








介绍
假设需要对人们是否戴眼镜进行分类,但是没有数据或资源训练自定义模型。
在本教程中,你将学习如何使用预训练的CLIP模型创建自定义分类器,无需任何训练。这种方法称为零快照图像分类,它使得能够对在原始CLIP模型训练期间未明确观察到的的类进行图像分类。
为了方便起见,下面提供了一个易于使用的jupyter笔记本,并提供完整的代码。
CLIP:理论背景
CLIP (对比语言-图像预训练)模型是OpenAI开发的多模式视觉和语言模型。它将图像和文本描述映射到相同的潜空间,使其能够确定图像和描述是否匹配。
CLIP是通过对超过4亿个来自互联网的图像-文字对数据集进行对比式训练开发的[1]。令人惊讶的是,经过预训练的CLIP生成的分类器已经表现出与受监督的基线模型竞争的结果,在本教程中,我们将利用这个预训练模型来生成眼镜检测器。
CLIP对比训练
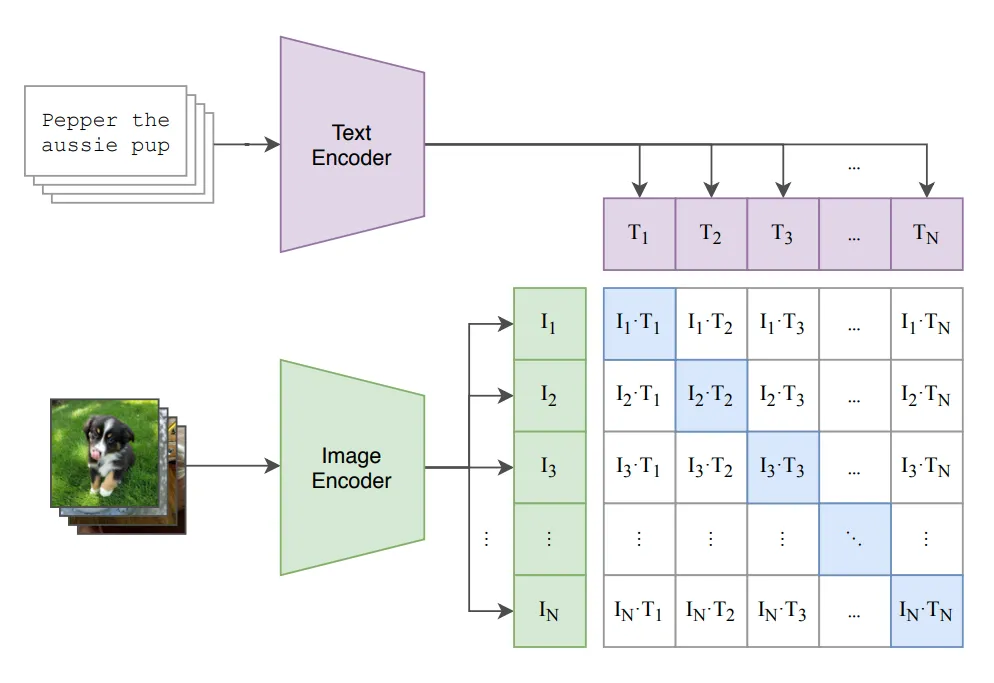
CLIP模型由图像编码器和文本编码器(图1)组成。在训练中,一批图像通过图像编码器(ResNet变体或ViT)处理以获得图像表示张量(嵌入)1。与此同时,它们对应的描述通过文本编码器(Transformer)进行处理,以获得文本嵌入。
CLIP模型是训练来预测哪一个图像张量属于批次中的哪个文本张量。这是通过共同训练图像编码器和文本编码器以最大化批次中真实配对的图像和文本嵌入之间的余弦相似度[2],同时使配对不正确的嵌入之间的余弦相似度减小而实现的(图1,对角线轴上的蓝色方块)。优化使用这些相似度得分的对称交叉熵损失来执行。
创建自定义分类器
使用CLIP创建自定义分类器时,将类别名称转换为文本嵌入向量经过预训练的文本编码器进行处理,同时使用预训练的图像编码器对图像进行嵌入(图2)。然后计算图像嵌入和每个文本嵌入之间的余弦相似度,并将图像分配给最高余弦相似度得分的类别。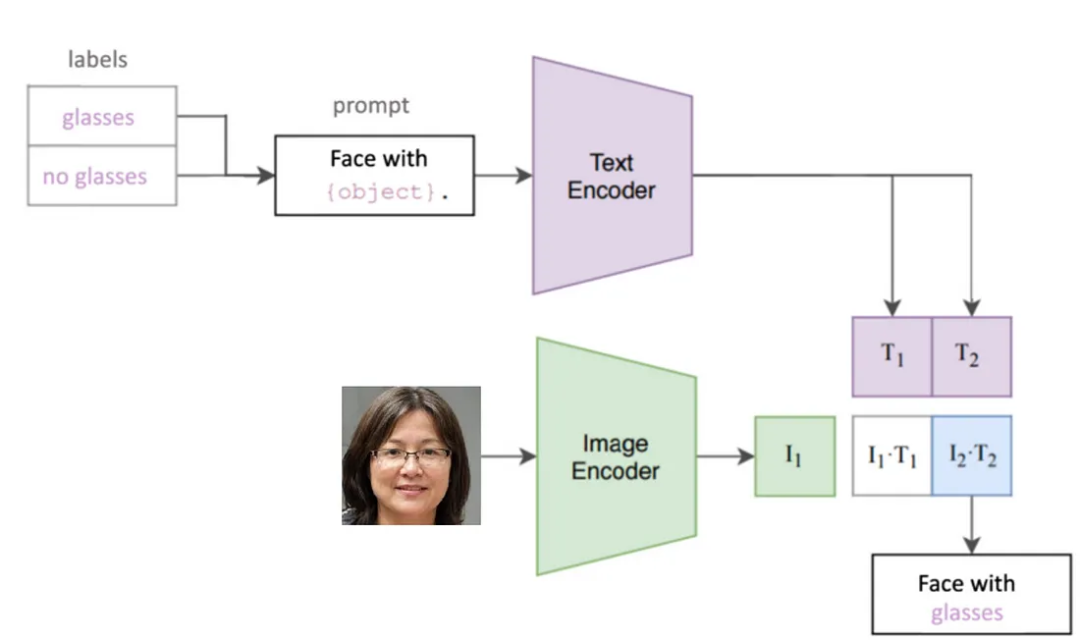
代码实现
数据集
在本教程中,我们将创建一个图像分类器,检测人们是否戴眼镜,并使用Kaggle上的“戴眼镜或不戴眼镜”数据集[3] 来评估分类器的性能。
