







包含人工蜂群(ABC)、灰狼(GWO)、差分进化(DE)、粒子群(PSO)、麻雀优化(SSA)、蜣螂优化(DBO)、白鲸优化(BWO)、遗传算法(GA)、粒子群算法(PSO),基于反向动态学习的差分进化算法,共十种算法,直接一文全部搞定!
其中基于反向动态学习的差分进化算法是我自己改进的。大家可以参考这种改进方式去改进别的算法,效果还是不错的!
以CEC2017函数为例,我随意选择了几个函数,每个算法迭代了500次,先上结果图:

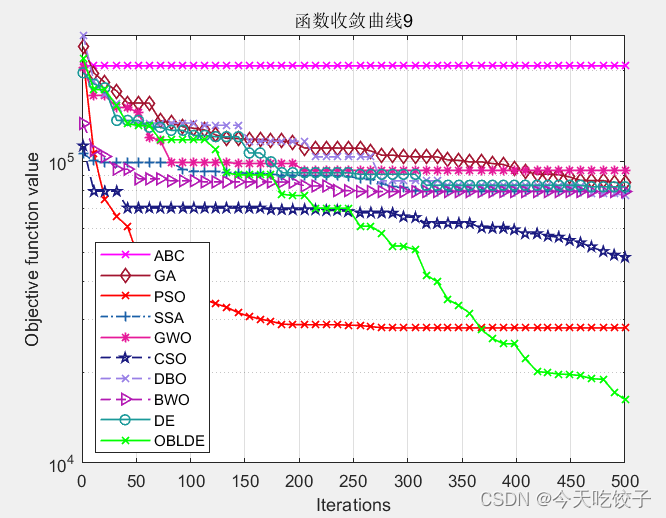
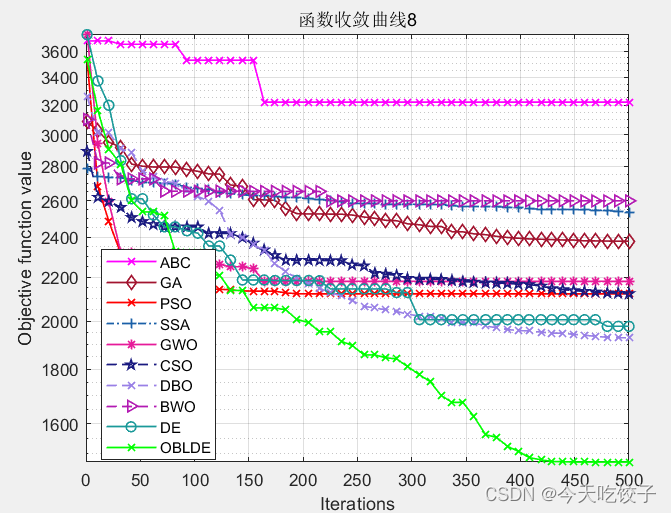
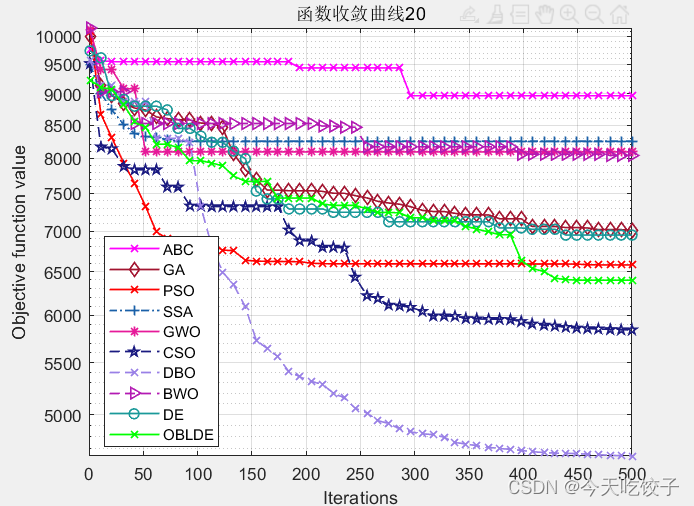

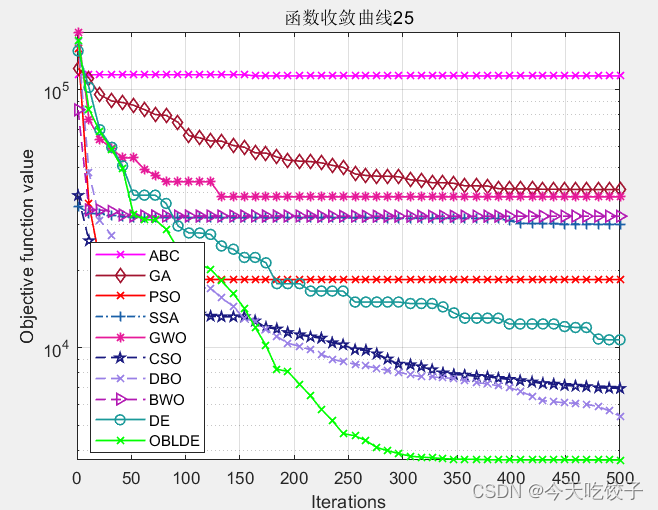
以上几个函数,都是我随机选择的,其他函数我没有一一测试。看上去确实很花里胡哨哈!大家可以根据自己需求进行删减。
不过就从这个随机选择的函数中,OBLDE算法(也就是动态反向学习的DE算法)在每个函数中的表现确实还不错!因此大家今后在改进智能算法的时候,可以参考这个动态反向学习的方法进行改进。
接下来到了最关键的上代码阶段!但是,无奈10个算法代码量实在是太大了,这里就截取部分代码啦!
【关键词:智能算法,优化算法,下方卡片任选其一回复。】
clear
clc
close all
addpath(genpath(pwd));
func_num=25; %选择函数
D=100; %维度
lb=-100; %下限
ub=100; %上限
N=50; %种群个数
T=500; %迭代次数
fhd=str2func('cec17_func'); %选择cec2017
%% 各类算法
[OBLDEfMin,OBLDEbestX,OBLDE_curve]=OBL_impDE(fhd,func_num,N,T,lb,ub,D); %动态反向学习的DE算法
[DEfMin,DEbestX,DE_curve]=DE(fhd,func_num,N,T,lb,ub,D); %DE算法
[Alpha_score,Alpha_pos,GWO_curve]=GWO(fhd,func_num,N,T,lb,ub,D); %灰狼算法
pso_curve=PSO(fhd,func_num,N,T,lb,ub,D); %粒子群算法
[bestchrom,GA_trace]=ga(fhd,func_num,N,T,lb,ub,D); %遗传算法
ABC_trace = ABC(fhd,func_num,N,T,lb,ub,D); %人工蜂群
