






截止到本期,一共发了11篇关于机器学习预测全家桶Python代码的文章。参考往期文章如下:
2.机器学习预测全家桶-Python,一次性搞定多/单特征输入,多/单步预测!最强模板!
3.机器学习预测全家桶-Python,新增CEEMDAN结合代码,大大提升预测精度!
4.机器学习预测全家桶-Python,新增VMD结合代码,大大提升预测精度!
5.Python机器学习预测+回归全家桶,再添数十种回归模型!这次千万别再错过了!
6.Python机器学习预测+回归全家桶,新增TCN,BiTCN,TCN-GRU,BiTCN-BiGRU等组合模型预测
7.调用最新mealpy库,实现215个优化算法优化CNN-BiLSTM-Attention,电力负荷预测
8.Transformer实现风电功率预测,python预测全家桶
9.几个小创新模型,KAN组合网络(LSTM、GRU、Transformer)时间序列预测
10.几个小创新模型,KAN组合网络(LSTM、GRU、Transformer)回归预测
11.接着更!seq2seq、wavenet、bert、informer、RNN时间预测模型
12.重大更新!建议所有人都下载!Python预测全家桶小白版
13.215个优化算法优化30余个机器学习预测模型,一键更改多/单输入,多/单步预测
上次更新对python全家桶增加了215个优化算法优化机器学习预测模型,本期继续更新,增加215个优化算法优化30余个机器学习回归模型。
30个机器学习模型包含如下:
CNN_BiLSTM、CNN_BiLSTM_Attention、BiGRU、BiGRU_Attention、
BiLSTM、BiLSTM_Attention、BiTCN_BiGRU、BiTCN_GRU、BiTCN_LSTM
、CNN_BiGRU_Attention、CNN_BiGRU、CNN_GRU_Attention、CNN_GRU、
CNN_LSTM_Attention、CNN_LSTM、GRU、GRU_Attention、LSTM、
LSTM_Attention、TCN、TCN_RNN、TCN_LSTM、TCN_GRU、TCN_BiGRU、
Transformer、BiLSTM_KAN、GRU_KAN、LSTM_KAN、Transformer_KAN什么?!一下子对30余个模型进行优化?怎么可能,怎么做到的!
大家可能会经常看到很多博主,各种不同优化算法与不同模型随便组合一下,就是一篇推文,像我这里,一下子综合这么多模型的,毫不客气的说:全网独一份!
本期代码在上一期的基础上,采用mealpy库直接完成对30多个模型库的调用,并将可调的每个模型参数单独写成了函数,上下限范围的设置也包装成了函数,这样直接在主函数即可调用啦!目的就是方便小白也能轻松掌握优化算法优化机器学习模型。
经常写代码的小伙伴肯定会明白此次代码改写的工作量。也能看到,我这里的全家桶是真的一直一直在用心更新的!
接下来先给大家看一下代码主函数,如果你是小白刚接触的,只要读懂以下代码,即可完成优化算法对机器学习模型的调用。
dataset=pd.read_csv("共享单车租赁数据集.csv",encoding='gb2312')
# 使用pandas模块的read_csv函数读取名为"共享单车租赁数据集.csv"的文件。
# 参数'encoding'设置为'gbk',这通常用于读取中文字符,确保文件中的中文字符能够正确读取。
# 读取的数据被存储在名为'dataset'的DataFrame变量中。
values = dataset.values[:,2:] #只取第2列数据,要写成1:2;只取第3列数据,要写成2:3,取第2列之后(包含第二列)的所有数据,写成 1:
