







 本博客介绍使用NumPy构建和训练小型神经网络对MNIST手写数字分类。涵盖加载和预处理数据集,用NumPy构建神经网络基本组件,如层、权重、激活函数等,还给出训练过程及结果。最后提供优化模型的方法和开发模型时需考虑的伦理问题。
本博客介绍使用NumPy构建和训练小型神经网络对MNIST手写数字分类。涵盖加载和预处理数据集,用NumPy构建神经网络基本组件,如层、权重、激活函数等,还给出训练过程及结果。最后提供优化模型的方法和开发模型时需考虑的伦理问题。
文章目录
本教程演示了如何使用 NumPy 构建一个简单的前馈神经网络(带有一个隐藏层),并从头开始训练它,以识别手写数字图像。
您的深度学习模型是最基本的人工神经网络之一,类似于原始的多层感知器,它将学习从 MNIST 数据集中分类数字 0 到 9。该数据集包含 60,000 个训练图像和 10,000 个测试图像以及相应的标签。每个训练和测试图像的大小为 784(或 28x28 像素)- 这将是神经网络的输入。
基于图像输入及其标签(监督学习),您的神经网络将通过前向传播和反向传播(反向模式微分)来学习它们的特征。网络的最终输出是一个包含 10 个分数的向量 - 每个手写数字图像对应一个分数。您还将评估您的模型在测试集上对图像进行分类的能力。
本教程是根据 Andrew Trask 的工作进行调整的(经过作者许可)。
先决条件
读者应该具备一些 Python、NumPy 数组操作和线性代数的知识。此外,您应该熟悉深度学习的主要概念。
为了恢复记忆,您可以参考 Python 和 n 维数组上的线性代数 教程。
建议您阅读由 Yann LeCun、Yoshua Bengio 和 Geoffrey Hinton 在 2015 年发表的 深度学习 论文,他们被认为是该领域的先驱之一。您还应该考虑阅读 Andrew Trask 的 Grokking Deep Learning,该书使用 NumPy 教授深度学习。
除了 NumPy,您还将使用以下 Python 标准模块来加载和处理数据:
-
urllib用于处理 URL -
request用于打开 URL -
gzip用于解压缩 gzip 文件 -
pickle用于处理 pickle 文件格式以及:
-
Matplotlib 用于数据可视化
本教程可以在隔离的环境中本地运行,例如 Virtualenv 或 conda。您可以使用 Jupyter Notebook 或 JupyterLab 来运行每个笔记本单元格。不要忘记设置 NumPy 和 Matplotlib。
目录
- 加载 MNIST 数据集
- 预处理数据集
- 从头构建和训练一个小型神经网络
- 下一步
1. 加载 MNIST 数据集
在本节中,您将下载最初存储在 Yann LeCun 的网站 上的压缩 MNIST 数据集文件。然后,您将使用内置的 Python 模块将它们转换为 4 个 NumPy 数组类型的文件。最后,您将把这些数组分割成训练集和测试集。
1. 定义一个变量,将 MNIST 数据集的训练/测试图像/标签名称存储在一个列表中:
data_sources = {
"training_images": "train-images-idx3-ubyte.gz", # 60,000 个训练图像。
"test_images": "t10k-images-idx3-ubyte.gz", # 10,000 个测试图像。
"training_labels": "train-labels-idx1-ubyte.gz", # 60,000 个训练标签。
"test_labels": "t10k-labels-idx1-ubyte.gz", # 10,000 个测试标签。
}
2. 加载数据。首先检查数据是否存储在本地;如果没有,则下载它。
import requests
import os
data_dir = "../_data"
os.makedirs(data_dir, exist_ok=True)
base_url = "https://github.com/rossbar/numpy-tutorial-data-mirror/blob/main/"
for fname in data_sources.values():
fpath = os.path.join(data_dir, fname)
if not os.path.exists(fpath):
print("Downloading file: " + fname)
resp = requests.get(base_url + fname, stream=True, **request_opts)
resp.raise_for_status() # 确保下载成功
with open(fpath, "wb") as fh:
