








文章目录
前言
自从前两天搞懂self-attention机制后,attention is all you need 萦绕耳畔,attention机制仔细品味,真的是令人拍案。接下来,transformer的设计足够创新,抛弃了传统的RNN,并且取得了非常好的效果,所以,我迫不及待的想探寻Transformer的底层,于是参考了网上的代码,写了一篇代码解读文章【手撕Transformer】Transformer输入输出细节以及代码实现(pytorch),了解了许多技术性细节,而在本篇文章中,我将对Transformer的思想,以及本人对Transformer的理解分享给大家。
模型特点
传统seq2seq最大的问题在于将Encoder端的所有信息压缩到一个固定长度的向量中,并将其作为Decoder端首个隐藏状态的输入,来预测Decoder端第一个单词(token)的隐藏状态。在输入序列比较长的时候,这样做显然会损失Encoder端的很多信息,而且这样一股脑的把该固定向量送入Decoder端,Decoder端不能够关注到其想要关注的信息。并且模型计算不可并行,计算隐层状态 h t h_{t} ht 依赖于 h t − 1 h_{t-1} ht−1 以及状态 t t t 时刻的输入,因此需要耗费大量时间。
Transformer优点:transformer架构完全依赖于Attention机制,解决了输入输出的长期依赖问题,并且拥有并行计算的能力,大大减少了计算资源的消耗。self-attention模块,让源序列和目标序列首先“自关联”(也就是cross attention)起来,这样的话,源序列和目标序列自身的embedding表示所蕴含的信息更加丰富,而且后续的FFN层也增强了模型的表达能力。Muti-Head Attention模块使得Encoder端拥有并行计算的能力
从宏观看
首先将这个模型看成是一个黑箱操作。在机器翻译中,就是输入一种语言,输出另一种语言。

那么拆开这个黑箱,我们可以看到它是由编码组件、解码组件和它们之间的连接组成
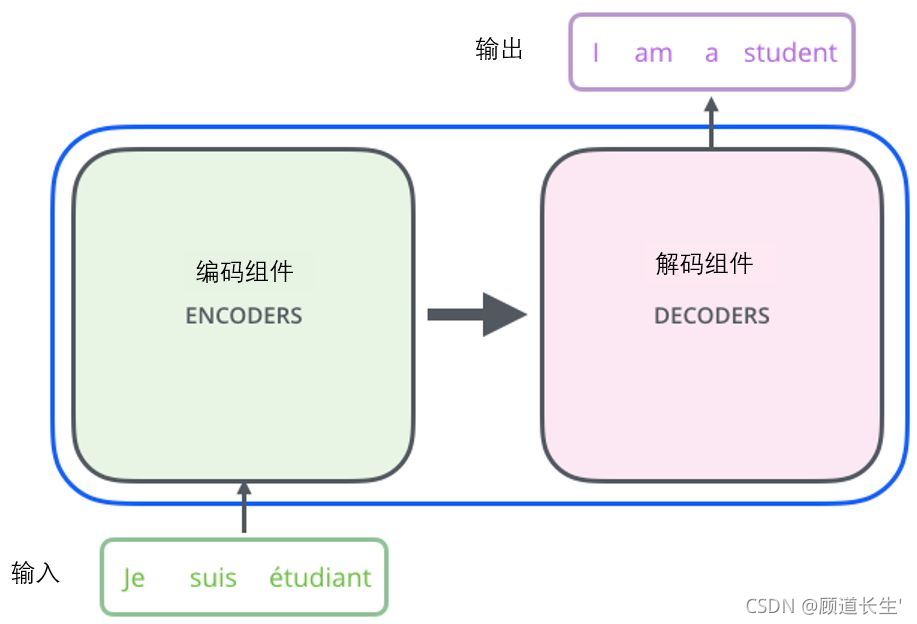
encoder and decoder的解释
Encoder-Decoder(编码-解码)是深度学习中非常常见的一个模型框架。这样的模型也被叫做 Sequence to Sequence learning。所谓编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。
在现在的深度学习领域当中,通常的做法是将输入的源Sequence编码到一个中间的context当中,这个context是一个特定长度的编码(可以理解为一个向量),然后再通过这个context还原成一个输出的目标Sequence。
