证书颁发机构,该颁发者不在其中。
如果您尝试使用浏览器导航到您的网站,您会收到类似的消息:
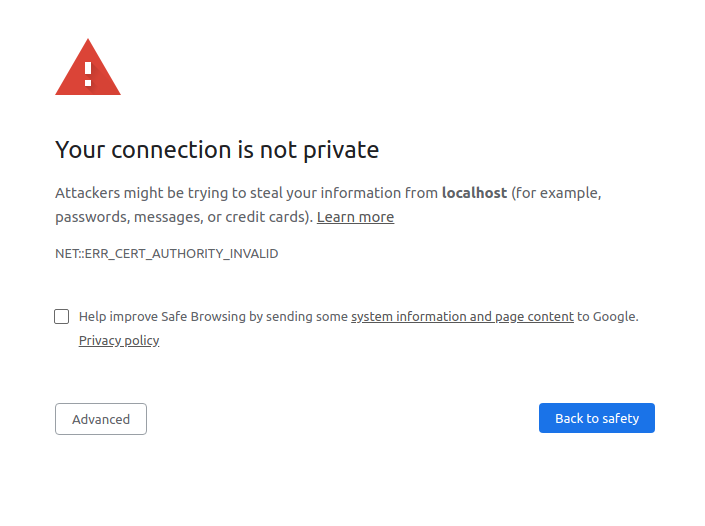
如果您想避免此消息,那么您必须告诉requests您的证书颁发机构!您需要做的就是将请求指向您之前生成的ca-public-key.pem文件:
# client.py
def get_secret_message():
response = requests.get("http://localhost:5683", verify="ca-public-key.pem")
print(f"The secret message is {response.text}")
完成后,您应该能够成功运行以下内容:
$ python client.py
The secret message is fluffy tail
不错!您已经创建了一个功能完整的 Python HTTPS 服务器,并成功查询了它。你和秘密松鼠现在有消息,你可以愉快和安全地来回交易!
结论
在本教程中,你已经了解了当今互联网上安全通信的一些核心基础。现在您已经理解了这些构件,您将成为一名更好、更安全的开发人员。
通过本教程,您已经了解了几个主题:
- 密码系统
- HTTPS 和 TLS
- 公钥基础设施
- 证书
如果这些信息让你感兴趣,那么你很幸运!你仅仅触及了每一层中所有细微差别的表面。安全世界在不断发展,新技术和漏洞也在不断被发现。如果你还有问题,请在下面的评论区或在 Twitter 上联系我们。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 探索 Python 中的 HTTPS 和密码学***********
Python IDEs 和代码编辑器(指南)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 寻找完美的 Python 代码编辑器
使用 IDLE 或 Python Shell 编写 Python 对于简单的事情来说是很棒的,但是这些工具很快会将大型编程项目变成令人沮丧的绝望之地。使用 IDE,或者仅仅是一个好的专用代码编辑器,会让编码变得有趣——但是哪一个最适合你呢?
不要害怕,亲爱的读者!我们在这里帮助你解释和揭开无数可供选择的秘密。我们无法选择最适合您和您的流程的方法,但是我们可以解释每种方法的优缺点,并帮助您做出明智的决定。
为了使事情变得简单,我们将把我们的列表分成两大类工具:一类是专门为 Python 开发构建的,另一类是为可以用于 Python 的一般开发构建的。我们将为每个问题说出一些为什么和为什么不。最后,这些选项都不是相互排斥的,所以您可以自己尝试一下,代价很小。
但是首先…
什么是 ide 和代码编辑器?
IDE(或集成开发环境)是专用于软件开发的程序。顾名思义,ide 集成了几个专门为软件开发设计的工具。这些工具通常包括:
- 为处理代码而设计的编辑器(例如,带有语法突出显示和自动完成功能)
- 构建、执行和调试工具
- 某种形式的源代码管理
大多数 ide 支持许多不同的编程语言,并包含更多的特性。因此,它们可能很大,下载和安装需要时间。您可能还需要高级知识来正确使用它们。
相比之下,专用代码编辑器可以像文本编辑器一样简单,具有语法突出显示和代码格式化功能。大多数好的代码编辑器可以执行代码并控制一个调试器。最好的软件也与源代码控制系统交互。与 IDE 相比,一个好的专用代码编辑器通常更小、更快,但是功能不丰富。
良好的 Python 编码环境的要求
那么在编码环境中我们真正需要的是什么呢?功能列表因应用而异,但有一组核心功能可以简化编码:
- 保存并重新加载代码文件
如果一个 IDE 或编辑器不允许你保存你的工作,并在你离开时以同样的状态重新打开一切,那它就不是一个好的 IDE。 - 在环境中运行代码
同样,如果你不得不退出编辑器来运行你的 Python 代码,那么它也不过是一个简单的文本编辑器。 - 调试支持
能够在代码运行时逐句通过代码是所有 ide 和大多数优秀代码编辑器的核心特性。 - 语法突出显示
能够快速发现代码中的关键词、变量和符号使得阅读和理解代码更加容易。 - 自动代码格式化
任何称职的编辑器或 IDE 都会识别出while或for语句末尾的冒号,并知道下一行应该缩进。
当然,您可能还需要许多其他特性,比如源代码控制、扩展模型、构建和测试工具、语言帮助等等。但是上面的列表是我认为一个好的编辑环境应该支持的“核心特性”。
记住这些特性,让我们来看看一些可以用于 Python 开发的通用工具。
支持 Python 的通用编辑器和 IDEs】
Eclipse + PyDev
类别: IDE
网站:www.eclipse.org
Python 工具: PyDev,www.pydev.org
如果你在开源社区呆过一段时间,你应该听说过 Eclipse。适用于 Linux、Windows 和 OS X 的 Eclipse 是 Java 开发的事实上的开源 IDE。它有一个丰富的扩展和附加组件市场,这使得 Eclipse 对于广泛的开发活动非常有用。
PyDev 就是这样一个扩展,它支持 Python 调试、代码完成和交互式 Python 控制台。将 PyDev 安装到 Eclipse 很容易:从 Eclipse 中选择 Help,Eclipse Marketplace,然后搜索 PyDev。如有必要,单击 Install 并重启 Eclipse。