for chunk in resp.iter_content(chunk_size=128):
fh.write(chunk)
3. 解压缩这 4 个文件,并创建 4 个 ndarrays,将它们保存到一个字典中。每个原始图像的大小为 28x28,神经网络通常期望一个 1D 向量输入;因此,您还需要通过将 28 乘以 28(784)来重塑图像。
import gzip
import numpy as np
mnist_dataset = {}
# 图像
for key in ("training_images", "test_images"):
with gzip.open(os.path.join(data_dir, data_sources[key]), "rb") as mnist_file:
mnist_dataset[key] = np.frombuffer(
mnist_file.read(), np.uint8, offset=16
).reshape(-1, 28 * 28)
# 标签
for key in ("training_labels", "test_labels"):
with gzip.open(os.path.join(data_dir, data_sources[key]), "rb") as mnist_file:
mnist_dataset[key] = np.frombuffer(mnist_file.read(), np.uint8, offset=8)
4. 使用标准符号 x 表示数据,y 表示标签,将数据分割为训练集和测试集,将训练集图像称为 x_train,测试集图像称为 x_test,标签称为 y_train 和 y_test:
x_train, y_train, x_test, y_test = (
mnist_dataset["training_images"],
mnist_dataset["training_labels"],
mnist_dataset["test_images"],
mnist_dataset["test_labels"],
)
5. 您可以确认图像数组的形状分别为 (60000, 784) 和 (10000,784),标签的形状为 (60000,) 和 (10000,):
print(
"训练图像的形状:{},训练标签的形状:{}".format(
x_train.shape, y_train.shape
)
)
print(
"测试图像的形状:{},测试标签的形状:{}".format(
x_test.shape, y_test.shape
)
)
训练图像的形状:(60000, 784),训练标签的形状:(60000,)
测试图像的形状:(10000, 784),测试标签的形状:(10000,)
6. 您可以使用 Matplotlib 查看一些图像:
import matplotlib.pyplot as plt
# 从训练集中取第 60,000 张图像(索引为 59,999),将其从 (784, ) 重塑为 (28, 28),以便显示。
mnist_image = x_train[59999, :].reshape(28, 28)
# 将颜色映射设置为灰度,以获得黑色背景。
plt.imshow(mnist_image, cmap="gray")
# 显示图像。
plt.show()
# 显示来自训练集的 5 个随机图像。
num_examples = 5
seed = 147197952744
rng = np.random.default_rng(seed)
fig, axes = plt.subplots(1, num_examples)
for sample, ax in zip(rng.choice(x_train, size=num_examples, replace=False), axes):
ax.imshow(sample.reshape(28, 28), cmap="gray")
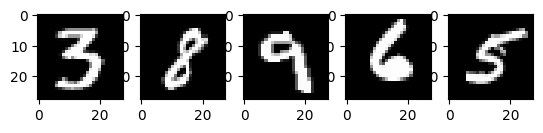
上面是从 MNIST 训练集中选取的五个图像。显示了各种手绘的阿拉伯数字,每次运行代码时都会随机选择确切的值。
注意: 您还可以通过打印
x_train[59999]将样本图像作为数组进行可视化。这里,59999是您的第 60,000 张训练图像样本(0是第一张)。您的输出将非常长,并且应该包含一个 8 位整数数组:... 0, 0, 38, 48, 48, 22, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 62, 97, 198, 243, 254, 254, 212, 27, 0, 0, 0, 0, ...
