






截止到本期,一共发了9篇关于机器学习预测全家桶Python代码的文章。参考往期文章如下:
2.机器学习预测全家桶-Python,一次性搞定多/单特征输入,多/单步预测!最强模板!
3.机器学习预测全家桶-Python,新增CEEMDAN结合代码,大大提升预测精度!
4.机器学习预测全家桶-Python,新增VMD结合代码,大大提升预测精度!
5.Python机器学习预测+回归全家桶,再添数十种回归模型!这次千万别再错过了!
6.Python机器学习预测+回归全家桶,新增TCN,BiTCN,TCN-GRU,BiTCN-BiGRU等组合模型预测
7.调用最新mealpy库,实现215个优化算法优化CNN-BiLSTM-Attention,电力负荷预测
8.Transformer实现风电功率预测,python预测全家桶
9.几个小创新模型,KAN组合网络(LSTM、GRU、Transformer)时间序列预测,python预测全家桶
上一期在python预测全家桶更新了关于KAN组合网络的预测模型,今天继续更新关于KAN网络的回归模型。
本次更新可以一键更改不同KAN网络的组合模型,而且可以一键实现单输出和多输出回归的简单切换。
一、KAN网络模型概述
KAN网络属于近期非常热门的一个模型,与传统的MLP架构截然不同,KAN网络能用更少的参数在数学、物理问题上取得更高精度。KAN其灵感来源于 Kolmogorov-Arnold 定理,这个定理的含义就是任意一个多变量连续函数都可以表现为一些单变量函数的组合。
KAN的核心特点是在网络的边缘(即权重)上拥有可学习的激活函数,而不是像传统的MLPs那样在节点(即神经元)上使用固定的激活函数。并且KAN的准确性和可解释性要比MLP好很多。
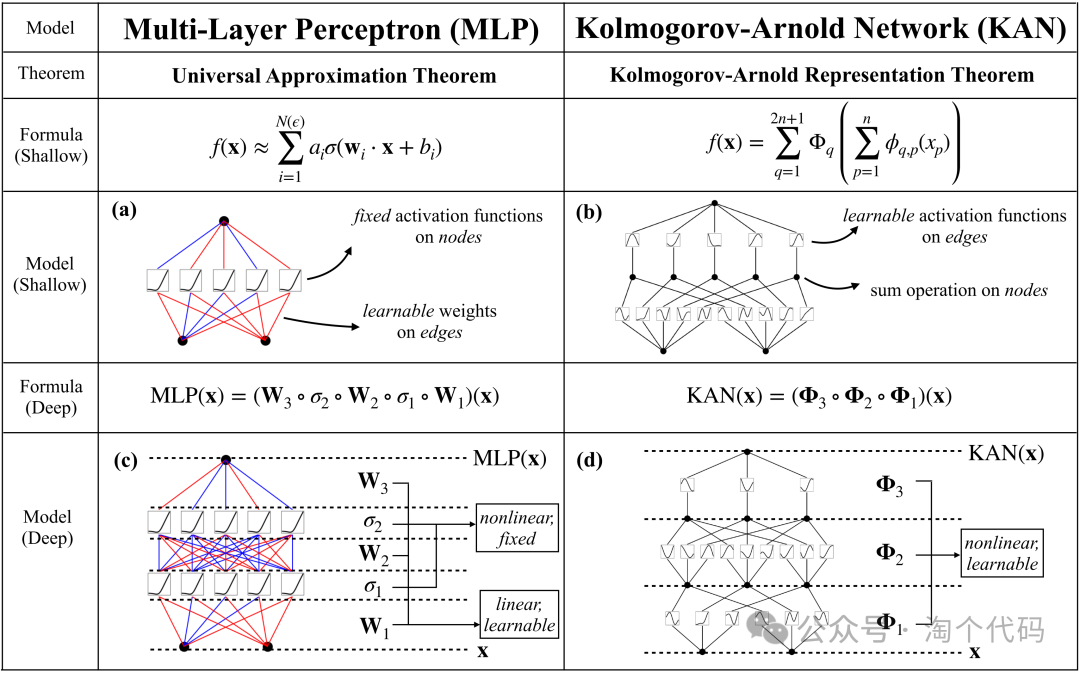
KAN的优点:
1. KAN可以避免大模型的灾难性遗忘问题
2. 在函数拟合、偏微分方程求解方面,KAN比MLP更准确
3. KAN可以直观地可视化。KAN 提供MLP无法提供的可解释性和交互性
KAN的缺点:
1.训练速度慢:因为训练一个激活函数,需要无限多的循环进行验证
2. 对于更深层结构可解释性是否还存在,论文中给出的实验只是浅层的
3.KAN网络在求解非线性函数等工程问题时更精确,但在时间序列预测方面,训练起来就非常慢。但是将其作为网络的一个小的改进点,还是可以的。
二、KAN网络组合模型
本期带来几个KAN网络的回归组合模型:LSTM-KAN、BiLSTM-KAN、GRU-KAN、TCN-KAN、Transformer-KAN。
以UCI数据集中的《共享单车租赁数量.csv》数据为例,可以看到,除时间序列外,数据共有14列,其中前13列为特征列,最后一列为输出列,也就是自行车的租赁数量。