[CSO_Best_score,CSO_Best_pos,cso_trace] = CSO(fhd,func_num,N,T,lb,ub,D); %鸡群算法
[fMin,bestX,DBO_curve]=DBO(fhd,func_num,N,T,lb,ub,D); %蜣螂优化
[BWO_Best_pos,BWO_Best_score,BWO_curve] = BWO(fhd,func_num,N,T,lb,ub,D); %白鲸优化算法
%% 麻雀
%设置SSA算法的参数
Params.nVar=D; % 优化变量数目
Params.VarSize=[1 Params.nVar]; % Size of Decision Variables Matrix
Params.VarMin=lb; % 下限值,分别是a,k
Params.VarMax=ub; % 上限值
Params.MaxIter=T; % 最大迭代数目
Params.nPop=N; % 种群规模
[particle3, GlobalBest3,SD,GlobalWorst3,Predator,Joiner] = SSAInitialization(fhd,func_num,Params,'SSA'); %初始化SSA参数
[GlobalBest,SSA_curve] = SSA(fhd,func_num,GlobalBest3,GlobalWorst3,SD,Predator,Joiner,Params); %采用SSA参数优化VMD的两个参数
%由于麻雀算法是将各个参数放进了一个结构体,这里作者不想再去折腾改了,因此麻雀算法单独设计。
%% 画图
CNT=50;
k=round(linspace(1,T,CNT)); %随机选50个点
% 注意:如果收敛曲线画出来的点很少,随机点很稀疏,说明点取少了,这时应增加取点的数量,100、200、300等,逐渐增加
% 相反,如果收敛曲线上的随机点非常密集,说明点取多了,此时要减少取点数量
iter=1:1:T;
semilogy(iter(k),ABC_trace(k),'m-x','linewidth',1);
hold on
semilogy(iter(k),GA_trace(k),'Color',[0.6350 0.0780 0.1840],'Marker','d','LineStyle','-','linewidth',1);
hold on
semilogy(iter(k),pso_curve(k),'r-x','linewidth',1);
hold on
semilogy(iter(k),SSA_curve(k),'Color',[0.1 0.3780 0.66],'Marker','+','LineStyle','-.','linewidth',1);