# 显示训练集中第 60,000 张图像(索引为 59,999)的标签。
y_train[59999]
8
2. 预处理数据
神经网络可以处理浮点类型的张量(多维数组)输入。在预处理数据时,您应该考虑以下过程:向量化和转换为浮点格式。
由于 MNIST 数据已经向量化,并且数组的 dtype 是 uint8,您的下一个挑战是将它们转换为浮点格式,例如 float64(双精度):
- 图像标签的独热编码/分类编码。
在实践中,您可以根据目标选择不同类型的浮点精度,您可以在Nvidia和Google Cloud的博客文章中找到更多信息。
将图像数据转换为浮点格式
图像数据包含在[0, 255]区间内的8位整数,颜色值介于0和255之间。
您将通过将它们除以255将它们归一化为[0, 1]区间内的浮点数组。
1. 检查向量化的图像数据的类型是否为uint8:
print("训练图像的数据类型:{}".format(x_train.dtype))
print("测试图像的数据类型:{}".format(x_test.dtype))
训练图像的数据类型:uint8
测试图像的数据类型:uint8
2. 通过将它们除以255(从而将数据类型从uint8提升为float64),然后将训练和测试图像数据变量(x_train和x_test)分别赋值给training_images和train_labels。为了在这个例子中减少模型训练和评估时间,只使用训练和测试图像的子集。training_images和test_images将分别包含完整数据集中的1,000个样本,其中完整数据集分别包含60,000个和10,000个图像。可以通过更改training_sample和test_sample来控制这些值,最大值分别为60,000和10,000。
training_sample, test_sample = 1000, 1000
training_images = x_train[0:training_sample] / 255
test_images = x_test[0:test_sample] / 255
3. 确认图像数据已更改为浮点格式:
print("训练图像的数据类型:{}".format(training_images.dtype))
print("测试图像的数据类型:{}".format(test_images.dtype))
训练图像的数据类型:float64
测试图像的数据类型:float64
**注意:**您还可以通过在笔记本单元格中打印
training_images[0]来检查归一化是否成功。您的输出应包含一个浮点数数组:... 0. , 0. , 0.01176471, 0.07058824, 0.07058824, 0.07058824, 0.49411765, 0.53333333, 0.68627451, 0.10196078, 0.65098039, 1. , 0.96862745, 0.49803922, 0. , ...
通过分类/独热编码将标签转换为浮点数
您将使用独热编码将每个数字标签嵌入为全零向量,并在标签索引处放置1。因此,您的标签数据将是具有每个图像标签位置上的1.0(或1.)的数组。
由于总共有10个标签(从0到9),您的数组将类似于以下内容:
array([0., 0., 0., 0., 0., 1., 0., 0., 0., 0.])
1. 确认图像标签数据为整数,具有dtype为uint8:
print("训练标签的数据类型:{}".format(y_train.dtype))
print("测试标签的数据类型:{}".format(y_test.dtype))
训练标签的数据类型:uint8
测试标签的数据类型:uint8
2. 定义一个在数组上执行独热编码的函数:
def one_hot_encoding(labels, dimension=10):
