







上篇说到chroma的近邻搜索算法实现得有问题,不如qdrant的。其实向量数据库之间看似都一样,但细细比较还是有很多不同的。
国外有一系列文章已经讲得很详细了,而且也就是半年前写的,还是具有很强的参考价值,文章如下:
Vector databases (1): What makes each one different?
Vector databases (2): Understanding their internals
Vector databases (3): Not all indexes are created equal
Vector databases (4): Analyzing the trade-offs
里边有很多细节,不想细看的,我这里给几张图给大家快速了解不同向量数据库的差异。
存在时间
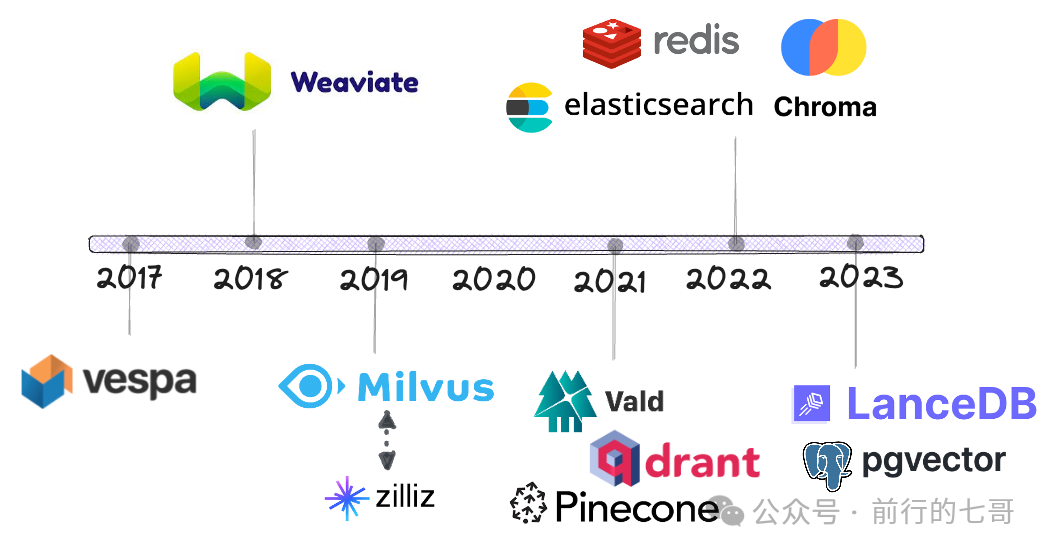
实现语言及是否开源