以上这个数据是一个多输入单输出的回归问题。
三、多输入单输出实验结果展示:
设置训练集测试集比例为8:2,并采用各大KAN组合模型预测。
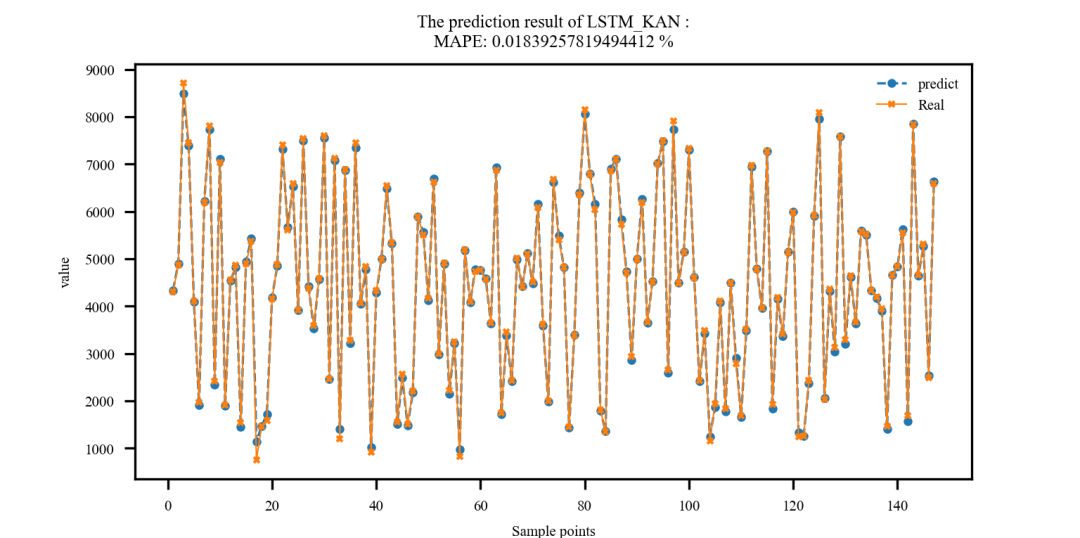
LSTM-KAN回归预测结果:

BiLSTM-KAN回归预测结果:


TCN-KAN回归预测结果:


Transformer-KAN回归预测结果:


四、多输入多步预测实验结果展示:
除此之外,还可以进行多步回归预测。
由于作者这里没有关于多步回归预测的合适数据,因此还用这个《共享单车租赁数量.csv》数据为例进行介绍。现在我们暂且把最后2列当做预测值,也就是说,将前12列作为数据特征,来同时预测注册数量和租赁数量。
结果如下:
TCN-KAN多步回归预测结果:
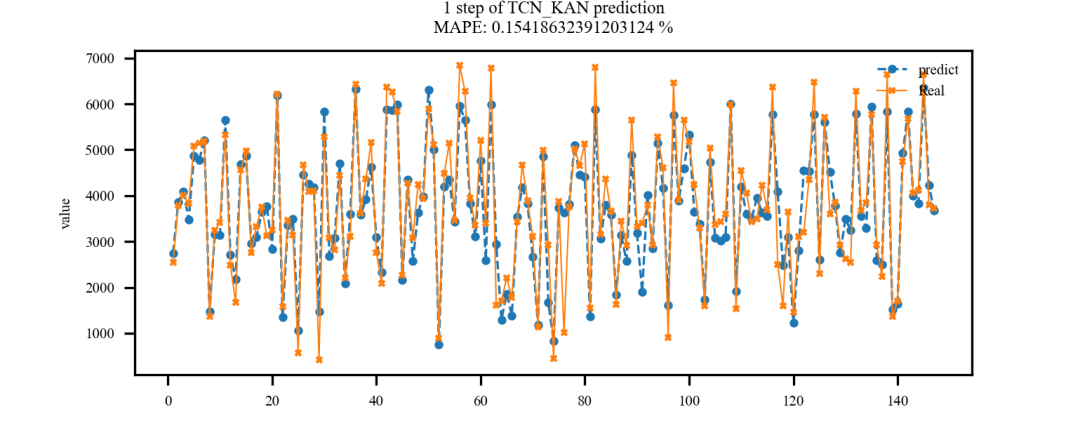


这里的第一步即注册数量的预测结果,第二步即租赁数量的预测结果。
这样一来,我们就实现了多输出的回归预测。代码中只需要修改一个参数即可,简单便捷!其他模型就不再一一展示。
代码获取
已将本文代码更新至python预测全家桶。
后续会继续更新一些其他模型……敬请期待!
机器学习python全家桶代码获取
https://mbd.pub/o/bread/ZZqXmpty
识别此二维码也可跳转全家桶
后续有更新直接进入此链接,即可下载最新的!

或点击下方阅读原文获取此全家桶。
python预测全家桶pip包推荐版如下:
tensorflow~=2.15.0
pandas~=2.2.0
openpyxl~=3.1.2
matplotlib~=3.8.2
numpy~=1.26.3
keras~=2.15.0
mplcyberpunk~=0.7.1
scikit-learn~=1.4.0
scipy~=1.12.0
qbstyles~=0.1.4
prettytable~=3.9.0
vmdpy~=0.2
xgboost~=2.0.3
mealpy~=3.0.1
torch~=2.3.1推荐使用3.9版本的python哦!
获取更多代码:

或者复制链接跳转:
https://docs.qq.com/sheet/DU3NjYkF5TWdFUnpu















 1392
1392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