**优点:**如果你已经安装了 Eclipse,添加 PyDev 会更快更容易。对于有经验的 Eclipse 开发人员来说,PyDev 非常容易使用。
缺点:如果你刚刚开始使用 Python,或者一般的软件开发,Eclipse 可能会很难处理。还记得我说过 ide 比较大,需要更多的知识才能正确使用吗?Eclipse 就是所有这些和一袋(微型)芯片。
崇高的文字
**类别:**代码编辑
网站:http://www.sublimetext.com
Sublime Text 是由一个梦想拥有更好的文本编辑器的 Google 工程师编写的,是一个非常受欢迎的代码编辑器。所有平台都支持 Sublime Text,它内置了对 Python 代码编辑的支持和一组丰富的扩展(称为包),这些扩展扩展了语法和编辑功能。
安装额外的 Python 包可能很棘手:所有 Sublime 文本包都是用 Python 本身编写的,安装社区包通常需要你直接在 Sublime 文本中执行 Python 脚本。
优点: Sublime Text 在社区中有很多追随者。作为一个代码编辑器,单独来说,Sublime Text 很快,很小,并且得到很好的支持。
缺点: Sublime Text 不是免费的,虽然你可以无限期使用评估版。安装扩展可能很棘手,并且没有从编辑器中执行或调试代码的直接支持。
为了充分利用您的 Sublime Text 设置,请阅读我们的 Python + Sublime Text 设置指南,并考虑我们的深度视频课程,该课程将向您展示如何使用 Sublime Text 3 创建有效的 Python 开发设置。
Atom
**类别:**代码编辑
网站:https://atom.io/
Atom 可在所有平台上使用,被宣传为“21 世纪可破解的文本编辑器”。凭借时尚的界面、文件系统浏览器和扩展市场,开源 Atom 是使用 Electron 构建的,这是一个使用 JavaScript 、 HTML 和 CSS 创建桌面应用程序的框架。Python 语言支持由一个扩展提供,该扩展可以在 Atom 运行时安装。
优点:多亏了 Electron,它在所有平台上都有广泛的支持。Atom 很小,所以下载和加载速度很快。
**缺点:**构建和调试支持不是内置的,而是社区提供的附加组件。因为 Atom 是基于 Electron 构建的,所以它总是在 JavaScript 进程中运行,而不是作为原生应用程序。
GNU Emacs
**类别:**代码编辑
网站:https://www.gnu.org/software/emacs/
早在 iPhone vs Android 大战之前,在 Linux vs Windows 大战之前,甚至在 PC vs Mac 大战之前,就有了编辑器大战,GNU Emacs 作为参战方之一。GNU Emacs 被宣传为“可扩展、可定制、自我文档化的实时显示编辑器”,它几乎和 UNIX 一样存在了很长时间,并拥有狂热的追随者。
GNU Emacs 总是免费的,在每个平台上都可用(以某种形式),它使用一种强大的 Lisp 编程语言进行定制,并且存在各种用于 Python 开发的定制脚本。
**优点:**你知道 Emacs,你用 Emacs,你爱 Emacs。Lisp 是第二语言,你知道它给你的力量意味着你可以做任何事情。
**缺点:**定制就是将 Lisp 代码编写(或者复制/粘贴)到各种脚本文件中。如果还没有提供,您可能需要学习 Lisp 来弄清楚如何去做。
另外,你知道 Emacs 会是一个很棒的操作系统,只要它有一个好的文本编辑器…
请务必参考我们的 Python + Emacs 设置指南来充分利用这个设置。
Vi / Vim
**类别:**代码编辑
网站:https://www.vim.org/
文本编辑器战争的另一方是 VI(又名 VIM)。几乎每个 UNIX 系统和 Mac OS X 系统都默认包含 VI,它拥有同样狂热的追随者。
VI 和 VIM 是模态编辑器,将文件的查看和编辑分开。VIM 包含了对原始 VI 的许多改进,包括可扩展性模型和就地代码构建。VIMScripts 可用于各种 Python 开发任务。
**优点:**你知道 VI,你用 VI,你爱 VI。VIMScripts 不会吓到你,你知道你可以随心所欲地使用它。
**缺点:**像 Emacs 一样,您不习惯寻找或编写自己的脚本来支持 Python 开发,并且您不确定模态编辑器应该如何工作。
另外,你知道 VI 将是一个伟大的文本编辑器,只要它有一个像样的操作系统。
如果你打算使用这种组合,请查看我们的 Python + VIM 设置指南,其中包含提示和插件推荐。
Visual Studio
类别: IDE
网站:https://www.visualstudio.com/vs/
Python 工具:Visual Studio 的 Python 工具,又名 PTVS
Visual Studio 由微软构建,是一个全功能的 IDE,在许多方面可以与 Eclipse 相媲美。VS 仅适用于 Windows 和 Mac OS,有免费(社区)和付费(专业和企业)两个版本。Visual Studio 支持各种平台的开发,并自带扩展市场。
Visual Studio 的 Python 工具(又名 PTVS)支持 Visual Studio 中的 Python 编码,以及 Python 的智能感知、调试和其他工具。