如果用人的思维来看,就是我们先看到源Sequence,将其读一遍,然后在我们大脑当中就记住了这个源Sequence,并且存在大脑的某一个位置上,形成我们自己的记忆(对应Context),然后我们再经过思考(解码),将这个大脑里的东西转变成输出,然后写下来。
那么我们大脑读入的过程叫做Encoder,即将输入的东西变成我们自己的记忆,放在大脑当中,而这个记忆可以叫做Context,然后我们再根据这个Context,转化成答案写下来,这个写的过程叫做Decoder。其实就是编码-存储-解码的过程。
其实,这个过程,还是在用人的大脑处理问题的方式,运用机器来模拟。
模型原理解读
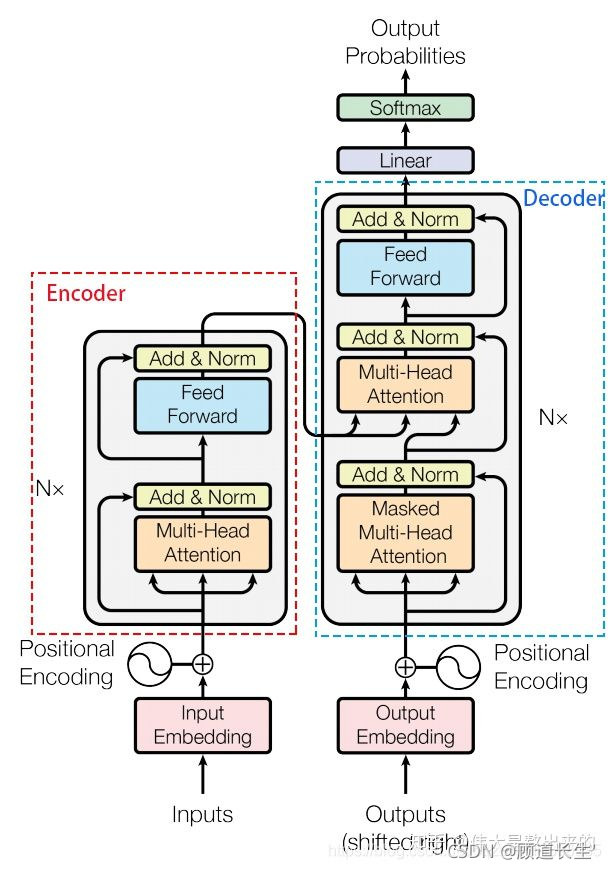
总体结构
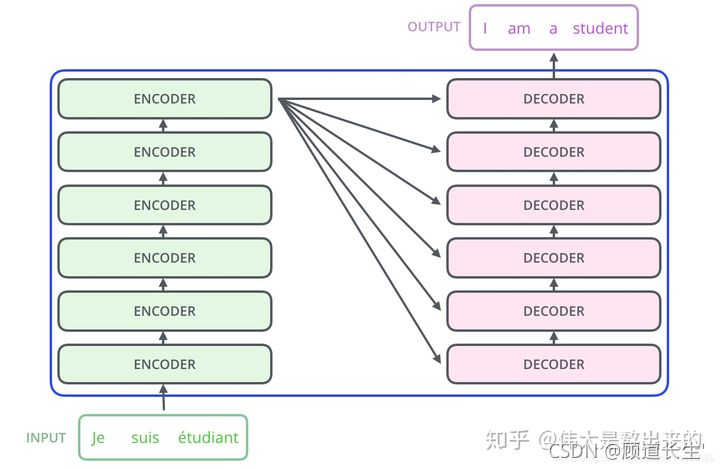
Encoder层和Decoder层内部结构如下图所示。
- Encoder具有两层结构,self-attention和前馈神经网络。self-attention计算句子中的每个词都和其他词的关联,从而帮助模型更好地理解上下文语义,引入Muti-Head attention后,每个头关注句子的不同位置,增强了Attention机制关注句子内部单词之间作用的表达能力。前馈神经网络为encoder引入非线性变换,增强了模型的拟合能力。
- Decoder接受output输入的同时接受encoder的输入,帮助当前节点获取到需要重点关注的内容
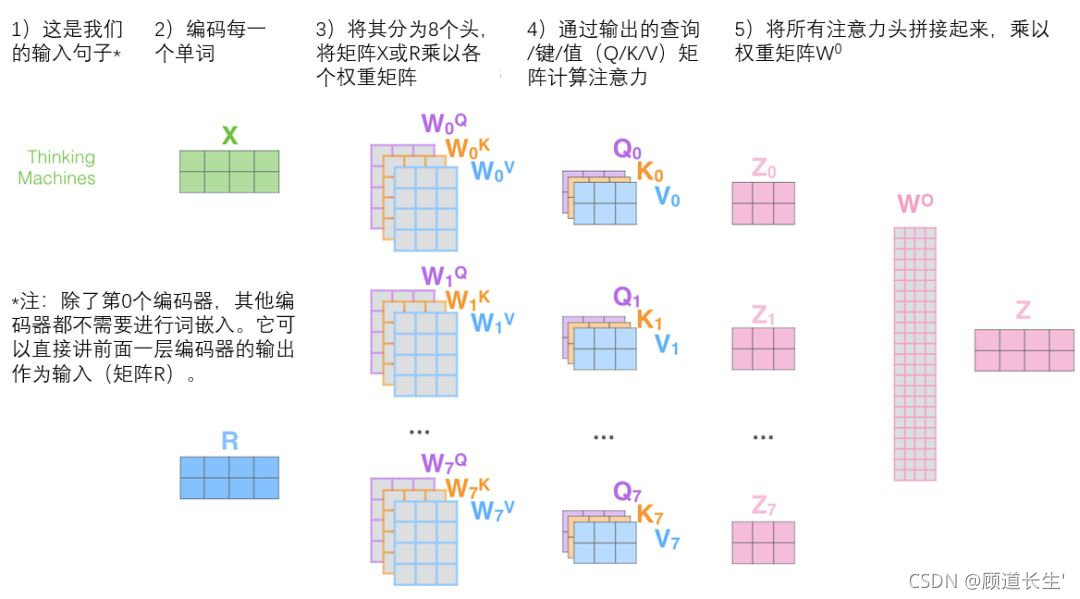
Multi-Head Attention
了解multi-head attention,首先要了解self-attention,参考(2021李宏毅)机器学习-Self-attention
为什么是多头:
原论文中说到进行Multi-head Attention的原因是将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息,最后再将各个方面的信息综合起来。其实直观上也可以想到,如果自己设计这样的一个模型,必然也不会只做一次attention,多次attention综合的结果至少能够起到增强模型的作用,也可以类比CNN中同时使用多个卷积核的作用,直观上讲,多头的注意力 有助于网络捕捉到更丰富的特征/信息 。
通过增加一种叫做“多头”注意力(“multi-headed” attention)的机制,论文进一步完善了自注意力层,并在两方面提高了注意力层的性能:
-
如果我们翻译一个句子,比如下面的例子,我们会想知道“it”指的是哪个词,这时模型的“多头”注意机制会起到作用。