# 为10维度(数字标签从0到9)的全零向量定义一个独热变量。
one_hot_labels = labels[..., None] == np.arange(dimension)[None]
# 返回独热编码的标签。
return one_hot_labels.astype(np.float64)
3. 对标签进行编码,并将值分配给新变量:
training_labels = one_hot_encoding(y_train[:training_sample])
test_labels = one_hot_encoding(y_test[:test_sample])
4. 检查数据类型是否已更改为浮点数:
print("训练标签的数据类型:{}".format(training_labels.dtype))
print("测试标签的数据类型:{}".format(test_labels.dtype))
训练标签的数据类型:float64
测试标签的数据类型:float64
5. 检查一些编码后的标签:
print(training_labels[0])
print(training_labels[1])
print(training_labels[2])
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
…并与原始标签进行比较:
print(y_train[0])
print(y_train[1])
print(y_train[2])
5
0
4
您已经完成了数据集的准备工作。
3. 从头构建和训练一个小型神经网络
在本节中,您将熟悉深度学习模型的基本构建块的一些高级概念。您可以参考原始的深度学习研究论文获取更多信息。
然后,您将使用Python和NumPy构建一个简单的深度学习模型的构建块,并训练它以在MNIST数据集中识别手写数字并达到一定的准确度。
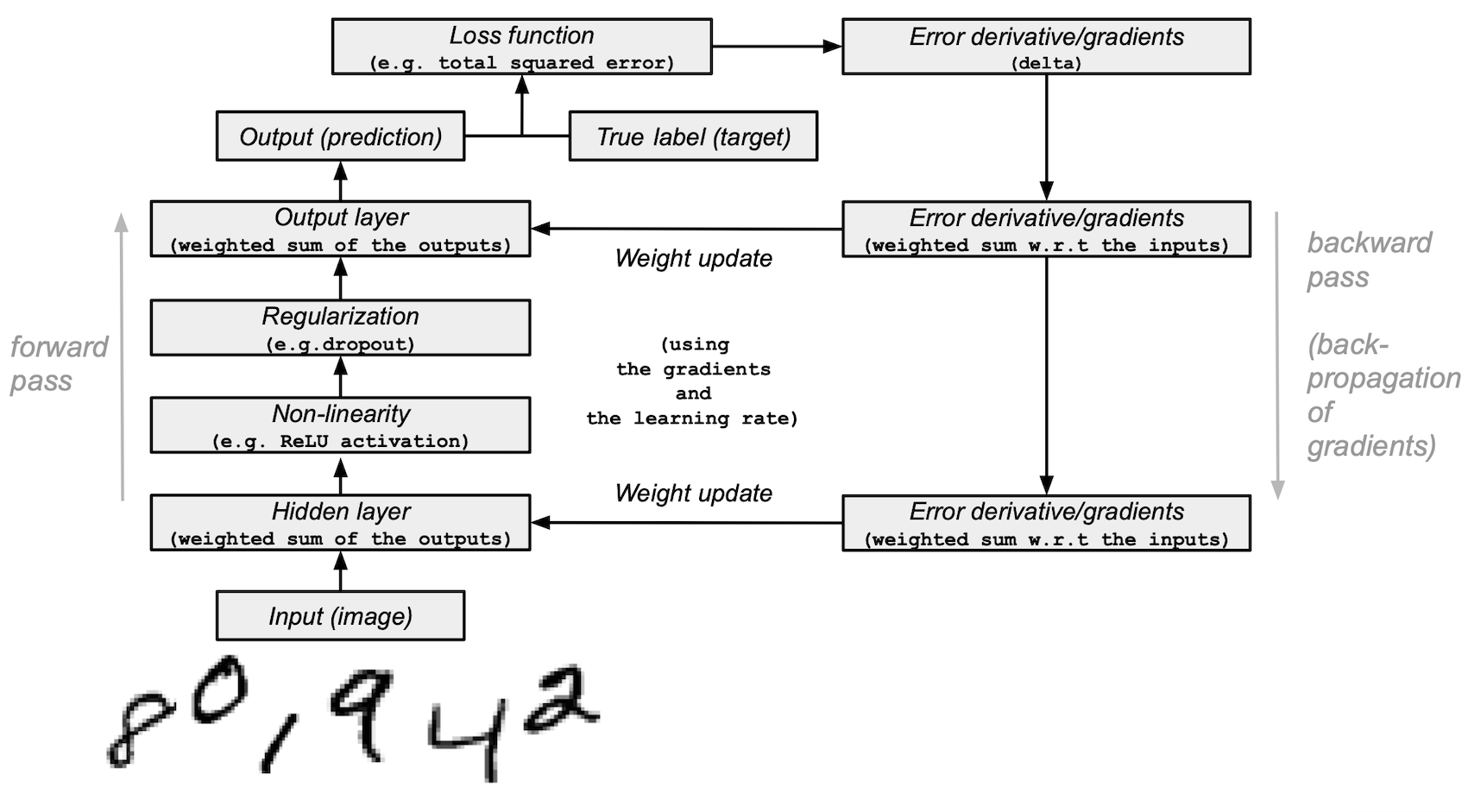
使用NumPy的神经网络构建块
-
层:这些构建块作为数据过滤器工作-它们处理数据并学习从输入中提取表示以更好地预测目标输出。
在您的模型中,您将使用1个隐藏层来将输入向前传递(前向传播)并将损失函数的梯度/误差导数向后传播(反向传播)。这些是输入、隐藏和输出层。
在隐藏(中间)和输出(最后)层中,神经网络模型将计算输入的加权和。为了计算这个过程,您将使用NumPy的矩阵乘法函数(“点乘”或
np.dot(layer,weights))。**注意:**为了简单起见,这个例子中省略了偏差项(没有
np.dot(layer, weights) + bias)。 -
权重:这些是通过前向和反向传播数据来微调的重要可调参数。它们通过一种称为梯度下降的过程进行优化。在模型训练开始之前,权重会用NumPy的
Generator.random()随机初始化。最佳权重应产生最高的预测准确度和最低的训练和测试集上的误差。
-
激活函数:深度学习模型能够确定输入和输出之间的非线性关系,这些非线性函数通常应用于每个层的输出。
您将使用修正线性单元(ReLU)应用于隐藏层的输出(例如,
relu(np.dot(layer, weights)))。 -
在这个例子中,您将使用一种称为dropout的方法-稀疏化,它将一个层中的一些特征随机设置为0。您将使用NumPy的
Generator.integers()方法定义它,并将其应用于网络的隐藏层。 -
损失函数:通过将图像标签(真实值)与最后一层输出的预测值进行比较,计算预测的质量。
为了简单起见,您将使用基本的总平方误差,使用NumPy的
np.sum()函数进行计算(例如,np.sum((final_layer_output - image_labels) ** 2))。 -
准确度:这个指标衡量网络在未见过的数据上进行预测的准确性。
模型架构和训练摘要
以下是神经网络模型架构和训练过程的摘要:
-
输入层:
这是网络的输入-之前经过预处理的从
training_images加载到layer_0中的数据。 -
