







原文:RealPython
Twitter 情绪分析——Python、Docker、Elasticsearch、Kibana
原文:# t0]https://realython . com/Twitter-感情 python 坞站-弹性搜索-kibana/
在本例中,我们将连接到 Twitter 流 API,收集推文(基于关键字),计算每条推文的情绪,并使用 Elasticsearch DB 和 Kibana 构建一个实时仪表板来可视化结果。
工具: Docker v1.3.0, boot2docker v1.3.0, Tweepy v2.3.0, TextBlob v0.9.0, Elasticsearch v1.3.5, Kibana v3.1.2
Docker 环境
按照官方 Docker 文档安装 Docker 和 boot2docker。然后启动并运行 boot2docker,运行docker version来测试 docker 安装。创建一个目录来存放您的项目,从库中获取 docker 文件,并构建映像:
$ docker build -rm -t=elasticsearch-kibana .
构建完成后,运行容器:
$ docker run -d -p 8000:8000 -p 9200:9200 elasticsearch-kibana
最后,在新的终端窗口中运行下面两个命令,将 boot2docker VM 使用的 IP 地址/端口组合映射到您的本地主机:
$ boot2docker ssh -L8000:localhost:8000
$ boot2docker ssh -L9200:localhost:9200
现在你可以在 http://localhost:9200 访问 Elasticsearch,在 http://localhost:8000 访问 Kibana。
Twitter 流媒体 API
为了访问 Twitter 流媒体 API ,你需要在 http://apps.twitter.com 的注册一个应用。创建完成后,您应该会被重定向到您的应用程序页面,在那里您可以获得消费者密钥和消费者密码,并在“密钥和访问令牌”选项卡下创建访问令牌。将这些添加到一个名为 config.py 的新文件中:
consumer_key = "add_your_consumer_key"
consumer_secret = "add_your_consumer_secret"
access_token = "add_your_access_token"
access_token_secret = "add_your_access_token_secret"
注意:因为这个文件包含敏感信息,所以不要把它添加到你的 Git 库。
根据 Twitter Streaming 文档,“建立到流 API 的连接意味着发出一个非常长的 HTTP 请求,并逐步解析响应。从概念上讲,你可以把它想象成通过 HTTP 下载一个无限长的文件。”
因此,你提出一个请求,通过特定的关键词、用户和/或地理区域进行过滤,然后保持连接打开,收集尽可能多的推文。
这听起来很复杂,但是 Tweepy 让它变得简单。
十二个听众
Tweepy 使用一个“监听器”不仅获取流媒体推文,还对它们进行过滤。
代码
将以下代码另存为perspective . py:
import json
from tweepy.streaming import StreamListener
from tweepy import OAuthHandler
from tweepy import Stream
from textblob import TextBlob
from elasticsearch import Elasticsearch
# import twitter keys and tokens
from config import *
# create instance of elasticsearch
es = Elasticsearch()
class TweetStreamListener(StreamListener):
# on success
def on_data(self, data):
# decode json
dict_data = json.loads(data)
# pass tweet into TextBlob
tweet = TextBlob(dict_data["text"])
# output sentiment polarity
print tweet.sentiment.polarity
# determine if sentiment is positive, negative, or neutral
if tweet.sentiment.polarity < 0:
sentiment = "negative"
elif tweet.sentiment.polarity == 0:
sentiment = "neutral"
else:
sentiment = "positive"
# output sentiment
print sentiment
# add text and sentiment info to elasticsearch
es.index(index="sentiment",
doc_type="test-type",
body={"author": dict_data["user"]["screen_name"],
"date": dict_data["created_at"],
"message": dict_data["text"],
"polarity": tweet.sentiment.polarity,
"subjectivity": tweet.sentiment.subjectivity,
"sentiment": sentiment})
return True
# on failure
def on_error(self, status):
print status
if __name__ == '__main__':
# create instance of the tweepy tweet stream listener
listener = TweetStreamListener()
# set twitter keys/tokens
auth = OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
# create instance of the tweepy stream
stream = Stream(auth, listener)
# search twitter for "congress" keyword
stream.filter(track=['congress'])
发生了什么事?:
- 我们连接到 Twitter 流 API
- 通过关键字
"congress"过滤数据; - 解码结果(推文);
- 通过 TextBlob 计算情感分析;
- 确定总体情绪是积极的、消极的还是中性的;而且,
- 最后,相关的情感和推文数据被添加到 Elasticsearch 数据库中。
有关更多详细信息,请查看行内注释。
TextBlob 情感基础
为了计算整体情绪,我们看一下极性得分:
- 正:从
0.01到1.0 - 中立:
0 - 负:从
-0.01到-1.0
有关 TextBlob 如何计算情感的更多信息,请参考官方文档。
弹性搜索分析
在我写这篇博客的两个多小时里,我用关键词“国会”拉了 9500 多条推文。在这一点上,继续进行你自己的搜索,搜索你感兴趣的主题。一旦你有相当数量的推文,停止脚本。现在,您可以执行一些快速搜索/分析…
使用来自perspective . py脚本的索引("sentiment",您可以使用 Elasticsearch 搜索 API 来收集一些基本的见解。
例如:
- 全文搜索“奥巴马”:http://localhost:9200/情操/_ 搜索?q =奥巴马
- 作者/Twitter 用户名搜索:http://localhost:9200/情操/_ 搜索?q =作者:allvoices
- 情感搜索:http://localhost:9200/情操/_ 搜索?q =情绪:积极
- 感悟与“奥巴马”搜索:http://localhost:9200/情操/_ 搜索?q =情绪:积极的&消息=奥巴马
除了搜索和过滤结果之外,你还可以用 Elasticsearch 做更多的事情。查看分析 API 以及弹性搜索——权威指南,了解更多关于如何分析和建模数据的想法。
基巴纳可视化工具
当您收集数据时,Kibana 可以让您实时“看到您的数据并与之互动”。因为它是用 JavaScript 编写的,所以您可以直接从浏览器访问它。查看来自官方介绍的基础知识,快速入门。
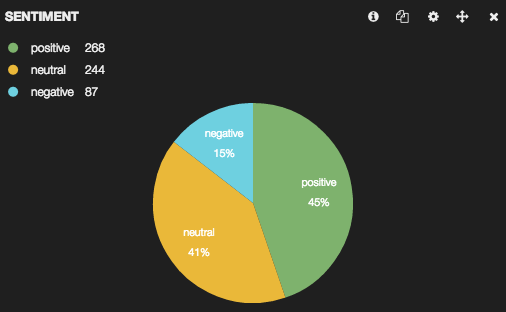
这篇文章顶部的饼状图直接来自基巴纳,它显示了每种情绪——积极的、中立的和消极的——在我提取的推文中所占的比例。这里是来自基巴纳的一些图表…
所有被“奥巴马”过滤的推文:
按推文数量排名的前几名推文用户:

请注意排名第一的作者是如何发布 76 条推文的。这绝对值得深入研究,因为在两个小时内有很多推文。无论如何,那位作者基本上发了 76 条同样的推文——所以你会想过滤掉其中的 75 条,因为总体结果目前是有偏差的。
除了这些图表之外,还有必要通过位置来可视化情绪。自己试试这个。你必须改变从每条推文中获取的数据。您可能还想尝试用直方图来可视化数据。
最后-
- 从库中获取代码。
- 在下面留下评论/问题。
干杯!**
Python 中的绝对导入与相对导入
原文:https://realpython.com/absolute-vs-relative-python-imports/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python 中的绝对 vs 相对导入
如果您曾经处理过包含多个文件的 Python 项目,那么您很可能曾经使用过 import 语句。
即使对于拥有几个项目的 Pythonistas 来说,导入也会令人困惑!您可能正在阅读这篇文章,因为您想更深入地了解 Python 中的导入,尤其是绝对和相对导入。
在本教程中,您将了解两者之间的差异,以及它们的优缺点。让我们开始吧!
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
进口快速回顾
你需要对 Python 模块和包有很好的理解,才能知道导入是如何工作的。Python 模块是一个扩展名为.py的文件,Python 包是任何包含模块的文件夹(或者,在 Python 2 中,包含__init__.py文件的文件夹)。
当一个模块中的代码需要访问另一个模块或包中的代码时会发生什么?你进口的!
进口如何运作
但是进口到底是怎么运作的呢?假设您像这样导入一个模块abc:
import abc
Python 会做的第一件事就是在 sys.modules 中查找名字abc。这是以前导入的所有模块的缓存。
如果在模块缓存中没有找到该名称,Python 将继续搜索内置模块列表。这些是 Python 预装的模块,可以在 Python 标准库中找到。如果在内置模块中仍然没有找到这个名字,Python 就会在由 sys.path 定义的目录列表中搜索它。该列表通常包括当前目录,首先搜索该目录。
当 Python 找到该模块时,它会将其绑定到本地范围内的一个名称。这意味着abc现在已经被定义,可以在当前文件中使用,而不用抛出NameError。
如果名字没有找到,你会得到一个ModuleNotFoundError。你可以在 Python 文档中找到更多关于导入的信息这里!
注意:安全问题
请注意,Python 的导入系统存在一些重大的安全风险。这很大程度上是因为它的灵活性。例如,模块缓存是可写的,并且可以使用导入系统覆盖核心 Python 功能。从第三方包导入也会使您的应用程序面临安全威胁。
以下是一些有趣的资源,可以帮助您了解更多关于这些安全问题以及如何缓解这些问题的信息:
- Anthony Shaw 的 Python 中的 10 个常见安全陷阱以及如何避免它们(第 5 点讨论了 Python 的导入系统。)
- 第 168 集:10 Python 安全漏洞和如何堵塞漏洞来自 TalkPython 播客(小组成员在大约 27:15 开始谈论进口。)
导入语句的语法
现在您已经知道了 import 语句是如何工作的,让我们来研究一下它们的语法。您可以导入包和模块。(注意,导入一个包实质上是将包的__init__.py文件作为一个模块导入。)您还可以从包或模块中导入特定的对象。
通常有两种类型的导入语法。当您使用第一个时,您直接导入资源,就像这样:
import abc
abc可以是包,也可以是模块。
当使用第二种语法时,从另一个包或模块中导入资源。这里有一个例子:
from abc import xyz
xyz可以是模块,子包,或者对象,比如类或者函数。
您还可以选择重命名导入的资源,如下所示:
import abc as other_name
这将在脚本中将导入的资源abc重命名为other_name。它现在必须被称为other_name,否则它将不会被识别。
导入报表的样式
Python 的官方风格指南 PEP 8 ,在编写导入语句时有一些提示。这里有一个总结:
-
导入应该总是写在文件的顶部,在任何模块注释和文档字符串之后。
-
进口应该根据进口的内容来划分。通常有三组:
- 标准库导入(Python 的内置模块)
- 相关的第三方导入(已安装但不属于当前应用程序的模块)
- 本地应用程序导入(属于当前应用程序的模块)
-
每组导入都应该用空格隔开。
在每个导入组中按字母顺序排列导入也是一个好主意。这使得查找特定的导入更加容易,尤其是当一个文件中有许多导入时。
以下是如何设计导入语句样式的示例:
"""Illustration of good import statement styling.
Note that the imports come after the docstring.
"""
# Standard library imports
import datetime
import os
# Third party imports
from flask import Flask
from flask_restful import Api
from flask_sqlalchemy import SQLAlchemy
# Local application imports
from local_module import local_class
from local_package import local_function
上面的导入语句分为三个不同的组,用空格隔开。它们在每个组中也是按字母顺序排列的。
绝对进口
您已经掌握了如何编写 import 语句以及如何像专家一样设计它们的风格。现在是时候多了解一点绝对进口了。
绝对导入使用项目根文件夹的完整路径指定要导入的资源。
语法和实例
假设您有以下目录结构:
└── project
├── package1
│ ├── module1.py
│ └── module2.py
└── package2
├── __init__.py
├── module3.py
├── module4.py
└── subpackage1
└── module5.py
有一个目录,project,包含两个子目录,package1和package2。package1目录下有两个文件,module1.py和module2.py。
package2目录有三个文件:两个模块module3.py和module4.py,以及一个初始化文件__init__.py。它还包含一个目录subpackage,该目录又包含一个文件module5.py。
让我们假设以下情况:
package1/module2.py包含一个函数,function1。package2/__init__.py包含一个类,class1。package2/subpackage1/module5.py包含一个函数,function2。
以下是绝对进口的实际例子:
from package1 import module1
from package1.module2 import function1
from package2 import class1
from package2.subpackage1.module5 import function2
请注意,您必须给出每个包或文件的详细路径,从顶层包文件夹开始。这有点类似于它的文件路径,但是我们用一个点(.)代替斜线(/)。
绝对进口的利弊
绝对导入是首选,因为它们非常清晰和直接。通过查看语句,很容易准确地判断导入的资源在哪里。此外,即使 import 语句的当前位置发生变化,绝对导入仍然有效。事实上,PEP 8 明确建议绝对进口。
然而,根据目录结构的复杂性,有时绝对导入会变得非常冗长。想象一下这样的陈述:
from package1.subpackage2.subpackage3.subpackage4.module5 import function6
太荒谬了,对吧?幸运的是,在这种情况下,相对进口是一个很好的选择!
相对进口
相对导入指定相对于当前位置(即导入语句所在的位置)要导入的资源。相对导入有两种类型:隐式和显式。Python 3 中不赞成隐式相对导入,所以我不会在这里讨论它们。
语法和实例
相对导入的语法取决于当前位置以及要导入的模块、包或对象的位置。以下是一些相对进口的例子:
from .some_module import some_class
from ..some_package import some_function
from . import some_class
你可以看到上面的每个 import 语句中至少有一个点。相对导入使用点符号来指定位置。
单个点意味着所引用的模块或包与当前位置在同一个目录中。两个点表示它在当前位置的父目录中,也就是上面的目录。三个点表示它在祖父母目录中,依此类推。如果您使用的是类似 Unix 的操作系统,您可能会对此很熟悉!
让我们假设您有和以前一样的目录结构:
└── project
├── package1
│ ├── module1.py
│ └── module2.py
└── package2
├── __init__.py
├── module3.py
├── module4.py
└── subpackage1
└── module5.py
回忆文件内容:
package1/module2.py包含一个函数,function1。package2/__init__.py包含一个类,class1。package2/subpackage1/module5.py包含一个函数,function2。
您可以这样将function1导入到package1/module1.py文件中:
# package1/module1.py
from .module2 import function1
这里只使用一个点,因为module2.py和当前模块module1.py在同一个目录中。
您可以这样将class1和function2导入到package2/module3.py文件中:
# package2/module3.py
from . import class1
from .subpackage1.module5 import function2
在第一个 import 语句中,单个点意味着您正在从当前包中导入class1。记住,导入一个包实际上是将包的__init__.py文件作为一个模块导入。
在第二个 import 语句中,您将再次使用一个点,因为subpackage1与当前模块module3.py在同一个目录中。
相对进口的利弊
相对导入的一个明显优势是它们非常简洁。根据当前的位置,他们可以将您之前看到的长得离谱的导入语句变成像这样简单的语句:
from ..subpackage4.module5 import function6
不幸的是,相对导入可能会很混乱,特别是对于目录结构可能会改变的共享项目。相对导入也不像绝对导入那样可读,并且不容易判断导入资源的位置。
结论
在这个绝对和相对进口的速成课程结束时做得很好!现在,您已经了解了导入是如何工作的。您已经学习了编写导入语句的最佳实践,并且知道绝对导入和相对导入之间的区别。
凭借您的新技能,您可以自信地从 Python 标准库、第三方包和您自己的本地包中导入包和模块。请记住,您通常应该选择绝对导入而不是相对导入,除非路径很复杂并且会使语句太长。
感谢阅读!
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python 中的绝对 vs 相对导入***
如何将 Python 添加到路径
如果已经安装了 Python,可能需要将 Python 添加到PATH中,但是在命令行中键入python似乎不起作用。您可能会收到一条消息,说术语python无法识别,或者您可能会运行错误版本的 Python。
解决这些问题的一个常见方法是将 Python 添加到PATH 环境变量。在本教程中,您将学习如何将 Python 添加到PATH中。您还将了解什么是PATH,以及为什么PATH对于像命令行这样的程序能够找到您的 Python 安装是至关重要的。
**注意:**一个路径是你硬盘上一个文件或文件夹的地址。PATH环境变量,也称为PATH或路径,是操作系统保存并用于查找可执行脚本和程序的目录的路径列表。
向PATH添加内容所需的步骤很大程度上取决于您的操作系统(OS ),所以如果您只对一个 OS 感兴趣,请务必跳到相关章节。
请注意,您可以使用以下步骤将任何程序添加到PATH,而不仅仅是 Python。
补充代码: 点击这里下载免费的补充代码,它将带你穿越操作系统的变化之路。
如何在 Windows 上给PATH添加 Python
第一步是定位目标 Python 可执行文件所在的目录。目录的路径就是您将要添加到PATH环境变量中的内容。
要找到 Python 可执行文件,您需要查找一个名为python.exe的文件。例如,Python 可执行文件可能在C:\Python\的目录中,或者在你的AppData\文件夹中。如果可执行文件在AppData\中,那么路径通常如下所示:
C:\Users\<USER>\AppData\Local\Programs\Python
在您的情况下,<USER>部分将被您当前登录的用户名替换。
找到可执行文件后,双击它并验证它是否在新窗口中启动了 Python REPL,以确保它能正常工作。
如果你正在努力寻找正确的可执行文件,你可以使用 Windows 资源管理器的搜索功能。内置搜索的问题是它非常慢。要对任何文件进行超快速的全系统搜索,一个很好的替代方法是 Everything :
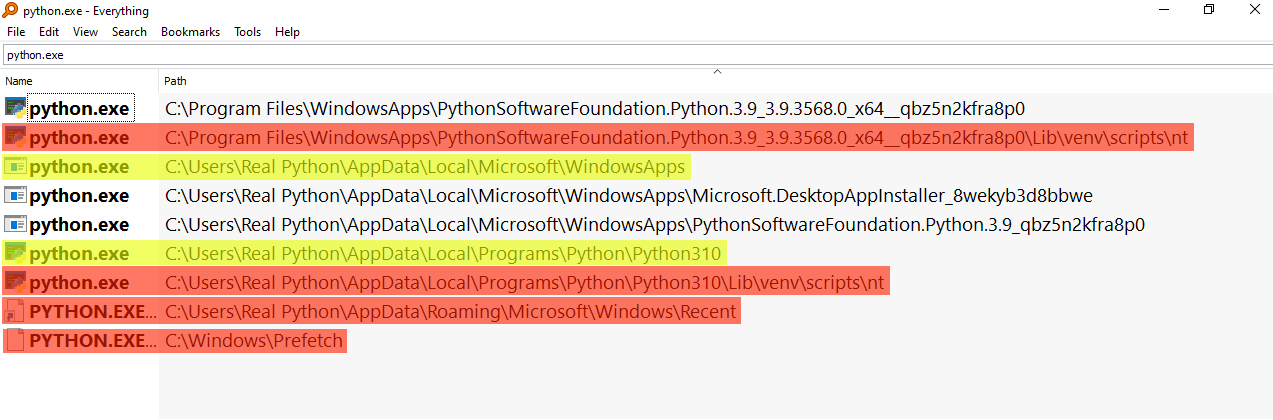
那些用黄色突出显示的路径,即那些位于\WindowsApps和\Python310的路径,将是添加到PATH的理想候选路径,因为它们看起来像是安装的根级别的可执行文件。那些用红色突出显示的不适合,因为有些是虚拟环境的一部分——你可以在路径中看到venv——有些是快捷方式或内部 Windows 安装。
您还可能会遇到安装在不同程序的文件夹中的 Python 可执行文件。这是因为许多应用程序在其中捆绑了自己的 Python 版本。这些捆绑的 Python 安装也不合适。
找到 Python 可执行文件后,打开开始菜单并搜索编辑系统环境变量条目,这将打开一个系统属性窗口。在高级选项卡中,点击按钮环境变量。在那里,您将看到用户和系统变量,您可以编辑这些变量:
https://player.vimeo.com/video/729132627
在标题为用户变量的部分,双击显示路径的条目。将弹出另一个窗口,显示路径列表。点击新建按钮,将 Python 可执行文件的路径粘贴到那里。插入后,选择新添加的路径并点击上移按钮,直到它位于顶部。
就是这样!您可能需要重新启动您的计算机以使更改生效,但是您现在应该能够从命令行调用python。
要从命令行设置PATH环境变量,请查看 Windows Python 编码设置指南中关于配置环境变量的章节。您也可以在补充材料中找到说明:
补充代码: 点击这里下载免费的补充代码,它将带你穿越操作系统的变化之路。
你可能还想在你的 Linux 或 macOS 机器上设置PATH,或者你可能正在使用 Windows 子系统 for Linux (WSL) 。如果是这样,请阅读下一节,了解基于 UNIX 的系统上的过程。
如何在 Linux 和 macOS 上给PATH添加 Python
由于 Python 通常预装在基于 UNIX 的系统上,Linux 和 macOS 上最常见的问题是运行错误的python,而不是找不到任何 python。也就是说,在本节中,您将排除根本无法运行python的故障。
**注意:**根据您的特定系统,Python 2 可能有一个python程序,Python 3 可能有一个python3程序。在其他情况下,python和python3将指向同一个可执行文件。
第一步是定位目标 Python 可执行文件。它应该是一个可以运行的程序,首先导航到包含它的目录,然后在命令行上键入./python。
您需要使用当前文件夹(./)中的相对路径预先调用 Python 可执行文件,因为否则您将调用当前记录在您的PATH中的任何 Python。正如您之前了解到的,这可能不是您想要运行的 Python 解释器。
通常 Python 可执行文件可以在/bin/文件夹中找到。但是如果 Python 已经在/bin/文件夹中,那么它很可能已经在PATH中,因为/bin/是系统自动添加的。如果是这种情况,那么您可能想跳到关于PATH 中路径顺序的章节。
既然您在这里可能是因为您已经安装了 Python,但是当您在命令行上键入python时仍然找不到它,那么您将希望在另一个位置搜索它。
**注意:**快速搜索大文件夹的一个很棒的搜索工具是 fzf 。它从命令行工作,并将搜索当前工作目录中的所有文件和文件夹。例如,你可以从你的主目录中搜索python。然后 fzf 会显示包含python的路径。
也就是说,/bin/可能已经从PATH中完全删除,在这种情况下,你可以跳到关于管理PATH 的部分。
一旦你找到了你的 Python 可执行文件,并且确定它正在工作,记下路径以便以后使用。现在是时候开始将它添加到您的PATH环境变量中了。
首先,您需要导航到您的个人文件夹,查看您有哪些可用的配置脚本:
$ cd ~
$ ls -a
您应该会看到一堆以句点(.)开头的配置文件。这些文件俗称为点文件,默认情况下对ls隐藏。
每当您登录到系统时,都会执行一两个点文件,每当您启动一个新的命令行会话时,都会运行另外一两个点文件,而其他大多数点文件则由其他应用程序用于配置设置。
您正在寻找在启动系统或新的命令行会话时运行的文件。他们可能会有类似的名字:
.profile.bash_profile.bash_login.zprofile.zlogin
要查找的关键字是个人资料和登录。理论上,您应该只有其中一个,但是如果您有多个,您可能需要阅读其中的注释,以确定哪些在登录时运行。例如,Ubuntu 上的.profile文件通常会有以下注释:
# This file is not read by bash(1), if ~/.bash_profile or ~/.bash_login
# exists.
所以,如果你既有.profile又有.bash_profile,那么你会想要使用.bash_profile。
您还可以使用一个.bashrc或.zshrc文件,它们是在您启动新的命令行会话时运行的脚本。运行命令 (rc)文件是放置PATH配置的常用地方。
**注意:**学究气地说,rc 文件一般用于影响你的命令行提示符的外观和感觉的设置,而不是用于配置像PATH这样的环境变量。但是如果您愿意,您可以使用 rc 文件进行您的PATH配置。
要将 Python 路径添加到您的PATH环境变量的开头,您将在命令行上执行一个命令。
使用下面一行,将<PATH_TO_PYTHON>替换为 Python 可执行文件的实际路径,将.profile替换为系统的登录脚本:
$ echo export PATH="<PATH_TO_PYTHON>:$PATH" >> ~/.profile
该命令将export PATH="<PATH_TO_PYTHON>:$PATH"添加到.profile的末尾。命令export PATH="<PATH_TO_PYTHON>:$PATH"将<PATH_TO_PYTHON>添加到PATH环境变量中。它类似于 Python 中的以下操作:
>>> PATH = "/home/realpython/apps:/bin"
>>> PATH = f"/home/realpython/python:{PATH}"
>>> PATH
'/home/realpython/python:/home/realpython/apps:/bin'
因为PATH只是一个由冒号分隔的字符串,所以在前面加上一个值需要创建一个新路径的字符串,一个冒号,然后是旧路径。使用这个字符串,您可以设置PATH的新值。
要刷新您当前的命令行会话,您可以运行以下命令,用您选择的登录脚本替换.profile:
$ source ~/.profile
现在,您应该能够直接从命令行调用python。下次登录时,Python 应该会自动添加到PATH中。
如果你觉得这个过程有点不透明,你并不孤单!请继续阅读,深入了解正在发生的事情。
理解什么是PATH什么是
PATH是包含文件夹路径列表的环境变量。PATH中的每个路径由冒号或分号分隔——基于 UNIX 的系统用冒号,Windows 用分号。它就像一个 Python 变量,用一个长字符串作为它的值。不同之处在于PATH是一个几乎所有程序都可以访问的变量。
像命令行这样的程序使用PATH环境变量来查找可执行文件。例如,每当您在命令行中键入一个程序的名称时,命令行就会在各个地方搜索该程序。命令行搜索的地方之一是PATH。
PATH中的所有路径都必须是目录——它们不应该直接是文件或可执行文件。使用PATH的程序依次进入每个目录并搜索其中的所有文件。不过,PATH目录下的子目录不会被搜索。所以仅仅把你的根路径加到PATH是没有用的!