## 开始实验!!只改下面三行即可切换案例!!
ratio = [0.7,0.2,0.1] # 设置训练集:验证集:测试集 = 7:2:1
# 调用数据整理的函数,关于测函数的机理是什么,请跳转Shared_def函数中查看regress_fit_datacollation的注释
n_out = 2 #选择最后几列作为预测列? # 当数据的最后一列是目标值时候,就给n_out赋值1即可,当数据的最后两列都是目标值时候,就给n_out赋值2即可……,以此类推
vp_train, vp_vaild, vp_test, vt_train,vt_vaild, vt_test, m_out, Yvaild,Ytest =regress_fit_datacollation(values,n_out,ratio)
num_samples, train_ratio)
''' 调用优化算法 '''
# 修改这里的flag即可切换模型
'''
可选flag有:
CNN_BiLSTM、CNN_BiLSTM_Attention、BiGRU、BiGRU_Attention、BiLSTM、BiLSTM_Attention、BiTCN_BiGRU、BiTCN_GRU、BiTCN_LSTM、BP、
CNN_BiGRU_Attention、CNN_BiGRU、CNN_GRU_Attention、CNN_GRU、CNN_LSTM_Attention、CNN_LSTM、GRU、GRU_Attention、LSTM、
LSTM_Attention、TCN、TCN_RNN、TCN_LSTM、TCN_GRU、TCN_BiGRU、XGBOOST、Transformer、BiLSTM_KAN、GRU_KAN、LSTM_KAN、Transformer_KAN、
'''
flag = 'Transformer'
epoch = 8 # 最大迭代次数
pop_size = 5 # 种群数量
##需要替换算法的小伙伴,直接按 Ctrl+R查找替换,将本代码的 GWO 全部替换为别的,比如 PSO,WOA算法等
optimized_model = GWO.OriginalGWO(epoch=epoch, pop_size=pop_size)
# 提取算法名字
optimized_name = optimized_model.name[8:]
def Objfun(x):
plotloss_, savemodel_, saveexcel_ = False,False,False
MSe_error, test_pred = fun(x,flag, optimized_name,plotloss_, savemodel_, saveexcel_,vp_train, vp_test, vt_train, vt_test, m_out, n_out, n_in, or_dim,Ytest)
return MSe_error
lb_,ub_ = LBUB(flag)
problem_dict = {
"obj_func": Objfun,
"bounds": FloatVar(lb=lb_, ub=ub_),
# 分别对应学习率,神经元,CNN核大小,迭代次数,注意CNN核大小设置的时候不能超过每个vp_train的行数!也就是不能超过n_in
"minmax": "min",
}
''' Objfun->目标函数, lb->下限, ub->上限 '''
'''求解'''
bestsolution = optimized_model.solve(problem_dict)
# 保存优化结果
savemat('优化后预测结果保存/'+optimized_name+'_optimized_paras.mat', {'trace': optimized_model.history.list_global_best_fit , 'bestx': bestsolution.solution, 'result': bestsolution.target})
# 将优化结果保存到MAT文件中。'trace'记录每次迭代的适应度值,'best'是最优参数,'result'是每次迭代的最优结果。
plt.ion()
plt.figure(figsize=(3, 1.5), dpi=250)
# plt.semilogy(Curve,'r-',linewidth=2)
x=np.arange(0,epoch)+1
x[0]=1
my_x_ticks = np.arange(1, epoch+1, 1)
plt.xticks(my_x_ticks)
plt.plot(x,optimized_model.history.list_global_best_fit ,'r-' ,linewidth=1,label = 'PSO',marker = "x",markersize=3)
plt.xlabel('Iterations', fontsize=5)
# 设置x轴标签为“迭代次数”。
plt.ylabel('fitness', fontsize=5)
# 设置y轴标签为“适应度值”。
plt.title("Iterative curve of optimization algorithm")
plt.savefig('优化后预测结果保存/'+optimized_name+'_'+flag+'优化算法收敛曲线.png')
plt.ioff() # 关闭交互模式
plt.show()# 显示绘制的图形。
if flag == 'XGBOOST':
print("请自行取整,最佳参数分别为:", [bestsolution.solution[i] if i > 0 else bestsolution.solution[i] for i in range(3,len(bestsolution.solution))])
else:
print("请自行取整,最佳参数分别为:", [bestsolution.solution[i] if i > 0 else bestsolution.solution[i] for i in
range(len(bestsolution.solution))])
'''
# ………………………………………………………………利用优化的参数建模……………………………………………………………………………………
'''
tf.random.set_seed(0)# 设置TensorFlow的随机种子,以确保实验的可重复性。
np.random.seed(0)# 设置numpy的随机种子。
best_pop=loadmat('优化后预测结果保存/'+optimized_name+'_optimized_paras.mat')['bestx'].reshape(-1,)
plotloss_, savemodel_, saveexcel_ = True,True,True #将最佳参数带入,并保存优化后的模型
MApe_error,Optimized_test_pred = fun(best_pop,flag,optimized_name,plotloss_, savemodel_, saveexcel_,vp_train, vp_test, vt_train, vt_test, m_out, n_out,Ytest)
print('优化后的预测结果指标:')
#调用已经写好绘图函数
FLAG = optimized_name+'_'+flag
plot_regress_result(Optimized_test_pred, Ytest, n_out,FLAG)
mse_dic,rmse_dic, mae_dic, mape_dic, r2_dic, table = evaluate_regress_forecasts(Ytest, Optimized_test_pred, n_out)
print(table)看一下上述主函数的代码,是不是非常的简单易懂,清晰明了。
想修改模型的,直接更改参数flag,想改智能优化算法的直接替换一下原代码的GWO。这样你就可以得到任意你想要的组合啦!