**优点:**如果您已经为其他开发活动安装了 Visual Studio,那么添加 PTVS 会更快更容易。
缺点: Visual Studio 对于 Python 来说是一个很大的下载量。此外,如果您使用的是 Linux,那么您就不走运了:该平台没有 Visual Studio 安装程序。
Visual Studio 代码
**类别:**代码编辑
网站:https://code.visualstudio.com/
Python 工具:https://marketplace.visualstudio.com/items?itemName=ms-python.python
不要与完整的 Visual Studio 混淆,Visual Studio Code(又名 VS Code)是一个适用于 Linux、Mac OS X 和 Windows 平台的全功能代码编辑器。小巧轻便,但功能齐全,VS 代码是开源的,可扩展的,并且几乎可以为任何任务进行配置。和 Atom 一样,VS 代码也是建立在电子之上的,所以它也有同样的优缺点。
在 VS 代码中安装 Python 支持非常容易:只需点击一下按钮就可以进入市场。搜索 Python,单击安装,并在必要时重启。VS 代码会自动识别你的 Python 安装和库。
**优点:**多亏了 electronic,VS 代码可以在每个平台上使用,尽管占地面积很小,但功能却惊人地全面,而且是开源的。
**缺点:**电子意味着 VS 代码不是原生 app。另外,有些人可能有原则性的理由不使用微软的资源。
请务必参考我们的教程使用 Visual Studio 代码进行 Python 开发,以及的配套视频课程,以充分利用这一设置。如果你使用的是 Windows,那么请查看你的 Python 编码环境:设置指南中的设置 VS 代码部分。
特定于 Python 的编辑器和 ide
PyCharm
**类别:**IDE
T3】网站:T5】https://www.jetbrains.com/pycharm/
Python 最好的(也是唯一的)全功能专用 ide 之一是 PyCharm 。PyCharm 有付费(专业版)和免费开源(社区版)两种版本,可以在 Windows、Mac OS X 和 Linux 平台上快速轻松地安装。
开箱即用,PyCharm 直接支持 Python 开发。你可以打开一个新文件,开始写代码。您可以在 PyCharm 中直接运行和调试 Python,它支持源代码控制和项目。
优点:这是事实上的 Python IDE 环境,有大量的支持和支持社区。它开箱即可编辑、运行和调试 Python。
缺点: PyCharm 加载速度可能会很慢,现有项目的默认设置可能需要调整。
Spyder
**类别:**IDE
T3】网站:T5】https://github.com/spyder-ide/spyder
Spyder 是一个开源 Python IDE,针对数据科学工作流进行了优化。Spyder 包含在 Anaconda 包管理器发行版中,所以根据您的设置,您可能已经在您的机器上安装了 spyder。
Spyder 的有趣之处在于,它的目标受众是使用 Python 的数据科学家。你会注意到这一点。例如,Spyder 与常见的 Python 数据科学库集成得很好,如 SciPy 、 NumPy 和 Matplotlib 。
Spyder 具有您可能期望的大多数“通用 IDE 特性”,例如具有强大语法高亮显示的代码编辑器、Python 代码完成,甚至是集成的文档浏览器。
我在其他 Python 编辑环境中没有见过的一个特殊特性是 Spyder 的“变量浏览器”,它允许您在 ide 中使用基于表格的布局显示数据。就我个人而言,我通常不需要这个,但它看起来很整洁。如果您经常使用 Python 进行数据科学工作,您可能会爱上这个独特的功能。IPython/Jupyter 集成也很好。
总的来说,我认为 Spyder 比其他 ide 更基本。我更喜欢把它看作一个特殊用途的工具,而不是我每天用来作为主要编辑环境的东西。这个 Python IDE 的好处在于它可以在 Windows、macOS 和 Linux 上免费获得,并且是完全开源的软件。
**优点:**你是一名使用 Anaconda Python 发行版的数据科学家。
**缺点:**更有经验的 Python 开发人员可能会发现 Spyder 过于基础,无法在日常工作中使用,因此会选择更完整的 IDE 或定制的编辑器解决方案。
汤妮
**类别:**IDE
T3】网站:T5】http://thonny.org/
Thonny 是 Python IDE 家族的新成员,被宣传为初学者的 IDE。Thonny 由爱沙尼亚塔尔图大学计算机科学研究所编写和维护,可用于所有主要平台,网站上有安装说明。
默认情况下,Thonny 安装了自己的 Python 捆绑版本,因此您不需要安装任何其他新的东西。更有经验的用户可能需要调整这个设置,以便找到并使用已经安装的库。
**优点:**你是 Python 的初级用户,想要一个现成的 IDE。
反对意见:更有经验的 Python 开发者会发现 Thonny 对于大多数应用来说太基础了,内置解释器是需要解决的,而不是与之一起使用的。此外,作为一种新工具,您可能会发现一些问题无法立即解决。
如果您有兴趣使用 Thonny 作为您的 Python 编辑器,请务必阅读我们关于 Thonny 的专门文章,这篇文章更深入地向您展示了其他特性。
哪个 Python IDE 适合你?