隐藏(中间)层:
layer_1获取前一层的输出,并通过NumPy的np.dot()对输入进行矩阵乘法(weights_1)。然后,将此输出通过ReLU激活函数进行非线性处理,然后应用dropout以帮助防止过拟合。
-
输出(最后)层:
layer_2接收layer_1的输出,并使用weights_2进行相同的“点乘”过程。最终输出返回每个0-9数字标签的10个分数。网络模型以一个大小为10的层结束-一个10维向量。
-
前向传播、反向传播、训练循环:
在模型训练开始时,您的网络随机初始化权重,并将输入数据前向传递到隐藏和输出层。这个过程称为前向传递或前向传播。
然后,网络将从损失函数中向后传播“信号”通过隐藏层,并通过学习率参数的帮助调整权重值(稍后会详细介绍)。
**注意:**更具体地说,您:
构建模型并开始训练和测试
在介绍了主要的深度学习概念和神经网络架构之后,让我们来编写代码。
1. 首先,我们创建一个新的随机数生成器,并提供一个种子以确保可重复性:
seed = 884736743
rng = np.random.default_rng(seed)
2. 对于隐藏层,定义前向传播的 ReLU 激活函数以及在反向传播过程中将使用的 ReLU 的导数:
# 定义 ReLU 函数,如果输入为正数则返回输入,否则返回 0。
def relu(x):
return (x >= 0) * x
# 设置 ReLU 函数的导数,对于正数输入返回 1,否则返回 0。
def relu2deriv(output):
return output >= 0
3. 设置一些超参数的默认值,例如:
- 学习率:
learning_rate— 用于限制权重更新的幅度,以防止过度修正。 - 迭代次数:
epochs— 数据通过网络的完整传递(前向传播和反向传播)的次数。该参数可能对结果产生积极或消极的影响。迭代次数越多,学习过程可能需要的时间越长。由于这是一个计算密集型的任务,我们选择了一个非常低的迭代次数(20)。为了得到有意义的结果,您应该选择一个更大的数字。 - 网络中隐藏(中间)层的大小:
hidden_size— 隐藏层的不同大小可能会影响训练和测试的结果。 - 输入的大小:
pixels_per_image— 您已经确定图像输入为 784(28x28)(以像素为单位)。 - 标签的数量:
num_labels— 表示输出层的输出数字,其中包含 10 个(0 到 9)手写数字标签。
learning_rate = 0.005
epochs = 20
hidden_size = 100
pixels_per_image = 784
num_labels = 10
4. 使用随机值初始化隐藏层和输出层中将使用的权重向量:
weights_1 = 0.2 * rng.random((pixels_per_image, hidden_size)) - 0.1
weights_2 = 0.2 * rng.random((hidden_size, num_labels)) - 0.1
5. 设置神经网络的学习实验,包括训练循环,并开始训练过程。请注意,模型在每个 epoch 中针对测试集进行评估,以跟踪其在训练 epoch 中的性能。
开始训练过程:
# 用于存储训练集和测试集的损失和准确预测的列表,以便可视化。
store_training_loss = []
store_training_accurate_pred = []
store_test_loss = []
store_test_accurate_pred = []
# 这是一个训练循环。
# 对于指定的迭代次数(epoch),运行学习实验。
for j in range(epochs):
#################
# 训练步骤 #
#################
# 将初始损失/错误和准确预测数设置为零。
training_loss = 0.0
training_accurate_predictions = 0