同样重要的是要注意,使用PATH的程序通常不搜索除了可执行文件之外的任何东西。所以,你不能用PATH来定义常用文件的快捷方式。
理解PATH 内顺序的重要性
如果在命令行中键入python,命令行将在PATH环境变量的每个文件夹中查找一个python可执行文件。一旦它找到一个,它就会停止搜索。这就是为什么您将 Python 可执行文件的路径前置到PATH的原因。将新添加的路径放在第一个可以确保您的系统能够找到这个 Python 可执行文件。
一个常见的问题是在您的PATH上安装 Python 失败。如果损坏的可执行文件是命令行遇到的第一个文件,那么命令行将尝试运行该文件,然后中止任何进一步的搜索。对此的快速解决方法是在旧的 Python 目录之前添加新的 Python 目录*,尽管您可能也想清除系统中的错误 Python 安装。*
在 Windows 上重新排序PATH相对简单。打开 GUI 控制面板,使用上移和下移按钮调整顺序。但是,如果您使用的是基于 UNIX 的操作系统,那么这个过程会更加复杂。请继续阅读,了解更多信息。
在基于 UNIX 的系统上管理您的PATH
通常,当你管理你的PATH时,你的第一个任务是看看里面有什么。要查看 Linux 或 macOS 中任何环境变量的值,可以使用echo命令:
$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/home/realpython/badpython:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games
注意,$符号是用来告诉命令行下面的标识符是一个变量。这个命令的问题是,它只是将所有路径转储到一行中,用冒号分隔。因此,您可能想利用 tr 命令将冒号转换成换行符:
$ echo $PATH | tr ":" "\n"
/usr/local/sbin
/usr/local/bin
/usr/sbin
/home/realpython/badpython
/usr/bin
/sbin
/bin
/usr/games
/usr/local/games
在这个例子中,你可以看到badpython出现在PATH中。理想的做法是执行一些PATH考古,并找出它在哪里被添加到PATH,但是现在,你只是想通过在你的登录脚本中添加一些东西来删除它。
因为PATH是一个 shell 字符串,你不能使用方便的方法来删除它的一部分,就像如果它是一个 Python 列表一样。也就是说,您可以将几个 shell 命令连接起来实现类似的功能:
export PATH=`echo $PATH | tr ":" "\n" | grep -v 'badpython' | tr "\n" ":"`
该命令从上一个命令中获取列表,并将其输入到grep,它与和-v开关一起过滤掉包含子串badpython的任何行。然后,您可以将换行符翻译回冒号,这样您就有了一个新的有效的PATH字符串,您可以立即使用它来替换旧的PATH字符串。
虽然这可能是一个方便的命令,但理想的解决方案是找出错误路径添加到哪里。您可以尝试查看其他登录脚本或检查/etc/中的特定文件。例如,在 Ubuntu 中,有一个名为environment的文件,它通常定义了系统的启动路径。在 macOS 中,这可能是/etc/paths。在/etc/中也可能有profile文件和文件夹包含启动脚本。
/etc/中的配置和您的个人文件夹中的配置之间的主要区别在于,/etc/中的配置是系统范围的,而您的个人文件夹中的配置则是针对您的用户的。
不过,这通常会涉及到一点考古学,来追踪你的PATH中添加了什么东西。因此,您可能希望在您的登录或 rc 脚本中添加一行来过滤掉来自PATH的某些条目,以此作为快速解决方案。
结论
在本教程中,您已经学习了如何在 Windows、Linux 和 macOS 上将 Python 或任何其他程序添加到您的PATH环境变量中。您还了解了更多关于什么是PATH,以及为什么考虑它的内部顺序是至关重要的。最后,您还发现了如何在基于 UNIX 的系统上管理您的PATH,因为这比在 Windows 上管理您的PATH更复杂。
补充代码: 点击这里下载免费的补充代码,它将带你穿越操作系统的变化之路。***
向 Django 添加社会认证
原文:https://realpython.com/adding-social-authentication-to-django/
Python Social Auth 是一个库,它提供了“一个易于设置的社交认证/注册机制,支持多个框架和认证提供者”。在本教程中,我们将详细介绍如何将这个库集成到一个 Django 项目中来提供用户认证。
我们使用的是什么:
- Django==1.7.1
- python-social-auth==0.2.1
Django 设置
如果你已经准备好了一个项目,可以跳过这一部分。
创建并激活一个 virtualenv,安装 Django,然后启动一个新的 Django 项目:
$ django-admin.py startproject django_social_project
$ cd django_social_project
$ python manage.py startapp django_social_app
设置初始表并添加超级用户:
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, contenttypes, auth, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying sessions.0001_initial... OK
$ python manage.py createsuperuser
Username (leave blank to use 'michaelherman'): admin
Email address: ad@min.com
Password:
Password (again):
Superuser created successfully.
在项目根目录下创建一个名为“templates”的新目录,然后将正确的路径添加到 settings.py 文件中:
TEMPLATE_DIRS = (
os.path.join(BASE_DIR, 'templates'),
)
运行开发服务器以确保一切正常,然后导航到 http://localhost:8000/ 。你应该看到“成功了!”页面。
您的项目应该如下所示:
└── django_social_project
├── db.sqlite3
├── django_social_app
│ ├── __init__.py
│ ├── admin.py
│ ├── migrations
│ │ └── __init__.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── django_social_project
│ ├── __init__.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── manage.py
└── templates
Python 社交认证设置
按照以下步骤和/或官方安装指南安装和设置基本配置。
安装
使用 pip 安装:
$ pip install python-social-auth==0.2.1
配置
更新 settings.py 以在我们的项目中包含/注册该库:
INSTALLED_APPS = (
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'django_social_project',
'social.apps.django_app.default',
)
TEMPLATE_CONTEXT_PROCESSORS = (
'django.contrib.auth.context_processors.auth',
'django.core.context_processors.debug',
'django.core.context_processors.i18n',
'django.core.context_processors.media',
'django.core.context_processors.static',
'django.core.context_processors.tz',
'django.contrib.messages.context_processors.messages',
'social.apps.django_app.context_processors.backends',
'social.apps.django_app.context_processors.login_redirect',
)
AUTHENTICATION_BACKENDS = (
'social.backends.facebook.FacebookOAuth2',
'social.backends.google.GoogleOAuth2',
'social.backends.twitter.TwitterOAuth',
'django.contrib.auth.backends.ModelBackend',
)
注册后,更新数据库:
$ python manage.py makemigrations
Migrations for 'default':
0002_auto_20141109_1829.py:
- Alter field user on usersocialauth
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, default, contenttypes, auth, sessions
Running migrations:
Applying default.0001_initial... OK
Applying default.0002_auto_20141109_1829... OK
在 urls.py 中更新项目的urlpatterns,以包含主要的授权 URL:
urlpatterns = patterns(
'',
url(r'^admin/', include(admin.site.urls)),
url('', include('social.apps.django_app.urls', namespace='social')),
)
接下来,您需要从想要包含的每个社交应用程序中获取所需的认证密钥。这个过程对于许多流行的社交网络来说是相似的——像推特、脸书和谷歌。让我们以 Twitter 为例…
Twitter 认证密钥
在https://apps.twitter.com/app/new创建一个新的应用程序,并确保使用回调 URLhttp://127 . 0 . 0 . 1:8000/complete/Twitter。
在“django_social_project”目录中,添加一个名为 config.py 的新文件。从 Twitter 的“Keys and Access Tokens”选项卡下获取Consumer Key (API Key)和Consumer Secret (API Secret),并将其添加到配置文件中,如下所示:
SOCIAL_AUTH_TWITTER_KEY = 'update me'
SOCIAL_AUTH_TWITTER_SECRET = 'update me'
让我们将以下 URL 添加到 config.py 中,以指定登录和重定向 URL(在用户验证之后):
SOCIAL_AUTH_LOGIN_REDIRECT_URL = '/home/'
SOCIAL_AUTH_LOGIN_URL = '/'
将以下导入添加到 settings.py :
from config import *
确保将 config.py 添加到您的中。gitignore 文件,因为不想将此文件添加到版本控制中,因为它包含敏感信息。
欲了解更多信息,请查看官方文件。
健全性检查
让我们来测试一下。启动服务器并导航到http://127 . 0 . 0 . 1:8000/log in/Twitter,授权应用程序,如果一切正常,你应该会被重定向到http://127 . 0 . 0 . 1:8000/home/(与SOCIAL_AUTH_LOGIN_REDIRECT_URL相关联的 URL)。您应该会看到 404 错误,因为我们还没有设置路由、视图或模板。
让我们现在就开始吧…
友好的观点
现在,我们只需要两个视图——登录和主页。
URLs
更新 urls.py 中的 URL 模式:
urlpatterns = patterns(
'',
url(r'^admin/', include(admin.site.urls)),
url('', include('social.apps.django_app.urls', namespace='social')),
url(r'^$', 'django_social_app.views.login'),
url(r'^home/$', 'django_social_app.views.home'),
url(r'^logout/$', 'django_social_app.views.logout'),
)
除了/和home/航线,我们还增加了logout/航线。
视图
接下来,添加以下视图函数:
from django.shortcuts import render_to_response, redirect, render
from django.contrib.auth import logout as auth_logout
from django.contrib.auth.decorators import login_required
# from django.template.context import RequestContext
def login(request):
# context = RequestContext(request, {
# 'request': request, 'user': request.user})
# return render_to_response('login.html', context_instance=context)
return render(request, 'login.html')
@login_required(login_url='/')
def home(request):
return render_to_response('home.html')
def logout(request):
auth_logout(request)
return redirect('/')
在login()函数中,我们用RequestContext获取登录的用户。作为参考,实现这一点的更明确的方法被注释掉了。
模板
添加两个模板home.html和 login.htmlT2。
home.html
<h1>Welcome</h1>
<p><a href="/logout">Logout</a>
login.html
{% if user and not user.is_anonymous %}
<a>Hello, {{ user.get_full_name }}!</a>
<br>
<a href="/logout">Logout</a>
{% else %}
<a href="{% url 'social:begin' 'twitter' %}?next={{ request.path }}">Login with Twitter</a>
{% endif %}
您的项目现在应该如下所示:
└── django_social_project
├── db.sqlite3
├── django_social_app
│ ├── __init__.py
│ ├── admin.py
│ ├── migrations
│ │ └── __init__.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── django_social_project
│ ├── __init__.py
│ ├── config.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── manage.py
└── templates
├── home.html
└── login.html
再测试一次。启动服务器。确保首先注销,因为用户应该已经从最后一次测试中登录,然后测试登录和注销。登录后,用户应该被重定向到/home。
接下来的步骤
在这一点上,你可能想要添加更多的认证提供者——像脸书和谷歌。添加新的社交身份验证提供者的工作流程很简单:
- 在提供商的网站上创建新的应用程序。
- 设置回调 URL。
- 获取密钥/令牌并将其添加到 config.py 中。
- 将新的提供者添加到 settings.py 中的
AUTHENTICATION_BACKENDS元组中。 - 通过添加新的 URL 来更新登录模板,如 so -
<a href="{% url 'social:begin' 'ADD AUTHENTICATION PROVIDER NAME' %}?next={{ request.path }}">Login with AUTHENTICATION PROVIDER NAME</a>。
请查看正式文件了解更多信息。请在下面留下评论和问题。感谢阅读!
哦——一定要从回购中获取代码。***
Python 开发人员的高级 Git 技巧
如果你已经在 Git 方面做了一点工作,并且开始理解我们在 Git 简介中介绍的基础知识,但是你想学习更高效和更好的控制,那么这就是你要找的地方!
在本教程中,我们将讨论如何处理特定的提交和整个范围的提交,使用 stash 来保存临时工作,比较不同的提交,更改历史,以及如何在出现问题时清理混乱。
本文假设您已经阅读了我们的第一个 Git 教程,或者至少了解 Git 是什么以及它是如何工作的。
有很多事情要谈,所以我们开始吧。
版本选择
有几个选项可以告诉 Git 您想要使用哪个修订(或提交)。我们已经看到,我们可以使用完整的 SHA ( 25b09b9ccfe9110aed2d09444f1b50fa2b4c979c)和短的 SHA ( 25b09b9cc)来表示修订。
我们还看到了如何使用HEAD或分支名称来指定特定的提交。然而,Git 还有其他一些技巧。
相对参考
有时,能够指示相对于已知位置的修订是有用的,比如HEAD或分支名称。Git 提供了两个操作符,虽然相似,但行为略有不同。
第一个是波浪号(~)操作符。Git 使用代字号指向提交的父级,因此HEAD~表示最后一次提交之前的修订。要进一步后退,您可以在波浪号后使用一个数字:HEAD~3带您后退三级。
在我们遇到合并之前,这一切都很好。合并提交有两个父对象,所以~只选择第一个。虽然这有时可行,但有时您希望指定第二个或更晚的父代。这就是为什么 Git 有脱字符(^)操作符。
^操作符移动到指定版本的特定父版本。你用一个数字来表示哪个父母。所以HEAD^2告诉 Git 选择最后提交的第二个父代,而不是的“祖父代”可以重复此操作以进一步后退:HEAD^2^^带您后退三级,在第一步选择第二个父级。如果不给出数字,Git 假设1。
**注意:**使用 Windows 的用户需要使用第二个^来转义 DOS 命令行上的^字符。
我承认,为了让生活变得更有趣,可读性更差,Git 允许您组合这些方法,所以如果您使用 merges 回溯树结构,那么25b09b9cc^2~3^3是一种有效的表示修订的方式。它会将您带到第二个父代,然后从该父代返回三个修订版本,然后到第三个父代。
修订范围
有几种不同的方法来指定像git log这样的命令的提交范围。然而,这些并不完全像 Python 中的切片那样工作,所以要小心!
双点符号
用于指定范围的“双点”方法看起来像它的声音:git log b05022238cdf08..60f89368787f0e。这很容易让人想到这是在说“显示从b05022238cdf08到60f89368787f0e的所有提交”,如果b05022238cdf08是60f89368787f0e的直接祖先,这就是它所做的。
**注意:**在本节的剩余部分,我将用大写字母替换单个提交的 sha,因为我认为这样会使图表更容易理解。我们稍后也将使用这个“假”符号。
然而,它比那更强大一点。双点符号实际上向您显示了第二次提交中包含的所有提交,而第一次提交中不包含这些提交。让我们看几个图表来阐明:
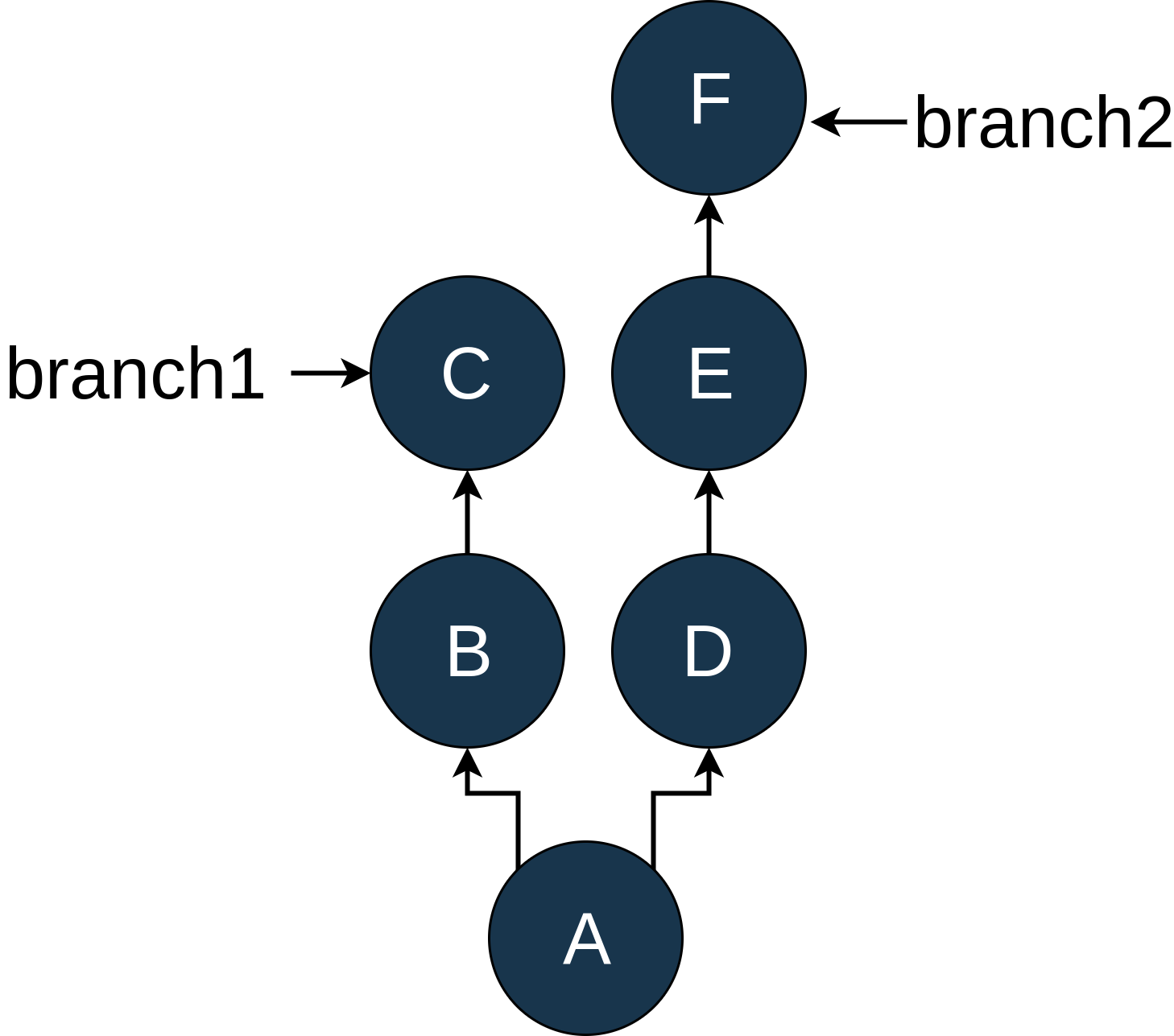
如您所见,在我们的示例回购中有两个分支,branch1和branch2,它们在提交A后分叉。首先,让我们看看简单的情况。我修改了日志输出,使其与图表相匹配:
$ git log --oneline D..F
E "Commit message for E"
F "Commit message for F"
D..F给出了在提交D之后branch2 的所有提交。
下面是一个更有趣的例子,也是我在撰写本教程时了解到的一个例子:
$ git log --oneline C..F
D "Commit message for D"
E "Commit message for E"
F "Commit message for F"
这显示了属于提交F的提交,而不属于提交C的提交。由于这里的结构,这些提交没有前/后关系,因为它们在不同的分支上。
如果把C和F的顺序对调,你觉得会得到什么?
$ git log --oneline F..C
B "Commit message for B"
C "Commit message for C"
三重点
你猜对了,三点符号在修订说明符之间使用了三个点。这以类似于双点符号的方式工作,除了它显示了在任一版本中的所有提交,这些提交不包括在两个版本中。对于上面的图表,使用C...F向您展示了这一点:
$ git log --oneline C...F
D "Commit message for D"
E "Commit message for E"
F "Commit message for F"
B "Commit message for B"
C "Commit message for C"
当您想要对一个命令使用一系列提交时,双点和三点符号可能非常强大,但是它们并不像许多人认为的那样简单。
分行对总行对 SHA
这可能是回顾 Git 中有哪些分支以及它们如何与 sha 和 HEAD 相关联的好时机。
HEAD是 Git 用来指代“你的文件系统现在指向的地方”的名字大多数情况下,这将指向一个指定的分支,但也不是必须如此。为了了解这些想法,让我们看一个例子。假设您的历史如下所示:
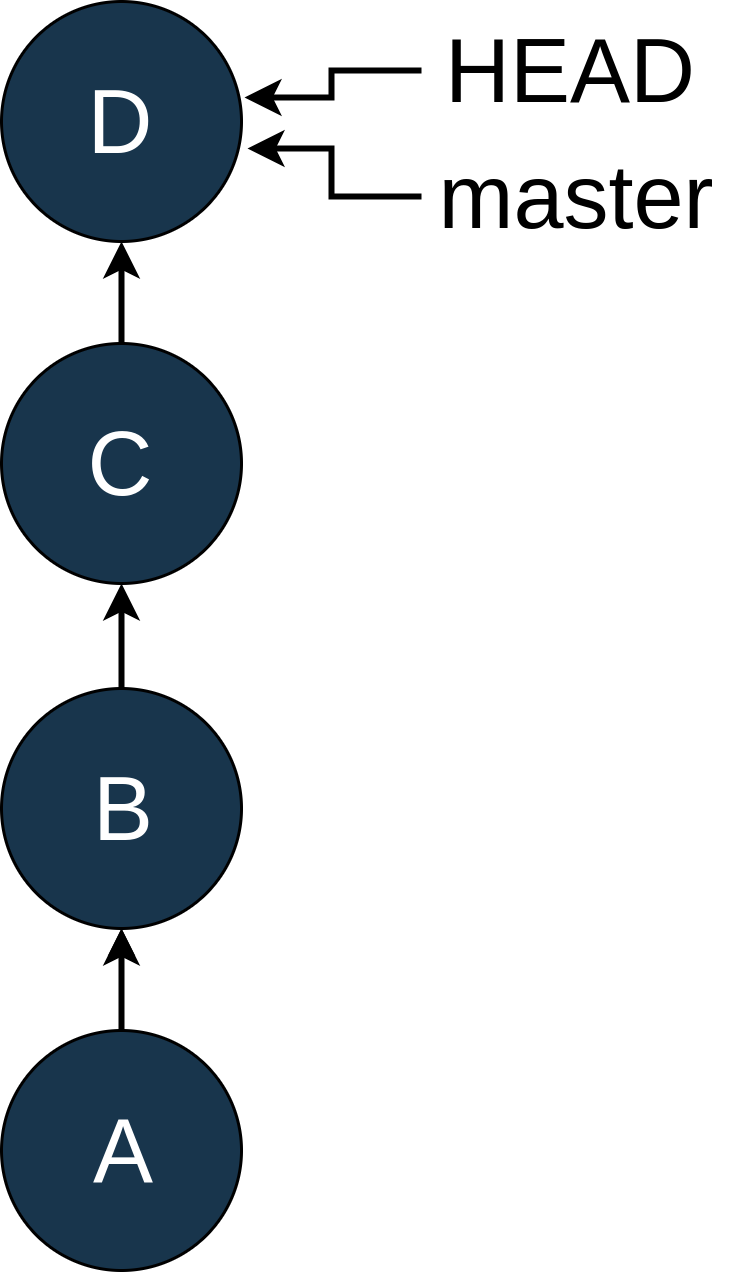
此时,您发现在 commit B. Rats 中意外地提交了一个 Python 日志记录语句。现在,大多数人会添加一个新的提交,E,推送到master,然后就完成了。但是你正在学习 Git,并且想要用困难的方式来解决这个问题,并且隐藏你在历史上犯了一个错误的事实。
所以你使用git checkout B将HEAD移回B,看起来像这样:
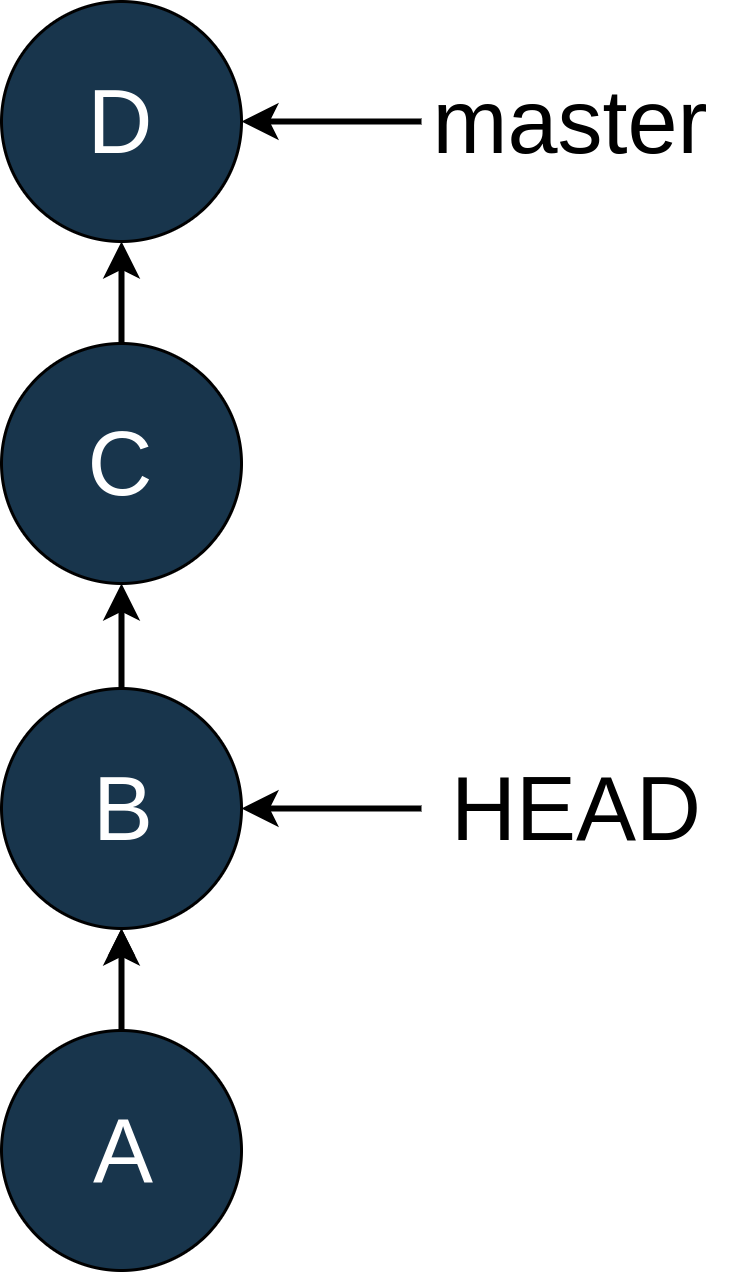
你可以看到master没有改变位置,但是HEAD现在指向了B。在 Git 入门教程中,我们谈到了“分离头”状态。这又是那个状态!