除了修改模型方便这个优点外,本期还增加了以下功能:
自动保存优化后的预测模型,方便之后直接加载模型进行预测。

自动保存各个算法优化不同模型后的预测结果为excel格式,并以算法名字和模型名字来命名,这样大家就好区分,更好做对比了,如下:
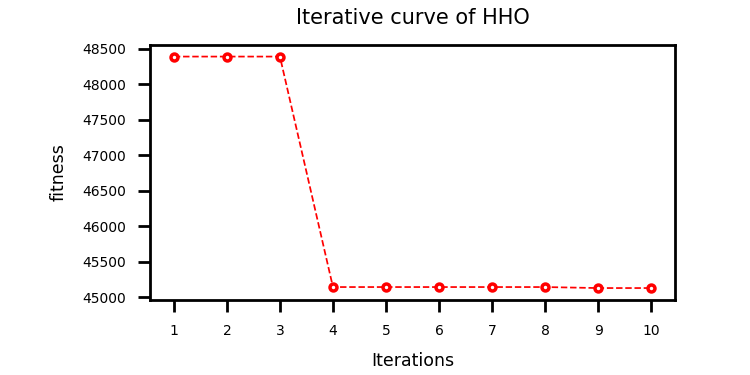
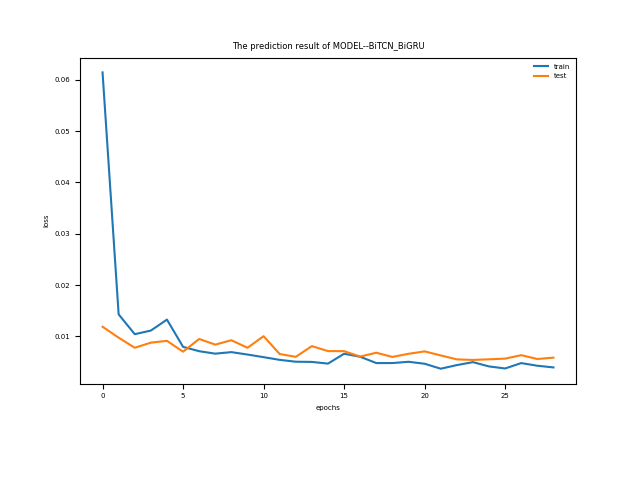
自动保存优化后的预测结果图,损失函数曲线,优化算法收敛曲线。
代码目录更是一目了然,小白也是一看就懂:
接下来让我们简单挑选几个模型进行结果展示吧!
案例1:
采用粒子群算法优化BiTCN_LSTM的超参数(
# 依次为:训练次数,beach_size,学习率,TCN滤波器个数,滤波器核大小,正则化参数,LSTM隐含层单元个数)上下限设置如下:lb = [20, 8, 1e-4, 32, 2, 0.1, 30]
# 依次为:训练次数,beach_size,学习率,TCN滤波器个数,滤波器核大小,正则化参数,LSTM隐含层单元个数
ub = [50, 32, 1e-3, 128, 6, 0.3, 200]结果:
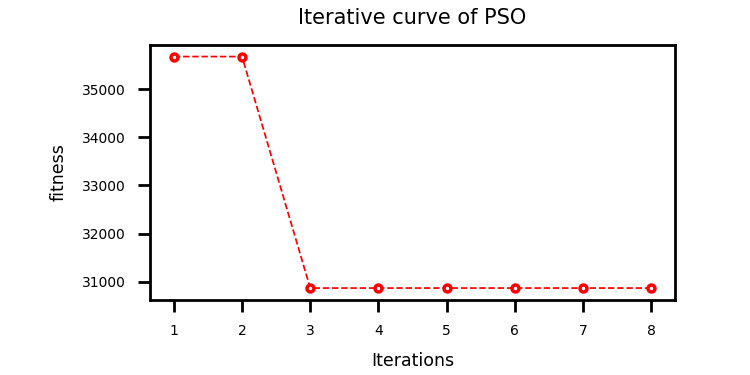
