 理解对比表示学习:对齐与均匀性
理解对比表示学习:对齐与均匀性





 本文探讨了对比表示学习在单位超球面上的对齐性和均匀性,这两个特性对于学习高质量的特征表示至关重要。研究发现,对比损失在无限负样本情况下优化了对齐和均匀性,并通过实验验证了这两个指标与下游任务性能的强相关性。直接优化这些指标可以取得与对比学习相当甚至更好的效果。
本文探讨了对比表示学习在单位超球面上的对齐性和均匀性,这两个特性对于学习高质量的特征表示至关重要。研究发现,对比损失在无限负样本情况下优化了对齐和均匀性,并通过实验验证了这两个指标与下游任务性能的强相关性。直接优化这些指标可以取得与对比学习相当甚至更好的效果。
文章目录
通过超球面的对齐和均匀性理解对比表示学习
paper题目:Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere
paper是MIT发表在ICML 2020的工作
paper地址:链接
Abstract
对比表征学习在实践中取得了显著的成功。在这项工作中,我们确定了与对比损失相关的两个关键特性:(1)正对特征的对齐(接近)和(2)超球面上(归一化)特征诱导分布的均匀性。我们证明,对比损失渐进地优化了这些属性,并分析了它们对下游任务的积极影响。根据经验,我们引入了一个可优化的度量来量化每个属性。在标准视觉和语言数据集上的大量实验证实了这两个指标和下游任务性能之间的强烈一致性。与对比学习相比,直接优化这两个指标可以在下游任务中获得相当或更好的表现。
项目页面: 链接
Code:链接
1. Introduction
最近大量的经验性工作都是在单位 ℓ 2 \ell_{2} ℓ2规范约束下学习表征,有效地将输出空间限制在单位超球上,包括许多最近的无监督的对比表征学习方法。
直观地说,让这些特征存在于单位超球面上会产生一些令人满意的特征。在点积无处不在的现代机器学习中,固定范数向量可以提高训练的稳定性。此外,如果一个类的特征足够好地聚集,那么它们与其他特征空间(见图2)是线性可分离的,这是用于评估表示质量的常用标准。

图2:超球面。当类被很好地聚集在一起时(形成球状帽),它们是线性可分离的。这一点对于欧几里得空间来说并不成立。
虽然单位超球面是一个流行的特征空间选择,但并非所有映射到它的编码器都是平等的。最近的工作认为,表征应该另外对不必要的细节保持不变,并尽可能多地保留信息。我们把这两个属性称为对齐性和均匀性(见图1)。对齐性倾向于将相似的特征分配给相似的样本的编码者。均匀性更倾向于保留最大信息的特征分布,即单位超球上的均匀分布。

图 1:输出单位超球面上特征分布的对齐性和均匀性示意图。
在这项工作中,我们分析了对齐性和均匀性属性。我们表明,目前流行的对比表示学习形式实际上在无限负样本的限制下直接优化了这两个属性。我们提出了基于理论动机的对齐性和均匀性指标,并观察到它们与下游任务性能之间的一致性。值得注意的是,直接对这两个指标进行优化会获得与对比学习相当或更好的性能。
我们的主要贡献是:
- 我们提出了用于对齐性和均匀性的量化指标作为表征质量的两个度量,具有理论动机。
- 我们证明了对比损失渐近优化对齐性和均匀性。
- 根据经验,我们发现指标和下游任务性能之间有很强的一致性。
- 尽管形式简单,但我们提出的指标在没有其他损失的情况下直接优化时,凭经验在下游任务中与对比学习相比具有可比或更好的性能。
2. Related Work
