







李航老师在《统计学习方法》中讲过:统计学习方法都是由模型、策略和算法构成的。在这篇博文中,学习一下策略。
策略就是在有了模型的假设空间之后,考虑按照什么样的准则学习或者选择最优的模型,统计学习的目标就在于从假设空间中选取最优模型。策略其实可以认为是根据模型导出来的目标函数、评价函数。
(1)损失函数:
(a)0-1损失函数。
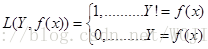
0-1损失函数就是预测值与真实标签相同为0,不相同为1。
(b)平方损失函数(quadratic loss function)
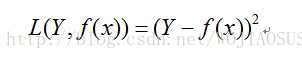
线性回归中使用的最小二乘法就是平方损失函数
(c)绝对损失函数(absolute loss fuction)
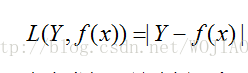
(d)对数损失函数(logarithmic loss function)
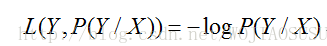
逻辑斯蒂回归中的逻辑斯蒂损失就属于对数损失
(e)合页损失 (hinge loss) 支持向量机SVM中用到的。
(f)指数损失 提升树里面用到的。
(2)给定一个训练数据集,模型f(x)关于训练数据集的平均损失称为经验风险或者经验损失
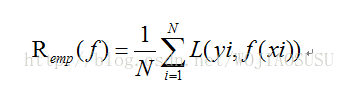
在假设空间、损失函数以及训练数据集确定的情况下,经验风险函数式(上式形式就可以确定)。经验风险最小化认为(ERM)策略认为,经验风险最小的模型是最优的模型。根据这个策略,模型就是求解最优化问题:
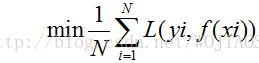
当样本量足够大的时候,经验风险最小化能保证有很好的学习效果,在现实中广泛被采用。但是当样本容量很小时,经验风险最小化的学习效果就未必很好,会产生过拟合(over-fitting)现象。
结构风险最小化(SRM)是为了防止过拟合而提出的策略。结构风险最小化等价于正则化。结构风险最小化就是在经验风险上加上表示模型复杂度的正则化项或者罚项。
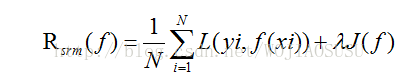
模型f越复杂,复杂度就越高,模型越简单,复杂度就越小。即复杂度表示了对复杂模型的惩罚。
结构风险最小化策略认为结构风险最小的模型是最优模型,所以求最优模型时,就是求解最优化问题:
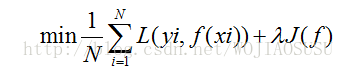
第二部分内容就是主要介绍了经验风险最小化与结构风险最小化。两者的联系与区别。
(3)模型评估与模型选择
统计学习的目的是使学到的模型不仅对已知数据而且对未知数据都能有很好的预测能力。不同的学习方法得到不同的模型。当损失函数给定时,基于损失函数的模型的训练误差(train error)和模型的测试误差(test error)就成了学习方法评估的标准。
训练误差的大小,对判定给定的问题是不是一个容易学习的问题是有意义的,但本质上不重要。测试误差反映了学习方法对未知的测试数据集的预测能力,是学习中的重要概念。显然,给定两种学习方法,测试误差小的方法具有更好的预测能力,是更有效的方法。通常将学习方法对未知数据的预测能力称为泛化能力。
如果一味追求提高训练数据的预测能力,所选模型的复杂度往往会比真模型更高。这种现象称为过拟合。过拟合是指学习时所选择的模型所包含的参数过多,以至于出现的这一模型对已知数据预测的很好,但对未知数据预测的很差的现象。
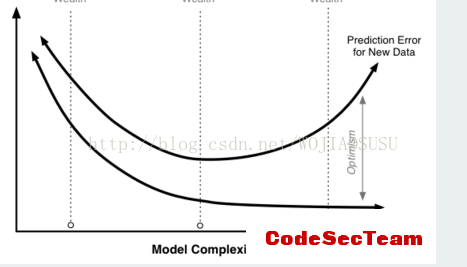
即在进行模型选择时,不仅要考虑对已知数据的预测能力,还要考虑对未知数据的预测能力。即结果好,还不复杂。
当模型的复杂度增大时,训练误差会逐渐减小并趋向于0.而测试误差会先减小后增大。当选择的模型的复杂度过大时,过拟合现象就会发生。即在学习时,要防止过拟合选择复杂度适当的模型,以达到使测试误差最小的学习目的。
过拟合可能的原因:
(1)建模样本抽取错误,包括(但不限于)样本数量太少,抽样方法错误,抽样时没有足够正确考虑业务场景或业务特点,等等导致抽出的样本数据不能有效足够代表业务逻辑或业务场景;
(2)就是样本里的噪音数据干扰过大,大到模型过分记住了噪音特征,反而忽略了真实的输入输出间的关系;这堆数据带有噪声,利用模型去拟合这堆数据,可能会把噪声数据也给拟合了,这点很致命,一方面会造成模型比较复杂(想想看,本来一次函数能够拟合的数据,现在由于数据带有噪声,导致要用五次函数来拟合,多复杂!),另一方面,模型的泛化性能太差了(本来是一次函数生成的数据,结果由于噪声的干扰,得到的模型是五次的),遇到了新的数据让你测试,你所得到的过拟合的模型,正确率是很差的。
(3)建模时的“逻辑假设”到了模型应用时已经不能成立了。任何预测模型都是在假设的基础上才可以搭建和应用的,常用的假设包括:假设历史数据可以推测未来,假设业务环节没有发生显著变化,假设建模数据与后来的应用数据是相似的,等等。如果上述假设违反了业务场景的话,根据这些假设搭建的模型当然是无法有效应用的。
(4)参数太多、模型复杂度高。
(5)决策树模型。如果我们对于决策树的生长没有合理的限制和修剪的话,决策树的自由生长有可能每片叶子里只包含单纯的事件数据(event)或非事件数据(no event),可以想象,这种决策树当然可以完美匹配(拟合)训练数据,但是一旦应用到新的业务真实数据时,效果是一塌糊涂。
解决方法:
(1)early stoping.其实就是限制迭代次数。这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradientdescent)学习算法。Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
(2)扩增数据。一份好的数据胜过一个好的模型。
(3)交叉验证
(4)正则化
这一部分内容还是蛮重要的面试官经常会问到。














 1977
1977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