只有你能决定,但这里有一些基本的建议:
- 新的 Python 开发人员应该尝试尽可能少定制的解决方案。越少妨碍越好。
- 如果您将文本编辑器用于其他任务(如网页或文档),请寻找代码编辑器解决方案。
- 如果您已经在开发其他软件,您可能会发现将 Python 功能添加到现有工具集更容易。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 寻找完美的 Python 代码编辑器***
Python IDLE 入门
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 从 Python 闲置开始
如果你最近下载了 Python 到你的电脑上,那么你可能已经注意到你的电脑上有一个名为 IDLE 的新程序。你可能想知道,“这个程序在我的电脑上做什么?我没有下载那个!”虽然您可能没有自己下载过这个程序,但 IDLE 是与每个 Python 安装捆绑在一起的。它可以帮助您立即开始学习这门语言。在本教程中,您将学习如何在 Python IDLE 中工作,以及一些您可以在 Python 之旅中使用的很酷的技巧!
在本教程中,您将学习:
- Python IDLE 是什么
- 如何使用 IDLE 直接与 Python 交互
- 如何用 IDLE 编辑、执行和调试 Python 文件
- 如何根据自己的喜好定制 Python IDLE
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
Python 空闲是什么?
每一个 Python 安装都带有一个集成开发和学习环境,你会看到它被缩短为 IDLE 甚至 IDE。这是一类帮助你更有效地编写代码的应用程序。虽然有许多ide供您选择,但是 Python IDLE 非常精简,这使得它成为初学程序员的完美工具。
Python IDLE 包含在 Windows 和 Mac 上的 Python 安装中。如果您是 Linux 用户,那么您应该能够使用您的包管理器找到并下载 Python IDLE。一旦你安装了它,你就可以使用 Python IDLE 作为交互式解释器或者文件编辑器。
交互式解释器
试验 Python 代码的最好地方是在交互式解释器,也称为外壳。外壳是一个基本的读取-评估-打印循环(REPL) 。它读取一条 Python 语句,评估该语句的结果,然后将结果打印在屏幕上。然后,它循环返回以读取下一条语句。
Python shell 是试验小代码片段的绝佳场所。您可以通过计算机上的终端或命令行应用程序来访问它。您可以使用 Python IDLE 简化工作流程,当您打开 Python shell 时,它会立即启动。
一个文件编辑器
每个程序员都需要能够编辑和保存文本文件。Python 程序是扩展名为.py的文件,包含多行 Python 代码。Python IDLE 使您能够轻松地创建和编辑这些文件。
Python IDLE 还提供了几个你将在专业 ide 中看到的有用特性,比如基本语法高亮、代码完成和自动缩进。专业 ide 是更健壮的软件,它们有一个陡峭的学习曲线。如果您刚刚开始您的 Python 编程之旅,那么 Python IDLE 是一个很好的选择!
如何使用 Python IDLE Shell
shell 是 Python IDLE 的默认操作模式。当你点击图标打开程序时,你首先看到的是外壳:
这是一个空白的 Python 解释器窗口。您可以使用它立即开始与 Python 交互。您可以用一小段代码来测试它:
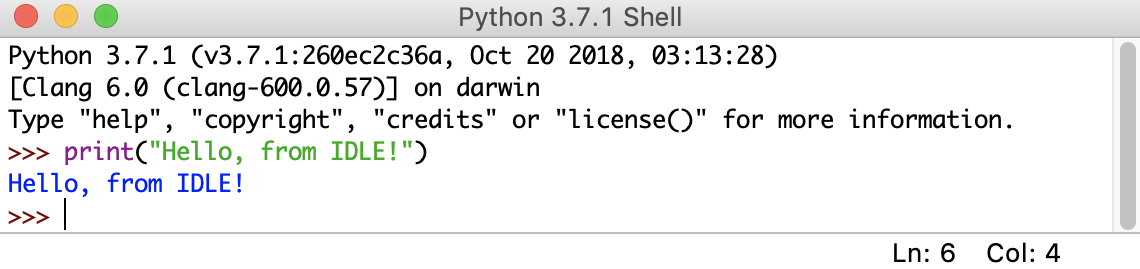
