









caffe中的参数管理是通过google于2008年开源的一款非常优秀的序列化反序列化工具——prtotocol buffer实现的。
一、Protobuf消息定义
消息由至少一个字段组合而成,类似于C语言中的结构。每个字段都有一定的格式。
字段格式:限定修饰符① | 数据类型② | 字段名称③ | = | 字段编码值④ | [字段默认值⑤]
(1)限定修饰符包含 required\optional\repeated
Required: 表示是一个必须字段,必须相对于发送方,在发送消息之前必须设置该字段的值,对于接收方,必须能够识别该字段的意思。发送之前没有设置required字段或者无法识别required字段都会引发编解码异常,导致消息被丢弃。
Optional:表示是一个可选字段,可选对于发送方,在发送消息时,可以有选择性的设置或者不设置该字段的值。对于接收方,如果能够识别可选字段就进行相应的处理,如果无法识别,则忽略该字段,消息中的其它字段正常处理。---因为optional字段的特性,很多接口在升级版本中都把后来添加的字段都统一的设置为optional字段,这样老的版本无需升级程序也可以正常的与新的软件进行通信,只不过新的字段无法识别而已,因为并不是每个节点都需要新的功能,因此可以做到按需升级和平滑过渡。
Repeated:表示该字段可以包含0~N个元素。其特性和optional一样,但是每一次可以包含多个值。可以看作是在传递一个数组的值。
(2)数据类型
Protobuf定义了一套基本数据类型。几乎都可以映射到C++\Java等语言的基础数据类型.
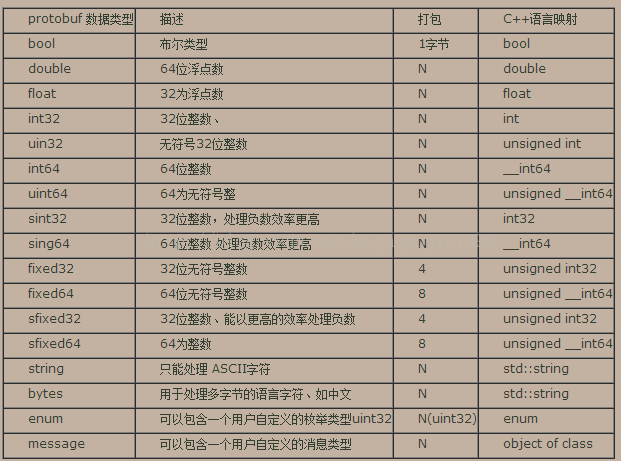
N 表示打包的字节并不是固定。而是根据数据的大小或者长度。
例如int32,如果数值比较小,在0~127时,使用一个字节打包。
关于枚举的打包方式和uint32相同。
关于message,类似于C语言中的结构包含另外一个结构作为数据成员一样。
关于 fixed32 和int32的区别。fixed32的打包效率比int32的效率高,但是使用的空间一般比int32多。因此一个属于时间效率高,一个属于空间效率高。根据项目的实际情况,一般选择fixed32,如果遇到对传输数据量要求比较苛刻的环境,可以选择int32.
(3)字段名称
字段名称的命名与C、C++、Java等语言的变量命名方式几乎是相同的。
protobuf建议字段的命名采用以下划线分割的驼峰式。例如 first_name 而不是firstName.
(4)字段编码值
有了该值,通信双方才能互相识别对方的字段。当然相同的编码值,其限定修饰符和数据类型必须相同。编码值的取值范围为 1~2^32(4294967296)。其中 1~15的编码时间和空间效率都是最高的,编码值越大,其编码的时间和空间效率就越低(相对于1-15),当然一般情况下相邻的2个值编码效率的是相同的,除非2个值恰好实在4字节,12字节,20字节等的临界区。比如15和16.1900~2000编码值为Google protobuf 系统内部保留值,建议不要在自己的项目中使用。
protobuf 还建议把经常要传递的值把其字段编码设置为1-15之间的值。消息中的字段的编码值无需连续,只要是合法的,并且不能在同一个消息中有字段包含相同的编码值。
建议:项目投入运营以后涉及到版本升级时的新增消息字段全部使用optional或者repeated,尽量不实用required。如果
(4)默认值
当在传递数据时,对于required数据类型,如果用户没有设置值,则使用默认值传递到对端。当接受数据是,对于optional字段,如果没有接收到optional字段,则设置为默认值。
二、注意事项
(1)关于import
protobuf 接口文件可以像C语言的h文件一个,分离为多个,在需要的时候通过 import导入需要对文件。其行为和C语言的#include或者java的import的行为大致相同。
(2)关于package
避免名称冲突,可以给每个文件指定一个package名称,对于java解析为java中的包。对于C++则解析为名称空间。
(3)关于message
支持嵌套消息,消息可以包含另一个消息作为其字段。也可以在消息内定义一个新的消息。
(4)关于enum
枚举的定义和C++相同,但是有一些限制。
枚举值必须大于等于0的整数。
使用分号(;)分隔枚举变量而不是C++语言中的逗号(,)
eg.
