







 本文介绍了如何利用Mediapipe进行高保真人体姿态跟踪,以及在多人场景下通过YOLOv5进行对象检测,解决MediaPipe不支持多人姿态估计的问题。通过YOLOv5识别帧中人物,再用MediaPipe估计每个人的姿态,最终整合到单个帧中。
本文介绍了如何利用Mediapipe进行高保真人体姿态跟踪,以及在多人场景下通过YOLOv5进行对象检测,解决MediaPipe不支持多人姿态估计的问题。通过YOLOv5识别帧中人物,再用MediaPipe估计每个人的姿态,最终整合到单个帧中。
介绍
基于图像和视频的人体姿态估计可以在许多应用中发挥重要作用,例如健身活动识别、肢体语言检测、手语识别、量化体育锻炼和全身手势控制。
MediaPipe Pose 是一种用于高保真人体姿态跟踪的机器学习解决方案,从 RGB 视频帧中推断出全身的 33 个 3D 地标和背景分割蒙版。不同姿势的分类也可以使用自定义对象检测模块来完成,但它需要大量数据并且训练将是耗时且复杂的。我们可以简单地使用 MediaPipe 中的关键点,并使用这些关键点通过简单的机器学习模型进行分类。
MediaPipe Pose 中的界标模型预测了 33 个姿势界标的位置,如下图所示。
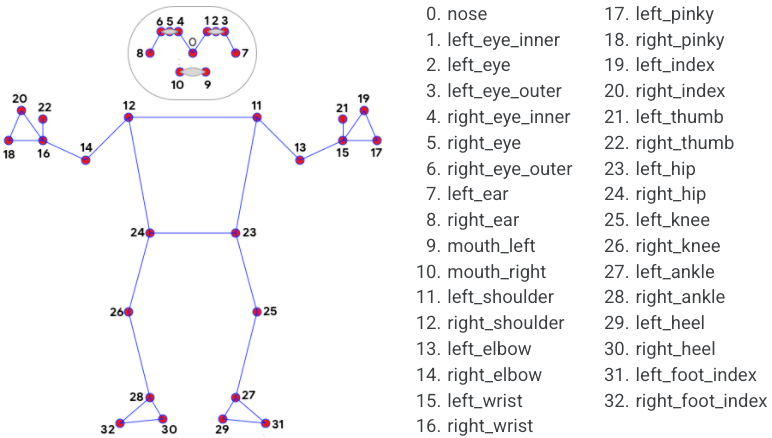
33个被 MediaPipe 识别的姿势地标
问题陈述
在大多数情况下,使用 MediaPipe 的姿势估计效果非常好,但是当单个帧上有多个人时就会出现问题。在撰写本文时,MediaPipe 不支持多人姿态估计,但每个问题都有解决方案。
解决此问题的一种灵活方法是使用对象检测模型并获取帧中存在的多个人,然后估计每个人的姿势,最后将图像聚合到单个帧中。对于对象检测模型,将使用 YOLOv5 。
YOLOv5
YOLO 是“You only look once”的首字母缩写,是一种将图像划分为网格系统的对象检测算法。网格中的每个单元都负责检测自身内部的对象。由于其速度和准确性,YOLO 是最著名的对象检测算法之一。开源代码可在 Github (https://github.com/ultralytics/yolov5)上获得。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