# 对于训练集中的所有图像,执行前向传播和反向传播,并相应地调整权重。
for i in range(len(training_images)):
# 前向传播/前向传递:
# 1. 输入层:
# 将训练图像数据初始化为输入。
layer_0 = training_images[i]
# 2. 隐藏层:
# 通过将其与随机初始化的权重进行矩阵乘法,将训练图像数据传入中间层。
layer_1 = np.dot(layer_0, weights_1)
# 3. 将隐藏层的输出通过 ReLU 激活函数。
layer_1 = relu(layer_1)
# 4. 为正则化定义 dropout 函数。
dropout_mask = rng.integers(low=0, high=2, size=layer_1.shape)
# 5. 将 dropout 应用于隐藏层的输出。
layer_1 *= dropout_mask * 2
# 6. 输出层:
# 通过将其与随机初始化的权重进行矩阵乘法,将中间层的输出传入最后一层。
# 生成一个具有 10 个分数的 10 维向量。
layer_2 = np.dot(layer_1, weights_2)
# 反向传播/反向传递:
# 1. 计算实际图像标签(真实值)和模型预测之间的训练误差(损失函数)。
training_loss += np.sum((training_labels[i] - layer_2) ** 2)
# 2. 增加准确预测计数。
training_accurate_predictions += int(
np.argmax(layer_2) == np.argmax(training_labels[i])
)
# 3. 计算损失函数/错误的导数。
layer_2_delta = training_labels[i] - layer_2
# 4. 将损失函数的梯度传播回隐藏层。
layer_1_delta = np.dot(weights_2, layer_2_delta) * relu2deriv(layer_1)
# 5. 将 dropout 应用于梯度。
layer_1_delta *= dropout_mask
# 6. 通过将学习率和梯度相乘,更新中间层和输入层的权重。
weights_1 += learning_rate * np.outer(layer_0, layer_1_delta)
weights_2 += learning_rate * np.outer(layer_1, layer_2_delta)
# 存储训练集的损失和准确预测。
store_training_loss.append(training_loss)
store_training_accurate_pred.append(training_accurate_predictions)
###################
# 评估步骤 #
###################
# 在每个 epoch 中评估模型在测试集上的性能。
# 与训练步骤不同,权重不会针对每个图像(或批次)进行修改。
# 因此,可以以矢量化的方式将模型应用于测试图像,而无需逐个图像循环:
results = relu(test_images @ weights_1) @ weights_2
# 计算实际标签(真实值)和预测值之间的误差。
test_loss = np.sum((test_labels - results) ** 2)
# 计算测试集上的准确预测数
test_accurate_predictions = np.sum(
np.argmax(results, axis=1) == np.argmax(test_labels, axis=1)
)
# 存储测试集的损失和准确预测。
store_test_loss.append(test_loss)