The animal didn’t cross the street because it was too tiredThe animal didn’t cross the street because it was too wide
-
Attention是将query和key映射到同一高维空间中去计算相似度,而对应的multi-head attention把query和key映射到高维空间 α \alpha α 的不同子空间 ( α 1 , α 2 , … , α h ) \left(\alpha_{1}, \alpha_{2}, \ldots, \alpha_{h}\right) (α1,α2,…,αh) 中去计算相似度
Position-wise Feed Forward
F
F
N
(
x
)
=
max
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
F F N(x)=\max \left(0, x W_{1}+b_{1}\right) W_{2}+b_{2}
FFN(x)=max(0,xW1+b1)W2+b2
每一层经过attention之后,还会有一个FFN,这个FFN的作用就是空间变换。FFN包含了2层linear transformation层,中间的激活函数是ReLu。
FFN的加入引入了非线性(ReLu激活函数),变换了attention output的空间, 从而增加了模型的表现能力
Layer Normalization
在每个block中,最后出现的是Layer Normalization,其作用是规范优化空间,加速收敛。
当使用梯度下降算法做优化时,可能会对输入数据进行归一化,但是经过网络层作用后,数据已经不是归一化的了。随着网络层数的增加,数据分布不断发生变化,偏差越来越大,导致不得不使用更小的学习率来稳定梯度。Layer Normalization 的作用就是保证数据特征分布的稳定性,将数据标准化到ReLU激活函数的作用区域,可以使得激活函数更好的发挥作用
Positional Encoding
Positional Encoding是transformer的特有机制,弥补了Attention机制无法捕捉sequence中token位置信息的缺点
深度解读请参考https://www.spaces.ac.cn/archives/8231
Residual Network 残差网络
在transformer模型中,encoder和decoder各有6层,为了使当模型中的层数较深时仍然能得到较好的训练效果,模型中引入了残差网络。
Linear & Softmax