无监督对比表征学习在图像和序列数据的表征学习方面取得了显著的成功。这些工作背后的共同动机是InfoMax原则,我们在这里将其实例化为最大化两个视图之间的互信息(MI)。然而,这种解释与实践中的实际行为不一致,例如,优化MI的更严格界限可能会导致更糟糕的表示。对比损失究竟是什么,在很大程度上仍是一个谜。基于潜在类别假设的分析提供了很好的理论见解,但不幸的是,与实证实践存在相当大的差距:代表性质量受到大量负面影响的结果与实证观察结果不一致。在本文中,我们从对齐性和均匀性的角度分析和描述了对比学习的行为,并用标准表征学习任务实证验证了我们的观点。
单位超球面上的表征学习。在对比学习之外,许多其他表征学习方法也将其特征标准化为单位超球面。在变分自编码器中,超球面潜在空间的性能优于欧几里德空间。我们知道,在单位超球面上直接匹配均匀采样点可以提供良好的表示,这与我们的直觉一致,即均匀性是一个理想的特性。Mettes等人(2019年)优化了单位超球面上的原型表示,以进行分类。超球面人脸嵌入的性能大大优于非正规化的人脸嵌入。它的经验成功表明,单位超球面确实是一个很好的特征空间。在这项工作中,我们正式研究了超球面几何和流行的对比表征学习之间的相互作用。
单位超球上的分布点。在单位超球上均匀分布点的问题是一个经过充分研究的问题。它通常被定义为对某一核函数的总势能最小化,例如,寻找电子最小静电势能配置的Thomson问题,以及Riesz s势能的最小化。我们提出的均匀性度量基于高斯势,它可以用来表示一类非常普遍的核,并且与普遍最优的点配置密切相关。此外,还讨论了超球面上的最佳填充问题。
3.无监督对比表征学习的初步研究
流行的无监督对比表征学习方法(本文中通常称为对比学习)从未标记的数据中学习表征。它假设了一种对正样本对进行采样的方法,表示应该具有相似表示的相似样本。根据经验,正样本对通常通过对同一样本的两个独立的随机增强版本获得,例如,同一图像的两个crops。
设 p data ( ⋅ ) p_{\text {data }}(\cdot) pdata (⋅)为 R n \mathbb{R}^{n} Rn上的数据分布, p pos ( ⋅ , ⋅ ) p_{\text {pos }}(\cdot, \cdot) ppos (⋅,⋅)为 R n × R n \mathbb{R}^{n} \times \mathbb{R}^{n} Rn×Rn上正样本对的分布。基于实践经验,我们假设如下性质。
假定分布 p data p_{\text {data }} pdata 和 p pos p_{\text {pos }} ppos 应满足
- 对称性: ∀ x , y , p pos ( x , y ) = p pos ( y , x ) \forall x, y, p_{\text {pos }}(x, y)=p_{\text {pos }}(y, x) ∀x,y,ppos (x,y)=ppos (y,x)
- 匹配边缘: ∀ x , ∫ p pos ( x , y ) d y = p data ( x ) \forall x, \int p_{\text {pos }}(x, y) \mathrm{d} y=p_{\text {data }}(x) ∀x,∫ppos (x,y)dy=pdata (x)
我们考虑以下特定且广泛流行的对比损失形式来训练编码器
f
:
R
n
→
S
m
−
1
f: \mathbb{R}^{n} \rightarrow \mathcal{S}^{m-1}
f:Rn→Sm−1,将数据映射到维度为
m
m
m的
ℓ
2
\ell_{2}
ℓ2归一化特征向量。许多最近的表示学习方法已经证明这种损失是有效的。
