







 本文探讨了在深度学习中常见的梯度消失和梯度爆炸问题,分析了这些问题产生的原因,包括网络层次过深和激活函数的选择不当。并提出了几种解决方案,如梯度剪切、正则化、更换激活函数及使用LSTM网络。
本文探讨了在深度学习中常见的梯度消失和梯度爆炸问题,分析了这些问题产生的原因,包括网络层次过深和激活函数的选择不当。并提出了几种解决方案,如梯度剪切、正则化、更换激活函数及使用LSTM网络。
关于梯度消失和爆炸,其前提是采用梯度下降办法去更新网络参数,使得代价函数最小化。出现梯度消失和爆炸的原因基本上归为两点:一,网络层次太深,由于很多网络的更新时的链式原理,使得更新信息往往指数级变化;二,采用了不合适的激活函数,比如sigmoid,梯度爆炸一般出现在深层网络和权值初始化值太大的情况下。
1.深层网络角度
比较简单的深层网络如下:

图中是一个四层的全连接网络,假设每一层网络激活后的输出为,其中
为第
层,
代表第
层的输入,
是激活函数,那么,得出
。
例如BP算法基于梯度下降策略,以目标的负梯度方向对参数进行调整,参数的更新为w←w+Δw,给定学习率α,得出。如果要更新第二隐藏层的权值信息,根据链式求导法则,更新梯度信息:
,很容易看出来
,即第二隐藏层的输入。
所以说,就是对激活函数进行求导,如果此部分大于1,那么层数增多的时候,最终的求出的梯度更新将以指数形式增加,即发生梯度爆炸,如果此部分小于1,那么随着层数增多,求出的梯度更新信息将会以指数形式衰减,即发生了梯度消失。
2.激活函数角度
其实也注意到了,上文中提到计算权值更新信息的时候需要计算前层偏导信息,因此如果激活函数选择不合适,比如使用sigmoid,梯度消失就会很明显了,原因看下图,左图是sigmoid的损失函数图,右边是其导数的图像,如果使用sigmoid作为损失函数,其梯度是不可能超过0.25的,这样经过链式求导之后,很容易发生梯度消失。


梯度消失、爆炸的解决方案
1.梯度剪切、正则
梯度剪切这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。这可以防止梯度爆炸。
另外一种解决梯度爆炸的手段是采用权重正则化(weithts regularization)。
2.换用relu、leakrelu、elu等激活函数
3.LSTM
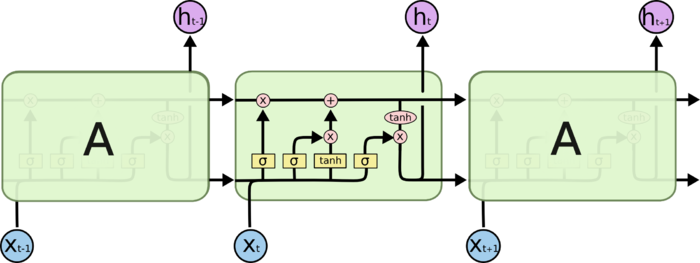
LSTM全称是长短期记忆网络(long-short term memory networks),是不那么容易发生梯度消失的,主要原因在于LSTM内部复杂的“门”(gates),如下图,LSTM通过它内部的“门”可以接下来更新的时候“记住”前几次训练的”残留记忆“,因此,经常用于生成文本中。

















 1713
1713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