Decoder最后是一个线性变换和softmax层。解码组件最后会输出一个实数向量。如何把浮点数变成一个单词?这便是线性变换层要做的工作,它之后就是Softmax层。
线性变换层是一个简单的全连接神经网络,它可以 把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里 。不妨假设我们的模型从训练集中学习一万个不同的英语单词(我们模型的“输出词表”)。因此对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数( 相当于做vocaburary_size大小的分类 )。接下来的Softmax 层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出。

训练与测试
训练
训练时,由于生成的mask矩阵,所以可以并行训练
测试
测试时,看不到未来信息,解码层中,前一个的输出,是后一个的输入,所以,测试时,只能为串行
总结
优点 :
- 虽然Transformer最终也没有逃脱传统学习的套路,Transformer也只是一个全连接(或者是一维卷积)加Attention的结合体。但是其设计已经足够有创新,因为其抛弃了在NLP中最根本的RNN或者CNN并且取得了非常不错的效果,算法的设计非常精彩,值得每个深度学习的相关人员仔细研究和品位。
- Transformer的设计最大的带来性能提升的关键是可以并行运算
- Transformer不仅仅可以应用在NLP的机器翻译领域,甚至可以不局限于NLP领域,是非常有科研潜力的一个方向。
- 算法的并行性非常好,符合目前的硬件(主要指GPU)环境。
缺点 :
- 粗暴的抛弃RNN和CNN虽然非常炫技,但是它也使模型丧失了捕捉局部特征的能力,RNN + CNN + Transformer的结合可能会带来更好的效果
- Transformer失去的位置信息其实在NLP中非常重要,而论文中在特征向量中加入Position Embedding也只是一个权宜之计,并没有改变Transformer结构上的固有缺陷。
补充
Decoder
具体来说,传统 Seq2Seq 中 Decoder 使用的是 RNN 模型,因此在训练过程中输入
t
t
t时刻的词,模型无论如何也看不到未来时刻的词,因为循环神经网络是时间驱动的,只有当
t
t
t时刻运算结束了,才能看到
t
+
1
t+1
t+1时刻的词。而 Transformer Decoder 抛弃了 RNN,改为 Self-Attention,由此就产生了一个问题,在训练过程中,整个 ground truth 都暴露在 Decoder 中,这显然是不对的,我们需要对 Decoder 的输入进行一些处理,该处理被称为 Mask
Mask怎么做?