hold on
semilogy(iter(k),GWO_curve(k),'Color',[0.9 0.1 0.6],'Marker','*','LineStyle','-','linewidth',1);
hold on
semilogy(iter(k),cso_trace(k),'Color',[0.1 0.1 0.5],'Marker','p','LineStyle','--','linewidth',1);
hold on
semilogy(iter(k),DBO_curve(k),'Color',[0.6 0.5 0.9],'Marker','x','LineStyle','--','linewidth',1);
hold on
semilogy(iter(k),BWO_curve(k),'Color',[0.7 0.1 0.7],'Marker','>','LineStyle','--','linewidth',1);
hold on
semilogy(iter(k),DE_curve(k),'Color',[0.1 0.6 0.6],'Marker','o','LineStyle','-','linewidth',1);
hold on
semilogy(iter(k),OBLDE_curve(k),'g-x','linewidth',1);
grid on;
title(['函数收敛曲线',num2str(func_num)])
xlabel('Iterations');
ylabel('Objective function value');
box on
legend('ABC','GA','PSO','SSA','GWO','CSO','DBO','BWO','DE','OBLDE')粒子群算法:
% Particle Swarm Optimization
function cg_curve=PSO(fhd,func_num,N,Max_iteration,lb,ub,dim)
%PSO Infotmation
Vmax=6;
noP=N;
wMax=0.5;
wMin=0.2;
c1=1.1;
c2=1.1;
% Initializations
iter=Max_iteration;
vel=zeros(noP,dim);
pBestScore=zeros(noP);
pBest=zeros(noP,dim);
gBest=zeros(1,dim);
cg_curve=zeros(1,iter);
% Random initialization for agents.
