







一、主要思想
CNN在计算机视觉领域取得了非常优异的成绩,但是训练CNN的模型需要大量的数据,小数据集上面无法体现出出CNN的优势。针对这个问题作者提出了通过Transferring CNN weights来解决这个问题。首先在imagenet等大数据集上面训练传统的CNN模型,然后在针对特定的任务就行fine-tuning(可能不准确),但是和以往fine-tuning不同的是:改变了整个pre-training的CNN的框架,删除了softmax层,加上了两层自适应层。在VOC2007和VOC2012上面取得了很好的结果。
二、基本框架
1、概述
CNN有
60 million
个参数,在小数据集上面学习这些参数不现实,因此可以再大规模数据集上面进行
pre-training
,然后在使用到特定的任务上面。如下图:

但是有一个问题就是:预训练的数据集和特定任务的数据集的图像有很大的差异,如物体的种类、角度、图像的成像条件等,如图示:

针对这个问题,作者提出:(1)设计一个可以在预训练集和特定任务集进行精确重映射的模型
(2)通过
sliding window
来提高训练和测试过程
2、网络框架
(1)在imagenet上面采用传统的CNN框架进行预训练
(2)去掉最后一层softmax层,加上FCa和FCb两层自适应层
(3)固定预训练模型的前面7层的参数不变,只训练自适应层的参数
3、网络训练(准备训练样本)
(1)采用sliding window的方法每张图像提取500个正方形图像块,每个块之间的重合比例至少为50%;
(2)给图像块打标签,假设图像块为P,某一类正样本为Bo标为相应类别的正样本条件:
(A)P和Bo的交集大于等于P的面积的0.2倍
(B)P和Bo的交集大于等于Bo的面积的0.6倍
(C)P中包含不多于一个物体
如图示:

(3)处理背景图像
通常这样得到的样本会导致训练样本不平衡的问题,大多数的图像块是背景图像,(处理这样的问题可以采用 hard negative mining 或者重新改变损失函数的权重),本文采用随机选择背景图像的10%;
4、分类
公式如下:

表示某一类在一张图像中的得分。
三、实验
在VOC数据集上进行了相应的实验。
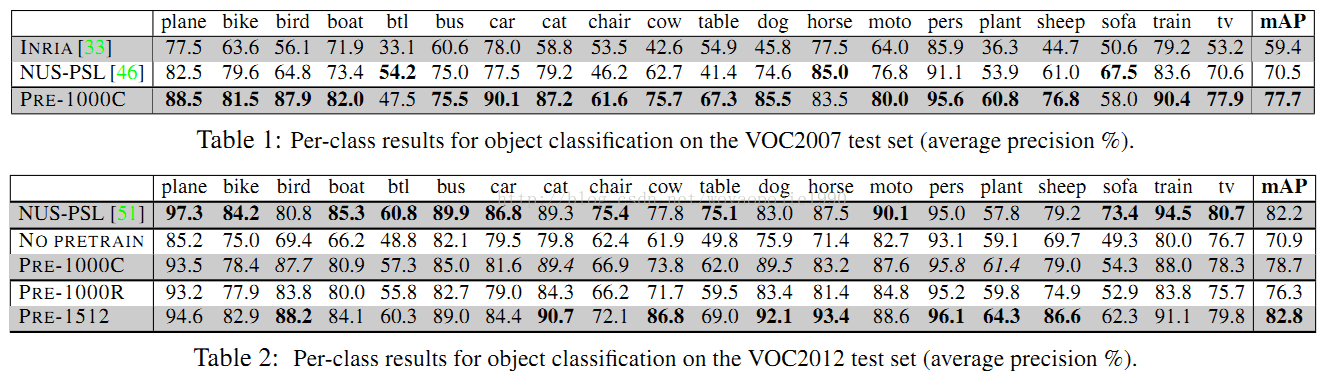
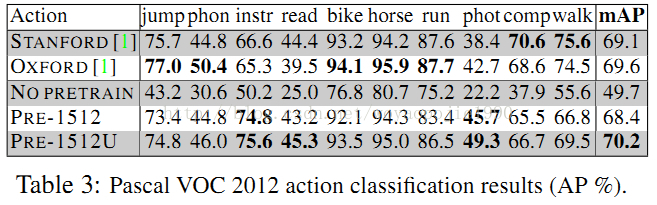
实验结论:(1)预训练数据集和特定任务数据的目标种类的重合程度对精度影响不是很大,有小的降低;但是随着预训练数据集的目标种类的增加,类别的重合度增加,识别率有了很大的提升,对于训练类别增加了或者是重合度增加了那个更重要,无从而知。
(2)增加或者减少一层自适应,精度都有1%的下降
四、总结
本篇论文的亮点就在于在fine-tuning的时候去掉了softmax层增加了自适应层,还有是统计一张图像中某一类的得分,我认为这也算是吧。但是,一个不足之处就是在于准备训练样本的时候,需要人工确定到底patch中包含几个物体,可能需要花费大量的时间。















 2813
2813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