这里,您使用了 print() 将字符串"Hello, from IDLE!"输出到您的屏幕。这是与 Python IDLE 交互的最基本方式。您一次输入一个命令,Python 会响应每个命令的结果。
接下来,看看菜单栏。您将看到使用 shell 的几个选项:
您可以从该菜单重新启动 shell。如果您选择该选项,那么您将清除 shell 的状态。它将表现得好像您已经启动了一个新的 Python IDLE 实例。外壳将会忘记以前状态的所有内容:
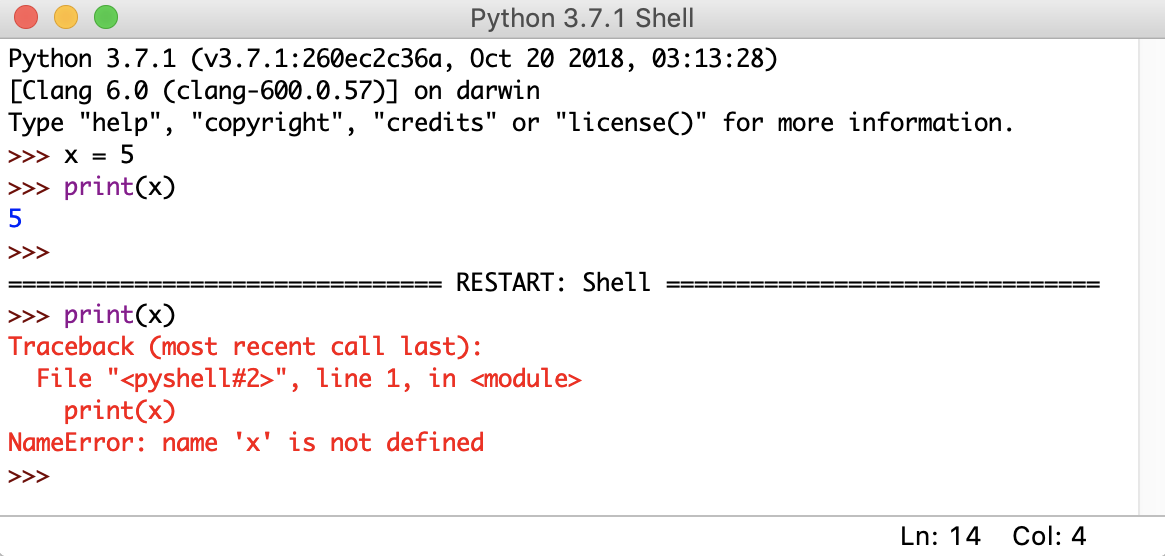
在上图中,首先声明一个变量,x = 5。当您调用print(x)时,shell 显示正确的输出,这是数字5。但是,当您重启 shell 并尝试再次调用print(x)时,您可以看到 shell 打印了一个 traceback 。这是一条错误消息,说明变量x未定义。shell 已经忘记了重启之前发生的所有事情。
您也可以从这个菜单中断 shell 的执行。这将在中断时停止 shell 中正在运行的任何程序或语句。看看当您向 shell 发送键盘中断时会发生什么:
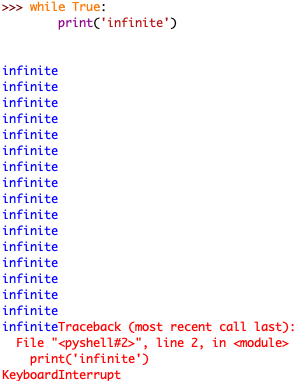
窗口底部以红色文本显示一条KeyboardInterrupt错误信息。程序接收到中断并已停止执行。
如何使用 Python 文件
Python IDLE 提供了一个成熟的文件编辑器,让您能够在这个程序中编写和执行 Python 程序。内置的文件编辑器还包括几个功能,如代码完成和自动缩进,这将加快您的编码工作流程。首先,我们来看看如何在 Python IDLE 中编写和执行程序。
打开文件
要启动一个新的 Python 文件,从菜单栏中选择文件→新文件。这将在编辑器中打开一个空白文件,如下所示:
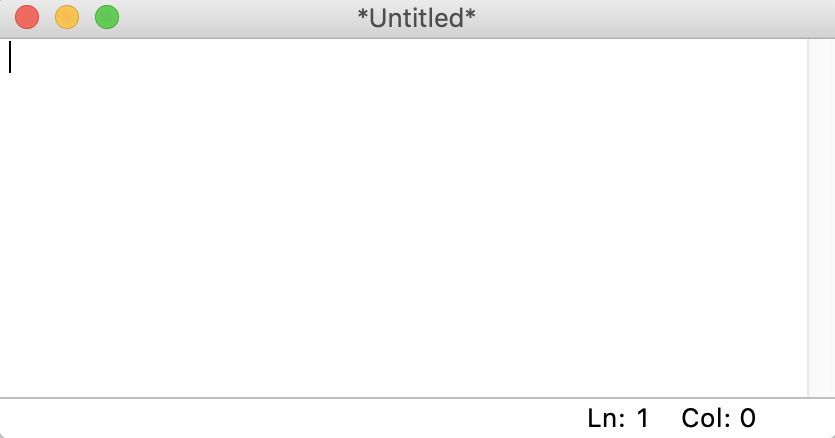
从这个窗口中,您可以编写一个全新的 Python 文件。您也可以通过选择菜单栏中的文件→打开… 来打开现有的 Python 文件。这将打开您操作系统的文件浏览器。然后,可以找到想要打开的 Python 文件。
如果您对阅读 Python 模块的源代码感兴趣,那么您可以选择文件→路径浏览器。这将允许您查看 Python IDLE 可以看到的模块。当你双击其中一个,文件编辑器就会打开,你就可以阅读它了。
该窗口的内容将与您调用sys.path时返回的路径相同。如果您知道想要查看的特定模块的名称,那么您可以选择文件→模块浏览器,并在出现的框中输入模块的名称。
编辑文件
一旦你在 Python IDLE 中打开了一个文件,你就可以对它进行修改。当您准备好编辑文件时,您会看到类似这样的内容:
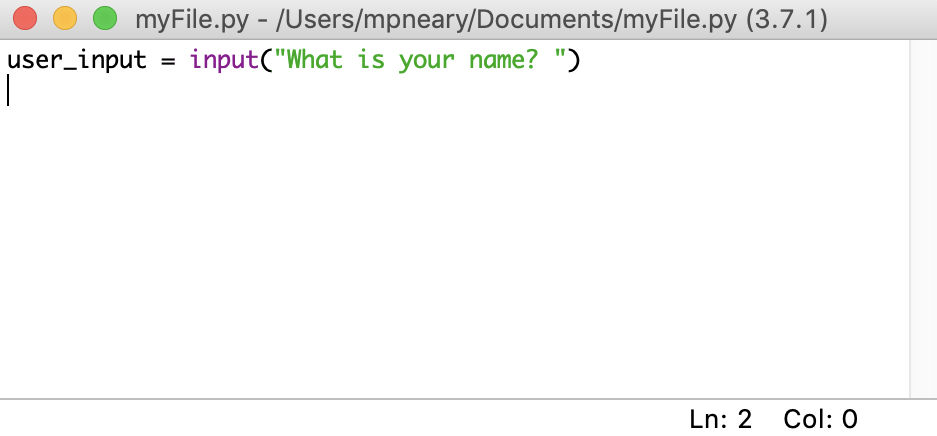
文件的内容显示在打开的窗口中。窗口顶部的栏包含三条重要信息:
- 您正在编辑的文件的名称
- 您可以在电脑上找到该文件的文件夹的完整路径
- IDLE 正在使用的 Python 版本
在上图中,您正在编辑文件myFile.py,它位于Documents文件夹中。Python 版本是 3.7.1,你可以在括号里看到。
窗口右下角还有两个数字:
- Ln: 显示光标所在的行号。
- Col: 显示光标所在的列号。
看到这些数字很有用,这样您可以更快地找到错误。它们还能帮助你确保你保持在一定的线宽内。
此窗口中有一些视觉提示,可以帮助您记住保存您的工作。如果你仔细观察,你会发现 Python IDLE 使用星号让你知道你的文件有未保存的修改:
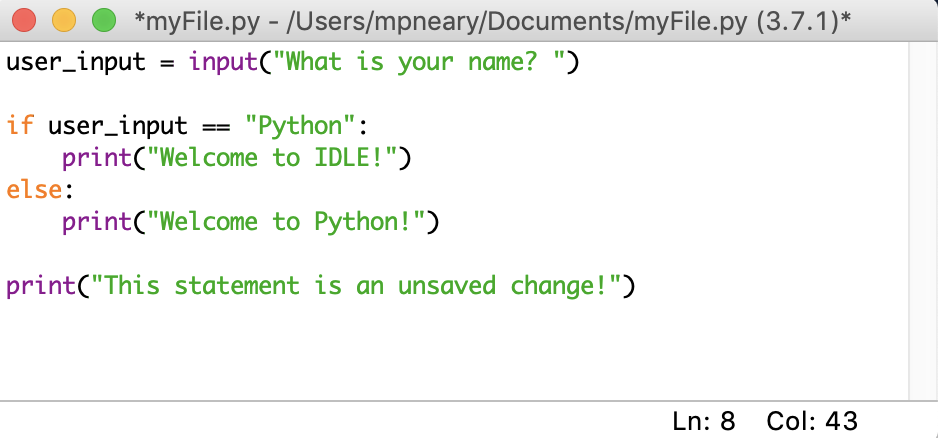