因为您想要提交更改,所以您用git checkout -b temp创建了一个新的分支:
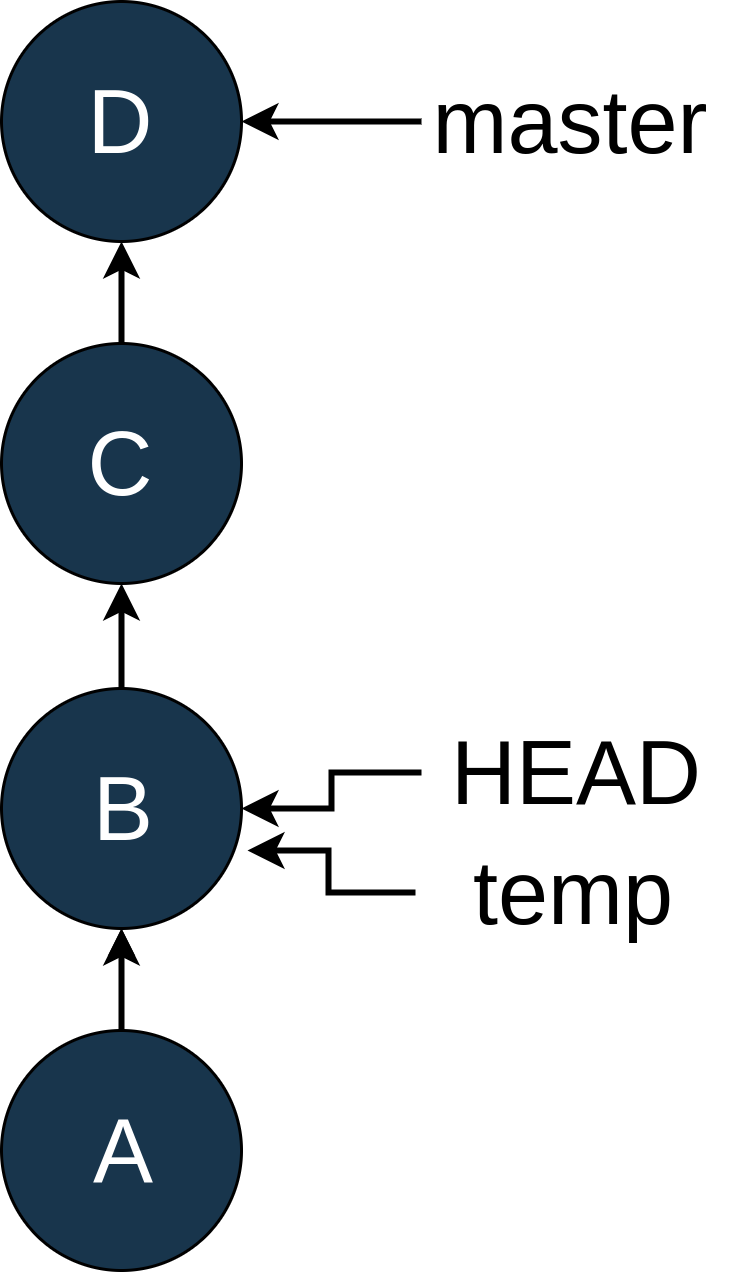
现在,您可以编辑该文件并删除有问题的日志语句。一旦完成,您就可以使用git add和git commit --amend来修改提交B:

哇哦。这里有一个名为B'的新提交。就像B一样,它的父节点是A,而C对此一无所知。现在我们希望 master 基于这个新的 commit,B'。
因为您有敏锐的记忆力,所以您记得 rebase 命令就是这样做的。因此,您可以通过键入git checkout master返回到master分支:
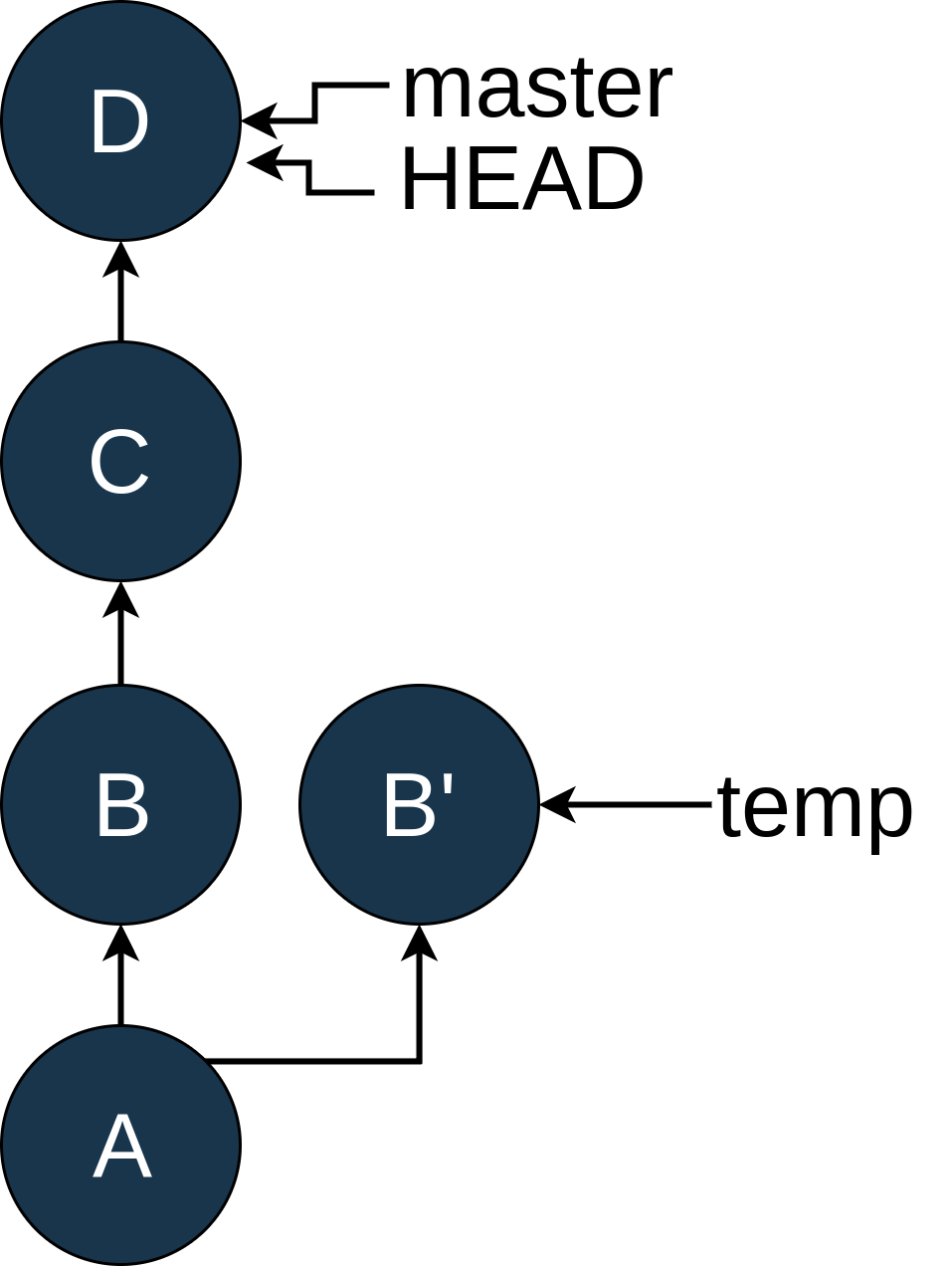
一旦你上了主游戏,你可以使用git rebase temp在B上重放C和D:
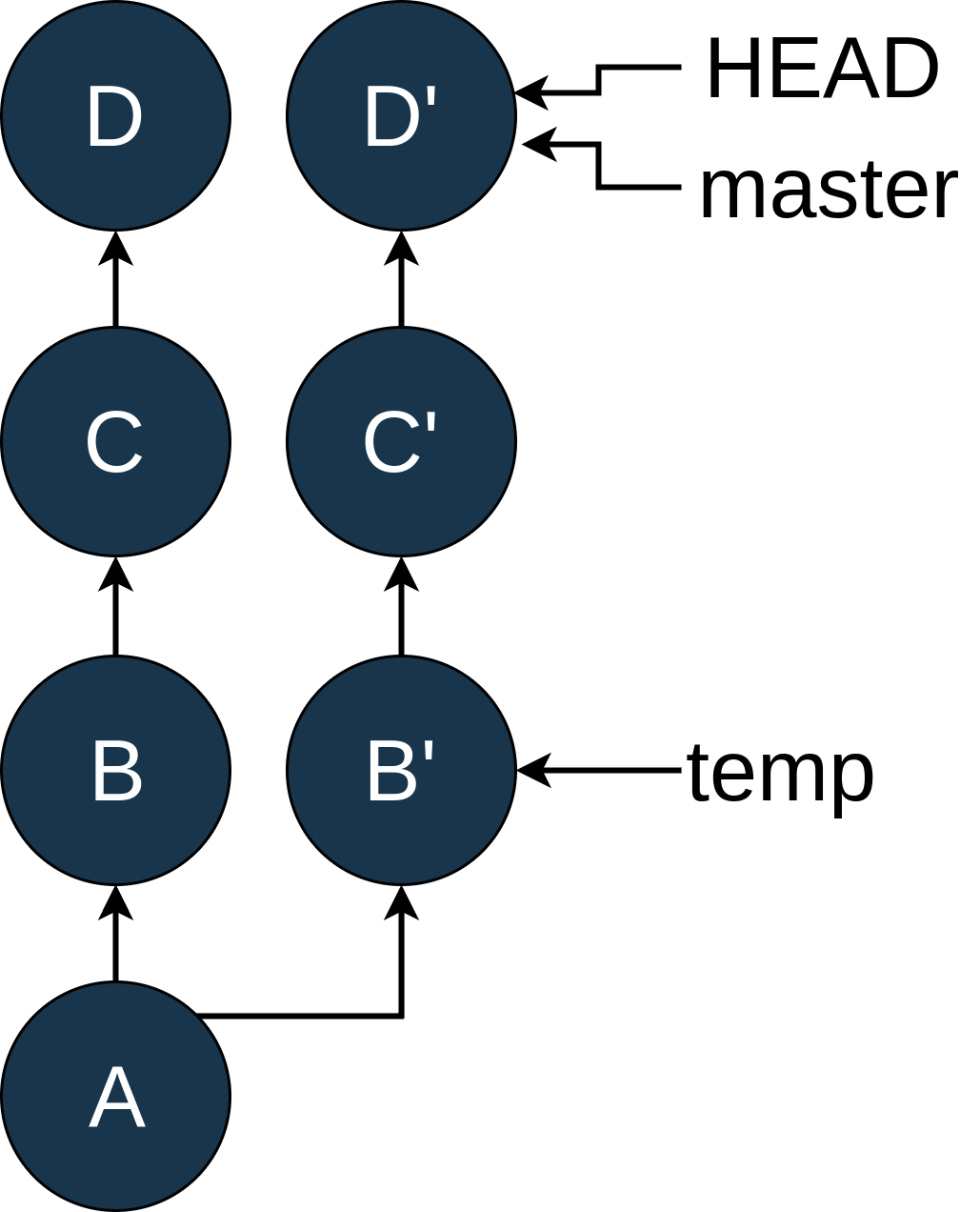
您可以看到 rebase 创建提交了C'和D'。C'仍然有和C一样的变化,D'也有和D一样的变化,但是他们有不同的 sha,因为他们现在是基于B'而不是B。
正如我前面提到的,您通常不会为了修复一个错误的日志语句而这么麻烦,但是有时候这种方法可能是有用的,并且它确实说明了HEAD、提交和分支之间的区别。
更
Git 的锦囊妙计更多,但我将在这里停下来,因为我很少看到在野外使用的其他方法。如果你想了解如何对两个以上的分支进行类似的操作,请查阅 Pro Git 书籍中关于修订选择的精彩文章。
处理中断:git stash
我经常使用并且觉得非常方便的 Git 特性之一是stash。它提供了一种简单的机制来保存您正在处理但尚未准备好提交的文件,以便您可以切换到不同的任务。在这一节中,您将首先浏览一个简单的用例,查看每一个不同的命令和选项,然后您将总结一些其他的用例,在这些用例中git stash真正发挥了作用。
git stash save和git stash pop
假设你正在处理一个讨厌的 bug。您已经在两个文件file1和file2中获得了 Python 日志代码,以帮助您跟踪它,并且您已经添加了file3作为一个可能的解决方案。
简而言之,回购的变化如下:
- 您已经编辑了
file1并完成了git add file1。 - 您已经编辑了
file2但尚未添加。 - 您已经创建了
file3但尚未添加。
你做一个git status来确认回购的条件:
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: file1
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: file2
Untracked files:
(use "git add <file>..." to include in what will be committed)
file3
现在一个同事(他们不讨厌吗?)走过来告诉你产量下降了,轮到你了。你知道你可以发挥你疯狂的技能来节省时间和扭转局面。
您还没有完成文件 1、2 和 3 的工作,所以您真的不想提交这些更改,但是您需要将它们从您的工作目录中删除,以便您可以切换到不同的分支来修复这个 bug。这是git stash最基本的用例。
您可以使用git stash save暂时“将这些更改放在一边”,并返回到一个干净的工作目录。stash的默认选项是save,所以通常只写为git stash。
当您保存一些东西到stash时,它会为这些更改创建一个唯一的存储点,并将您的工作目录返回到上次提交的状态。它用一个神秘的信息告诉你它做了什么:
$ git stash save
Saved working directory and index state WIP on master: 387dcfc adding some files
HEAD is now at 387dcfc adding some files
在该输出中,master是分支的名称,387dcfc是最后一次提交的 SHA,adding some files是该提交的提交消息,WIP代表“正在进行的工作”在这些细节上,你的回购协议的输出可能会有所不同。
如果此时执行status,它仍会显示file3为未跟踪文件,但file1和file2不再存在:
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
file3
nothing added to commit but untracked files present (use "git add" to track)
在这一点上,就 Git 而言,您的工作目录是“干净的”,您可以自由地做一些事情,比如签出不同的分支、精选更改或任何您需要做的事情。
你去检查了另一个分支,修复了错误,赢得了同事的赞赏,现在准备好回到这个工作中。
你怎么把最后一批货拿回来?git stash pop!
此时使用pop命令如下所示:
$ git stash pop
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: file1
modified: file2
Untracked files:
(use "git add <file>..." to include in what will be committed)
file3
no changes added to commit (use "git add" and/or "git commit -a")
Dropped refs/stash@{0} (71d0f2469db0f1eb9ee7510a9e3e9bd3c1c4211c)
现在,您可以在底部看到一条关于“丢弃的引用/存储@{0}”的消息。我们将在下面详细讨论该语法,但它基本上是说它应用了您隐藏的更改并清除了隐藏本身。在你问之前,是的,有一种方法可以使用这些藏起来的东西并且而不是处理掉它,但是我们不要想得太多。
你会注意到file1曾经在索引中,但现在不在了。默认情况下,git stash pop不会像那样维护变更的状态。当然,有一个选项告诉它这样做。将file1添加回索引,然后重试:
$ git add file1
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: file1
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: file2
Untracked files:
(use "git add <file>..." to include in what will be committed)
file3
$ git stash save "another try"
Saved working directory and index state On master: another try
HEAD is now at 387dcfc adding some files
$ git stash pop --index
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: file1
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: file2
Untracked files:
(use "git add <file>..." to include in what will be committed)
file3
Dropped refs/stash@{0} (aed3a02aeb876c1137dd8bab753636a294a3cc43)
您可以看到,我们第二次向git pop命令添加了--index选项,这告诉它尝试维护文件是否在索引中的状态。
在前两次尝试中,你可能注意到file3不在你的收藏中。您可能希望将file3与其他更改放在一起。幸运的是,有一个选项可以帮助你:--include-untracked。
假设我们回到了上一个示例结束时的位置,我们可以重新运行命令:
$ git stash save --include-untracked "third attempt"
Saved working directory and index state On master: third attempt
HEAD is now at 387dcfc adding some files
$ git status
On branch master
nothing to commit, working directory clean
这就把未被跟踪的file3和我们其他的变化放在了一起。
在我们继续之前,我只想指出save是git stash的默认选项。除非你正在指定一个消息,我们将在后面讨论,你可以简单地使用git stash,它将做一个save。
git stash list
git stash的一个强大特性是你可以拥有不止一个。Git 将数据存储在一个栈中,这意味着默认情况下,它总是使用最近保存的数据。git stash list命令将显示本地 repo 中的堆栈。让我们创建几个仓库,这样我们就可以看到它是如何工作的:
$ echo "editing file1" >> file1
$ git stash save "the first save"
Saved working directory and index state On master: the first save
HEAD is now at b3e9b4d adding file3
$ # you can see that stash save cleaned up our working directory
$ # now create a few more stashes by "editing" files and saving them
$ echo "editing file2" >> file2
$ git stash save "the second save"
Saved working directory and index state On master: the second save
HEAD is now at b3e9b4d adding file3
$ echo "editing file3" >> file3
$ git stash save "the third save"
Saved working directory and index state On master: the third save
HEAD is now at b3e9b4d adding file3
$ git status
On branch master
nothing to commit, working directory clean
你现在有三个不同的仓库保存。幸运的是,Git 有一个处理 stashes 的系统,使得这个问题很容易处理。系统的第一步是git stash list命令:
$ git stash list
stash@{0}: On master: the third save
stash@{1}: On master: the second save
stash@{2}: On master: the first save
列表显示您在此回购中的堆栈,最新的在最前面。注意每个条目开头的stash@{n}语法吗?那是藏毒点的名字。其余的git stash子命令将使用该名称来引用一个特定的存储。一般来说,如果你不给出一个名字,它总是假设你指的是最近的藏匿,stash@{0}。稍后你会看到更多。
这里我想指出的另一件事是,您可以在清单中看到我们执行git stash save "message"命令时使用的消息。如果你藏了很多东西,这会很有帮助。
如上所述,git stash save [name]命令的save [name]部分是不需要的。你可以简单地输入git stash,它默认为一个保存命令,但是自动生成的消息不会给你太多信息:
$ echo "more editing file1" >> file1
$ git stash
Saved working directory and index state WIP on master: 387dcfc adding some files
HEAD is now at 387dcfc adding some files
$ git stash list
stash@{0}: WIP on master: 387dcfc adding some files
stash@{1}: On master: the third save
stash@{2}: On master: the second save
stash@{3}: On master: the first save
默认消息是WIP on <branch>: <SHA> <commit message>.,没告诉你多少。如果我们对前三次藏匿都这样做,他们会得到同样的信息。这就是为什么,对于这里的例子,我使用完整的git stash save <message>语法。
git stash show
好了,现在你有了一堆藏物,你甚至可以用有意义的信息来描述它们,但是如果你想知道某个藏物里到底有什么呢?这就是git stash show命令的用武之地。使用默认选项会告诉您有多少文件发生了更改,以及哪些文件发生了更改:
$ git stash show stash@{2}
file1 | 1 +
1 file changed, 1 insertion(+)
然而,默认选项并没有告诉您发生了什么变化。幸运的是,您可以添加-p/--patch选项,它会以“补丁”格式向您展示不同之处:
$ git stash show -p stash@{2}
diff --git a/file1 b/file1
index e212970..04dbd7b 100644
--- a/file1
+++ b/file1
@@ -1 +1,2 @@
file1
+editing file1
这里显示行“编辑文件 1”被添加到file1。如果您不熟悉显示差异的补丁格式,不要担心。当您到达下面的git difftool部分时,您将看到如何在一个存储上调出一个可视化的比较工具。
git stash popvsgit stash applyT2】
您在前面已经看到了如何使用git stash pop命令将最近的存储放回到您的工作目录中。您可能已经猜到,我们前面看到的 stash name 语法也适用于 pop 命令:
$ git stash list
stash@{0}: On master: the third save
stash@{1}: On master: the second save
stash@{2}: On master: the first save
$ git stash pop stash@{1}
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
while read line; do echo -n "$line" | wc -c; done<
modified: file2
no changes added to commit (use "git add" and/or "git commit -a")
Dropped stash@{1} (84f7c9890908a1a1bf3c35acfe36a6ecd1f30a2c)
$ git stash list
stash@{0}: On master: the third save
stash@{1}: On master: the first save
您可以看到,git stash pop stash@{1}将“第二次保存”放回到我们的工作目录中,并折叠了我们的堆栈,因此只有第一个和第三个堆栈在那里。请注意在pop之后,“第一次保存”是如何从stash@{2}变为stash@{1}的。
也可以把一个存储放在你的工作目录中,但是也可以把它留在堆栈中。这是通过git stash apply完成的:
$ git stash list
stash@{0}: On master: the third save
stash@{1}: On master: the first save
$ git stash apply stash@{1}
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: file1
modified: file2
no changes added to commit (use "git add" and/or "git commit -a")
$ git stash list
stash@{0}: On master: the third save
stash@{1}: On master: the first save
如果您想要多次应用同一组更改,这可能会很方便。我最近在原型硬件上工作时使用了这个。为了让代码在我桌子上的特定硬件上工作,需要做一些修改,但其他的都不需要。每次我下载新的 master 副本时,我都会使用git stash apply来应用这些更改。
git stash drop
要查看的最后一个 stash 子命令是drop。当您想要丢弃一个存储库并且不将它应用到您的工作目录时,这是非常有用的。看起来是这样的:
$ git status
On branch master
nothing to commit, working directory clean
$ git stash list
stash@{0}: On master: the third save
stash@{1}: On master: the first save
$ git stash drop stash@{1}
Dropped stash@{1} (9aaa9996bd6aa363e7be723b4712afaae4fc3235)
$ git stash drop
Dropped refs/stash@{0} (194f99db7a8fcc547fdd6d9f5fbffe8b896e2267)
$ git stash list
$ git status
On branch master
nothing to commit, working directory clean
这删除了最后两个栈,Git 没有改变您的工作目录。在上面的例子中有一些事情需要注意。首先,drop命令和大多数其他git stash命令一样,可以使用可选的stash@{n}名称。如果不提供,Git 假设stash@{0}。
另一件有趣的事情是,drop 命令的输出为您提供了阿沙。像 Git 中的其他 sha 一样,您可以利用这一点。例如,如果您真的想要在上面的stash@{1}上执行pop而不是drop,您可以使用它显示给您的那个 SHA 创建一个新的分支(9aaa9996):
$ git branch tmp 9aaa9996
$ git status
On branch master
nothing to commit, working directory clean
$ # use git log <branchname> to see commits on that branch
$ git log tmp
commit 9aaa9996bd6aa363e7be723b4712afaae4fc3235
Merge: b3e9b4d f2d6ecc
Author: Jim Anderson <your_email_here@gmail.com>
Date: Sat May 12 09:34:29 2018 -0600
On master: the first save
[rest of log deleted for brevity]
一旦您有了那个分支,您就可以使用git merge或其他技术将那些变更返回到您的分支。如果您没有从git drop命令中保存 SHA,有其他方法可以尝试恢复更改,但是它们会变得复杂。你可以在这里了解更多关于的信息。
git stash举例:拉进一棵脏兮兮的树
让我们通过查看它的一个最初对我来说并不明显的用途来结束这一节。通常,当你在一个共享分支上工作很长一段时间时,另一个开发人员会将变更推送到你想在本地回购中得到的分支上。您会记得我们使用了git pull命令来做这件事。但是,如果您在文件中有本地更改,而 pull 将修改这些更改,Git 会拒绝,并显示一条错误消息,解释发生了什么错误:
error: Your local changes to the following files would be overwritten by merge:
<list of files that conflict>
Please, commit your changes or stash them before you can merge.