尽管数据集包含5000张图像,但我们将只利用前100张以加快演示速度。数据集包含一个包含所有图像的文件夹以及一个包含标签的CSV文件。为了便于加载图像路径和标签,我们将自定义Pytorch数据集类来创建CustomDataset()类。你可以在提供的笔记本代码中找到它。

加载CLIP模型
安装并导入CLIP及其相关库后,我们加载所需的模型和torchvision转换流水线。文本编码器是一个Transformer,而图像编码器可以是Vision Transformer(ViT)或ResNet50等ResNet变体。你可以使用命令clip.available_models()查看可用的图像编码器。
print( clip.available_models() )
model, preprocess = clip.load("RN50")提取文本嵌入向量
首先通过文本分词器(clip.tokenize())处理文本标签,将标签单词转换为数值。这会产生大小为N x 77(N是类别数量,二分类下的两个类别是77)的填充张量,作为文本编码器的输入。
文本编码器将张量转换为大小为N x 512的文本嵌入张量,其中每个类别由单个向量表示。要编码文本并检索嵌入,请使用model.encode_text()方法。
preprocessed_text = clip.tokenize(['no glasses','glasses'])
text_embedding = model.encode_text(preprocessed_text)提取图像嵌入向量
在传递给图像编码器之前,每个图像都要经过预处理,包括中心裁剪、标准化和调整大小,以满足图像编码器的要求。预处理后,图像传递给图像编码器,该编码器生成大小为1 x 512的图像嵌入张量作为输出。
preprocessed_image = preprocess(Image.open(image_path)).unsqueeze(0)
image_embedding = model.encode_image(preproces 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1454
1454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