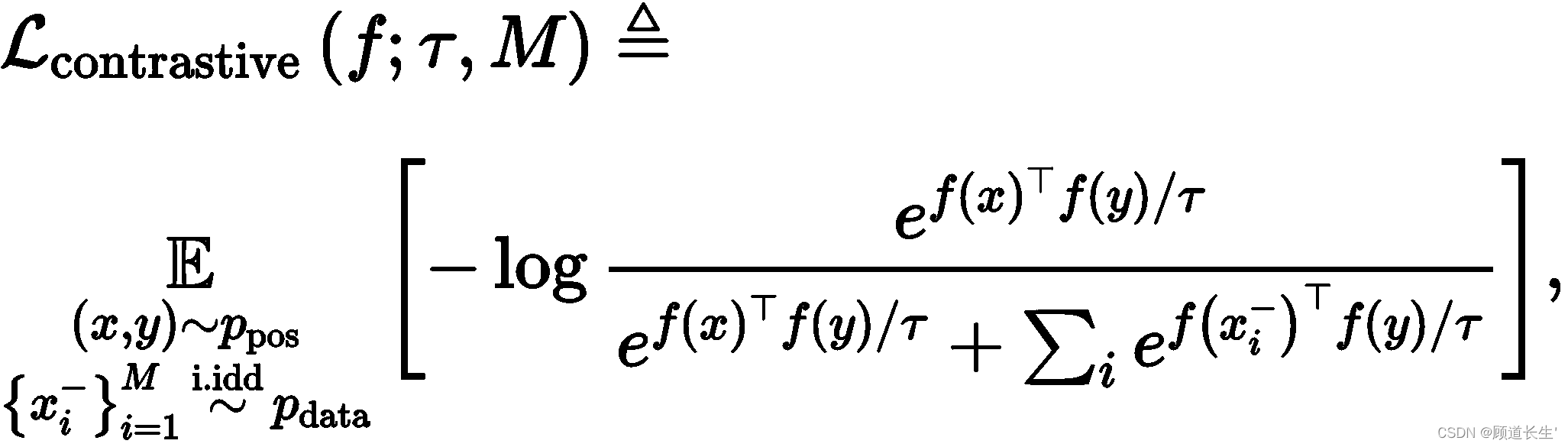
其中 τ > 0 \tau>0 τ>0是标量温度超参数, M ∈ Z + M \in \mathbb{Z}_{+} M∈Z+是固定数量的负样本。
对比损失一词也通常用于指基于正面和负面样本的各种目标。在这项工作中,我们关注公式(1)中的具体形式,它在现代无监督对比表征学习文献中被广泛使用。
规范化的必要性。在没有范数约束的情况下,通过简单地缩放所有特征,softmax分布可以变得随机尖锐。Wang等人(2017年)对这种影响进行了分析,并论证了在交叉熵损失中使用特征向量点积时进行归一化的必要性,如在公式(1)中所述。在实验上,Chen等人(2020年)也表明,规范化输出会获得更好的表现。
InfoMax 原则。许多实证工作是由 InfoMax 原则推动的,即对于 ( x , y ) ∼ p pos (x, y) \sim p_{\text {pos }} (x,y)∼ppos 最大化 I ( f ( x ) ; f ( y ) ) I(f(x) ; f(y)) I(f(x);f(y))。通常他们解释公式(1)中的 L contrastive \mathcal{L}_{\text {contrastive}} Lcontrastive作为 I ( f ( x ) ; f ( y ) ) I(f(x) ; f(y)) I(f(x);f(y))的下界。然而,众所周知,这种解释在实践中存在问题,例如,最大化更紧密的界限通常会导致下游任务性能更差。因此,我们没有将其视为界限,而是在以下部分中研究直接优化 L contrastive \mathcal{L}_{\text {contrastive}} Lcontrastive的确切行为。
4. Feature Distribution on the Hypersphere
对比损失鼓励正样本对的学习特征表示相似,同时将随机采样的负样本对的特征推开。传统观点认为,表示应该提取正样本对之间共享的信息,并且对其他噪声因素保持不变。因此,损失应该优先考虑以下两个属性:
- 对齐性:形成正样本对的两个样本应该映射到附近的特征,因此(大部分)对不需要的噪声因子保持不变。
- 均匀性:特征向量应大致均匀分布在单位超球面 S m − 1 \mathcal{S}^{m-1} Sm−1上,尽可能多地保留数据信息。
为了凭经验验证这一点,我们将通过三种不同方法获得的 S 1 ( m = 2 ) \mathcal{S}^{1}(m=2) S1(m=2)上的 CIFAR-10 表示可视化:
- 随机初始化。
- 监督预测学习:编码器和线性分类器从头开始联合训练,在监督标签上具有交叉熵损失。
- 无监督对比学习:编码器经过 τ = 0.5 \tau=0.5 τ=0.5 and M = 256 M=256 M=256的 L contrastive \mathcal{L}_{\text {contrastive }} Lcontrastive 训练。
所有三个编码器都共享相同的基于AlexNet的架构,经过修改,可以将输入图像映射到 S 1 \mathcal{S}^{1} S1中的二维向量。预测学习和对比学习都使用标准数据扩充来扩充数据集和正样本对。
图3总结了验证集特性的结果分布。事实上,来自无监督对比学习的特征(图3的底部)表现出最均匀的分布,并且紧密地聚集在正样本对中。
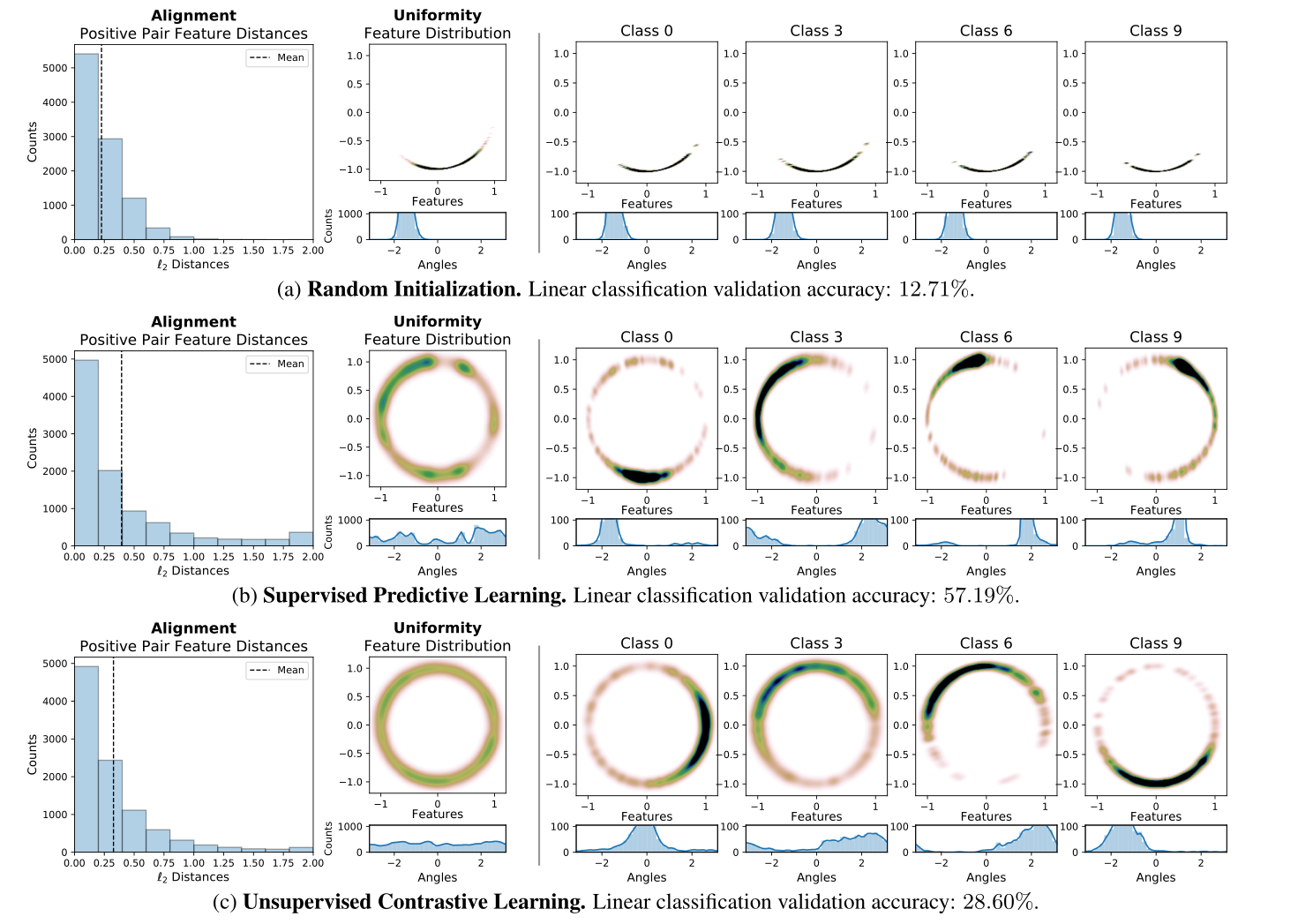