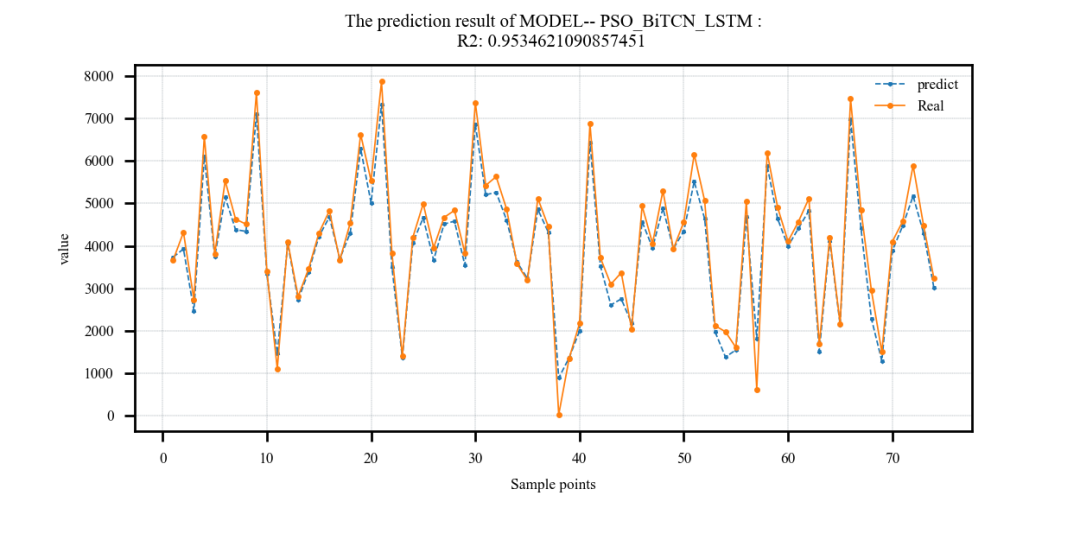
案例2:
采用麻雀算法优化CNN_BiLSTM的超参数(
# 依次为:训练次数,beach_size,学习率,LSTM隐含层单元个数,层数)上下限设置如下:lb = [20, 8, 1e-4, 32, 2, 0.1, 30]
#依次为:训练次数,beach_size,学习率,CNN滤波器个数,滤波器核大小,正则化参数,LSTM隐含层单元个数
ub = [50, 32, 1e-3, 128, 6, 0.3, 200]结果: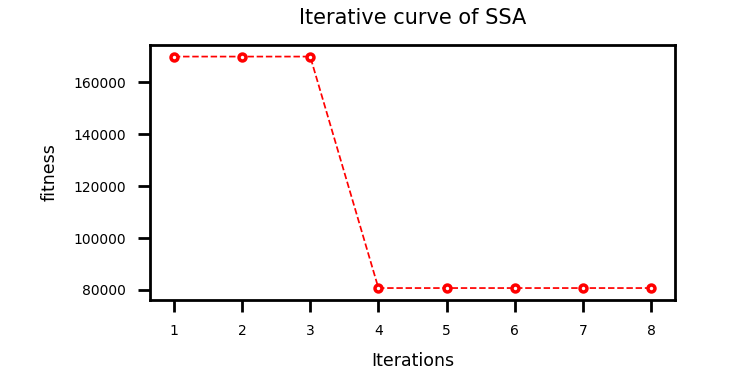
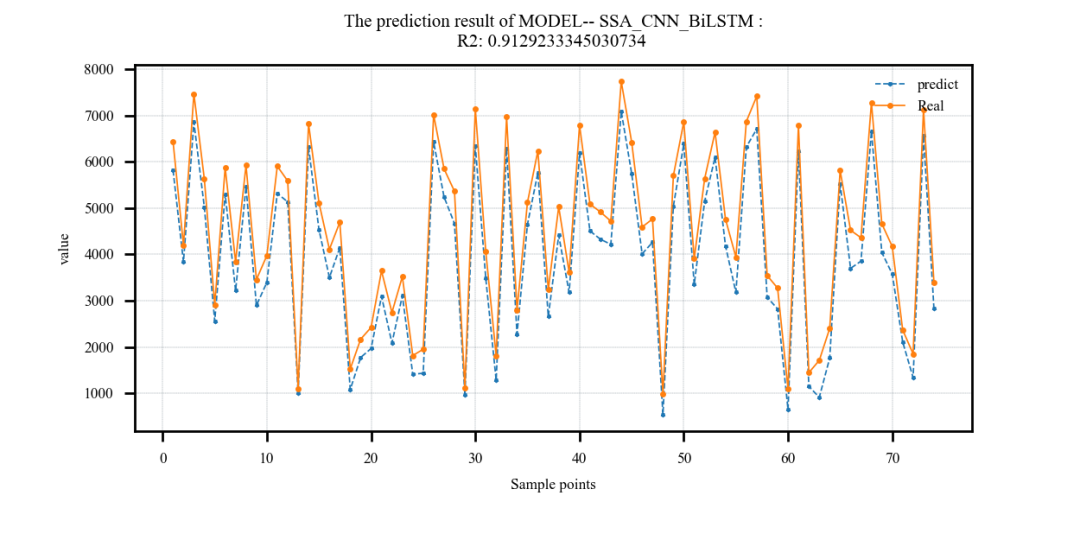
案例3:
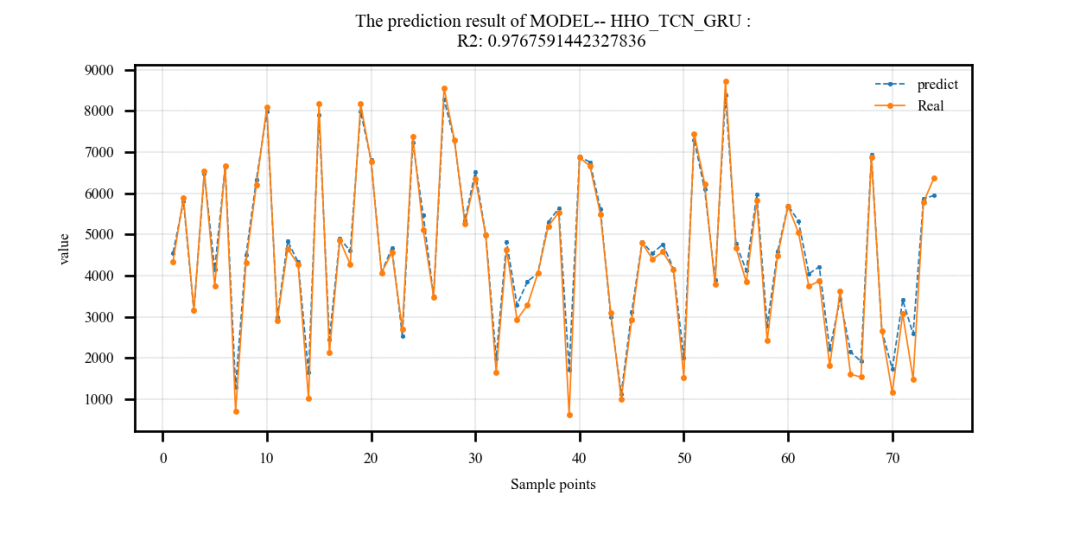
采用哈里斯鹰优化算法算法优化TCN_GRU的超参数(
# 依次为:训练次数,beach_size,学习率,正则化参数,GRU隐含层单元个数)上下限设置如下:lb = [20, 8, 1e-4, 32, 2, 0.1, 30]
# 依次为:训练次数,beach_size,学习率,TCN滤波器个数,滤波器大小,正则化参数,神经元个数
ub = [50, 32, 1e-3, 128, 6, 0.3, 200]结果: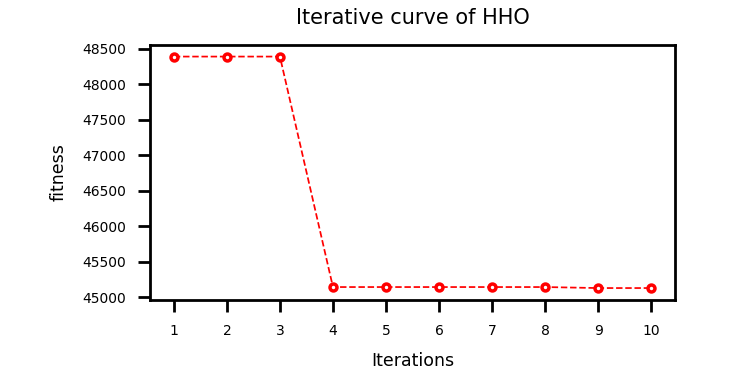
代码获取
已将本文代码更新至python预测全家桶。
后续会继续更新一些其他模型……敬请期待!
机器学习python全家桶代码获取
https://mbd.pub/o/bread/ZZqXmpty
识别此二维码也可跳转全家桶
后续有更新直接进入此链接,即可下载最新的!

或点击下方阅读原文获取此全家桶。
python预测全家桶pip包推荐版如下:
numpy~=1.26.4
matplotlib~=3.8.4
scipy~=1.13.0
xgboost~=2.1.1
torch~=2.3.1
joblib~=1.4.2
keras~=2.15.0
tensorflow~=2.15.0
scikit-learn~=1.4.2
prettytable~=3.10.0
pandas~=2.2.2
mealpy~=3.0.1推荐使用3.9版本的python哦!
获取更多代码:

或者复制链接跳转:
https://docs.qq.com/sheet/DU3NjYkF5TWdFUnpu















 1673
1673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