托管方法
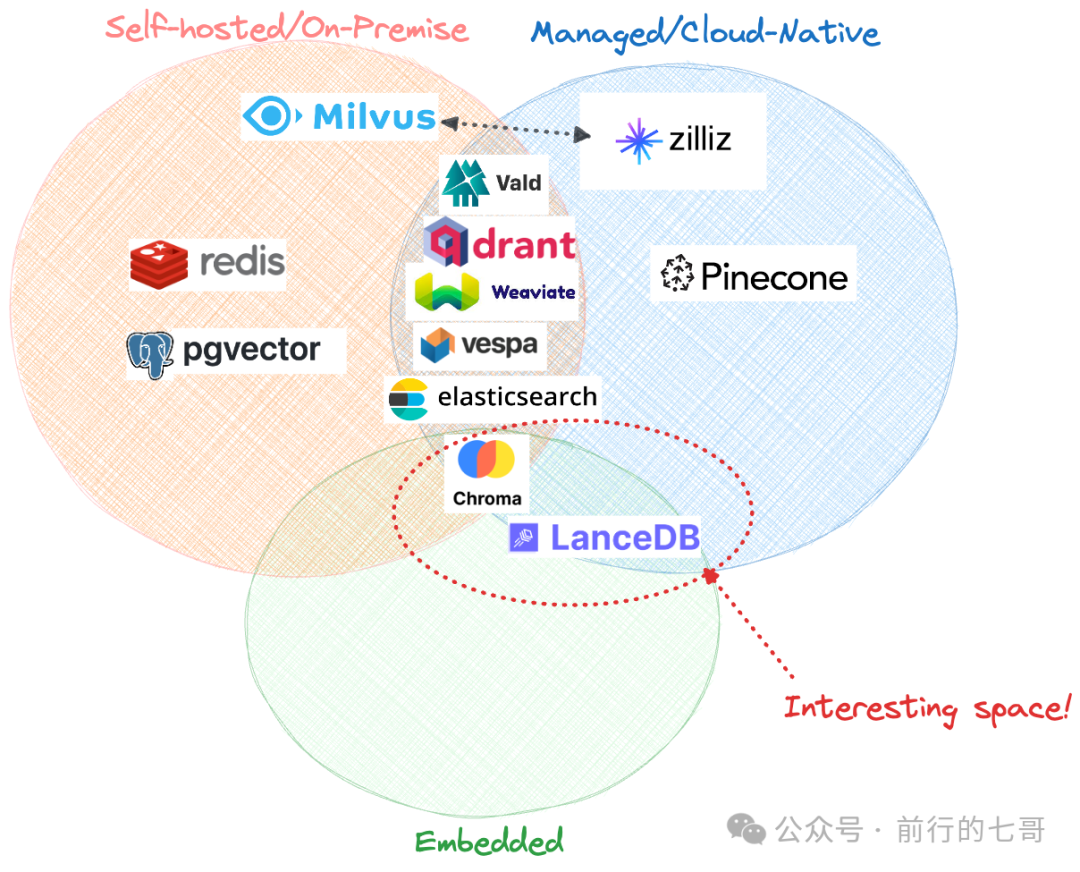
索引方法

向量压缩的概念
向量一般是由浮点数组成,比如float32。一个float32 占4个字节,当向量维度很高且向量很多时,向量存储空间会比较大,查询起来也会比较慢。优化的一种方式是压缩向量,比如改成用一个byte的整数来表示原来的float32。这样每个维度就从4个字节变成一个字节,存储空间变小,查询也变快。当然,压缩会损失精度,可能会导致求向量相似度的时候有误差。向量压缩的过程叫量化(Quantization)
上图中的Flat 表示按向量的原始方式存储向量,没有压缩。压缩的方式有标量量化Scalar Quantization (SQ) 和 乘积量化 Product Quantization (PQ)。上边举的例子(float32 -> byte)就是标量量化。
更多细节,请见文章开头给的四篇文章,我就不一一赘述了。
Qdrant的向量压缩算法
qdrant有篇文章介绍它的向量压缩算法,详细可见:
https://qdrant.tech/documentation/guides/quantization/
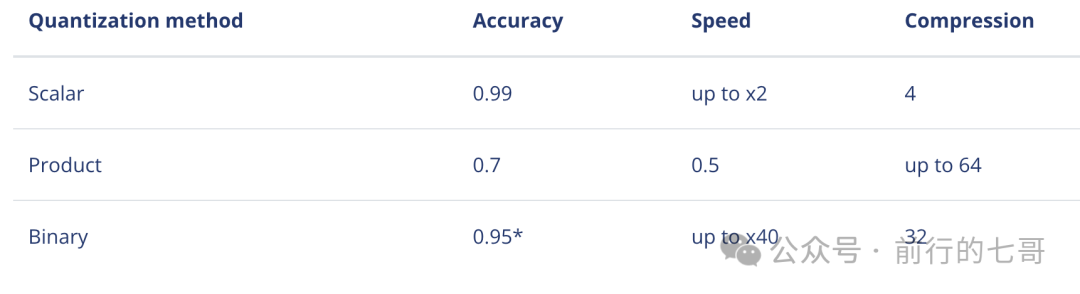
上边是qdrant的各种量化方式及对应的准确率,速度和压缩比。qdrant还支持了一种二进制量化压缩算法,速度可以提升到原来的40倍,存储效率是原来的32倍,只损失5%的准确率,但只建议用在测试过的向量模型。
qdrant的压缩查询优化
查询的时候如果不想用量化,可以直接设置参数 ignore 为true关闭量化向量的使用。如果配置了量化配置,默认使用量化向量进行查询。
为了提高量化后的向量查询的准确率,qdrant还支持rescore参数和oversampling参数。
rescore就是用量化后的向量查询出top k后,再用原始向量去对比,找出最相似的。比如我要top 3,你找出后再对比也还是在这3个向量之前再排序,看上去没有什么作用?加上oversampling 参数就可以很大用处了。
oversampling 就是预先取多多少向量,再通过取原始向量计算并排序,返回最终真正需要的。比如top 3, oversampling是10,那就会按量化后的向量找出30个最相似的,然后按原始向量计算相似度再排序,返回这时算出来的top 3向量。
真正去实践才发现细节很多,下场把手弄脏是学习最快的。















 903
903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