Aborting
您可以提交它,然后执行pull,但是这会创建一个合并节点,并且您可能还没有准备好提交这些文件。现在你知道了git stash,你可以用它来代替:
$ git stash
Saved working directory and index state WIP on master: b25fe34 Cleaned up when no TOKEN is present. Added ignored tasks
HEAD is now at <SHA> <commit message>
$ git pull
Updating <SHA1>..<SHA2>
Fast-forward
<more info here>
$ git stash pop
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
<rest of stash pop output trimmed>
执行git stash pop命令完全有可能会产生合并冲突。如果是这种情况,您需要手动编辑冲突来解决它,然后您可以继续。我们将在下面讨论解决合并冲突。
比较修订:git diff
git diff命令是一个强大的特性,您会发现自己经常使用它。我查找了它可以比较的事物列表,并对列表感到惊讶。如果你想自己看,试着输入git diff --help。我不会在这里涵盖所有这些用例,因为它们中的许多并不常见。
本节有几个关于diff命令的用例,显示在命令行上。下一节将展示如何设置 Git 来使用可视化比较工具,比如 Meld、Windiff、BeyondCompare,甚至是 IDE 中的扩展。diff和difftool的选项是相同的,所以本节中的大部分讨论也适用于此,但是在命令行版本中显示输出更容易。
git diff最常见的用途是查看您在工作目录中修改了什么:
$ echo "I'm editing file3 now" >> file3
$ git diff
diff --git a/file3 b/file3
index faf2282..c5dd702 100644
--- a/file3
+++ b/file3
@@ -1,3 +1,4 @@
{other contents of files3}
+I'm editing file3 now
如您所见,diff在命令行上以“补丁”的格式向您展示了不同之处。一旦你完成了这个格式,你可以看到,+字符表明一行已经被添加到了文件中,正如你所期望的,行I'm editing file3 now被添加到了file3。
git diff的默认选项是向您显示您的工作目录中有哪些变化是而不是在您的索引或 HEAD 中。如果您将上述更改添加到索引中,然后执行 diff,它会显示没有差异:
$ git add file3
$ git diff
[no output here]
我发现这让我困惑了一段时间,但我渐渐喜欢上了它。要查看索引中的更改并为下一次提交准备,请使用--staged选项:
$ git diff --staged
diff --git a/file3 b/file3
index faf2282..c5dd702 100644
--- a/file3
+++ b/file3
@@ -1,3 +1,4 @@
file1
file2
file3
+I'm editing file3 now
git diff命令也可以用来比较 repo 中的任意两个提交。这可以向您展示两个 sha 之间的变化:
$ git diff b3e9b4d 387dcfc
diff --git a/file3 b/file3
deleted file mode 100644
index faf2282..0000000
--- a/file3
+++ /dev/null
@@ -1,3 +0,0 @@
-file1
-file2
-file3
您还可以使用分支名称来查看一个分支和另一个分支之间的全部更改:
$ git diff master tmp
diff --git a/file1 b/file1
index e212970..04dbd7b 100644
--- a/file1
+++ b/file1
@@ -1 +1,2 @@
file1
+editing file1
您甚至可以使用我们在上面看到的版本命名方法的任意组合:
$ git diff master^ master
diff --git a/file3 b/file3
new file mode 100644
index 0000000..faf2282
--- /dev/null
+++ b/file3
@@ -0,0 +1,3 @@
+file1
+file2
+file3
当您比较两个分支时,它会显示两个分支之间的所有变化。通常,您只想查看单个文件的差异。您可以通过在一个--(两个负号)选项后列出文件来将输出限制为一个文件:
$ git diff HEAD~3 HEAD
diff --git a/file1 b/file1
index e212970..04dbd7b 100644
--- a/file1
+++ b/file1
@@ -1 +1,2 @@
file1
+editing file1
diff --git a/file2 b/file2
index 89361a0..91c5d97 100644
--- a/file2
+++ b/file2
@@ -1,2 +1,3 @@
file1
file2
+editing file2
diff --git a/file3 b/file3
index faf2282..c5dd702 100644
--- a/file3
+++ b/file3
@@ -1,3 +1,4 @@
file1
file2
file3
+I'm editing file3 now
$ git diff HEAD~3 HEAD -- file3
diff --git a/file3 b/file3
index faf2282..c5dd702 100644
--- a/file3
+++ b/file3
@@ -1,3 +1,4 @@
file1
file2
file3
+I'm editing file3 now
git diff有很多很多选项,我不会一一列举,但是我想探索另一个我经常使用的用例,显示在提交中被更改的文件。
在您当前的回购中,master上的最近提交向file1添加了一行文本。通过比较HEAD和HEAD^你可以看到:
$ git diff HEAD^ HEAD
diff --git a/file1 b/file1
index e212970..04dbd7b 100644
--- a/file1
+++ b/file1
@@ -1 +1,2 @@
file1
+editing file1
对于这个小例子来说这没什么,但是提交的差异通常会有几页长,而且提取文件名会变得非常困难。当然,Git 有一个选项可以帮助解决这个问题:
$ git diff HEAD^ HEAD --name-only
file1
--name-only选项将显示两次提交之间更改的文件名列表,但不显示这些文件中更改的内容。
正如我上面所说的,git diff命令覆盖了的许多选项和用例,这里你只是触及了表面。一旦你弄清楚了上面列出的命令,我鼓励你看看git diff --help,看看你还能找到什么技巧。我肯定学到了新的东西准备这个教程!
git difftool
Git 有一种机制,可以使用可视化的 diff 工具来显示差异,而不仅仅是使用我们目前看到的命令行格式。你用git diff看到的所有选项和功能在这里仍然有效,但是它将在一个单独的窗口中显示不同之处,包括我在内的许多人都觉得这样更容易阅读。对于这个例子,我将使用meld作为 diff 工具,因为它可以在 Windows、Mac 和 Linux 上使用。
如果设置得当,Difftool 更容易使用。Git 有一组配置选项来控制difftool的默认值。您可以使用git config命令在 shell 中设置这些:
$ git config --global diff.tool meld
$ git config --global difftool.prompt false
我认为prompt选项很重要。如果不指定,Git 会在每次启动外部构建工具之前提示您。这可能很烦人,因为它对 diff 中的每个文件都是这样,一次一个:
$ git difftool HEAD^ HEAD
Viewing (1/1): 'python-git-intro/new_section.md'
Launch 'meld' [Y/n]: y
将prompt设置为 false 会强制 Git 在没有询问的情况下启动该工具,从而加快您的进程并使您变得更好!
在上面的diff讨论中,您已经介绍了difftool的大部分特性,但是我想补充一点,这是我在为本文进行研究时学到的。你还记得上面你在看git stash show命令的时候吗?我提到有一种方法可以直观地看到给定的储藏中有什么,而difftool就是这种方法。我们学习的所有用于寻址堆栈的语法都适用于 difftool:
$ git difftool stash@{1}
与所有的stash子命令一样,如果您只想查看最新的存储,您可以使用stash快捷键:
$ git difftool stash
许多 ide 和编辑器都有可以帮助查看差异的工具。在 Git 教程的介绍的最后有一个特定于编辑器的教程列表。
改变历史
Git 的一个让一些人害怕的特性是它有能力改变提交。虽然我能理解他们的担心,但这是工具的一部分,而且,像任何强大的工具一样,如果你不明智地使用它,你可能会带来麻烦。
我们将讨论修改提交的几种方法,但是在此之前,让我们讨论一下什么时候这样做是合适的。在前面几节中,您已经看到了本地回购和远程回购之间的区别。您已创建但尚未推送的提交仅位于您的本地回购中。其他开发人员已经推送但您没有拉取的提交仅在远程回购中。执行push或pull会将这些提交放入两个回购中。
你应该考虑修改提交的唯一时间是当它存在于你的本地存储库中而不是远程存储库中的时候。如果您修改已经从远程推送的提交,您很可能很难从远程推送或拉取,如果您成功了,您的同事会不高兴。
除此之外,让我们来谈谈如何修改提交和改变历史!
git commit --amend
如果您刚刚提交了一个请求,但是在运行时发现flake8有错误,您会怎么做?或者您在刚刚输入的提交消息中发现了一个打字错误?Git 将允许您“修改”提交:
$ git commit -m "I am bad at spilling"
[master 63f74b7] I am bad at spilling
1 file changed, 4 insertions(+)
$ git commit --amend -m "I am bad at spelling"
[master 951bf2f] I am bad at spelling
Date: Tue May 22 20:41:27 2018 -0600
1 file changed, 4 insertions(+)
现在,如果您查看修改后的日志,您会看到只有一次提交,并且它具有正确的消息:
$ git log
commit 951bf2f45957079f305e8a039dea1771e14b503c
Author: Jim Anderson <your_email_here@gmail.com>
Date: Tue May 22 20:41:27 2018 -0600
I am bad at spelling
commit c789957055bd81dd57c09f5329c448112c1398d8
Author: Jim Anderson <your_email_here@gmail.com>
Date: Tue May 22 20:39:17 2018 -0600
new message
[rest of log deleted]
如果您在修改之前修改并添加了文件,这些文件也会包含在单次提交中。您可以看到这是一个修复错误的便捷工具。我将再次警告您,执行commit --amend会修改提交。如果原始提交被推送到远程回购,其他人可能已经基于它进行了更改。那会很混乱,所以只对本地的提交使用它。
git rebase
一个rebase操作类似于一个合并,但是它可以产生一个更清晰的历史。当你重定基础时,Git 会在你当前的分支和指定的分支之间找到共同的祖先。然后,它将从您的分支中获取该共同祖先之后的所有更改,并在另一个分支上“重放”它们。结果看起来就像你在另一个分支之后做了所有的修改。
这可能有点难以想象,所以让我们看一些实际的提交。在这个练习中,我将使用git log命令中的--oneline选项来减少混乱。让我们从你一直在做的一个叫做my_feature_branch的特性分支开始。这是该分支的状态:
$ git log --oneline
143ae7f second feature commit
aef68dc first feature commit
2512d27 Common Ancestor Commit
如您所料,您可以看到,--oneline选项只显示了 SHA 和每次提交的提交消息。在标记为2512d27 Common Ancestor Commit的提交之后,您的分支有两个提交。
如果你打算重定基数,你需要第二个分支,而master似乎是个不错的选择。下面是master分支的当前状态:
$ git log --oneline master
23a558c third master commit
5ec06af second master commit
190d6af first master commit
2512d27 Common Ancestor Commit
在2512d27 Common Ancestor Commit之后的master有三次提交。当您仍然签出my_feature_branch时,您可以执行rebase来将两个特性提交放在主服务器上的三个提交之后:
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: first feature commit
Applying: second feature commit
$ git log --oneline
cf16517 second feature commit
69f61e9 first feature commit
23a558c third master commit
5ec06af second master commit
190d6af first master commit
2512d27 Common Ancestor Commit
在这个日志列表中有两件事需要注意:
1)正如所宣传的,两个特性提交在三个主提交之后。
2)这两个功能提交的 sha 已经更改。
sha 是不同的,因为回购略有不同。提交表示对文件的相同更改,但是因为它们被添加到已经在master中的更改之上,所以回购的状态是不同的,所以它们具有不同的 sha。
如果你做了一个merge而不是一个rebase,将会有一个新的提交和消息Merge branch 'master' into my_feature_branch,并且两个特性提交的 sha 将保持不变。做一个 rebase 可以避免额外的合并提交,使你的修订历史更加清晰。
git pull -r
当您与不同的开发人员一起处理一个分支时,使用 rebase 也是一个方便的工具。如果远程上有更改,并且您有对同一个分支的本地提交,那么您可以在git pull命令上使用-r选项。当一个普通的git pull对远程分支做一个merge时,git pull -r会在远程分支上的变更的基础上重新调整你的提交。
git rebase -i
rebase 命令有另一种操作方法。有一个-i标志可以添加到rebase命令中,使其进入交互模式。虽然这乍一看似乎令人困惑,但它是一个非常强大的特性,让您在将提交推送到远程之前完全控制提交列表。请记住关于不要更改已提交的提交历史的警告。
这些例子展示了一个基本的交互式 rebase,但是要注意还有更多的选项和用例。git rebase --help命令会给你一个列表,并且很好地解释了它们。
对于这个例子,您将会想象您一直在使用您的 Python 库,在您实现一个解决方案、测试它、发现一个问题并修复它时,多次提交到您的本地 repo。在这个过程的最后,你有一个本地回购上的提交链,所有这些都是新特性的一部分。一旦你完成了工作,你看着你的git log:
$ git log --oneline
8bb7af8 implemented feedback from code review
504d520 added unit test to cover new bug
56d1c23 more flake8 clean up
d9b1f9e restructuring to clean up
08dc922 another bug fix
7f82500 pylint cleanup
a113f67 found a bug fixing
3b8a6f2 First attempt at solution
af21a53 [older stuff here]
这里有几个提交并没有给其他开发人员甚至是未来的你增加价值。您可以使用rebase -i创建一个“挤压提交”,并将所有这些放入历史中的一个点。
要开始这个过程,您可以运行git rebase -i af21a53,这将显示一个编辑器,其中有一个提交列表和一些指令:
pick 3b8a6f2 First attempt at solution
pick a113f67 found a bug fixing
pick 7f82500 pylint cleanup
pick 08dc922 another bug fix
pick d9b1f9e restructuring to clean up
pick 56d1c23 more flake8 clean up
pick 504d520 added unit test to cover new bug
pick 8bb7af8 implemented feedback from code review
# Rebase af21a53..8bb7af8 onto af21a53 (8 command(s))
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
# d, drop = remove commit
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented out
您会注意到提交是以相反的顺序列出的,最早的放在最前面。这是 Git 在af21a53之上重放提交的顺序。如果您只是在此时保存文件,什么都不会改变。如果删除所有文本并保存文件,也是如此。
此外,有几行以#开头,提醒您如何编辑这个文件。这些评论可以删除,但不是必须删除。
但是您希望将所有这些提交压缩成一个,以便“未来的您”知道这是完全添加了该特性的提交。为此,您可以编辑该文件,如下所示:
pick 3b8a6f2 First attempt at solution
squash a113f67 found a bug fixing
s 7f82500 pylint cleanup
s 08dc922 another bug fix
s d9b1f9e restructuring to clean up
s 56d1c23 more flake8 clean up
s 504d520 added unit test to cover new bug
s 8bb7af8 implemented feedback from code review
您可以使用命令的完整单词,或者像您在前两行之后所做的那样,使用单字符版本。上面的示例选择“挑选”最早的提交,并将每个后续提交“挤压”到那个提交中。如果您保存并退出编辑器,Git 将继续将所有这些提交放入一个编辑器中,然后再次打开编辑器,列出被压缩的提交的所有提交消息:
# This is a combination of 8 commits.
# The first commit's message is:
Implemented feature ABC
# This is the 2nd commit message:
found a bug fixing
# This is the 3rd commit message:
pylint cleanup
# This is the 4th commit message:
another bug fix
[the rest trimmed for brevity]
默认情况下,挤压提交会有一个很长的提交消息,包含每次提交的所有消息。在你的情况下,最好改写第一条信息,删除其余的。这样做并保存文件将完成该过程,您的日志现在将只有一个针对该特性的提交:
$ git log --oneline
9a325ad Implemented feature ABC
af21a53 [older stuff here]
酷!你只是隐藏了任何证据,表明你不得不做一个以上的承诺来解决这个问题。干得好!请注意,决定何时进行挤压合并通常比实际过程更困难。有一篇很棒的文章很好地展示了复杂性。
正如你可能猜到的,git rebase -i将允许你做更复杂的操作。让我们再看一个例子。
在一周的时间里,你处理了三个不同的问题,在不同的时间对每个问题进行了修改。还有一个承诺,你会后悔,会假装从未发生过。这是你的起始日志:
$ git log --oneline
2f0a106 feature 3 commit 3
f0e14d2 feature 2 commit 3
b2eec2c feature 1 commit 3
d6afbee really rotten, very bad commit
6219ba3 feature 3 commit 2
70e07b8 feature 2 commit 2
c08bf37 feature 1 commit 2
c9747ae feature 3 commit 1
fdf23fc feature 2 commit 1
0f05458 feature 1 commit 1
3ca2262 older stuff here
你的任务是把它分成三个干净的提交,并去掉一个坏的。您可以遵循相同的过程,git rebase -i 3ca2262,Git 会向您显示命令文件:
pick 0f05458 feature 1 commit 1
pick fdf23fc feature 2 commit 1
pick c9747ae feature 3 commit 1
pick c08bf37 feature 1 commit 2
pick 70e07b8 feature 2 commit 2
pick 6219ba3 feature 3 commit 2
pick d6afbee really rotten, very bad commit
pick b2eec2c feature 1 commit 3
pick f0e14d2 feature 2 commit 3
pick 2f0a106 feature 3 commit 3
交互式 rebase 不仅允许您指定每次提交要做什么,还允许您重新安排它们。因此,为了得到您的三次提交,您可以编辑该文件,如下所示:
pick 0f05458 feature 1 commit 1
s c08bf37 feature 1 commit 2
s b2eec2c feature 1 commit 3
pick fdf23fc feature 2 commit 1
s 70e07b8 feature 2 commit 2
s f0e14d2 feature 2 commit 3
pick c9747ae feature 3 commit 1
s 6219ba3 feature 3 commit 2
s 2f0a106 feature 3 commit 3
# pick d6afbee really rotten, very bad commit
每个特性的提交被分组在一起,其中只有一个被“挑选”,其余的被“挤压”注释掉错误的提交将会删除它,但是您也可以很容易地从文件中删除这一行来达到相同的效果。
当您保存该文件时,您将获得一个单独的编辑器会话,为三个被压缩的提交中的每一个创建提交消息。如果您将它们称为feature 1、feature 2和feature 3,您的日志现在将只有这三个提交,每个特性一个:
$ git log --oneline
f700f1f feature 3
443272f feature 2
0ff80ca feature 1
3ca2262 older stuff here
就像任何重新定基或合并一样,您可能会在这个过程中遇到冲突,您需要通过编辑文件、纠正更改、git add -ing 文件并运行git rebase --continue来解决这些冲突。
我将通过指出关于 rebase 的一些事情来结束这一部分:
1)创建挤压提交是一个“很好”的特性,但是不使用它也可以成功地使用 Git。
2)大型交互式 rebases 上的合并冲突可能会令人困惑。没有一个步骤是困难的,但是可以有很多
3)我们只是简单介绍了您可以用git rebase -i做些什么。这里有比大多数人发现的更多的功能。
git revertvsgit reset:清理
不足为奇的是,Git 为你提供了几种清理混乱的方法。这些技巧取决于你的回购处于何种状态,以及混乱是发生在你的回购上还是被推到了远处。
让我们从简单的例子开始。您做出了不想要的提交,并且它还没有被推到远程。从创建提交开始,这样你就知道你在看什么了:
$ ls >> file_i_do_not_want
$ git add file_i_do_not_want
$ git commit -m "bad commit"
[master baebe14] bad commit
2 files changed, 31 insertions(+)
create mode 100644 file_i_do_not_want
$ git log --oneline
baebe14 bad commit
443272f feature 2
0ff80ca feature 1
3ca2262 older stuff here
上面的示例创建了一个新文件file_i_do_not_want,并将其提交给本地 repo。它尚未被推送到远程回购。本节中的其余示例将以此为起点。
要管理仅在本地 repo 上的提交,可以使用git reset命令。有两个选项可以探索:--soft和--hard。
git reset --soft <SHA>命令告诉 Git 将磁头移回指定的 SHA。它不会改变本地文件系统,也不会改变索引。我承认当我读到这个描述的时候,它对我来说没有什么意义,但是看看这个例子绝对有帮助:
$ git reset --soft HEAD^
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: file_i_do_not_want
$ git log --oneline
443272f feature 2
0ff80ca feature 1
3ca2262 older stuff here
在示例中,我们将HEAD重置为HEAD^。记住^告诉 Git 退回一次提交。--soft选项告诉 Git而不是更改索引或本地文件系统,所以file_i_do_not_want仍然在索引中处于“Changes to commit:”状态。然而,git log命令显示bad commit已从历史中删除。
这就是--soft选项的作用。现在我们来看一下--hard选项。让我们回到原来的状态,让bad commit再次参与回购,并尝试--hard:
$ git log --oneline
2e9d704 bad commit
443272f feature 2
0ff80ca feature 1
3ca2262 older stuff here
$ git reset --hard HEAD^
HEAD is now at 443272f feature 2
$ git status
On branch master
nothing to commit, working directory clean
$ git log --oneline
443272f feature 2
0ff80ca feature 1
3ca2262 older stuff here
这里有几点需要注意。首先,reset命令实际上在--hard选项上给了你反馈,而在--soft上却没有。老实说,我不知道这是为什么。此外,当我们之后执行git status和git log时,您会看到不仅bad commit消失了,而且提交中的更改也被清除了。--hard选项将您完全重置回您指定的 SHA。
现在,如果您还记得关于在 Git 中更改历史的最后一节,您会发现对已经推送到远程的分支进行重置可能是个坏主意。它改变了历史,这真的会让你的同事感到困惑。
当然,Git 有一个解决方案。git revert命令允许您轻松地从给定的提交中删除更改,但不会更改历史。它通过执行与您指定的提交相反的操作来实现这一点。如果您在文件中添加了一行,git revert将从文件中删除该行。它会这样做,并自动为您创建一个新的“恢复提交”。
再次将回购重置回最近一次提交的时间点bad commit。首先确认bad commit有什么变化:
$ git diff HEAD^
diff --git a/file_i_do_not_want b/file_i_do_not_want
new file mode 100644
index 0000000..6fe5391
--- /dev/null
+++ b/file_i_do_not_want
@@ -0,0 +1,6 @@
+file1
+file2
+file3
+file4
+file_i_do_not_want
+growing_file
您可以看到,我们只是将新的file_i_do_not_want添加到了回购中。@@ -0,0 +1,6 @@下面的行是新文件的内容。现在,假设这次你已经把那个bad commit推到了主人面前,你不想让你的同事讨厌你,使用 revert 来修复这个错误:
$ git revert HEAD
[master 8a53ee4] Revert "bad commit"
1 file changed, 6 deletions(-)
delete mode 100644 file_i_do_not_want
当您运行该命令时,Git 将弹出一个编辑器窗口,允许您修改 revert commit 的提交消息:
Revert "bad commit"
This reverts commit 1fec3f78f7aea20bf99c124e5b75f8cec319de10.
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# On branch master
# Changes to be committed:
# deleted: file_i_do_not_want
#
与commit不同,git revert没有在命令行上指定提交消息的选项。您可以使用-n跳过消息编辑步骤,告诉 Git 简单地使用默认消息。
在我们恢复错误的提交后,我们的日志显示一个新的提交,并显示以下消息:
$ git log --oneline
8a53ee4 Revert "bad commit"
1fec3f7 bad commit
443272f feature 2
0ff80ca feature 1
3ca2262 older stuff here
“错误提交”仍然存在。它需要在那里,因为你不想在这种情况下改变历史。然而,有一个新的提交,它“撤销”了该提交中的更改。
git clean
我发现另一个“清理”命令很有用,但是我想提出一个警告。
**注意:**使用git clean可以清除未提交给回购的文件,您将无法恢复这些文件。
如你所料:它会清理你的本地工作目录。我发现当一些大的错误发生,并且我的文件系统上有几个我不想要的文件时,这非常有用。
在其简单的形式中,git clean简单地删除不在“版本控制之下”的文件这意味着当你查看git status时,出现在Untracked files部分的文件将从工作树中移除。如果您不小心这样做了,没有办法恢复,因为那些文件不在版本控制中。
这很方便,但是如果您想删除使用 Python 模块创建的所有pyc文件,该怎么办呢?这些都在你的.gitignore文件中,所以它们不会显示为未被追踪,也不会被git clean删除。
-x选项告诉git clean删除未被跟踪和忽略的文件,所以git clean -x会处理这个问题。差不多了。
Git 对clean命令有点保守,除非你告诉它这样做,否则不会删除未被跟踪的目录。Python 3 喜欢创建__pycache__目录,清理这些目录也很好。要解决这个问题,您可以添加-d选项。git clean -xd将清理所有未被跟踪和忽略的文件和目录。
现在,如果你已经测试过了,你会发现它实际上并不工作。还记得我在本节开始时给出的警告吗?Git 在删除无法恢复的文件时会尽量谨慎。因此,如果您尝试上面的命令,您会看到一条错误消息:
$ git clean -xd
fatal: clean.requireForce defaults to true and neither -i, -n, nor -f given; refusing to clean
虽然可以将 git 配置文件改为不需要它,但我交谈过的大多数人都习惯于将-f选项和其他选项一起使用:
$ git clean -xfd
Removing file_to_delete
再次警告,git clean -xfd将删除您无法恢复的文件,因此请谨慎使用!
解决合并冲突
当您刚接触 Git 时,合并冲突似乎是一件可怕的事情,但是通过一些实践和技巧,它们可以变得更容易处理。
让我们从一些可以使这变得更容易的技巧开始。第一个改变了冲突显示的格式。
diff3格式
我们将通过一个简单的例子来了解 Git 在默认情况下做什么,以及我们有哪些选项可以使它变得更简单。为此,创建一个新文件merge.py,如下所示:
def display():
print("Welcome to my project!")
将这个文件添加并提交到您的分支master,这将是您的基线提交。您将创建以不同方式修改该文件的分支,然后您将看到如何解决合并冲突。
您现在需要创建具有冲突变更的独立分支。您已经看到了这是如何实现的,所以我就不详细描述了:
$ git checkout -b mergebranch
Switched to a new branch 'mergebranch'
$ vi merge.py # edit file to change 'project' to 'program'
$ git add merge.py
$ git commit -m "change project to program"
[mergebranch a775c38] change project to program
1 file changed, 1 insertion(+), 1 deletion(-)
$ git status
On branch mergebranch
nothing to commit, working directory clean
$ git checkout master
Switched to branch 'master'
$ vi merge.py # edit file to add 'very cool' before project
$ git add merge.py
$ git commit -m "added description of project"
[master ab41ed2] added description of project
1 file changed, 1 insertion(+), 1 deletion(-)
$ git show-branch master mergebranch
* [master] added description of project
! [mergebranch] change project to program
--
* [master] added description of project
+ [mergebranch] change project to program
*+ [master^] baseline for merging
此时,您在mergebranch和master上有冲突的变更。使用我们在介绍教程中学到的show-branch命令,您可以在命令行上直观地看到这一点:
$ git show-branch master mergebranch
* [master] added description of project
! [mergebranch] change project to program
--
* [master] added description of project
+ [mergebranch] change project to program
*+ [master^] baseline for merging
你在分支master上,所以让我们试着在mergebranch中合并。既然您已经做了更改,并打算创建一个合并冲突,让我们希望这种情况发生:
$ git merge mergebranch
Auto-merging merge.py
CONFLICT (content): Merge conflict in merge.py
Automatic merge failed; fix conflicts and then commit the result.