store_test_accurate_pred.append(test_accurate_predictions)
# 在每个 epoch 中总结错误和准确性指标
print(
(
f"Epoch: {j}\n"
f" 训练集错误: {training_loss / len(training_images):.3f}\n"
f" 训练集准确率: {training_accurate_predictions / len(training_images)}\n"
f" 测试集错误: {test_loss / len(test_images):.3f}\n"
f" 测试集准确率: {test_accurate_predictions / len(test_images)}"
)
)
Epoch: 0
训练集错误: 0.898
训练集准确率: 0.397
测试集错误: 0.680
测试集准确率: 0.582
Epoch: 1
训练集错误: 0.656
训练集准确率: 0.633
测试集错误: 0.607
测试集准确率: 0.641
Epoch: 2
训练集错误: 0.592
训练集准确率: 0.68
测试集错误: 0.569
测试集准确率: 0.679
Epoch: 3
训练集错误: 0.556
训练集准确率: 0.7
测试集错误: 0.541
测试集准确率: 0.708
Epoch: 4
训练集错误: 0.534
训练集准确率: 0.732
测试集错误: 0.526
测试集准确率: 0.729
Epoch: 5
训练集错误: 0.515
训练集准确率: 0.715
测试集错误: 0.500
测试集准确率: 0.739
Epoch: 6
训练集错误: 0.495
训练集准确率: 0.748
测试集错误: 0.487
测试集准确率: 0.753
Epoch: 7
训练集错误: 0.483
训练集准确率: 0.769
测试集错误: 0.486
测试集准确率: 0.747
Epoch: 8
训练集错误: 0.473
训练集准确率: 0.776
测试集错误: 0.473
测试集准确率: 0.752
Epoch: 9
训练集错误: 0.460
训练集准确率: 0.788
测试集错误: 0.462
测试集准确率: 0.762
Epoch: 10
训练集错误: 0.465
训练集准确率: 0.769
测试集错误: 0.462
测试集准确率: 0.767
Epoch: 11
训练集错误: 0.443
训练集准确率: 0.801
测试集错误: 0.456
测试集准确率: 0.775
Epoch: 12
训练集错误: 0.448
训练集准确率: 0.795
测试集错误: 0.455
测试集准确率: 0.772
Epoch: 13
训练集错误: 0.438
训练集准确率: 0.787
测试集错误: 0.453
测试集准确率: 0.778
Epoch: 14
训练集错误: 0.446
训练集准确率: 0.791
测试集错误: 0.450
测试集准确率: 0.779
Epoch: 15
训练集错误: 0.441
训练集准确率: 0.788
测试集错误: 0.452
测试集准确率: 0.772
Epoch: 16
训练集错误: 0.437
训练集准确率: 0.786
测试集错误: 0.453
测试集准确率: 0.772
Epoch: 17
训练集错误: 0.436
训练集准确率: 0.794
测试集错误: 0.449
测试集准确率: 0.778
Epoch: 18
训练集错误: 0.433
训练集准确率: 0.801
测试集错误: 0.450
测试集准确率: 0.774
第19轮
训练集误差:0.429
训练集准确率:0.785
测试集误差:0.436
测试集准确率:0.784
训练过程可能需要很多分钟,具体取决于多个因素,例如运行实验的机器的处理能力和迭代次数。为了减少等待时间,您可以将迭代次数从100更改为较低的数字,重置运行时(这将重置权重),然后再次运行笔记本单元格。
在执行上面的单元格后,您可以可视化此训练过程的训练集和测试集的误差和准确率。