图3: S 1 \mathcal{S}^{1} S1上的CIFAR-10验证集表示。对齐分析:我们展示了正样本对特征之间的距离分布(两个随机增强)。均匀性分析:我们用 R 2 \mathbb{R}^{2} R2中的高斯核密度估计(KDE)和Mises-Fisher(vMF)KDE绘制每个点 ( x , y ) ∈ S 1 (x, y) \in \mathcal{S}^{1} (x,y)∈S1的角度(即 arctan 2 ( y , x ) \arctan 2(y, x) arctan2(y,x))上的特征分布)。最右边的四个图显示了选定特定类别的特征分布。对比学习的表征既一致(具有较低的正配对特征距离),又均匀(在 S 1 \mathcal{S}^{1} S1上均匀分布)。
Eqn(1) 中对比损失的形式也表明了这一点。我们在下面介绍非正式的论点,然后在第4.2节中进行更正式的处理。从
p
p
p的对称性,我们可以导出
L
contrastive
(
f
;
τ
,
M
)
=
E
(
x
,
y
)
∼
p
pos
[
−
f
(
x
)
⊤
f
(
y
)
/
τ
]
+
E
(
x
,
y
)
∼
p
pos
[
log
(
e
f
(
x
)
⊤
f
(
y
)
/
τ
+
∑
i
e
f
(
x
i
−
)
⊤
f
(
x
)
/
τ
)
]
{
x
i
−
}
i
=
1
M
∼
p
data
\begin{aligned} &\mathcal{L}_{\text {contrastive }}(f ; \tau, M)=\underset{(x, y) \sim p_{\text {pos }}}{\mathbb{E}}\left[-f(x)^{\top} f(y) / \tau\right] \\ &+\underset{(x, y) \sim p_{\text {pos }}}{\mathbb{E}}\left[\log \left(e^{f(x)^{\top} f(y) / \tau}+\sum_{i} e^{f\left(x_{i}^{-}\right)^{\top} f(x) / \tau}\right)\right] \\ &\quad\left\{x_{i}^{-}\right\}_{i=1}^{M} \sim p_{\text {data }} \end{aligned}
Lcontrastive (f;τ,M)=(x,y)∼ppos E[−f(x)⊤f(y)/τ]+(x,y)∼ppos E[log(ef(x)⊤f(y)/τ+i∑ef(xi−)⊤f(x)/τ)]{xi−}i=1M∼pdata
因为
∑
i
e
f
(
x
i
−
)
⊤
f
(
x
)
/
τ
\sum_{i} e^{f\left(x_{i}^{-}\right)^{\top} f(x) / \tau}
∑ief(xi−)⊤f(x)/τ项始终为正且有界在下方,所以损失有利于更小的
E
[
−
f
(
x
)
⊤
f
(
y
)
/
τ
]
\mathbb{E}\left[-f(x)^{\top} f(y) / \tau\right]
E[−f(x)⊤f(y)/τ],即具有更多对齐的正样本对特征。假设编码器完全对齐,即
P
[
f
(
x
)
=
f
(
y
)
]
=
1
\mathbb{P}[f(x)=f(y)]=1
P[f(x)=f(y)]=1,那么最小化损失就相当于优化
KaTeX parse error: Undefined control sequence: \substack at position 12: \underset{\̲s̲u̲b̲s̲t̲a̲c̲k̲{x \sim p_{\tex…