显示在空闲窗口顶部的文件名被星号包围。这意味着编辑器中有未保存的更改。您可以使用系统的标准键盘快捷键保存这些更改,也可以从菜单栏中选择文件→保存。请确保使用扩展名.py保存文件,以便启用语法高亮显示。
执行文件
当你想执行一个你在空闲状态下创建的文件时,你应该首先确保它被保存。请记住,您可以通过查看文件编辑器窗口顶部文件名周围的星号来查看您的文件是否被正确保存。不过,如果你忘记了也不用担心!当你试图执行一个未保存的文件时,Python IDLE 会提醒你保存。
要在空闲状态下执行文件,只需按键盘上的 F5 键。您也可以从菜单栏中选择运行→运行模块。这两个选项都将重启 Python 解释器,然后运行您用新的解释器编写的代码。这个过程与您在终端中运行python3 -i [filename]是一样的。
当你的代码执行完毕,解释器将知道你的代码的一切,包括任何全局变量、函数和类。这使得 Python IDLE 成为在出现问题时检查数据的好地方。如果你需要中断程序的执行,你可以在运行代码的解释器中按 Ctrl + C 。
如何改进你的工作流程
现在您已经了解了如何在 Python IDLE 中编写、编辑和执行文件,是时候加快您的工作流程了!Python IDLE 编辑器提供了一些您将在大多数专业 ide 中看到的特性,来帮助您更快地编码。这些特性包括自动缩进、代码完成和调用提示以及代码上下文。
自动缩进
当 IDLE 需要开始一个新的块时,它会自动缩进你的代码。这通常发生在您键入冒号(:)之后。当您在冒号后按回车键时,光标将自动移动一定数量的空格,并开始一个新的代码块。
您可以在设置中配置光标将移动多少个空格,但默认是标准的四个空格。Python 的开发人员就编写良好的 Python 代码的标准风格达成了一致,这包括缩进、空白等规则。这种标准风格被形式化了,现在被称为 PEP 8 。要了解更多信息,请查看如何用 PEP 8 编写漂亮的 Python 代码。
代码完成和呼叫提示
当你为一个大项目或者一个复杂的问题编写代码时,你可能会花费大量的时间来输入你需要的所有代码。代码完成通过尝试为您完成代码来帮助您节省键入时间。Python IDLE 具有基本的代码完成功能。它只能自动补全函数和类名。要在编辑器中使用自动完成功能,只需在一系列文本后按 tab 键。
Python IDLE 还会提供呼叫提示。一个调用提示就像是对代码某一部分的提示,帮助你记住那个元素需要什么。键入左括号开始函数调用后,如果几秒钟内没有键入任何内容,将会出现调用提示。例如,如果您不太记得如何添加到一个列表,那么您可以在左括号后暂停以调出呼叫提示:

呼叫提示将显示为弹出提示,提醒您如何添加到列表中。像这样的调用技巧在您编写代码时提供了有用的信息。
代码上下文
代码上下文功能是 Python 空闲文件编辑器的一个简洁的特性。它将向你展示一个函数、类、循环或其他结构的范围。当您滚动浏览一个很长的文件,并需要在编辑器中查看代码时跟踪您的位置时,这尤其有用。
要打开它,在菜单栏中选择选项→代码上下文。您会看到编辑器窗口顶部出现一个灰色栏:
当你向下滚动你的代码时,包含每一行代码的上下文将停留在这个灰色条内。这意味着你在上图中看到的print()函数是主函数的一部分。当您到达超出此函数范围的一行时,条形将会消失。
如何在空闲状态下调试
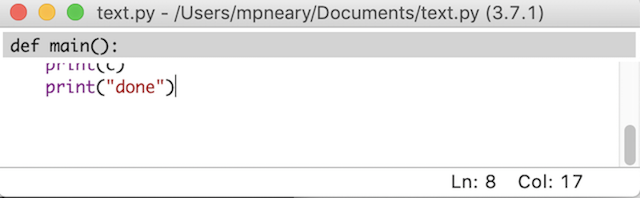
一个 bug 是你程序中的一个意外问题。它们可以以多种形式出现,其中一些比另一些更难修复。有些 bug 非常棘手,你不能通过通读你的程序来发现它们。幸运的是,Python IDLE 提供了一些基本工具,可以帮助你轻松调试你的程序!