正如您所料,存在合并冲突。如果你看看状态,那里有很多有用的信息。它不仅显示您正在进行合并,You have unmerged paths,还显示您修改了哪些文件,merge.py:
$ git status
On branch master
You have unmerged paths.
(fix conflicts and run "git commit")
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: merge.py
no changes added to commit (use "git add" and/or "git commit -a")
你已经做了所有的工作,得到了一个合并冲突的点。现在你可以开始学习如何解决它了!在第一部分中,您将使用命令行工具和编辑器。在那之后,您将会发现使用 visual diff 工具来解决这个问题。
当您在编辑器中打开merge.py时,您可以看到 Git 产生了什么:
def display():
<<<<<<< HEAD
print("Welcome to my very cool project!")
=======
print("Welcome to my program!")
>>>>>>> mergebranch
Git 使用 Linux 中的diff语法来显示冲突。顶端部分,在<<<<<<< HEAD和=======之间,来自头部,在你的例子中是master。最下面的部分,在=======和>>>>>>> mergebranch之间,你猜对了,是来自mergebranch。
现在,在这个非常简单的例子中,很容易记住哪些更改来自哪里以及我们应该如何合并它,但是有一个设置可以使这变得更容易。
diff3设置将合并冲突的输出修改为更接近三路合并,这意味着在这种情况下,它将向您显示master中的内容,然后是它在共同祖先中的样子,最后是它在mergebranch中的样子:
def display():
<<<<<<< HEAD
print("Welcome to my very cool project!")
||||||| merged common ancestors
print("Welcome to my project!")
=======
print("Welcome to my program!")
>>>>>>> mergebranch
现在你可以看到起点了,“欢迎来到我的项目!”,您可以确切地看到在master上做了什么更改,在mergebranch上做了什么更改。对于这样一个简单的例子来说,这似乎没什么大不了的,但是对于大的冲突来说,尤其是在别人做了一些更改的合并中,这可能会产生巨大的影响。
您可以通过发出以下命令在 Git 中全局设置该选项:
$ git config --global merge.conflictstyle diff3
好了,你知道如何看待冲突了。让我们来看看如何修复它。首先编辑文件,删除 Git 添加的所有标记,并更正冲突的一行:
def display():
print("Welcome to my very cool program!")
然后,将修改后的文件添加到索引中,并提交合并。这将完成合并过程并创建新节点:
$ git add merge.py
$ git commit
[master a56a01e] Merge branch 'mergebranch'
$ git log --oneline
a56a01e Merge branch 'mergebranch'
ab41ed2 added description of project
a775c38 change project to program
f29b775 baseline for merging
合并冲突也可能在你挑选的时候发生。摘樱桃的过程略有不同。不使用git commit命令,而是使用git cherry-pick --continue命令。别担心,Git 会在状态消息中告诉你需要使用哪个命令。你可以随时回去检查,以确保这一点。
git mergetool
与git difftool类似,Git 将允许您配置一个可视化比较工具来处理三向合并。它知道不同操作系统上的几种不同的工具。您可以使用下面的命令查看它知道的您系统上的工具列表。在我的 Linux 机器上,它显示以下内容:
$ git mergetool --tool-help
'git mergetool --tool=<tool>' may be set to one of the following:
araxis
gvimdiff
gvimdiff2
gvimdiff3
meld
vimdiff
vimdiff2
vimdiff3
The following tools are valid, but not currently available:
bc
bc3
codecompare
deltawalker
diffmerge
diffuse
ecmerge
emerge
kdiff3
opendiff
p4merge
tkdiff
tortoisemerge
winmerge
xxdiff
Some of the tools listed above only work in a windowed
environment. If run in a terminal-only session, they will fail.
同样与difftool类似,您可以全局配置mergetool选项以使其更易于使用:
$ git config --global merge.tool meld
$ git config --global mergetool.prompt false
最后一个选项mergetool.prompt,告诉 Git 不要在每次打开窗口时都提示您。这听起来可能不烦人,但是当你的合并涉及到几个文件时,它会在每个文件之间提示你。
结论
您已经在这些教程中涉及了很多内容,但是还有很多内容需要学习。如果您想更深入地了解 Git,我可以推荐这些资源:
- 免费的在线工具是一个非常方便的参考。
- 对于那些喜欢在纸上阅读的人来说,有一个印刷版本的 Pro Git ,我发现奥赖利的版本控制与 Git 在我阅读时很有用。
--help对你知道的任何子命令都有用。git diff --help产生近 1000 行信息。虽然其中的一些内容非常详细,并且其中一些假设您对 Git 有很深的了解,但是阅读您经常使用的命令的帮助可以教会您如何使用它们的新技巧。*********
Python 开发人员的高级 Visual Studio 代码
原文:https://realpython.com/advanced-visual-studio-code-python/
Visual Studio Code,简称 VS Code ,是微软免费开放的源代码编辑器。可以将 VS 代码作为轻量级代码编辑器进行快速修改,也可以通过使用第三方扩展将其配置为集成开发环境(IDE) 。在本教程中,您将了解如何在 Python 开发中充分利用 VS 代码。
在本教程中,您将学习如何配置、扩展和优化 VS 代码,以获得更高效的 Python 开发环境。完成本教程后,您将拥有多种工具来帮助您更高效地使用 VS 代码。它可以成为快速 Python 开发的强大工具。
在本教程中,您将学习如何:
- 定制您的用户界面
- 运行并监控 Python 测试
- 皮棉和自动格式化你的代码
- 利用类型注释和通孔以更高的准确性更快地编写代码
- 配置和利用本地和远程调试
- 设置数据科学工具
像往常一样,本教程充满了链接、提示和技巧,以帮助您上路。
如果你还没有安装 Visual Studio 代码或者 Python 扩展,那么在本教程中你需要这两个。如果你刚刚开始学习 VS 代码,在继续学习这篇之前,你可能想看看 Jon Fincher 关于用 Visual Studio 代码开发 Python 的教程。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
掌握 Visual Studio 代码用户界面
默认情况下,VS Code 的用户界面是为所有人设计的——无论你是在编写 C++,用 JavaScript 和 CSS 做前端开发,还是使用 Jupyter 笔记本这样的数据科学工具。在第一部分中,您将探索如何定制 VS 代码来支持您的工作方式。
键盘快捷键
几乎所有你在 VS 代码中做的事情,你都可以直接从键盘上完成。您可以将 VS 代码中的所有活动映射到一个键盘快捷键,无论它们是内置的还是通过扩展提供的。
一小部分内置命令已经映射在键盘快捷键中。如果你想学习这些默认快捷键,打印出适用于 Windows 、 macOS 或 Linux 的 PDF 文件,并把它钉在你的显示器旁边。
作为 Python 开发人员,您将在 Visual Studio 代码中使用的许多命令都是由扩展提供的,类似于您已经安装的 Python 扩展。这些没有默认映射的快捷键,但是你可以使用 VS Code 的键盘快捷键编辑器来配置它们。
使用键盘快捷键编辑器
在 macOS 上,进入文件→首选项→键盘快捷键或代码→首选项→键盘快捷键,打开键盘快捷键编辑器:
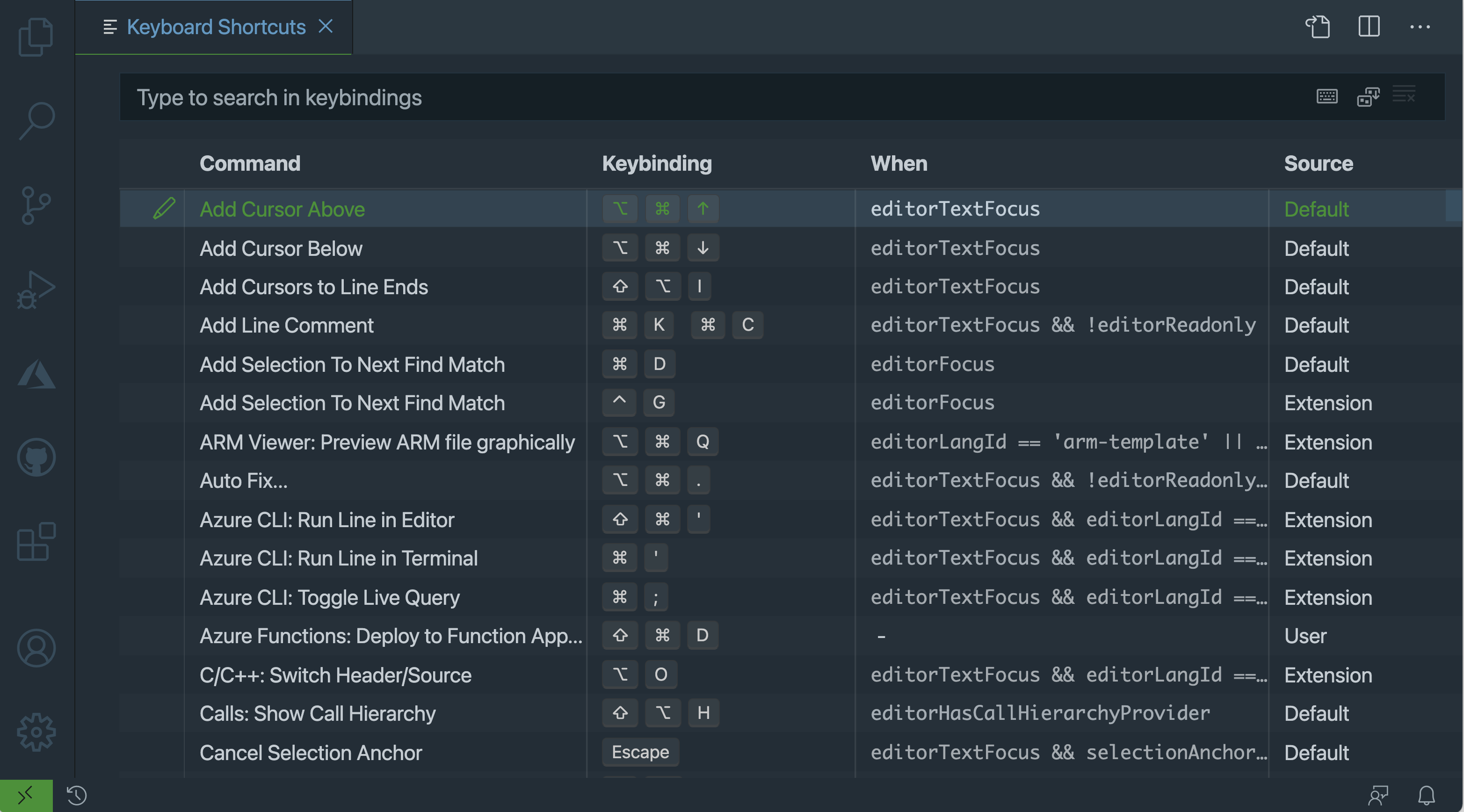
在此编辑器中,您可以看到所有现有快捷方式的列表及其详细信息:
- 命令:要运行的命令或动作
- 组合键:触发该命令的按键顺序,空白表示没有映射
- When :该键绑定工作需要满足的条件,减号(
-)表示没有要求 - Source :这个绑定被配置的地方,要么由默认、用户定义,要么由扩展定义,最后一个表示你是通过安装一个键映射扩展提供的
要覆盖现有的绑定,右键单击现有的动作,然后单击 Change Keybinding 。要将 keybinding 分配给没有绑定的命令,请双击它。如果你按下的键序列已经被分配给其他的东西,VS Code 会警告你一个链接,看看哪些命令被映射到这个 keybinding。
例如,在顶部的搜索框中键入python create terminal。如果没有结果,请确保安装了 Python 扩展。按 Enter 分配一个键位绑定,像Ctrl+Alt+T,然后再按 Enter 。
要指定该快捷方式仅在编辑 Python 代码时工作,右键单击该快捷方式并选择当表达式改变时。输入表达式editorLangId == 'python':
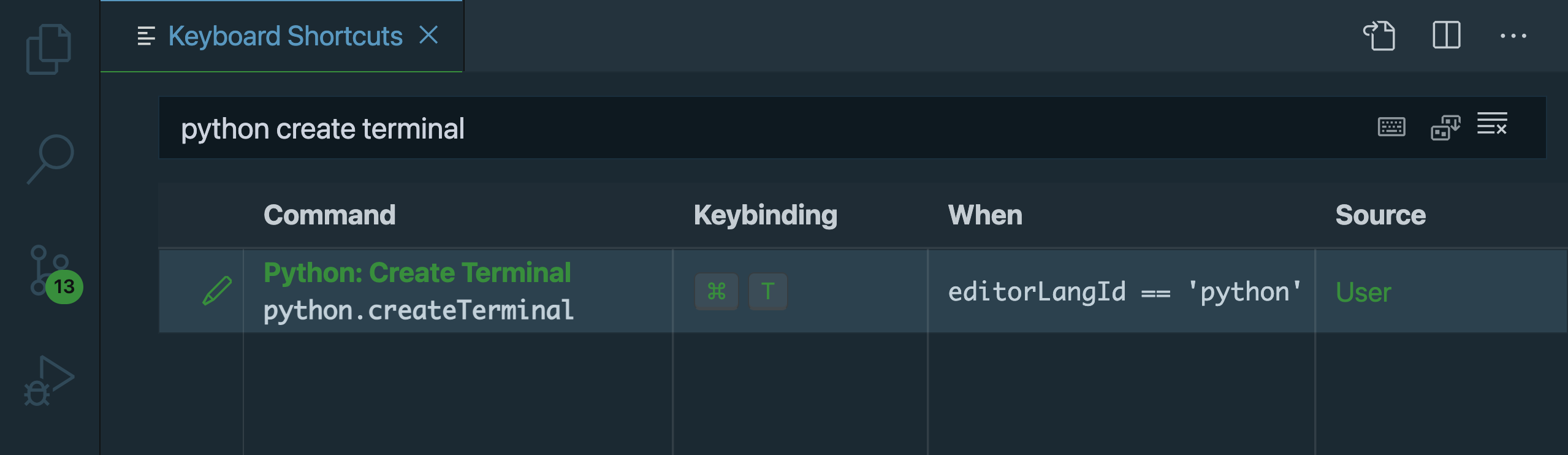
如果你需要更具体的东西,有更多的条件操作符可以选择。以下是一些帮助您入门的示例:
- 当您正在编辑的文件是
__init__.py时,使用resourceFilename == '__init__.py' - 使用 Python 时使用
editorLangId == 'python'。如果需要,您也可以用另一个语言标识符替换'python'。 - 当你在编辑器里面的时候,使用
editorHasSelection。
一旦你配置了这个扩展,在编辑器中打开一个 Python 文件,按下你新分配的键盘快捷键Ctrl+Alt+T打开一个 Python 终端。
从命令调板设置命令的键盘快捷键
在本教程中,你会多次引用命令面板。VS 代码中的大多数功能都可以通过 UI 从上下文菜单中访问,但是你不会在那里找到所有的东西。可以在核心编辑器中或通过扩展完成的任何事情都可以在命令面板中找到。您可以通过按以下键盘快捷键之一进入命令调板:
- macOS:
F1或Cmd+Shift+P - Windows 或 Linux:
F1或Ctrl+Shift+P
要运行命令,请键入其描述性名称,如Python: Run All Tests。命令调板打开后,您需要的命令出现在菜单顶部,单击右侧的图标以指定键盘快捷键:
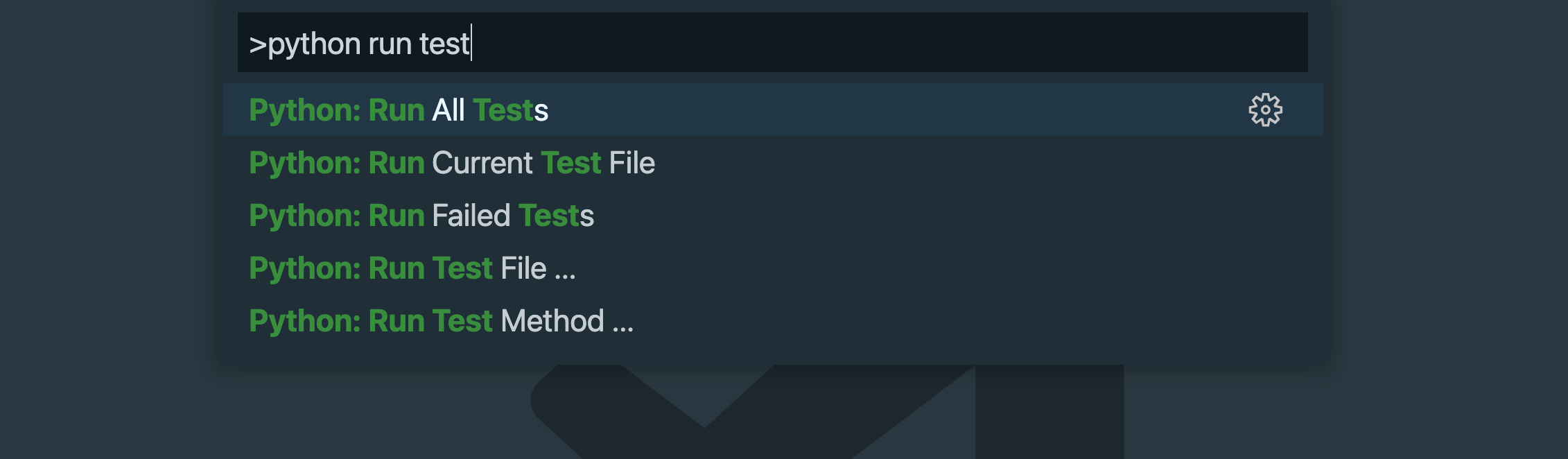
一旦你开始经常使用命令面板,你会发现有五到十个命令是你经常运行的。为这些命令分配一些快捷键,这样可以节省一些额外的击键次数。
从其他编辑器安装键盘映射
如果您已经在另一个编辑器或 IDE 中工作了一段时间,您可能会将常用的键盘快捷键保存在内存中。
你会在 Vim 、 IntelliJ 和 PyCharm 、 Sublime Text 、 Notepad++ 、 Emacs 和 Atom 的扩展中找到有用的键盘映射。
如果您之前的编辑器不在此列表中,您可能会发现其他人已经为您创建了一个制图扩展。键映射是 VS 代码扩展市场上一个有用的类别。
一旦你安装了一个键映射扩展,你可能会发现除了缺省值之外,还有额外的选项来定制它。例如,您可以使用 Vim keymap 扩展来配置 Vim 特性,比如是否以插入模式启动。
定制用户界面
当你跳进汽车的驾驶座时,首先要做的是调整座椅,调整后视镜,并将转向柱调到合适的高度。代码编辑器也不例外。它们有一个默认的布局,对每个人来说都可以,但对任何人来说都不是特别好。你不想伸展身体去够踏板。让我们来设置您的 VS 代码环境以适合您,并使它看起来很棒。
首先,VS 代码左侧的活动栏是在用于查看文件的浏览器视图、源代码控制视图、搜索视图、运行和调试视图以及扩展视图之间切换的主要导航工具。你不局限于这些选项。许多扩展都带有默认隐藏的视图。右键单击活动栏来控制您可以看到哪些视图:
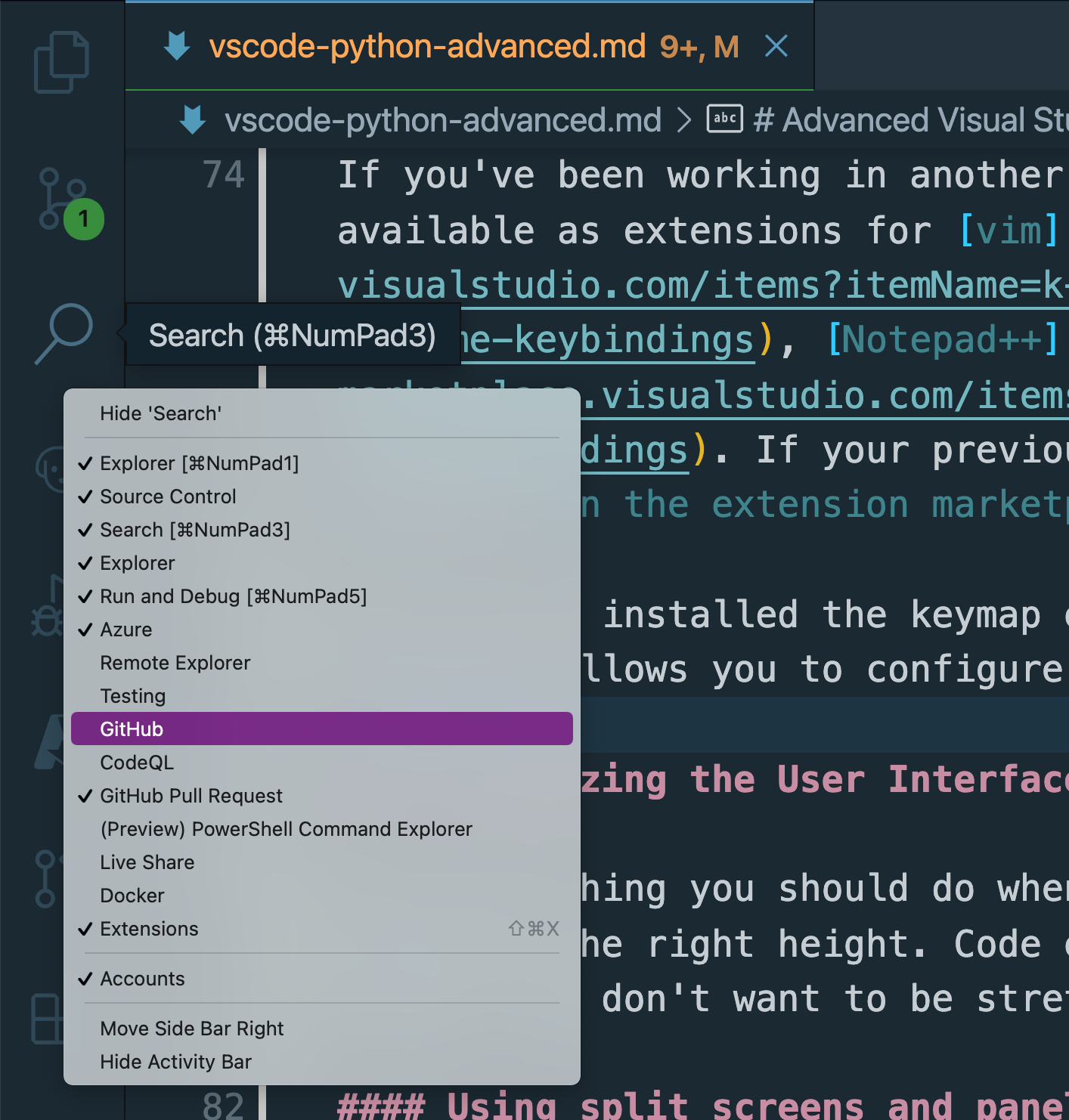
您也可以使用此菜单隐藏任何您从不使用的视图。请记住,您并不局限于列表中的视图。如果主视图中有一些面板——例如,您可以在浏览器视图中找到一些额外的面板——您可以将它们拖到活动栏来创建一个永久的快捷方式:
对于您一直使用的视图,请使用此功能。
使用分屏
Python 的风格指南 PEP 8 ,倾向于短线长度。对于宽屏幕,这留下了大量未使用的屏幕空间。
当您发现自己需要在两个或多个文件之间切换时,可以使用拆分面板功能一次显示多个编辑器区域。您可以使用命令View: Split Editor通过命令面板访问该功能。
或者,您可以使用相关的键盘快捷键:
- MAC OS:
Cmd+\ - Windows 或者 Linux:
Ctrl+\
您也可以通过进入视图→编辑器布局或右击文件标签来打开拆分编辑器功能:
这种设置在编写单元测试时非常有用,测试代码在左边,测试模块在右边。
有些文件类型,如 Markdown,有一个预览区域,您可以使用。使用Markdown: Open Preview to the Side命令打开预览编辑器。
使用禅模式专注工作
如果你需要完全专注于 VS 代码中的单个文件或任务,那么进入视图→外观→ Zen 模式使用 Zen 模式,显示一个只有编辑器的全屏窗口:
这项功能对于屏蔽嘈杂的干扰和通知特别有用,这样您就可以专注于完成当前的任务。
主题化
VS 代码在 VS 代码市场中有一个庞大的主题库。一些最受欢迎的主题有物质主题、冬天来了、吸血鬼、夜魔和 Monokai Pro 。
让我们来关注一下材质主题,因为它有一套广泛的配色方案来满足许多人的口味。你可以从扩展视图安装扩展。安装完成后,您可以通过在命令面板中运行Preferences: Color Theme来选择颜色主题。
自定义图标主题的材质主题看起来最好。图标主题是独立于颜色主题的扩展,所以你必须安装第二个扩展。在扩展视图中搜索pkief.material-icon-theme,找到该主题最流行的材质图标包。安装后,VS 代码会提示你切换你的图标包。
这是带有 Palenight 颜色主题和材料图标包的材料主题:
通过使用命令Preferences: File Icon Theme并从列表中选择一个图标主题,您可以在命令面板中随时更改图标主题。
安装更好的编程字体
编程字体是一组特殊的字体,通常具有固定宽度的字符,称为等宽。在 ProgrammingFonts.org 的有一长串可供浏览的字体:
一旦你选择了一种字体,去 Nerd Fonts 下载并在你的操作系统上安装该字体。Nerd Fonts 下载的是支持字形的等宽字体的副本,也称为图标,可以在终端提示符中使用。
安装好你选择的字体后,你需要将editor.fontFamily设置更改为新字体的名称。你可以通过导航到代码→首选项→设置,然后在导航下拉菜单中选择文本编辑器→字体来完成。您可以通过在字体系列设置的第一个字段中添加新字体的名称来更改编辑器将使用的字体。
设置您的终端
您将在 shell 终端中花费大量的 Python 开发时间。您可以使用单独的应用程序,如 iTerm2 或 Windows 终端,但 VS 代码已经有一个强大的内置终端窗口。
因为 VS 代码确实需要一点配置来使它像专用终端应用程序一样强大,所以现在您将设置它。
更改默认外壳提供者
您可以将“终端”窗口重新配置为具有多个描述文件。当您生成新的终端时,这些配置文件形成下拉列表。
VS 代码允许您配置多个终端配置文件。您不能在设置 UI 中编辑终端配置文件,因此您需要使用命令调板中的Preferences: Open Settings (JSON)命令来打开settings.json文件。您会注意到键值对组成了设置文件。每个键代表 VS 代码或其扩展之一的配置设置。
有三种终端配置文件设置,其名称如下:
| 操作系统 | 终端配置文件设置 |
|---|---|
| Windows 操作系统 | terminal.integrated.profiles.windows |