这类似于使用 LogSumExp 变换最大化成对距离。直观地说,将所有特征彼此推开确实应该使它们大致均匀分布。
4.1. Quantifying Alignment and Uniformity
为了进一步分析,我们需要一种测量对齐和均匀性的方法。我们提出以下两个指标(损失)。
4.1.1. ALIGNMENT
对齐损失直接定义为正样本对之间的预期距离:
L
align
(
f
;
α
)
≜
−
E
(
x
,
y
)
∼
p
pos
[
∥
f
(
x
)
−
f
(
y
)
∥
2
α
]
,
α
>
0
\mathcal{L}_{\text {align }}(f ; \alpha) \triangleq-\underset{(x, y) \sim p_{\text {pos }}}{\mathbb{E}}\left[\|f(x)-f(y)\|_{2}^{\alpha}\right], \quad \alpha>0
Lalign (f;α)≜−(x,y)∼ppos E[∥f(x)−f(y)∥2α],α>0
4.1.2. UNIFORMITY
我们希望均匀性度量在渐近上是正确的(即,优化该度量的分布应该收敛到均匀分布)并且在有限数量的点上经验上是合理的。为此,我们考虑高斯势核(也称为径向基函数 (RBF) 核)
G
t
:
S
d
×
S
d
→
R
+
G_{t}: \mathcal{S}^{d} \times \mathcal{S}^{d} \rightarrow \mathbb{R}_{+}
Gt:Sd×Sd→R+:
G
t
(
u
,
v
)
≜
e
−
t
∥
u
−
v
∥
2
2
=
e
2
t
⋅
u
⊤
v
−
2
t
,
t
>
0
,
G_{t}(u, v) \triangleq e^{-t\|u-v\|_{2}^{2}}=e^{2 t \cdot u^{\top} v-2 t}, \quad t>0,
Gt(u,v)≜e−t∥u−v∥22=e2t⋅u⊤v−2t,t>0,
并将均匀性损失定义为平均成对高斯势的对数:
L
uniform
(
f
;
t
)
≜
log
E
x
,
y
∼
i.i.d
p
data
[
G
t
(
u
,
v
)
]
,
t
>
0
,
\mathcal{L}_{\text {uniform }}(f ; t) \triangleq \log \underset{x, y \underset{\text { i.i.d }}{\sim} p_{\text {data }}}{\mathbb{E}}\left[G_{t}(u, v)\right], \quad t>0,
Luniform (f;t)≜logx,y i.i.d ∼pdata E[Gt(u,v)],t>0,
其中
t
t
t是一个固定参数。
平均成对高斯势与单位超球面上的均匀分布很好地联系在一起。
定义( S d \mathcal{S}^{d} Sd上的均匀分布)。 σ d \sigma_{d} σd表示 S d \mathcal{S}^{d} Sd上的归一化表面积测量值。
首先,我们证明了均匀分布是最小化预期成对势的唯一分布。
命题1 对于
S
d
\mathcal{S}^{d}
Sd上的Borel概率测度集
M
(
S
d
)
\mathcal{M}\left(\mathcal{S}^{d}\right)
M(Sd),
σ
d
\sigma_{d}
σd是唯一解
min
μ
∈
M
(
S
d
)
∫
u
∫
v
G
t
(
u
,
v
)
d
μ
d
μ
.