解释器调试模式
如果您想用内置调试器运行您的代码,那么您需要打开这个特性。为此,从 Python 空闲菜单栏中选择调试→调试器。在解释器中,您应该看到[DEBUG ON]出现在提示符(>>>)之前,这意味着解释器已经准备好并正在等待。
执行 Python 文件时,将出现调试器窗口:
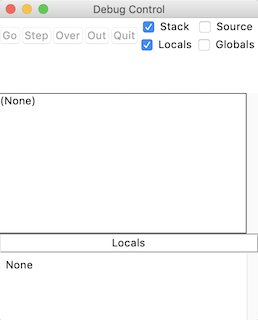
在此窗口中,您可以在代码执行时检查局部变量和全局变量的值。这使您能够深入了解代码运行时数据是如何被操作的。
您也可以单击以下按钮来浏览代码:
- Go: 按下此键,执行前进到下一个断点。您将在下一节了解这些内容。
- **步骤:**按此执行当前行,转到下一行。
- Over: 如果当前代码行包含一个函数调用,那么按下此键以跳过该函数。换句话说,执行那个函数,转到下一行,但是在执行函数的时候不要暂停(除非有断点)。
- Out: 如果当前行代码在一个函数中,则按此键可以从该函数的中跳出。换句话说,继续执行这个函数,直到返回。
一定要小心,因为没有反向按钮!在程序的执行过程中,您只能及时向前移动。
您还会在“调试”窗口中看到四个复选框:
- **全局:**您的程序的全局信息
- Locals: 您的程序在执行过程中的本地信息
- **栈:**执行过程中运行的函数
- **来源:**你的文件在空闲时编辑
当您选择其中之一时,您将在调试窗口中看到相关信息。
断点
一个断点是一行代码,当你运行你的代码时,你把它标识为解释器应该暂停的地方。它们只有在调试模式开启时才能工作,所以确保你已经先这样做了。
要设置断点,右键单击要暂停的代码行。这将以黄色突出显示代码行,作为设置断点的可视指示。您可以在代码中设置任意数量的断点。要撤销断点,再次右键单击同一行并选择清除断点。
一旦你设置了断点并打开了调试模式,你就可以像平常一样运行你的代码了。调试器窗口将弹出,您可以开始手动单步调试您的代码。
错误和异常
当您在解释器中看到报告给您的错误时,Python IDLE 允许您从菜单栏直接跳转到有问题的文件或行。您只需用光标高亮显示报告的行号或文件名,并从菜单栏中选择调试→转到文件/行。这将打开有问题的文件,并把您带到包含错误的那一行。无论调试模式是否开启,该功能都起作用。
Python IDLE 还提供了一个叫做堆栈查看器的工具。你可以在菜单栏的调试选项下进入。这个工具将向您展示 Python IDLE 在运行代码时遇到的最后一个错误或异常的堆栈上出现的错误的回溯。当发生意外或有趣的错误时,您可能会发现查看堆栈很有帮助。否则,这个特性可能很难解析,并且可能对您没有用处,除非您正在编写非常复杂的代码。
如何定制 Python IDLE
有很多方法可以让 Python IDLE 拥有适合自己的视觉风格。默认的外观基于 Python 徽标中的颜色。如果你不喜欢任何东西的样子,那么你几乎总是可以改变它。
要访问定制窗口,从菜单栏中选择选项→配置空闲。要预览您想要进行的更改的结果,请按下应用。当你定制完 Python IDLE 后,按 OK 保存你所有的修改。如果您不想保存您的更改,只需按下取消。
您可以自定义 Python IDLE 的 5 个区域:
- 字体/标签
- 突出
- 键
- 一般
- 扩展ˌ扩张
现在,让我们来逐一了解一下。
字体/标签
第一个选项卡允许您更改字体颜色、字体大小和字体样式。根据您的操作系统,您可以将字体更改为几乎任何您喜欢的样式。字体设置窗口如下所示:
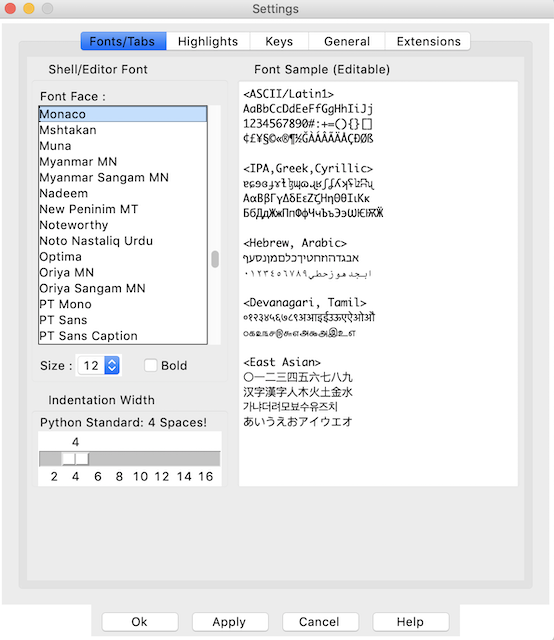
您可以使用滚动窗口选择您喜欢的字体。(建议你选择 Courier New 这样的定宽字体。)选择一个足够大的字体,让你看得更清楚。您也可以点击粗体旁边的复选框来切换是否所有文本都以粗体显示。