pos=initialization(noP,dim,ub,lb);
for i=1:noP
pBestScore(i)=inf;
end
% Initialize gBestScore for a minimization problem
gBestScore=inf;
for l=1:iter
% Return back the particles that go beyond the boundaries of the search
% space
Flag4ub=pos(i,:)>ub;
Flag4lb=pos(i,:)<lb;
pos(i,:)=(pos(i,:).*(~(Flag4ub+Flag4lb)))+ub.*Flag4ub+lb.*Flag4lb;
for i=1:size(pos,1)
%Calculate objective function for each particle
fitness= feval(fhd, pos(i,:)',func_num);
if(pBestScore(i)>fitness)
pBestScore(i)=fitness;
pBest(i,:)=pos(i,:);
end
if(gBestScore>fitness)
gBestScore=fitness;
gBest=pos(i,:);
end
end
%Update the W of PSO
w=wMax-l*((wMax-wMin)/iter);
%Update the Velocity and Position of particles
for i=1:size(pos,1)
for j=1:size(pos,2)
vel(i,j)=w*vel(i,j)+c1*rand()*(pBest(i,j)-pos(i,j))+c2*rand()*(gBest(j)-pos(i,j));
if(vel(i,j)>Vmax)
vel(i,j)=Vmax;
end
if(vel(i,j)<-Vmax)
vel(i,j)=-Vmax;
end
pos(i,j)=pos(i,j)+vel(i,j);
end
end
cg_curve(l)=gBestScore;
end
endGWO灰狼算法代码:
% Grey Wolf Optimizer
function [Alpha_score,Alpha_pos,Convergence_curve]=GWO(fhd,func_num,SearchAgents_no,Max_iter,lb,ub,dim)
% initialize alpha, beta, and delta_pos
Alpha_pos=zeros(1,dim);
Alpha_score=inf; %change this to -inf for maximization problems
Beta_pos=zeros(1,dim);
Beta_score=inf; %change this to -inf for maximization problems
Delta_pos=zeros(1,dim);
Delta_score=inf; %change this to -inf for maximization problems
%Initialize the positions of search agents
Positions=initialization(SearchAgents_no,dim,ub,lb);
Convergence_curve=zeros(1,Max_iter);
l=0;% Loop counter
% Main loop
while l<Max_iter
for i=1:size(Positions,1)
% Return back the search agents that go beyond the boundaries of the search space
Flag4ub=Positions(i,:)>ub;
Flag4lb=Positions(i,:)<lb;
Positions(i,:)=(Positions(i,:).*(~(Flag4ub+Flag4lb)))+ub.*Flag4ub+lb.*Flag4lb;
% Calculate objective function for each search agent
fitness=feval(fhd, Positions(i,:)',func_num);
% Update Alpha, Beta, and Delta
if fitness<Alpha_score
Alpha_score=fitness; % Update alpha
Alpha_pos=Positions(i,:);
end
if fitness>Alpha_score && fitness<Beta_score
Beta_score=fitness; % Update beta
Beta_pos=Positions(i,:);
end
if fitness>Alpha_score && fitness>Beta_score && fitness<Delta_score
Delta_score=fitness; % Update delta
Delta_pos=Positions(i,:);
end
end
a=2-l*((2)/Max_iter); % a decreases linearly fron 2 to 0
% Update the Position of search agents including omegas
for i=1:size(Positions,1)
for j=1:size(Positions,2)
r1=rand(); % r1 is a random number in [0,1]
r2=rand(); % r2 is a random number in [0,1]
A1=2*a*r1-a; % Equation (3.3)
C1=2*r2; % Equation (3.4)
D_alpha=abs(C1*Alpha_pos(j)-Positions(i,j)); % Equation (3.5)-part 1
X1=Alpha_pos(j)-A1*D_alpha; % Equation (3.6)-part 1
r1=rand();
r2=rand();
A2=2*a*r1-a; % Equation (3.3)
C2=2*r2; % Equation (3.4)
D_beta=abs(C2*Beta_pos(j)-Positions(i,j)); % Equation (3.5)-part 2
X2=Beta_pos(j)-A2*D_beta; % Equation (3.6)-part 2
r1=rand();
r2=rand();
A3=2*a*r1-a; % Equation (3.3)
C3=2*r2; % Equation (3.4)
D_delta=abs(C3*Delta_pos(j)-Positions(i,j)); % Equation (3.5)-part 3
X3=Delta_pos(j)-A3*D_delta; % Equation (3.5)-part 3
Positions(i,j)=(X1+X2+X3)/3;% Equation (3.7)
end
end
l=l+1;
Convergence_curve(l)=Alpha_score;
end
关键词:大比拼,优化算法,下方卡片任选其一回复。
欢迎大家评论区留言哦!

















 3609
3609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