\min _{\mu \in \mathcal{M}\left(\mathcal{S}^{d}\right)} \int_{u} \int_{v} G_{t}(u, v) \mathrm{d} \mu \mathrm{d} \mu .
μ∈M(Sd)min∫u∫vGt(u,v)dμdμ.
此外,随着点的数量趋于无穷大,最小化平均成对势的点分布将 w e a k ∗ weak^{*} weak∗收敛到均匀分布。回想一下 w e a k ∗ weak^{*} weak∗的定义。
定义(
w
e
a
k
∗
weak^{*}
weak∗收敛度量)。对于所有连续函数
f
:
R
p
→
R
f: \mathbb{R}^{p} \rightarrow \mathbb{R}
f:Rp→R,在
R
p
\mathbb{R}^{p}
Rp中,
{
μ
n
}
n
=
1
∞
\left\{\mu_{n}\right\}_{n=1}^{\infty}
{μn}n=1∞收敛到
μ
\mu
μ,我们有
lim
n
→
∞
∫
f
(
x
)
d
μ
n
(
x
)
=
∫
f
(
x
)
d
μ
(
x
)
\lim _{n \rightarrow \infty} \int f(x) \mathrm{d} \mu_{n}(x)=\int f(x) \mathrm{d} \mu(x)
n→∞lim∫f(x)dμn(x)=∫f(x)dμ(x)
命题 2. 对于每个
N
>
0
N>0
N>0,平均成对势的
N
N
N点最小化器是
u
N
∗
=
arg
min
u
1
,
u
2
,
…
,
u
N
∈
S
d
∑
1
≤
i
<
j
≤
N
G
t
(
u
i
,
u
j
)
\mathbf{u}_{N}^{*}=\underset{u_{1}, u_{2}, \ldots, u_{N} \in \mathcal{S}^{d}}{\arg \min } \sum_{1 \leq i< j \leq N} G_{t}\left(u_{i}, u_{j}\right)
uN∗=u1,u2,…,uN∈Sdargmin1≤i<j≤N∑Gt(ui,uj)
与
{
u
N
∗
}
N
=
1
∞
\left\{\mathbf{u}_{N}^{*}\right\}_{N=1}^{\infty}
{uN∗}N=1∞序列相关的归一化计数度量将weak
∗
{ }^{*}
∗收敛到
σ
d
\sigma_{d}
σd。
设计一个通过均匀分布最小化的目标实际上是不平凡的。例如,平均成对点积或欧几里得距离可以简单地通过任何均值为零的分布进行优化。在达到最优一致性的核中,高斯核的特殊之处在于它与普遍最优点配置密切相关,也可以用来表示其他核的一般类别,包括 Riesz s-potentials。此外,如下所示,用高斯核定义的 L uniform, \mathcal{L}_{\text {uniform, }} Luniform, 与 L contrastive \mathcal{L}_{\text {contrastive }} Lcontrastive 有着密切的联系。
4.2. Limiting Behavior of Contrastive Learning
在本节中,我们将对比学习优化对齐性和均匀性的直觉形式化,并描述其渐近行为。我们考虑所有可测量编码器函数的优化问题,从 R n \mathbb{R}^{n} Rn中的 p data p_{\text {data }} pdata 测量到 Borel 空间 S m − 1 \mathcal{S}^{m-1} Sm−1。
我们首先为这些指标定义最优性的概念。
定义(完美对齐)。如果 f ( x ) = f ( y ) f(x)=f(y) f(x)=f(y)几乎肯定在 ( x , y ) ∼ p pos (x, y) \sim p_{\text {pos }} (x,y)∼ppos 上,我们说编码器 f f f是完全对齐的。
定义(完美的均匀性)。如果 x ∼ p data x \sim p_{\text {data }} x∼pdata 的 f ( x ) f(x) f(x)的分布是 S m − 1 \mathcal{S}^{m-1} Sm−1上的均匀分布 σ m − 1 \sigma_{m-1} σm−1,我们说编码器 f f f是完全均匀的。
完美均匀性的可实现性。我们注意到,并不总是可以实现完美的一致性,例如,当 R n \mathbb{R}^{n} Rn中的数据流形的维度低于特征空间 S m − 1 \mathcal{S}^{m-1} Sm−1时。此外,在 p data p_{\text {data }} pdata 和 p pos p_{\text {pos }} ppos 是从有限数据集中采样增强样本形成的情况下,不可能有一个既完美对齐又完美均匀的编码器,因为完美对齐意味着来自单个元素的所有增强都具有相同的特征向量.尽管如此,在 n ≥ n \geq n≥ m − 1 m-1 m−1且 p data p_{\text {data }} pdata 具有有界密度的条件下,确实存在完全一致的编码器函数。
我们用无限负样本分析渐近线。现有的实证工作已经确定,大量的负样本始终会导致更好的下游任务性能,并且经常使用非常大的值(例如,He et al. (2019) 中的 M = 65536)。以下定理很好地证实了优化关于限制损失确实需要对齐和均匀性。
定理 1(
L
contrastive
\mathcal{L}_{\text {contrastive }}
Lcontrastive 的渐近线)。对于固定的
τ
>
0
\tau>0
τ>0,随着负样本的数量
M
→
∞
M \rightarrow \infty
M→∞,(归一化)对比损失收敛到
lim
M
→
∞
L
contrastive
(
f
;
τ
,
M
)
−
log
M
=
−
1
τ
E
(
x
,
y
)
∼
p
pos
[
f
(
x
)
⊤
f
(
y
)
]
+
E
x
∼
p
data
[
log
E
x
−
∼
p
data
[
e
f
(
x
−
)
⊤
f
(
x
)
/
τ
]
]
.