enum VoipProtocol
{
H323 = 1;
SIP = 2;
MGCP = 3;
H248 = 4;
}
使用了required,需要全网统一升级,如果使用optional或者repeated可以平滑升级。三、安装
下载地址:https://protobuf.googlecode.com/svn/rc/protobuf-2.6.0.tar.gz
运行:(1)./autogen.sh;
(2)./configure --prefix=/usr (这样可以不用手动添加环境变量)
(3)make
(4) make check
(5)make install
四、例子分析
从例子入手是学习一门新工具的最佳方法。下面我们通过一个简单的例子看看我们如何用protobuf的C++接口序列化反序列化一个结构体。就以protobuf自带的例子(protobuf-master/examples下面)。
(1)编辑您将要序列化的结构体描述文件.proto
protobuf使用前,先编写proto文件,这是描述我们需要配置参数的数据结构。这个例子里面的proto如下:
<span style="font-family:KaiTi_GB2312;font-size:18px;"><span style="font-family:KaiTi_GB2312;font-size:18px;">// See README.txt for information and build instructions.
package tutorial;
option java_package = "com.example.tutorial";
option java_outer_classname = "AddressBookProtos";
message Person {
required string name = 1;
required int32 id = 2; // Unique ID number for this person.
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
// Our address book file is just one of these.
message AddressBook {
repeated Person person = 1;
}</span></span>前几行是定义包的,可以忽略。
message Person{...}定义了一个需要传输的参数结构体,可见包括这么几个单元:name(string类型)、id(int32类型)、email(string类型)、phone(PhoneNumber类型,嵌套在Person内的类)。前面标记为“required”是必须有值的,而“optional“则为可选项,”repeated“表示后面单元为相同类型的一组向量。
(2)用protoc工具“编译”Hello.proto
protoc工具使用的一般格式是:
protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/xxx.proto
其中SRC_DIR是proto文件所在的目录,DST_DIR是编译proto文件后生成的结构体处理文件的目
运行:protoc --cpp_out=. addressbook.proto ;运行后生成了两个文件:addressbook.pb.cc 和addressbook.pb.h。
(3)测试
我们可以自己编写函数:序列化(add_person.cc)/反序列化(list_people.cc)通过自动生成的接口实现
运行:make cpp; 行后生成了两个文件:add_person_cpp 和list_people_cpp
运行:./add_person_cpp wq;会出现以下需要用户输入的信息,同时生成一个wq文件
Enter person ID number: 123456
Enter name: wq
Enter email address (blank for none): 123456@163.com
Enter a phone number (or leave blank to finish): 12346789
Is this a mobile, home, or work phone? mobile
Enter a phone number (or leave blank to finish):回车
运行:./add_person_cpp wq;会出现以的信息
Person ID: 123456
Name: wq
E-mail address: 123456@163.com
Mobile phone #: 12346789
可见只需要调用addressbook.pb.h中声明的tutorial::AddressBook类、Person类中的接口(add_person(), add_phone(), set_number(), set_email()等)就能操作相应的参数,最后将内存中的参数序列化为文件只需要执行SerializeToOstream(),相应的读取参数文件的操作为ParseFromIstream()。这样以来可以不用自己编写函数操作这些参数的函数,可以减少很多的工作量。















 7586
7586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