```python
epoch_range = np.arange(epochs) + 1 # 从1开始
# 训练集指标
training_metrics = {
"accuracy": np.asarray(store_training_accurate_pred) / len(training_images),
"error": np.asarray(store_training_loss) / len(training_images),
}
# 测试集指标
test_metrics = {
"accuracy": np.asarray(store_test_accurate_pred) / len(test_images),
"error": np.asarray(store_test_loss) / len(test_images),
}
# 显示图表
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 5))
for ax, metrics, title in zip(
axes, (training_metrics, test_metrics), ("训练集", "测试集")
):
# 绘制指标
for metric, values in metrics.items():
ax.plot(epoch_range, values, label=metric.capitalize())
ax.set_title(title)
ax.set_xlabel("迭代次数")
ax.legend()
plt.show()
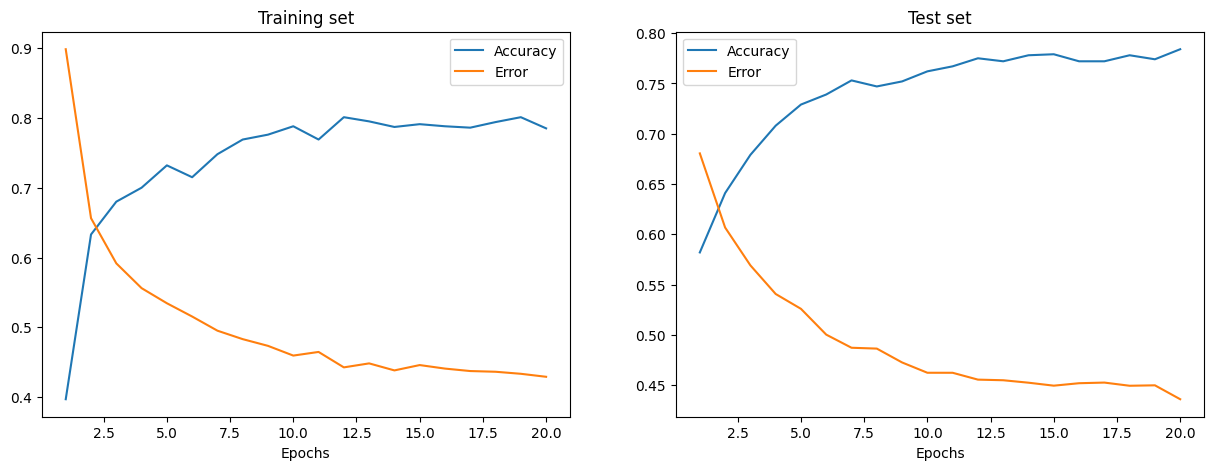
上图显示了左侧和右侧的训练和测试误差。随着迭代次数的增加,总误差减小,准确率增加。
您的模型在训练和测试过程中达到的准确率可能是合理的,但您可能会发现错误率相当高。
为了减少训练和测试过程中的错误,您可以考虑将简单的损失函数更改为例如分类的交叉熵。下面讨论了其他可能的解决方案。
下一步
您已经学会了如何使用NumPy从头开始构建和训练一个简单的前馈神经网络,以对手写的MNIST数字进行分类。
为了进一步增强和优化您的神经网络模型,您可以考虑以下一种或多种方法:
- 将训练样本数量从1,000增加到更高的数字(最多60,000)。
- 使用小批量和降低学习率。
- 通过引入更多隐藏层来改变架构,使网络变得更深。
- 将交叉熵损失函数与最后一层的softmax激活函数相结合。
- 引入卷积层:用卷积神经网络架构替换前馈网络。
- 使用更大的迭代次数进行更长时间的训练,并添加更多的正则化技术,例如提前停止,以防止过拟合。
- 为了对模型拟合进行公正评估,引入验证集。
- 应用批量归一化以实现更快、更稳定的训练。
- 调整其他参数,如学习率和隐藏层大小。
使用NumPy从头开始构建神经网络是学习更多关于NumPy和深度学习的好方法。然而,对于实际应用,您应该使用专门的框架,如PyTorch、JAX、TensorFlow或MXNet,它们提供类似于NumPy的API,具有内置的自动微分和GPU支持,并且专为高性能数值计算和机器学习而设计。
最后,在开发机器学习模型时,您应该考虑潜在的伦理问题,并采取措施避免或减轻这些问题:
- 使用模型卡片记录已训练的模型 - 参见Margaret Mitchell等人的模型报告的模型卡片论文。
- 使用数据表格记录数据集 - 参见Timnit Gebru等人的数据集数据表格论文。
- 考虑模型的影响 - 谁受到影响,谁从中受益 - 参见Pratyusha Kalluri的文章和演讲。
- 更多资源,请参见Rachel Thomas的博文和Radical AI podcast。


















 371
371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