\begin{aligned} \lim _{M \rightarrow \infty} & \mathcal{L}_{\text {contrastive }}(f ; \tau, M)-\log M=\\ &-\frac{1}{\tau} \underset{(x, y) \sim p_{\text {pos }}}{\mathbb{E}}\left[f(x)^{\top} f(y)\right] \\ &+\underset{x \sim p_{\text {data }}}{\mathbb{E}}\left[\log \underset{x^{-} \sim p_{\text {data }}}{\mathbb{E}}\left[e^{f\left(x^{-}\right)^{\top} f(x) / \tau}\right]\right] . \end{aligned}
M→∞limLcontrastive (f;τ,M)−logM=−τ1(x,y)∼ppos E[f(x)⊤f(y)]+x∼pdata E[logx−∼pdata E[ef(x−)⊤f(x)/τ]].
我们有以下结果: 1. 如果 f f f完全对齐,则第一项最小化。 2. 如果存在完全一致的编码器,它们形成第二项的精确最小化器。 3. 对于上式中的收敛,与极限的绝对偏差在 O ( M − 2 / 3 ) \mathcal{O}\left(M^{-2 / 3}\right) O(M−2/3)中衰减。
与 L uniform \mathcal{L}_{\text {uniform }} Luniform 的关系。补充材料中定理 1 的证明将渐近 L contrastive \mathcal{L}_{\text {contrastive }} Lcontrastive 形式与最小化平均成对高斯势联系起来,即最小化 L uniform \mathcal{L}_{\text {uniform}} Luniform。与上式的第二项相比, L uniform \mathcal{L}_{\text {uniform }} Luniform 本质上将log推到了外部期望之外,而没有改变最小化器(完全一致的编码器)。然而,由于其成对的性质, L uniform. \mathcal{L}_{\text {uniform. }} Luniform. 在形式上要简单得多,并且避免了 L contrastive \mathcal{L}_{\text {contrastive }} Lcontrastive 中计算量大的 softmax 操作。
与特征分布熵估计的关系。当
p
data
p_{\text {data }}
pdata 在有限样本
{
x
1
,
x
2
,
…
,
x
N
}
\left\{x_{1}, x_{2}, \ldots, x_{N}\right\}
{x1,x2,…,xN}(例如,收集的数据集),上式中的第二项也可以看作是
f
(
x
)
f(x)
f(x)的重新代入熵估计量,其中
x
x
x遵循生成
{
x
i
}
i
=
1
N
\left\{x_{i}\right\}_{i=1}^{N}
{xi}i=1N的基础分布
p
nature
p_{\text {nature }}
pnature ,通过 von Mises-Fisher (vMF) 核密度估计 (KDE):
E
x
∼
p
data
[
log
E
x
−
∼
p
data
[
e
f
(
x
−
)
⊤
f
(
x
)
/
τ
]
]
=
1
N
∑
i
=
1
N
log
(
1
N
∑
j
=
1
N
e
f
(
x
i
)
⊤
f
(
x
j
)
/
τ
)
=
1
N
∑
i
=
1
N
log
p
^
v
M
F
−
K
D
E
(
f
(
x
i
)
)
+
log
Z
v
M
F
≜
−
H
^
(
f
(
x
)
)
+
log
Z
v
M
F
,
x
∼
p
nature
≜
−
I
^
(
x
;
f
(
x
)
)
+
log
Z
v
M
F
,
x
∼
p
nature
,
\begin{aligned} &\underset{x \sim p_{\text {data }}}{\mathbb{E}}\left[\log \underset{x^{-} \sim p_{\text {data }}}{\mathbb{E}}\left[e^{f\left(x^{-}\right)^{\top} f(x) / \tau}\right]\right]\\ &=\frac{1}{N} \sum_{i=1}^{N} \log \left(\frac{1}{N} \sum_{j=1}^{N} e^{f\left(x_{i}\right)^{\top} f\left(x_{j}\right) / \tau}\right)\\ &=\frac{1}{N} \sum_{i=1}^{N} \log \hat{p}_{\mathrm{vMF}-\mathrm{KDE}}\left(f\left(x_{i}\right)\right)+\log Z_{\mathrm{vMF}}\\ &\triangleq-\hat{H}(f(x))+\log Z_{\mathrm{vMF}}, \quad x \sim p_{\text {nature }}\\ &\triangleq-\hat{I}(x ; f(x))+\log Z_{\mathrm{vMF}}, \quad x \sim p_{\text {nature }}, \end{aligned}