| Linux 操作系统 | terminal.integrated.profiles.linux |
| 马科斯 | terminal.integrated.profiles.osx |
输入名称后,编辑器会自动将默认概要文件填充到 JSON 文件中。
请注意,默认设置中没有 Python REPL 配置文件。您可以将带有关键字"python3-repl"的概要文件添加到 integrated profiles JSON 文件中,这样 VS 代码就可以将它作为一个概要文件选项,并直接进入 REPL 提示符:
"python3-repl": { "path": "python3", "args": ["-q"] }
-q标志是一个 Python 命令行标志,用于阻止版本头的显示。您可以向"args"添加任何额外的 Python 命令行标志。
配置完成后,根据您的操作系统,您的配置文件应该如下所示:
"terminal.integrated.profiles.osx": { "bash": { "path": "bash", "icon": "terminal-bash", }, "zsh": { "path": "zsh" }, "pwsh": { "path": "pwsh", "icon": "terminal-powershell", }, "python3-repl": { "path": "python3", "args": ["-q"] } },
VS 码对终端有两种发射方式:集成和外接。配置好配置文件后,您可以通过设置"terminal.integrated.defaultProfile.osx"的值来设置集成终端的默认配置文件:
"terminal.integrated.defaultProfile.osx": "zsh",
如果某个东西在外部终端启动,它将使用你的操作系统的默认外壳。如果您喜欢不同的终端应用程序,如 macOS 的 iTerm 2 或 Windows 的 Windows 终端,您也可以更改默认的外部终端:
"terminal.external.osxExec": "iTerm.app",
例如,对于 macOS 的这种设置,您说 VS 代码应该在每次启动外部终端窗口时调出 iTerm 应用程序。
关于 VS 代码中的终端,您甚至可以更改更多的设置。例如,当您调出一个新的终端窗口时,您可以让 VS 代码自动激活您的虚拟环境,并且您可以通过添加自定义提示来自定义您的终端的外观和感觉。在本教程中,您将探索如何做到这两点。
终端中的虚拟环境激活
虚拟环境对于管理跨 Python 项目的多种依赖关系非常重要。一旦选择了解释器,Visual Studio 代码将激活任何 Python 虚拟环境。如果您已经有了一个虚拟环境,从命令面板运行Python: Select Interpreter来选择 Python 解释器虚拟环境。
如果没有,那么在终端内部创建一个。如果虚拟环境路径被命名为.venv/、env/或venv/,VS 代码可以自动拾取它。
设置解释器后,当您在 VS 代码中启动一个新的终端窗口时,您将自动激活虚拟环境:
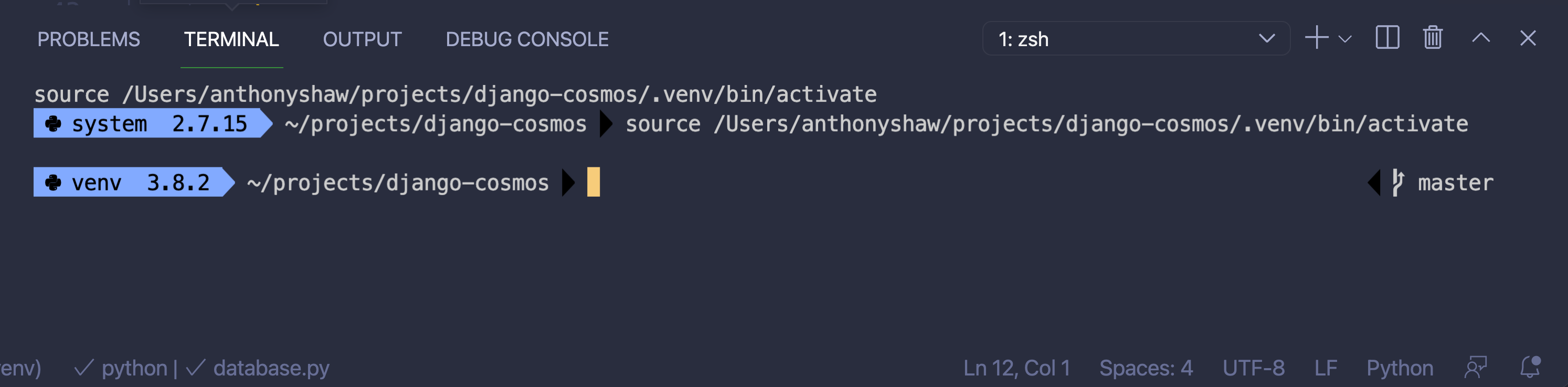
如果您已经打开了一个终端,您可以通过单击垃圾桶图标来销毁它。
您在终端内部运行的任何命令,如python -m pip install,都将用于激活的虚拟环境。
在上面的截图中,您可以看到一个自定义的命令提示符,它使用了 Oh My Posh prompt toolkit。在下一节中,您将安装和配置 Oh My Posh。哦,我的 Posh 是可选的,尤其是如果你已经安装了自定义命令提示符。
安装我的豪华轿车
Oh My Posh 是众多定制终端命令提示符的库之一。它可以在 Linux、macOS 和 Windows 上运行。它也适用于所有 Shell,如 Bash、Zsh、Fish 和 PowerShell。你可以安装 Oh My Posh 来增加你终端的趣味。
如果您在 macOS 上使用 Bash,运行以下命令来安装 Oh My Posh:
$ brew tap jandedobbeleer/oh-my-posh
$ brew install oh-my-posh
$ curl https://github.com/JanDeDobbeleer/oh-my-posh/raw/main/themes/tonybaloney.omp.json -sLo ~/.mytheme.omp.json
$ echo "eval \"\$(oh-my-posh --init --shell bash --config ~/.mytheme.omp.json)\"" >> ~/.profile
$ . ~/.profile
如果您在 macOS 上使用 Zsh,运行以下命令来安装 Oh My Posh:
$ brew tap jandedobbeleer/oh-my-posh
$ brew install oh-my-posh
$ curl https://github.com/JanDeDobbeleer/oh-my-posh/raw/main/themes/tonybaloney.omp.json -sLo ~/.mytheme.omp.json
$ echo "eval \"\$(oh-my-posh --init --shell bash --config ~/.mytheme.omp.json)\"" >> ~/.zprofile
$ . ~/.zprofile
如果您在 Windows 上使用 PowerShell,运行以下命令来安装 Oh My Posh:
PS C:\> Install-Module oh-my-posh -Scope CurrentUser
PS C:\> Add-Content $PROFILE "`nSet-PoshPrompt -Theme tonybaloney"
最后,如果您在 Linux 上使用 Bash,运行以下命令来安装 Oh My Posh:
$ sudo wget https://github.com/JanDeDobbeleer/oh-my-posh/releases/latest/download/posh-linux-amd64 -O /usr/local/bin/oh-my-posh
$ sudo chmod +x /usr/local/bin/oh-my-posh
$ curl https://github.com/JanDeDobbeleer/oh-my-posh/raw/main/themes/tonybaloney.omp.json -sLo ~/.mytheme.omp.json
$ echo "eval \"\$(oh-my-posh --init --shell bash --config ~/.mytheme.omp.json)\"" >> ~/.bashrc
$ . ~/.bashrc
当您在 VS 代码中打开一个新的终端时,您将得到以下提示:
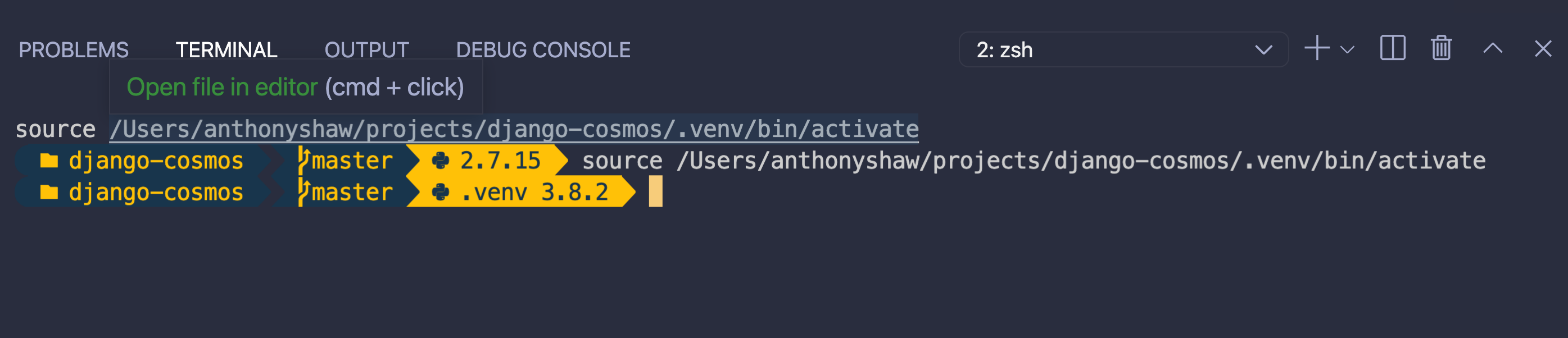
终端上的组件是文件夹、Git 分支和 Python 版本。查看主题列表中的其他选项。
**注意:**如果你正在使用定制的终端提示,如 Oh My Posh 或 Oh My Zsh ,你必须选择一个已安装的书呆子字体,以便字形在 VS 代码中正确显示。
默认情况下,终端将使用您为编辑器配置的相同字体,editor.fontFamily。您可以通过为terminal.integrated.fontFamily标识符定义不同的字体系列来覆盖它。您还需要更新您使用的任何外部终端应用程序。
团队设置 vs 个人设置
VS 代码有两个级别的设置:
- 用户设置,适用于所有项目
- 工作区设置,仅适用于该工作区
如果在两者中都声明了设置,工作区设置将覆盖用户设置。
VS 代码及其所有扩展的工作区配置位于工作区根目录下的一个.vscode/目录中。
将与项目无关的设置放在用户设置中,将特定于项目的设置放在.vscode/中是一个好主意。通过将您的个人用户设置与您的项目设置分开,您和从事该项目的任何其他开发人员都可以更有效地工作。
Python 的全局用户设置
默认情况下,Visual Studio 代码的 Python 扩展具有非常基本的配置。许多功能如林挺、格式化和安全检查被禁用,因为你需要安装第三方工具如 Black、Pylint 和 Bandit 来使用它们。
您可以安装这些工具,并通过使用pipx或pip install --user让它们对每个虚拟环境可用。 pipx 比pip install --user更可取,因为它将为该包创建并维护一个虚拟环境,使您的全球站点包更小,并降低打包冲突的风险。
一旦安装了pipx ,就可以安装常用工具了:
$ pipx install pylint && \
pipx install black && \
pipx install poetry && \
pipx install pipenv && \
pipx install bandit && \
pipx install mypy && \
pipx install flake8
或者,使用python3 -m pip install --user安装常用工具:
$ python3 -m pip install --user pylint black poetry pipenv bandit mypy flake8
安装好基础工具后,用Preferences: Open Settings (JSON)从命令面板打开用户设置。为您想要应用到所有项目的偏好设置添加设置:
1"python.pipenvPath": "${env:HOME}/.local/bin/pipenv", 2"python.poetryPath": "${env:HOME}/.local/bin/poetry", 3"python.condaPath": "${env:HOME}/.local/bin/conda", 4"python.linting.enabled": true, 5"python.linting.banditPath": "${env:HOME}/.local/bin/bandit", 6"python.linting.banditEnabled": true, 7"python.linting.pylintPath": "${env:HOME}/.local/bin/pylint", 8"python.linting.mypyPath": "${env:HOME}/.local/bin/mypy", 9"python.linting.flake8Path": "${env:HOME}/.local/bin/flake8", 10"python.formatting.blackPath": "${env:HOME}/.local/bin/black",
有了这些设置,您已经成功地完成了几件事,这对您跨许多项目的开发工作流很有用:
- 第 1 行到第 3 行为启用了
pipenv、poetry和conda的项目启用包发现。 - 第 4 行启用 Python 林挺。
- 线 5 至线 6 使能并将路径设置为
bandit。 - 第 7 到 10 行启用 Python 格式化,并设置路径到一个全局安装的
pylint、mypy、flake8和black实例。
在每个绝对路径中,您可以使用宏${env:HOME}自动替换您的主文件夹。
工作区设置
在用户设置之外,您可以使用工作区内的.vscode/目录来配置一些特定于项目的设置:
- 哪个命令运行以执行项目
- 如何测试和调试项目
- 使用哪个棉绒和格式器以及任何项目特定参数
以下文件包含 VS 代码首选项:
| 文件 | 目的 |
|---|---|
settings.json | VS 代码设置 |
launch.json | 从运行和调试菜单执行项目的配置文件 |
tasks.json | 要执行的任何附加任务,如构建步骤 |
大多数 VS 代码的设置,以及您的扩展的设置,都在这三个文件中。
在工作区首选项中,支持以下预定义变量:
| 预定义变量 | 意义 | |
|---|---|---|
${env.VARIABLE} | 任何环境变量 | |
${workspaceFolder} | 在 VS 代码中打开的文件夹的路径 | |
${workspaceFolderBasename} | 在 VS 代码中打开的文件夹的名称,不带任何斜杠(/) | |
${file} | 当前打开的文件 | |
${fileWorkspaceFolder} | 当前打开的文件的工作区文件夹 | |
${relativeFile} | 当前打开的文件相对于workspaceFolder | |
${cwd} | 启动时任务运行程序的当前工作目录 | |
${execPath} | 正在运行的 VS 代码可执行文件的路径 | |
${pathSeparator} | 操作系统用来分隔文件路径中各部分的字符,例如,正斜杠(/)或反斜杠(\) |
使用这些变量将保持项目设置与环境无关,因此您可以将它们提交到 Git 中。
作为使用这些设置的一个例子,如果您想使用 Black 作为这个项目的默认代码格式化程序,您可以用这个配置创建文件.vscode/settings.json:
{ "python.formatting.provider": "black", }
任何签出这个项目的人现在将自动使用 Black 作为 Python 文件的格式化程序。在关于设置格式和 lint on save 的章节中,您将看到该设置如何影响自动套用格式选项。
使用设置同步扩展
如果您在多台计算机上使用 VS 代码,您可以启用设置、键盘快捷键、用户代码片段、扩展和 UI 状态的自动同步。如果你以前没有使用过设置同步,你需要启用它:
- 在命令面板中运行
Settings Sync: Turn On。 - 按照 VS 代码提示的设置步骤进行操作。可以用 GitHub 认证。
- 一旦设置完成,从命令面板运行
Settings Sync: Configure。 - 选择您想要同步的内容。
一旦在所有安装了 VS 代码的计算机上配置了设置同步,你可以通过从命令面板运行Settings Sync: Show Synced Data来查看每个同步设置的状态,它们会显示在同步机器下:
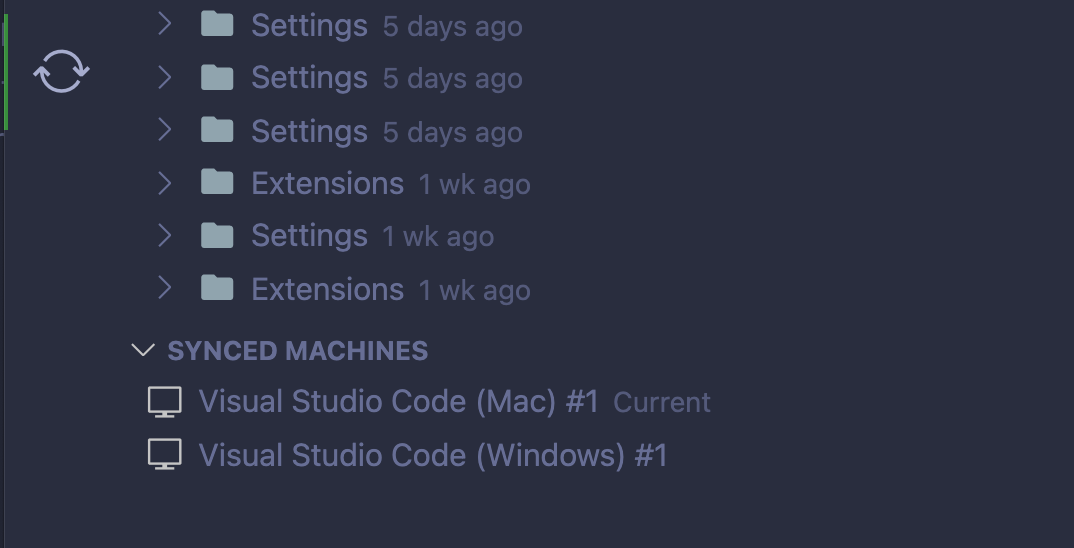
此视图显示每个设置的上次同步时间以及哪些机器正在同步。
林挺和格式化
Visual Studio 代码中的所有语言都可以使用自动格式化程序之一进行格式化,Python 扩展也支持 linters。Linters 和 formatters 执行不同的任务:
- 一个格式化程序将改变你的代码的外观,但不会改变它的工作方式。
- 一个 linter 会警告你你的代码是否符合风格、类型坚持、安全性和一系列最佳实践的标准。
Python 扩展支持许多第三方 linters,它们经常执行不同的工作。例如, Bandit 是一个针对安全漏洞的贴体, Flake8 是一个符合风格指南的贴体。
Python 扩展还附带了语言服务器工具,它通过从您的代码和您使用的库中加载接口(方法、函数、类)来执行分析。
在写这篇教程的时候,Visual Studio 代码上最新最棒的 Python 语言服务器扩展是 Pylance 。
设置挂架
Pylance 是一个扩展,在 Visual Studio 代码中与 Python 一起工作,提供更深层次的语言支持和 Python 代码的自省。Pylance 将提供自动完成、自动化模块导入、更好的代码导航、类型检查以及更多的功能。
要获得 Pylance,进入侧边栏上的扩展菜单并搜索Pylance ( ms-python.vscode-pylance)。
注意: Pylance 现在与 Python 扩展捆绑在一起,所以您可能已经安装了它。
一旦你安装了 Pylance,在你的用户设置中有两个默认的配置设置你可能想要改变,以充分利用这个扩展。
第一个要更改的设置是类型检查模式,您可以使用该模式来指定所执行的类型检查分析的级别:
"python.analysis.typeCheckingMode": "basic"
默认情况下,类型检查模式设置为"off"。
其他选项是"basic"或"strict"。使用"basic",运行与类型检查无关的规则和基本类型检查规则。如果模式设置为"strict",它将以最高的错误严重性运行所有类型检查规则。将此项设置为"basic"以在严格和禁用之间取得平衡。
另一个默认设置是python.analysis.diagnosticMode。默认情况下,Pylance 将只检查当前打开的文件。将此设置更改为workspace将检查工作区中的所有 Python 文件,在浏览器视图中给您一个错误和警告列表:

如果你有多余的内存,你应该只设置python.analysis.diagnosticMode到"workspace",因为它会消耗更多的资源。
当 Pylance 拥有关于用作方法和函数的参数的类型以及返回类型的信息时,它是最有效的。