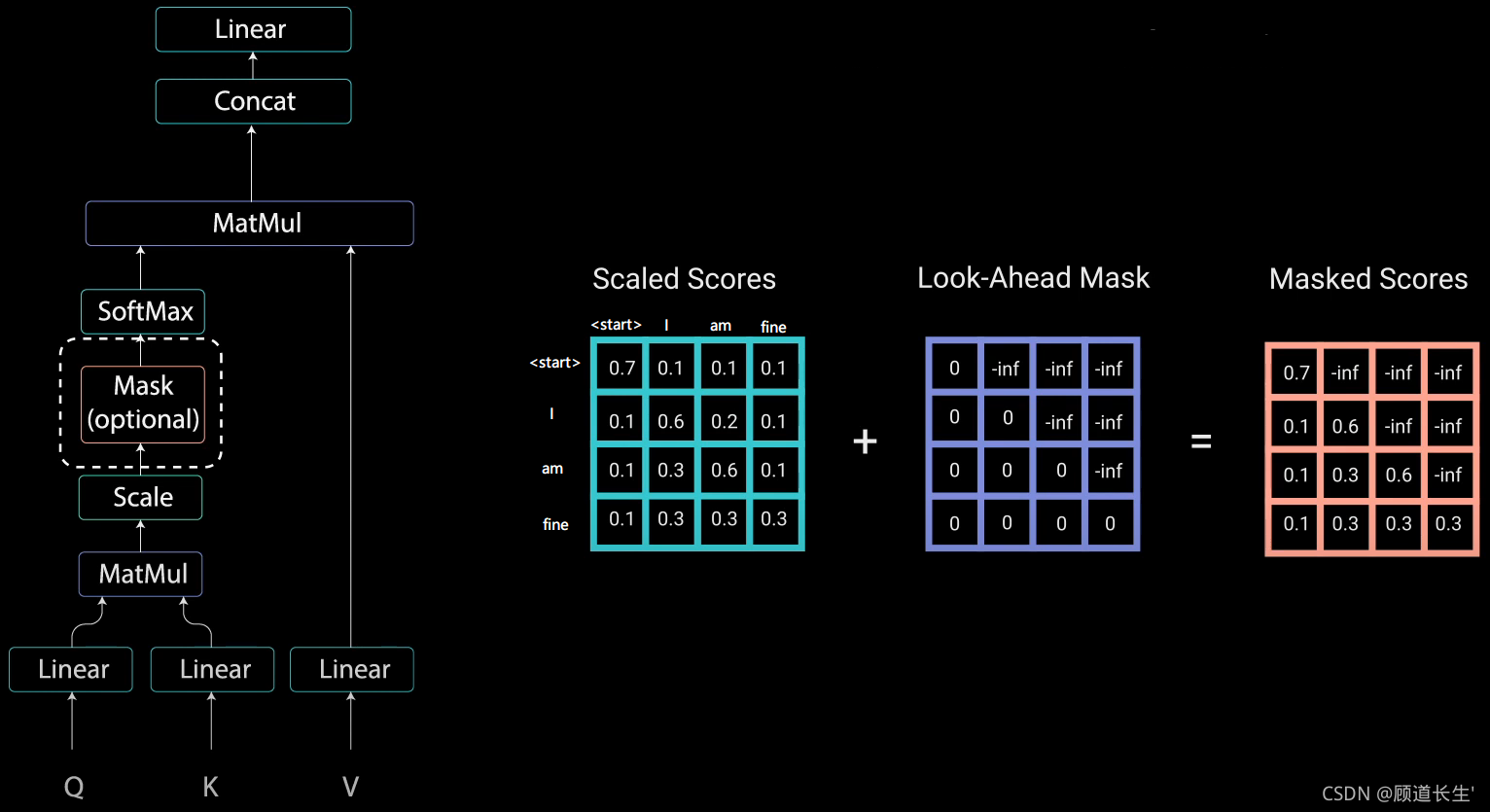
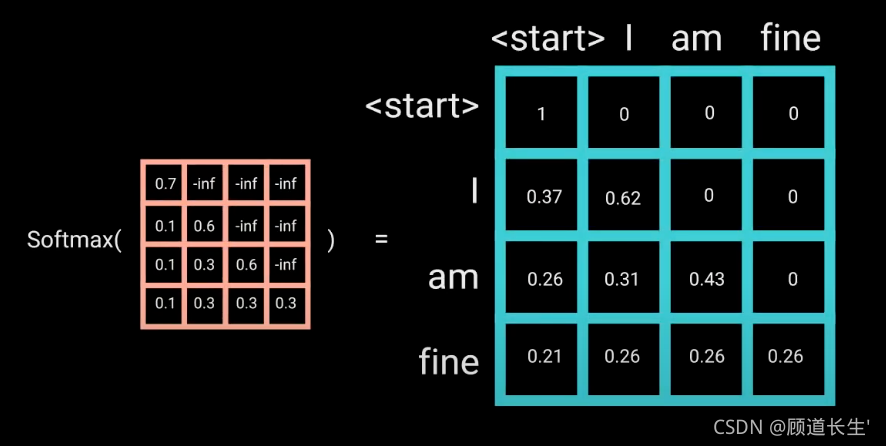


















 2161
2161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