x∼pdata E[logx−∼pdata E[ef(x−)⊤f(x)/τ]]=N1i=1∑Nlog(N1j=1∑Nef(xi)⊤f(xj)/τ)=N1i=1∑Nlogp^vMF−KDE(f(xi))+logZvMF≜−H^(f(x))+logZvMF,x∼pnature ≜−I^(x;f(x))+logZvMF,x∼pnature ,
其中
-
p ^ v M F − K D E \hat{p}_{\mathrm{vMF}-\mathrm{KDE}} p^vMF−KDE是基于样本 { f ( x j ) } j = 1 N \left\{f\left(x_{j}\right)\right\}_{j=1}^{N} {f(xj)}j=1N使用具有 κ = τ − 1 \kappa=\tau^{-1} κ=τ−1的 vMF 内核的 KDE,
-
Z v M F Z_{\mathrm{vMF}} ZvMF是 κ = τ − 1 \kappa=\tau^{-1} κ=τ−1的 vMF 归一化常数,
-
H ^ \hat{H} H^表示重新代入熵估计量
-
I ^ \hat{I} I^表示基于 H ^ \hat{H} H^的互信息估计量,因为 f f f是确定性函数。
与 InfoMax 原则的关系。许多实证工作受到 InfoMax 原理的启发,即最大化 I ( f ( x ) ; f ( y ) ) I(f(x) ; f(y)) I(f(x);f(y))对于 ( x , y ) ∼ p pos (x, y) \sim p_{\text {pos}} (x,y)∼ppos。然而,已知将 L contrastive \mathcal{L}_{\text {contrastive }} Lcontrastive 解释为 I ( f ( x ) ; f ( y ) ) I(f(x) ; f(y)) I(f(x);f(y))的下限与其在实践中的实际行为不一致。我们的结果反而分析了 I ( f ( x ) ; f ( y ) ) I(f(x) ; f(y)) I(f(x);f(y))本身的特性。考虑恒等式 I ( f ( x ) ; f ( y ) ) = H ( f ( x ) ) − H ( f ( x ) ∣ f ( y ) ) I(f(x) ; f(y))=H(f(x))-H(f(x) \mid f(y)) I(f(x);f(y))=H(f(x))−H(f(x)∣f(y)),我们可以看到虽然均匀性确实有利于大 H ( f ( x ) ) H(f(x)) H(f(x)),对齐比仅仅希望小的 H ( f ( x ) ∣ f ( y ) ) H(f(x) \mid f(y)) H(f(x)∣f(y))更强。相反,我们的上述分析表明 L contrastive \mathcal{L}_{\text {contrastive }} Lcontrastive 针对对齐和信息保留编码器进行了优化。
最后,即使对于仅使用单个负样本的情况(即 M = 1 M=1 M=1),我们仍然可以证明较弱的结果。
参考文献
Mettes, P ., van der Pol, E., and Snoek, C. Hyperspherical prototype networks. In Advances in Neural Information Processing Systems, pp. 1485–1495, 2019.
Wang, F., Xiang, X., Cheng, J., and Y uille, A. L. Normface: L2 hypersphere embedding for face verification. In Proceedings of the 25th ACM international conference on Multimedia, pp. 1041–1049, 2017.
Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709, 2020.
He, K., Fan, H., Wu, Y ., Xie, S., and Girshick, R. Momentum contrast for unsupervised visual representation learning. arXiv preprint arXiv:1911.05722, 2019.


















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