此窗口还允许您更改每个缩进级别使用的空格数。默认情况下,这将被设置为四个空格的 PEP 8 标准。您可以更改这一点,使代码的宽度根据您的喜好或多或少地展开。
亮点
第二个定制选项卡将允许您更改突出显示。语法突出显示是任何 IDE 的一个重要特性,它可以突出显示您正在使用的语言的语法。这有助于您直观地区分不同的 Python 结构和代码中使用的数据。
Python IDLE 允许您完全自定义 Python 代码的外观。它预装了三种不同的亮点主题:
- 无聊的日子
- 无所事事的夜晚
- 闲置新闻
您可以从这些预安装的主题中进行选择,或者在此窗口中创建您自己的自定义主题:
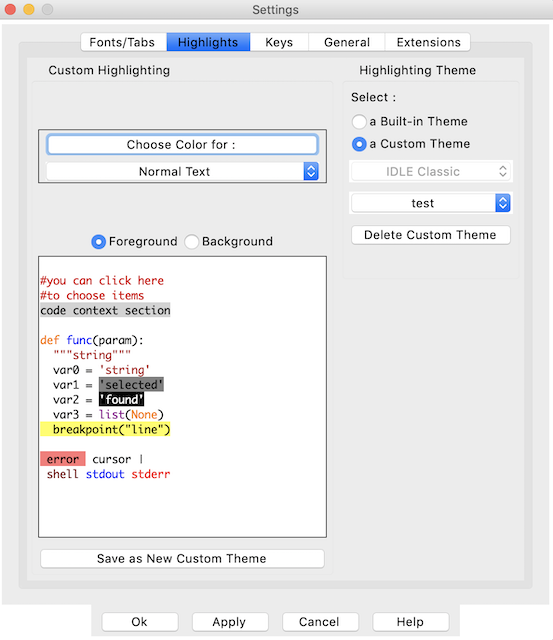
不幸的是,IDLE 不允许你从一个文件中安装自定义主题。你必须从这个窗口创建自定义主题。为此,您可以简单地开始改变不同项目的颜色。选择一个项目,然后按为选择颜色。你将被带到一个颜色选择器,在那里你可以选择你想要使用的确切颜色。
然后,系统会提示您将该主题保存为新的自定义主题,您可以输入自己选择的名称。如果愿意,您可以继续更改不同项目的颜色。记得按下应用来查看您的行动变化!
按键
第三个定制选项卡允许您将不同的按键映射到动作,也称为键盘快捷键。无论何时使用 IDE,这些都是生产力的重要组成部分。你可以自己想出键盘快捷键,也可以使用 IDLE 自带的快捷键。预安装的快捷方式是一个很好的起点:
键盘快捷键按动作的字母顺序列出。它们以动作-快捷方式的格式列出,其中动作是当你按下快捷方式中的组合键时会发生的事情。如果您想使用内置的键集,请选择与您的操作系统相匹配的映射。请密切注意不同的键,并确保您的键盘有它们!
创建自己的快捷方式
键盘快捷键的定制与语法高亮颜色的定制非常相似。遗憾的是,IDLE 不允许您从文件中安装自定义键盘快捷键。您必须从键选项卡创建一组自定义快捷键。
从列表中选择一对,按下获取新的选择键。将弹出一个新窗口:
在这里,您可以使用复选框和滚动菜单来选择要用于该快捷键的组合键。您可以选择高级键绑定条目> > 手动输入命令。请注意,这不会拾取您按下的键。您必须逐字键入您在快捷键列表中看到的命令。
常规
“定制”窗口的第四个选项卡是进行小的常规更改的地方。“常规设置”选项卡如下所示:
在这里,您可以自定义窗口大小,以及启动 Python IDLE 时是先打开 shell 还是先打开文件编辑器。这个窗口中的大部分东西改变起来并不令人兴奋,所以你可能不需要摆弄它们。
扩展
定制窗口的第五个选项卡允许您向 Python IDLE 添加扩展。扩展允许你在编辑器和解释器窗口中添加新的、令人敬畏的特性。您可以从互联网上下载它们,并将其安装到 Python IDLE 中。
要查看安装了哪些扩展,选择选项→配置空闲- >扩展。互联网上有许多扩展可供你阅读更多。找到自己喜欢的,添加到 Python IDLE!
结论
在本教程中,您已经学习了使用 IDLE 编写 Python 程序的所有基础知识。你知道什么是 Python IDLE,以及如何使用它直接与 Python 交互。您还了解了如何处理 Python 文件,以及如何根据自己的喜好定制 Python IDLE。
你已经学会了如何:
- 使用 Python 空闲 shell
- 使用 Python IDLE 作为文件编辑器
- 利用帮助您更快编码的功能改进您的工作流程
- 调试代码并查看错误和异常
- 根据您的喜好定制 Python IDLE
现在,您拥有了一个新工具,它将让您高效地编写 Pythonic 代码,并为您节省无数时间。编程快乐!
立即观看本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 从 Python 闲置开始*****


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