对于外部库,Pylance 将使用typed来推断返回类型和参数类型。Pylance 还为一些最流行的数据科学库提供了类型存根和智能,如 pandas、Matplotlib、scikit-learn 和 NumPy。如果你在和熊猫一起工作,Pylance 会给你一些常见功能和模式的信息和例子:
对于在 typeshed 上没有类型存根的库,Pylance 会尽力猜测类型是什么。否则,你可以添加你自己的类型存根。
保存时设置格式和 Lint
格式化文档是一个将格式应用于 VS 代码中任何文档的动作。对于 Python 扩展,这个动作执行"python.formatting.provider",它可以被设置为任何支持的自动格式化程序:"autopep8"、"black"或"yapf"。
一旦您在settings.json中配置了格式化程序,您可以设置格式化程序在保存文件时自动运行。在 VS 代码配置中,您可以将编辑器设置配置为只应用于某些文件类型,方法是将它们放在一个"[<file_type>]"组中:
... "[python]": { "editor.formatOnSave": true, },
除了执行格式化程序之外,您还可以按字母顺序组织导入语句,并通过将标准库模块、外部模块和包导入分成具有以下配置的组:
"[python]": { ... "editor.codeActionsOnSave": {"source.organizeImports": true}, },
与格式化不同,林挺特定于 Python 扩展。要启用林挺,在命令面板上运行Python: Select Linter选择一个 linter。您也可以在您的设置中启用一个或多个棉条。例如,要启用 Bandit 和 Pylint linters,请编辑您的settings.json:
... "python.linting.enabled": true, "python.linting.banditEnabled": true, "python.linting.pylintEnabled": true,
要在保存文件时运行启用的 linters,将以下设置添加到settings.json:
... "python.linting.lintOnSave": true,
您可能会发现启用多个 linter 很有帮助。请记住,Pylance 已经提供了许多您可以从 pylint 获得的见解,因此您可能不需要同时启用 pylint 和 Pylance。相比之下,Flake8 提供了 Pylance 没有涵盖的风格反馈,因此您可以一起使用这两者。
在 Visual Studio 代码中测试您的 Python 代码
Python 提供了大量的工具来测试你的代码。VS 代码的 Python 扩展支持最流行的测试框架,unittest和pytest。
配置测试集成
要启用对 Python 的测试支持,请从命令面板运行Python: Configure Tests命令。VS 代码将提示您从一个支持的测试框架中进行选择,并指定哪个文件夹包含您的测试。
该向导将配置选项添加到.vscode/settings.json:
"python.testing.pytestEnabled": true, "python.testing.pytestArgs": [ "tests" ],
您可以用您喜欢的测试框架编辑python.testing.<framework>Args,以添加任何额外的命令行标志。上面的例子显示了 pytest 的配置选项。
如果你有更复杂的 pytest 设置,把它们放在pytest.ini而不是 VS 代码设置中。这样,您将保持配置与任何自动化测试或 CI/CD 工具一致。
执行测试
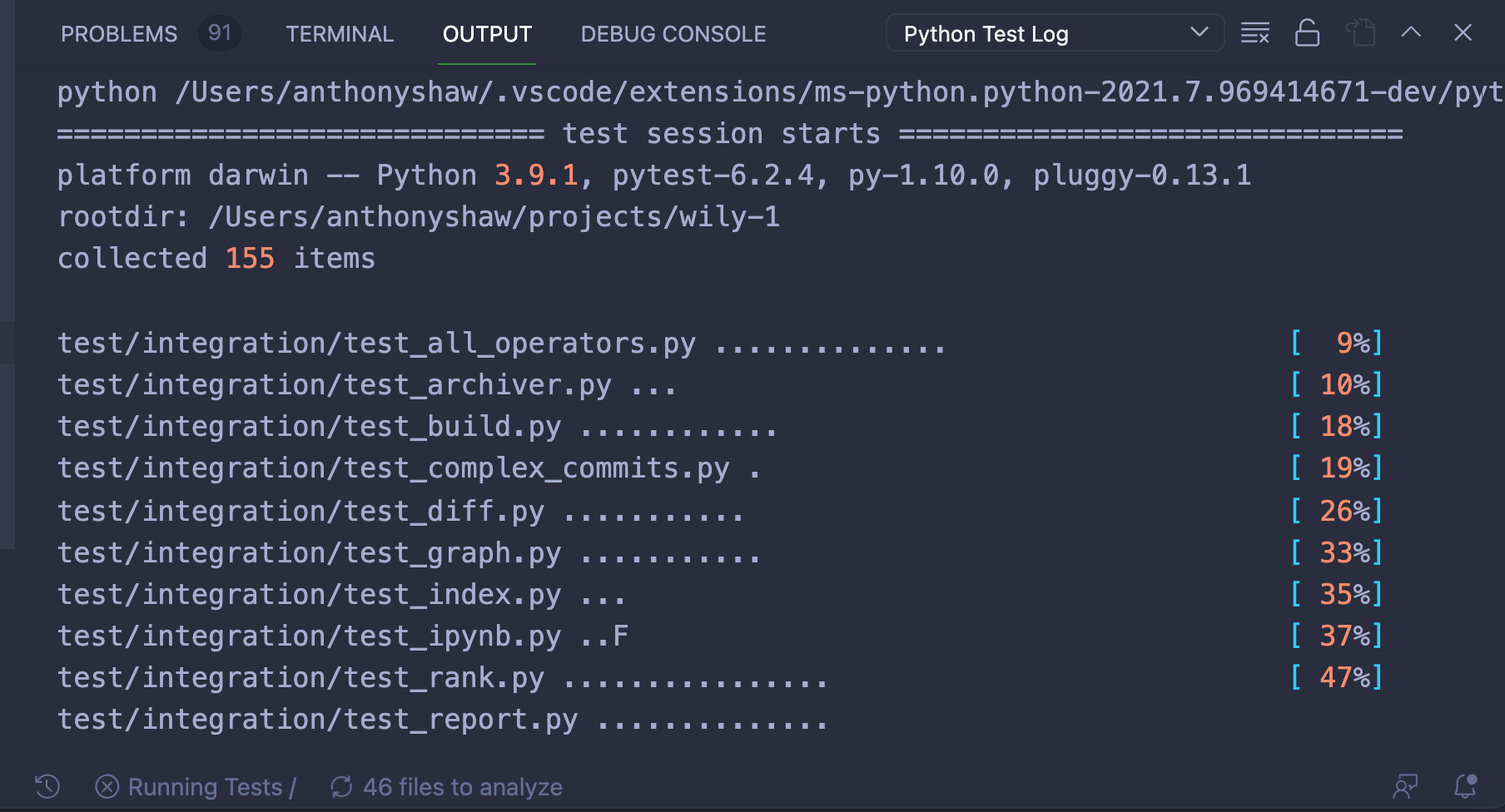
一旦您为测试运行器配置了测试框架和参数,您就可以通过从命令面板运行Python: Run All Tests命令来执行您的测试。这将使用配置的参数启动测试运行器,并将测试输出放入 Python 测试日志输出面板:
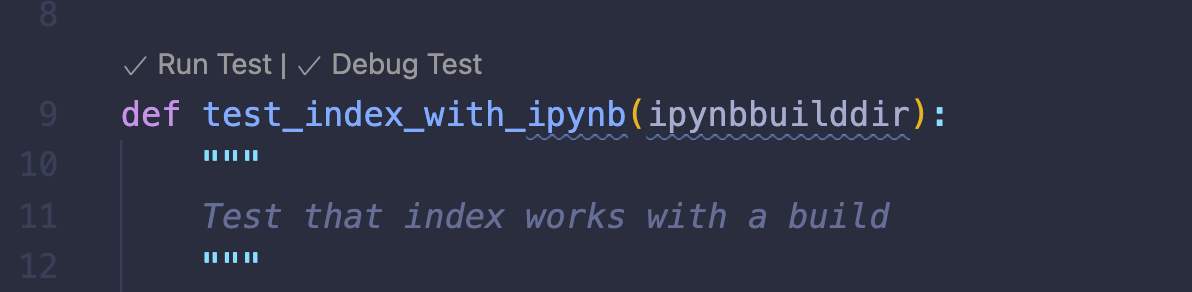
一旦测试发现完成,每个测试用例将有一个内联选项来执行或调试该用例:
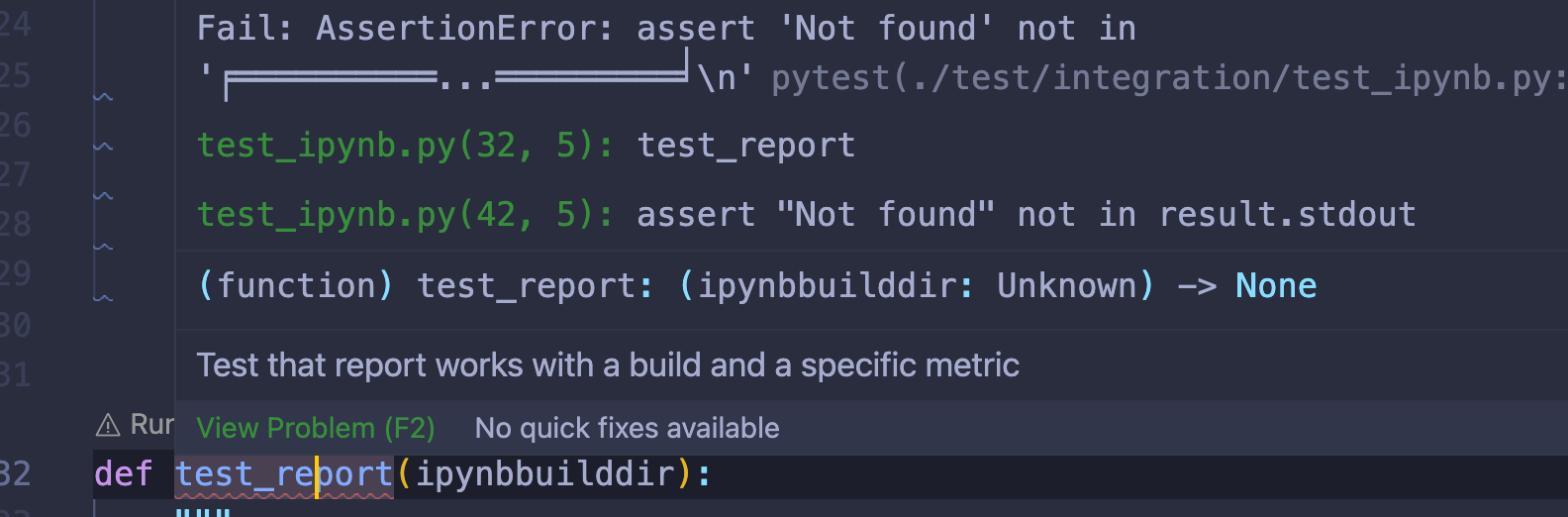
失败的测试将被标记为有错误。您可以在 Python 测试日志面板中看到测试运行程序的失败,也可以将鼠标悬停在代码中失败的测试用例上:
如果您经常运行测试,您可以使用测试浏览器改善您在 VS 代码中的测试体验。
要启用测试面板,右键单击侧栏并确保选中了测试。测试面板显示 Python 扩展发现的所有测试,并为您提供许多功能:
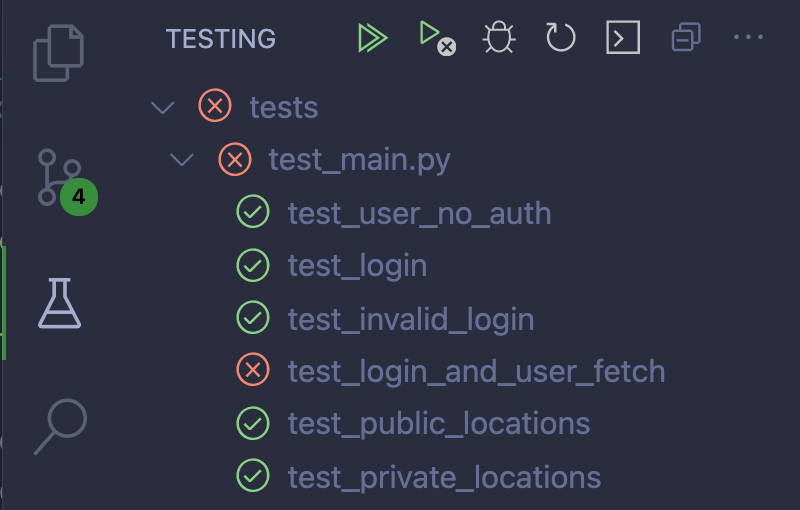
您有一个测试套件分组以及哪些测试失败的可视化表示。您还可以使用菜单按钮来运行和调试测试。
VS Code 的测试系统很强大,但是很多功能在默认情况下是禁用的,以保持它是一个轻量级的编辑器。除了测试之外,您可能还想从 VS 代码内部定期运行其他任务。这就是任务系统的用武之地。
使用 Visual Studio 代码任务系统
Visual Studio 代码支持编译语言,如 Go、Rust 和 C++,也支持解释语言,如 Python 和 Ruby。VS Code 有一个灵活的系统来执行用户定义的配置好的任务,比如构建和编译代码。
Python 代码通常不需要提前编译,因为 Python 解释器会为你做这件事。相反,您可以使用任务系统来预配置任务,否则您将在命令行运行这些任务,例如:
- 构建一个轮或源分布
- 在像 Django 这样的框架中运行任务
- 编译 Python C 扩展
VS 代码任务是命令或可执行文件,您可以使用命令面板按需运行。有两个内置的默认任务:
- 构建任务
- 测试任务
请注意,您可以将任务用于任何原本可以通过命令行执行的事情。您并不局限于构建和测试活动。
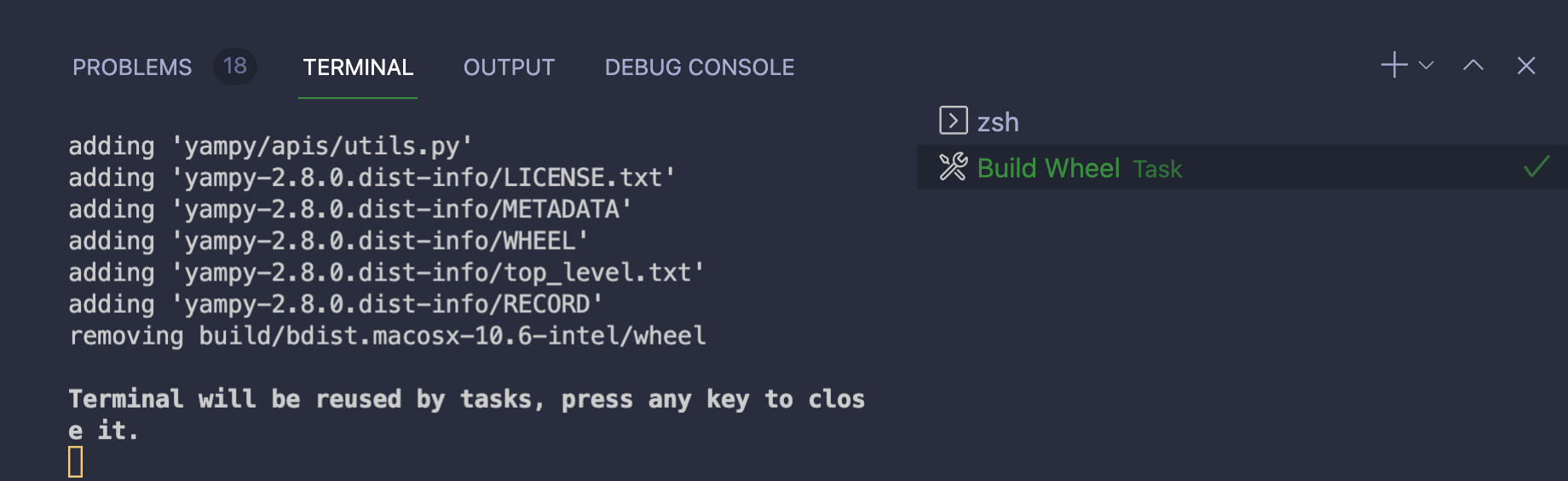
使用任务编译车轮
如果您有一个setup.py文件来构建一个包以便在 PyPI 上发布,那么您可以使用 tasks 系统来自动构建源代码(Python)和二进制(编译的 Python)发布包。
任务在一个.vscode/tasks.json文件中定义。为了进行试验,创建.vscode/tasks.json并复制这个配置:
1{ 2 "version": "2.0.0", 3 "tasks": [ 4 { 5 "type": "shell", 6 "command": "${command:python.interpreterPath}", 7 "args": ["setup.py", "bdist_wheel", "sdist"], 8 "isBackground": true, 9 "options": {"cwd": "${workspaceFolder}"}, 10 "label": "Build Wheel", 11 "group": { 12 "kind": "build", 13 "isDefault": true 14 } 15 } 16 ] 17}
在这个例子中有一些事情需要注意,所以您将逐行查看最重要的配置:
- **第 5 行:**任务类型是
shell,它指定这个任务应该在您配置的 shell 下运行。 - **第 6 行:**命令是
${command:python.interpreterPath},这是这个环境的 Python 解释器的内置变量。这包括任何激活的虚拟环境。 - **第 9 行:**选项
"options": {"cwd": "${workspaceFolder}"}指定这应该在项目的根目录下运行。如果需要,您可以将其更改为子文件夹。 - 第 11 行到第 13 行:
"group"设置为"build",由于你将"isDefault"设置为true,该任务将成为你的默认任务。这意味着此任务将作为默认的生成任务运行。
要执行默认的构建任务,可以从命令面板运行Tasks: Run Build Task或者使用内置的键盘快捷键 Cmd + F9 或者 Ctrl + F9 。在终端选项卡下,您可以找到在"label"中指定的构建命令的输出:
您不局限于构建脚本。对于 Django 和 Flask 的管理命令来说,任务系统是一个很好的解决方案。
使用 Django 的任务
您正在使用 Django 应用程序吗,您想从命令行自动运行manage.py吗?您可以使用shell类型创建一个任务。这样,您就可以使用想要运行的 Django 子命令以及任何参数来执行manage.py:
{ "version": "2.0.0", "tasks": [ { "type": "shell", "command": "${command:python.interpreterPath}", "args": ["manage.py", "makemigrations"], "isBackground": true, "options": {"cwd": "${workspaceFolder}"}, "label": "Make Migrations" } ] }
要运行这个任务,使用命令面板中的Tasks: Run Task命令,并从列表中选择 Make Migrations 任务。
您可以复制这个代码片段,并将其粘贴到您定期运行的任何 Django 命令中,比如collectstatic。
链接任务
如果您有多个应该按顺序运行的任务或者一个任务依赖于另一个任务,您可以在tasks.json中配置任务相关性。
扩展一下的setup.py例子,如果您想首先构建您的包的源代码发行版,您可以将下面的任务添加到tasks.json:
... { "type": "shell", "command": "${command:python.interpreterPath}", "args": ["setup.py", "sdist"], "isBackground": true, "options": {"cwd": "${workspaceFolder}"}, "label": "Build Source", }
在默认的构建任务中,您可以添加一个属性dependsOn以及需要首先运行的任务标签列表:
{ "version": "2.0.0", "tasks": [ { "type": "shell", "command": "${command:python.interpreterPath}", "args": ["setup.py", "bdist_wheel"], "isBackground": true, "options": {"cwd": "${workspaceFolder}"}, "label": "Build Wheel", "group": { "kind": "build", "isDefault": true }, "dependsOn": ["Build Source"] } ] }
下次运行此任务时,它将首先运行所有相关任务。
如果您有该任务依赖的多个任务,并且它们可以并行运行,请将"dependsOrder": "parallel"添加到任务配置中。
使用任务运行 Tox
现在您将探索 tox ,这是一个旨在自动化和标准化 Python 测试的工具。针对 Visual Studio 代码的 Python 扩展没有与 tox 集成。相反,您可以使用 tasks 系统将 tox 设置为默认测试任务。
**提示:**如果你想快速上手 tox,那么安装tox和 pip 并运行tox-quickstart命令:
$ python -m pip install tox
$ tox-quickstart
这将提示您创建一个 tox 配置文件的步骤。
要使用您的 tox 配置自动运行 tox,请向tasks.json添加以下任务:
{ "type": "shell", "command": "tox", "args": [], "isBackground": false, "options": {"cwd": "${workspaceFolder}"}, "label": "Run tox", "group": { "kind": "test", "isDefault": true } }
您可以使用命令面板中的Tasks: Run Test Task来运行该任务,该任务将使用终端选项卡中的输出来执行 tox:
如果您有一些任务并且需要经常运行它们,那么是时候探索一个伟大的扩展了,它在 UI 中添加了一些快捷方式来运行配置好的任务。
使用任务浏览器扩展
任务浏览器扩展(spmeesseman.vscode-taskexplorer ) 增加了简单的 UI 控件来运行你预先配置的任务。一旦安装完毕,任务浏览器将成为浏览器视图中的一个面板。它扫描您的项目,自动发现npm、make、gulp和许多其他构建工具的任务。您可以在 vscode 组下找到您的任务:
单击任何任务旁边的箭头来执行该任务,如果更改任务的配置,则单击顶部的刷新图标。
在 Visual Studio 代码中调试 Python 脚本
Visual Studio 代码的 Python 扩展捆绑了一个强大的调试器,它支持本地和远程调试。
运行和调试一个简单的 Python 脚本最简单的方法是进入运行→开始调试菜单,并从选项中选择 Python 文件。这将使用配置的 Python 解释器执行当前文件。
您可以在代码中的任意位置设置断点,方法是单击行号左侧的空白。当代码执行过程中遇到断点时,代码将暂停并等待指令:
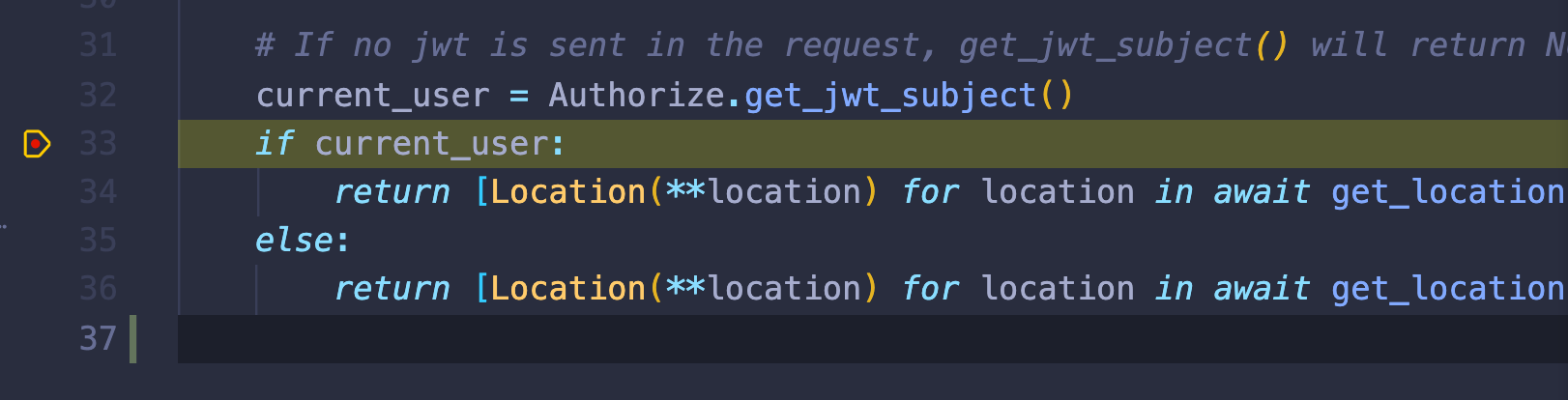
调试器增加了一个菜单控件:继续,跨过,步入,步出,重启,停止执行:

在左侧面板上,您可以执行常见的调试操作,例如探索局部和全局变量以及 Python 的调用堆栈。您还可以设置手表,这将在下一节中详细介绍。
设置手表
Watches 是在调试会话之间持续的表达式。当您停止执行并再次开始调试时,您将保留上次会话中的所有监视。
你可以从变量面板通过右击一个变量并选择添加到观察来添加一个变量到观察面板。
您还可以通过点击 + 图标,将任何 Python 表达式添加到观察列表中。表达式可以包含:
- 小 Python 表达式,比如
x == 3 - 函数调用,如
var.upper() - 比较
每当遇到断点时,您将实时获得每个表达式的当前结果。VS 代码还会在您调试会话时更新每个观察器的值:
您可以使用左边的箭头扩展复杂类型,如字典和对象。
到目前为止,您已经看到了单个 Python 文件的调试器,但是许多 Python 应用程序都是模块,或者需要特殊的命令才能启动。
配置启动文件
VS 代码有一个用于启动概要文件的配置文件,.vscode/launch.json。VS 代码的 Python 调试器可以启动任何启动配置,并将调试器附加到它上面。
**注意:**要查看即将到来的配置的预期结果,您需要设置一个有效的 FastAPI 项目,并且在您正在使用的 Python 环境中安装 async web 服务器uvicon。
作为在 VS 代码中使用启动概要文件的例子,您将探索如何使用 ASGI 服务器uvicorn来启动一个 FastAPI 应用程序。通常,您可以只使用命令行:
$ python -m uvicorn example_app.main:app
相反,您可以在launch.json中设置一个等效的启动配置:
{ "configurations": [ { "name": "Python: FastAPI", "type": "python", "request": "launch", "module": "uvicorn", "cwd": "${workspaceFolder}", "args": [ "example_app.main:app" ], } ] }
这里,您将配置中的"type"设置为"python",这告诉 VS 代码使用 Python 调试器。您还设置了"module"来指定要运行的 Python 模块,在本例中是"uvicorn"。您可以在"args"下提供任意数量的参数。如果您的应用程序需要环境变量,您也可以使用env参数设置这些变量。
一旦您添加了这个配置,您应该会发现您的新启动配置已经准备好在运行和调试面板下启动:
当您按下 F5 或从顶部菜单中选择运行→开始调试时,您配置为首次启动配置的任何内容都将运行。
如果 VS 代码没有自动为您选择正确的 Python 环境,那么您也可以在您的.vscode/launch.json文件中声明一个到适当的 Python 解释器的显式路径作为选项:
1{ 2 "configurations": [ 3 { 4 "name": "Python: FastAPI", 5 "type": "python", 6 "python": "${workspaceFolder}/venv/bin/python", 7 "request": "launch", 8 "module": "uvicorn", 9 "cwd": "${workspaceFolder}", 10 "args": [ 11 "example_app.main:app" 12 ], 13 } 14 ] 15}
您可以将路径作为名为"python"的新条目添加到您的 Python 解释器中。在这个例子中,解释器位于一个名为venv的 Python 虚拟环境中,这个环境是在您的工作空间文件夹的根目录下创建的。如果您想使用不同的 Python 解释器,您可以通过编辑第 6 行所示的路径来定义它的路径,以适应您的设置。
掌握远程开发
VS 代码支持三种远程开发配置文件:
- 容器
- SSH 上的远程主机
- 用于 Linux 的 Windows 子系统(WSL)
所有三个选项都由远程开发扩展包(ms-vscode-remote.vscode-remote-extensionpack ) 提供。您需要安装这个扩展包,以便在 VS 代码中显示远程调试特性。
使用容器进行远程开发
您需要在您的机器上安装 Docker 运行时,以便对容器使用远程调试。如果你还没有安装 Docker,你可以从 Docker 网站下载。
Docker 运行后,转到左侧导航菜单上的远程浏览器选项卡。将远程浏览器下拉菜单更改为容器,您将看到一个带有面板的视图:
如果您有一个全新的 Docker 安装,这些面板不会被填充。
如果您已经安装并运行了 Docker 映像,则可能会填充三个面板:
- **容器:**一个导航面板,显示这个工作区中的开发容器或者一些快速启动步骤的链接
- **容器的名称(如果正在运行)😗*正在运行的容器的属性和卷装载
- DevVolumes: 您可以编辑和挂载以修改代码的开发卷列表
例如,如果您按照 VS Code 的容器教程中概述的步骤安装了试用开发容器:Python ,那么您的 VS Code 远程资源管理器选项卡将在前面提到的面板中显示运行容器的名称:
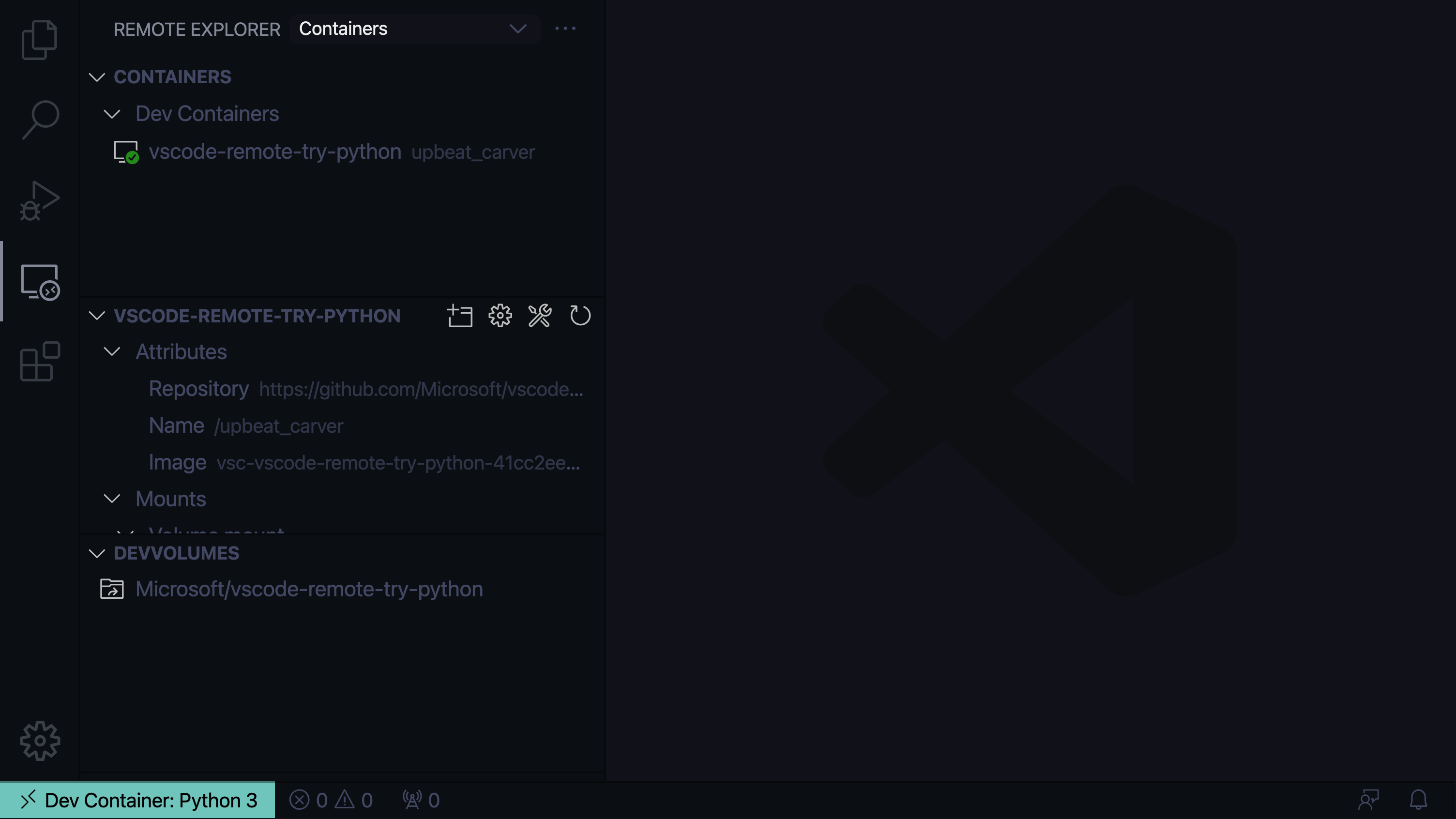
使用这些面板可以快速管理项目所依赖的任何 Docker 容器。
一般来说,运行远程容器扩展有三种主要方式:
- 附加到现有的运行容器以进行快速更改
- 创建一个
.devcontainer/devcontainer.json文件,并将工作区作为远程容器打开 - 运行
Remote-Containers: Reopen in Container命令并选择 Python 3 图像
创建一个.devcontainer/devcontainer.json文件比简单地打开一个容器有更大的好处:
- 开发容器支持 GitHub 代码空间
- Dev 容器支持本教程中显示的启动概要文件和任务配置
如果你计划在容器和 VS 代码中工作很多,花费额外的时间来创建一个开发容器将会得到回报。
**注意:**通过通读 VS 官方代码文档,你可以更详细地了解如何创建开发容器。
开始使用 dev 容器的一个快速方法是从您当前的工作区创建它:
- 从命令面板运行
Remote-Containers: Reopen in Container命令。 - 选择 Python 3,然后选择所需的 Python 版本。
- 接受 Node.js 的默认建议版本。
然后,VS 代码将移植您现有的工作空间,并基于 Python 的通用 Dockerfile 创建一个.devcontainer/devcontainer.json配置。
开发容器有两个必需的文件:
.devcontainer/devcontainer.json,指定所有 VS 代码需求,比如需要哪些扩展,使用什么设置Dockerfile,其中指定了哪些命令将构建环境
在默认设置中,Dockerfile位于.devcontainer/目录中。如果您的项目已经有了一个Dockerfile,您可以通过改变.devcontainer/devcontainer.json中的路径来重用它。
您将使用.devcontainer/devcontainer.json中的默认值来指定:
- 路径到
Dockerfile - 容器的名称
- 要应用的 VS 代码设置
- 任何需要安装的 VS 代码扩展
- 任何你想要运行的后期创建命令,比如
python -m pip install <package>
如果您的应用程序需要来自 PyPI 的额外包,请更改.devcontainer/devcontainer.json并取消对指定"postCreateCommand"的行的注释:
{ ... // Use 'postCreateCommand' to run commands after the Container is created. "postCreateCommand": "python3 -m pip install -r requirements.txt", }
如果您正在开发提供网络服务的应用程序,如 web 应用程序,您还可以添加端口转发选项。对于选项的完整列表,您可以通过 devcontainer.json参考。
在对Dockerfile或 devcontainer 规范进行更改之后,通过右键单击正在运行的容器并选择 Rebuild Container ,从远程资源管理器重新构建容器:
通过这样做,您将使用对配置和Dockerfile的任何更改来重新构建 Docker 容器。
除了远程开发扩展包的远程调试扩展功能之外,还有一个针对 VS 代码的 Docker 扩展。您将在本教程的最后讨论这个扩展,并找到更多的特性。
使用 SSH 进行远程开发
通过在命令面板中运行Remote-SSH: Open SSH Configuration File,您可以打开本地 SSH 配置文件。这是一个标准的 SSH 配置文件,用于列出主机、端口和私有密钥的路径。IdentityFile选项默认为~/.ssh/id_rsa,因此最好的认证方式是一个私有和公共密钥对。
下面是两台主机的配置示例:
Host 192.168.86.30
HostName 192.168.86.30
User development
IdentityFile ~/path/to/rsa
Host Test-Box
HostName localhost
User vagrant
Port 2222
一旦保存了配置文件, Remote Explorer 选项卡将在 SSH Targets 下拉选项下列出那些 SSH 主机:
要连接到该服务器,请在新窗口中点击连接到主机,该窗口是任何主机右侧的图标。这将在远程主机上打开一个新的 VS 代码窗口。
一旦连接上,点击浏览器视图下的打开文件夹。VS 代码将向您显示一个特殊的文件夹导航菜单,该菜单显示远程主机上的可用文件夹。导航到您的代码所在的文件夹,您可以在该目录下启动一个新的工作区:
在这个远程工作区中,您可以编辑和保存远程服务器上的任何文件。如果您需要运行任何额外的命令,终端选项卡会自动设置为远程主机的 SSH 终端。
使用 WSL 进行远程开发
Linux 的 Windows 子系统或 WSL 是微软 Windows 的一个组件,它使用户能够在他们的 Windows 操作系统上运行任意数量的 Linux 发行版,而不需要单独的管理程序。
VS 代码支持 WSL 作为远程目标,所以可以在 WSL 下运行 Windows 的 VS 代码,进行 Linux 的开发。
首先将 WSL 与 VS 代码一起使用需要安装 WSL。一旦安装了 WSL,您需要至少有一个可用的发行版。
在最新版本的 Windows 10 上安装 WSL 最简单的方法是打开命令提示符并运行:
C:\> wsl --install
--install命令执行以下动作:
- 启用可选的 WSL 和虚拟机平台组件
- 下载并安装最新的 Linux 内核
- 将 WSL 2 设置为默认值
- 下载并安装 Linux 发行版,可能需要重启机器
一旦你成功地在你的计算机上设置了 WSL,你还需要为 VS 代码安装 Remote - WSL ( ms-vscode-remote.remote-wsl ) 扩展。之后,您就可以在 Visual Studio 代码中使用 WSL 了。
如果您已经有了 WSL 中的代码,那么在 VS 代码中从命令面板运行Remote-WSL: Open Folder in WSL。在 Linux 子系统中选择代码的目标目录。
如果您的代码在 Windows 中签出,请从命令面板运行Remote-WSL: Reopen Folder in WSL。
远程浏览器将记住您配置的 WSL 目标,并让您从远程浏览器视图中的 WSL 目标下拉列表中快速重新打开它们:
如果您想要一个可再现的环境,可以考虑创建一个Dockerfile,而不是直接在 WSL 主机上工作。
使用数据科学工具
VS 代码非常适合使用 Python 进行应用程序开发和 web 开发。它还有一套强大的扩展和工具,用于处理数据科学项目。
到目前为止,您已经讨论了 VS 代码的 Python 扩展。还有 Jupyter 笔记本扩展,它将 IPython 内核和一个笔记本编辑器集成到 VS 代码中。
安装 Jupyter 笔记本扩展
要在 VS 代码上开始使用 Jupyter 笔记本,你需要 Jupyter 扩展(ms-toolsai.jupyter ) 。
注意: Jupyter 笔记本支持现在与 Python 扩展捆绑在一起,所以如果您已经安装了它,请不要感到惊讶。
Jupyter 笔记本支持pip作为包管理器,以及来自Anaconda 发行版的conda。
Python 的数据科学库通常需要用 C 和 C++编写的编译模块。如果您正在使用大量第三方包,那么您应该使用conda作为包管理器,因为 Anaconda 发行版已经代表您解决了构建依赖,使得安装包变得更加容易。
VS 代码【Jupyter 笔记本入门
对于这个例子,你将打开一系列关于波变换的 Jupyter 笔记本。下载 repo 的.zip/文件夹解压,或者克隆 GitHub repo 用 VS 代码打开。下面进一步描述的步骤也适用于包含.ipynb笔记本文件的任何其他工作区。
**注意:**本节的其余部分使用conda包管理器。如果您想使用本节中显示的命令,您需要安装Anaconda。
在 VS 代码中,可以使用任何现有的conda环境。您可以从终端创建一个专门针对 VS 代码的conda环境,而不是将包安装到基础环境中:
$ conda create --name vscode python=3.8
在创建了名为vscode的conda环境之后,您可以在其中安装一些常见的依赖项:
$ conda install -n vscode -y numpy scipy pandas matplotlib ipython ipykernel ipympl
一旦安装了依赖项,从 VS 代码命令面板运行Python: Select Interpreter命令并搜索vscode来选择新的conda环境:
这个选项将设置您的 VS 代码使用来自您的conda环境vscode的 Python 解释器。
**注意:**如果列表中没有conda环境,您可能需要通过从命令面板运行Developer: Reload Window命令来重新加载窗口。
选中后,在 VS 代码中打开一个笔记本,点击右边的选择内核按钮或者从命令面板中运行Notebook: Select Notebook Kernel命令。键入vscode选择新创建的conda环境,其中安装了依赖项:

选择您的新conda环境作为您笔记本的内核将使您的笔记本能够访问您在该环境中安装的所有依赖项。这是执行代码单元所必需的。
一旦选择了内核,您就可以运行任意或所有的单元并查看显示在 VS 代码中的操作输出:
一旦笔记本被执行,Jupyter 扩展将使任何中间变量,如列表、NumPy 数组和 pandas 数据帧在 Jupyter: Variables 视图中可用:
你可以通过点击笔记本顶部的变量按钮或运行Jupyter: Focus on Variables View命令来聚焦这个视图。
对于更复杂的变量,选择图标在数据查看器中打开数据。
使用数据查看器
Jupyter 扩展附带了一个数据查看器,用于查看和过滤 2D 数组,如列表、NumPy 的ndarray和 pandas 数据帧:
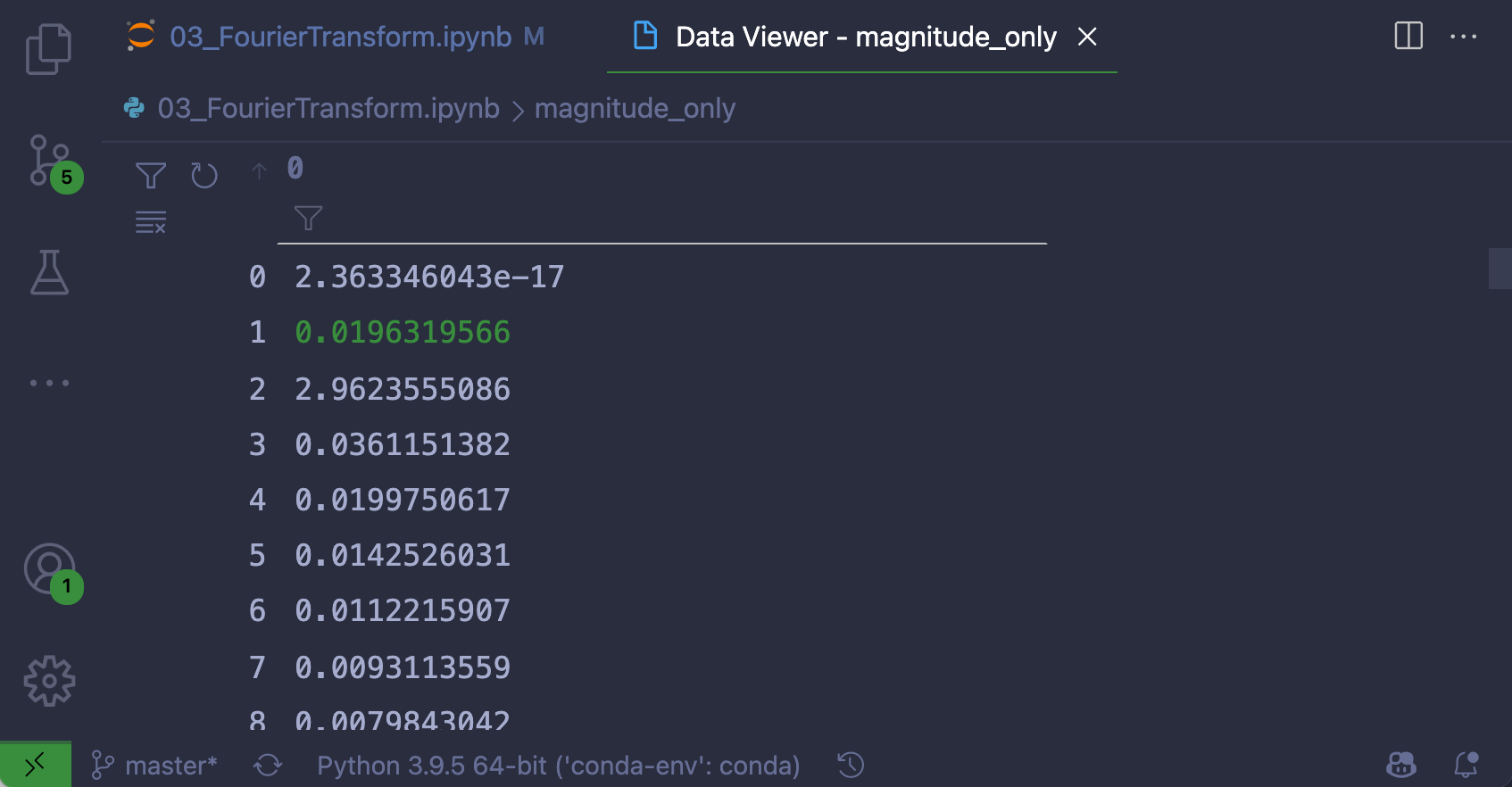
要访问数据查看器,您可以点击在数据查看器中显示变量,在变量视图中展开复杂变量。该选项由一个图标表示,该图标显示在代表复杂变量的行的左侧:
data viewer 支持对大型数据集进行在线过滤和分页。如果您在 Matplotlib 中绘制大型数据集,Jupyter 扩展支持 Matplotlib 小部件而不是 SVG 呈现。
使用 Rainbow CSV 扩展
如果您处理 CSV 或 TSV 输入数据,有一个有用的扩展叫做 Rainbow CSV ( mechatroner.rainbow-csv ) ,它使您能够在 VS 代码中打开并可视化 CSV 文件:
每一列都是彩色的,让您可以快速找到遗漏的逗号。您也可以通过从命令面板运行Rainbow CSV: Align CSV Columns命令来对齐所有列。
**注意:**如果你正在寻找一个示例 CSV 文件来尝试这个扩展,你可以从新西兰政府的官方统计页面选择一个 CSV 文件来下载。
Rainbow CSV 扩展还附带了一个Rainbow Query Language(RBQL)查询工具,允许您对 CSV 数据编写 RBQL 查询,以创建过滤数据集:
您可以通过在命令面板中运行Rainbow CSV: RBQL来访问 RBQL 控制台。执行查询后,您将在新的选项卡中看到作为临时 CSV 文件的结果,您可以保存该文件并将其用于进一步的数据分析工作。
在本教程中,您已经为 VS 代码安装了几个有用的扩展。有许多有用的扩展可用。在本教程的最后一节,您将了解到一些到目前为止还没有涉及到的额外扩展,您可能也想尝试一下。
向 Visual Studio 代码添加额外的扩展
VS 代码市场有数千个扩展。扩展的选择涵盖了从语言支持,主题,拼写检查,甚至小游戏。
到目前为止,在本教程中,您已经介绍了许多扩展,这些扩展使 Visual Studio 代码中的 Python 开发更加强大。这最后四个扩展是可选的——但是可以让您的生活更轻松。
代码拼写检查器
代码拼写检查器(streetsidesoftware.code-spell-checker ) 是一个检查变量名、字符串中的文本和 Python 文档字符串的拼写检查器:

代码拼写检查扩展将突出任何可疑的拼写错误。您可以从字典中更正拼写,也可以将单词添加到用户或工作区字典中。
工作区字典将位于工作区文件夹中,因此您可以将其签入 Git。用户字典在所有项目中都是持久的。如果有很多经常使用的关键词和短语,您可以将它们添加到用户词典中。
码头工人
Docker 扩展(ms-azuretools.vscode-docker ) 使创建、管理和调试容器化的应用程序变得容易:
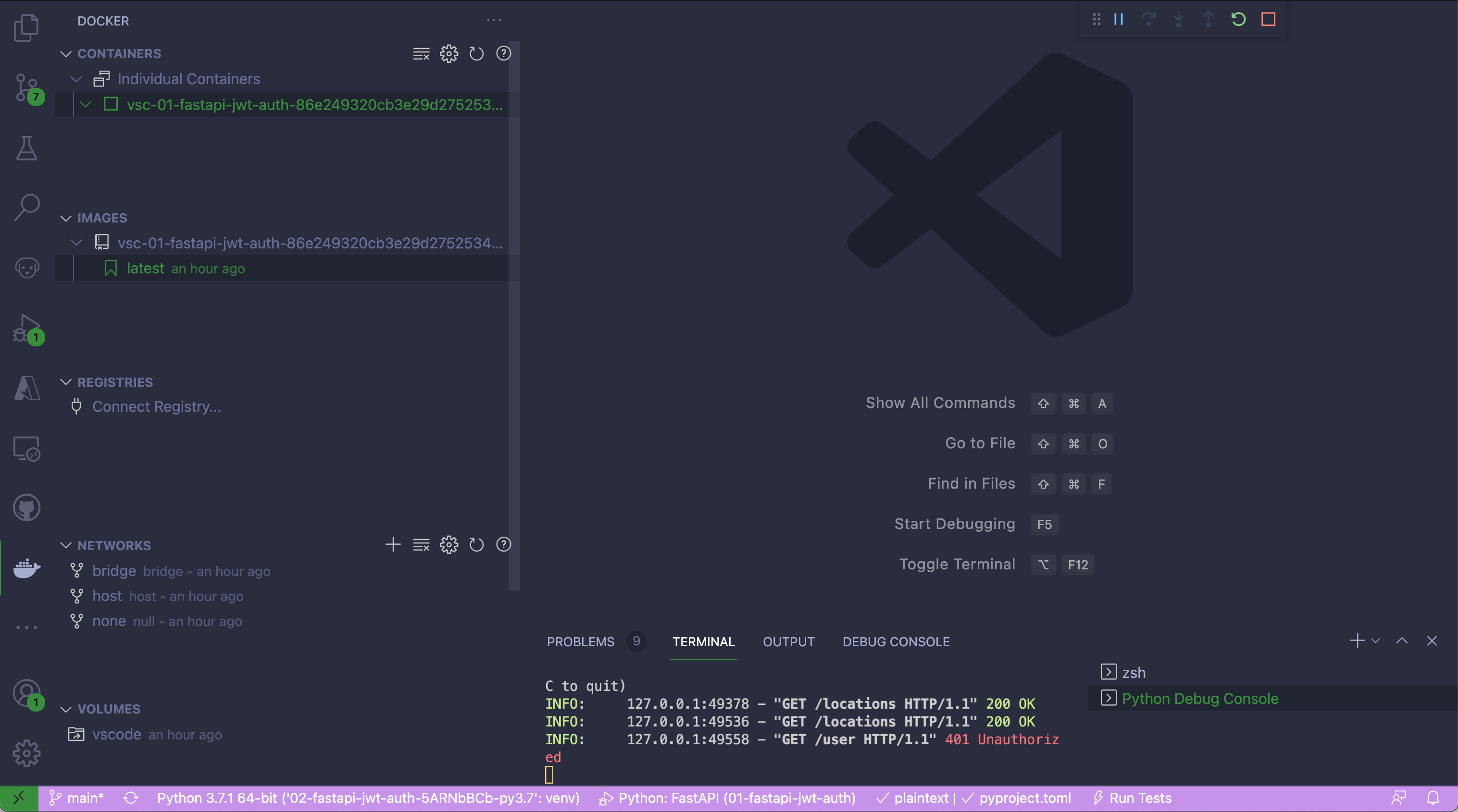
Docker 扩展超出了您之前介绍的远程容器扩展。它为您提供了一个管理映像、网络、容器注册表、卷和容器的 UI。
迅雷客户端
Thunder Client ( rangav.vscode-thunder-client ) 是一个 HTTP 客户端和 VS 代码 UI,旨在帮助测试 REST APIs。如果你在像 Flask 、 FastAPI 或 Django Rest Framework 这样的框架中开发和测试 API,你可能已经使用了像 Postman 或 curl 这样的工具来测试你的应用程序。
在 Thunder Client 中,您可以创建 HTTP 请求并将其发送到您的 API,操作标头,以及设置文本、XML 和 JSON 的有效负载:
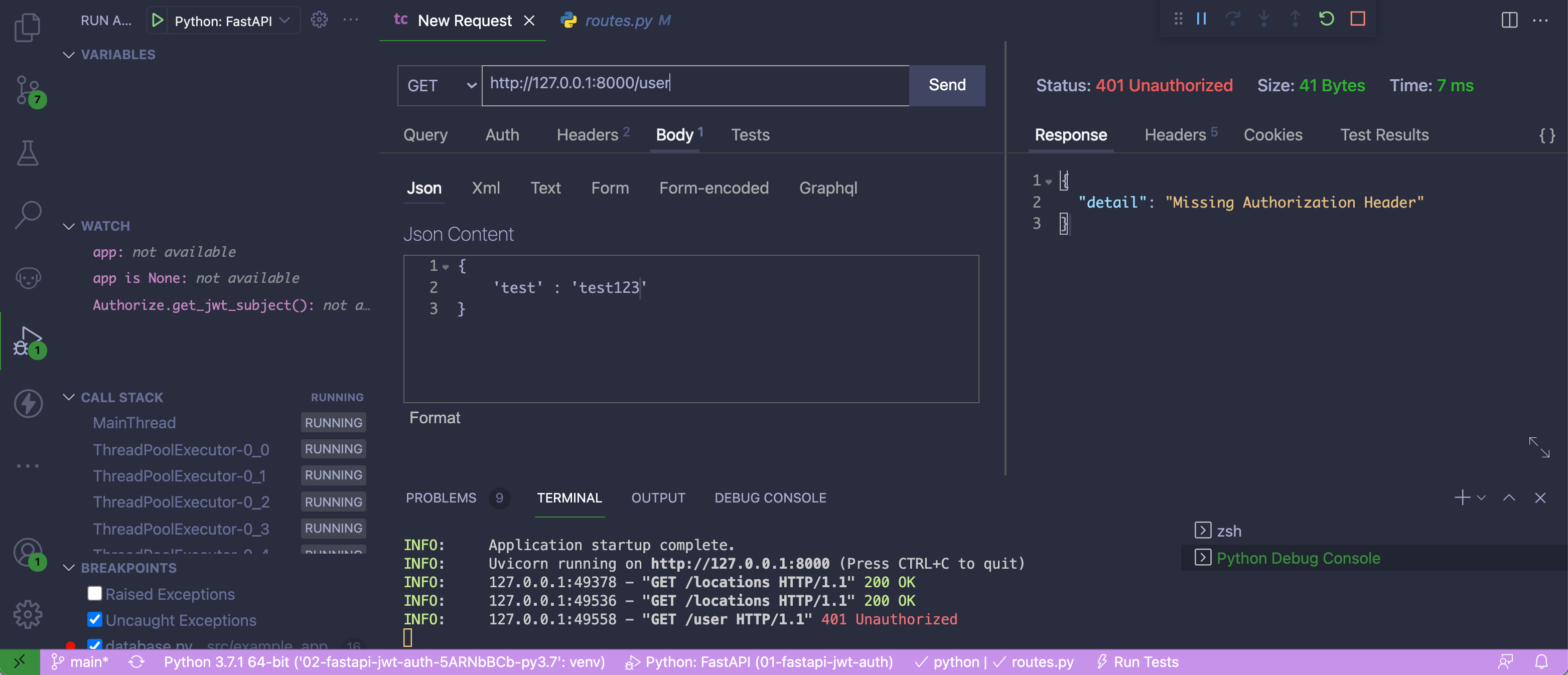
Thunder Client 是 Postman 或 curl 的一个很好的替代品,因为您可以直接在 VS 代码中使用它,所以在测试和开发 REST APIs 时,您可以避免在应用程序之间切换。
VS 代码宠物
VS 代码宠物(tonybaloney.vscode-pets ) 是一个有趣的扩展,可以在你的 VS 代码窗口中放置一个或多个小宠物:

你可以定制宠物,定制它们的环境,和它们一起玩游戏。
**注意:**作为本教程的作者,我要说这是一个很棒的扩展——但我可能会有偏见,因为我创建了它。
这只是市场上扩展的一个快照。还有成千上万的其他语言支持、UI 改进,甚至是 Spotify 集成。
结论
Visual Studio Code 的 Python 工具正在快速发展,该团队每月都会发布错误修复和新功能的更新。确保安装任何新的更新,以保持您的环境处于最新和最佳状态。
在本教程中,您已经看到了 Visual Studio 代码中一些更高级特性的概述,Python 和 Jupyter 扩展,以及一些额外的扩展。
您学习了如何:
- 用灵活的 UI 定制和键盘绑定定制你的用户界面
- 通过将测试框架集成到 Visual Studio 代码中来运行和监控 Python 测试
- 棉绒和格式代码带挂架和外部棉绒
- 调试本地和远程环境通过 SSH 和 Docker
- 旋转数据科学工具以使用 Jupyter 笔记本
您可以利用这些知识让自己走上成为 VS Code power 用户的道路。
在下一个项目中,尝试这些扩展并测试它们。你会发现一些 VS 代码特性对你来说比其他的更有用。一旦你对一些定制和扩展有了感觉,你可能会发现自己在 VS 代码文档中寻找更多甚至是编码你自己的扩展!**********


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









