






参考博文:Paper | Quality assessment of deblocked images - RyanXing - 博客园 (cnblogs.com)
像的阻挡效应因子(Blocking Effect Factor,BEF)。阻挡效应是指当图像被分割成块时,相邻块之间的边界会引入人眼可见的伪影。阻挡效应因子用于评估图像中阻挡效应的程度。
PSNR-B指标,旨在衡量 压缩图像的块效应强度 或 去块效应后的残留块效应强度(比较去块效应算法的优劣)。
我们首先假设图像由整数个块(tiling)组成。例如:
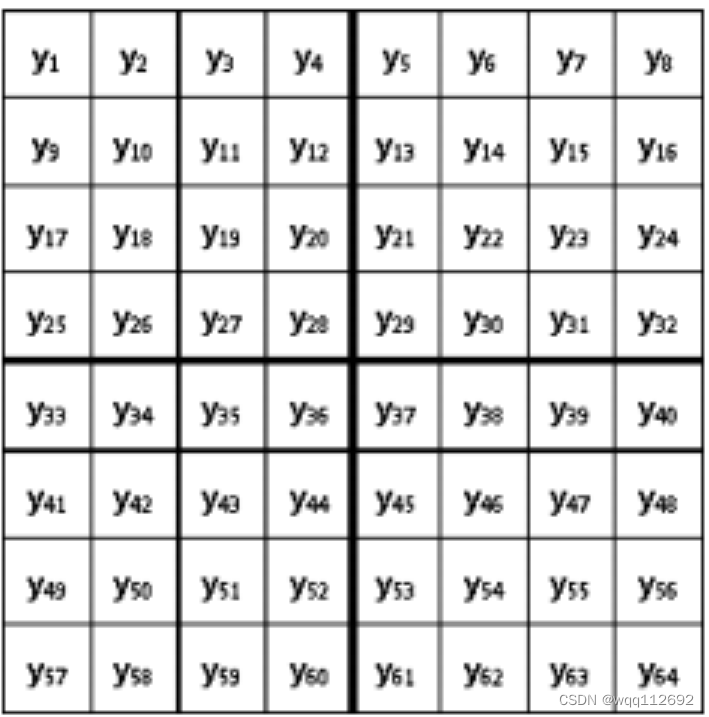
图中每一个块都是8×8的块,一共有64个。定义以下块类别:

分别代表:纵向接壤块边缘的像素对、纵向非接壤块边缘的像素对、横向接壤块边缘的像素对 和 横向非接壤块边缘的像素对。
定义两个指标:
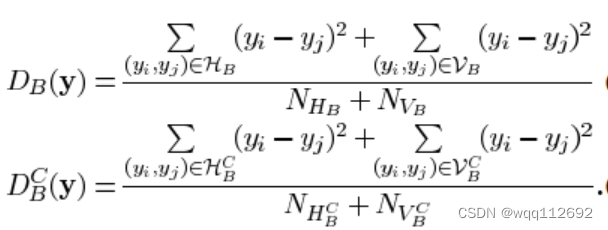
前者代表块边缘变化强度,后者代表非块边缘(块内)变化强度。随着量化逐渐粗糙,前者的增大会明显快于后者。
还考虑一个因素:随着块增大,块效应也会逐渐明显。【反过来,如果块很小,那么远看是看不出块效应的】因此我们定义一个块效应因数(blocking effect factor, BEF):
![]()
其中的η随着块尺寸的增大而增大:
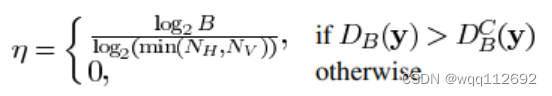
例如在H264压缩标准下,一张图像内可以有多种不同尺寸的块。此时就有:
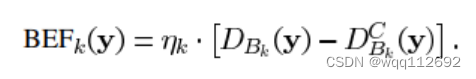
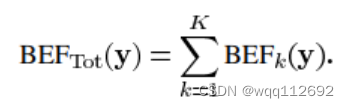
定义PSNR-B如下:
![]()
阻挡效应因子(Blocking Effect Factor,BEF)代码实现
def _blocking_effect_factor(im): # 计算了图像的阻挡效应因子(Blocking Effect Factor,BEF)
'''
阻挡效应是指当图像被分割成块时,相邻块之间的边界会引入人眼可见的伪影。
阻挡效应因子用于评估图像中阻挡效应的程度。
Args:
im:输入的图片
Returns:计算了图像的阻挡效应因子
'''
block_size = 8
# im是一个四维的数组,代表输入的图像。通常,它的形状是(height, width, channels, frames),表示图像的高度、宽度、通道数和帧数
block_horizontal_positions = torch.arange(7, im.shape[3] - 1, 8) # 定义了一个块的大小为8个像素
block_vertical_positions = torch.arange(7, im.shape[2] - 1, 8)
horizontal_block_difference = (
(im[:, :, :, block_horizontal_positions] - im[:, :, :, block_horizontal_positions + 1]) ** 2).sum(
3).sum(2).sum(1) # 计算图像中水平方向上相邻像素之差的平方
vertical_block_difference = (
(im[:, :, block_vertical_positions, :] - im[:, :, block_vertical_positions + 1, :]) ** 2).sum(3).sum(
2).sum(1) # 计算图像中竖直方向上相邻像素之差的平方
nonblock_horizontal_positions = np.setdiff1d(torch.arange(0, im.shape[3] - 1), block_horizontal_positions)
nonblock_vertical_positions = np.setdiff1d(torch.arange(0, im.shape[2] - 1), block_vertical_positions)
horizontal_nonblock_difference = (
(im[:, :, :, nonblock_horizontal_positions] - im[:, :, :, nonblock_horizontal_positions + 1]) ** 2).sum(
3).sum(2).sum(1)
vertical_nonblock_difference = (
(im[:, :, nonblock_vertical_positions, :] - im[:, :, nonblock_vertical_positions + 1, :]) ** 2).sum(
3).sum(2).sum(1)
# np.setdiff1d()函数来找到两个数组之间的差异,然后计算了图像中水平和垂直方向上非块(non-block)位置的像素差值的平方和
n_boundary_horiz = im.shape[2] * (im.shape[3] // block_size - 1)
n_boundary_vert = im.shape[3] * (im.shape[2] // block_size - 1)
boundary_difference = (horizontal_block_difference + vertical_block_difference) / (
n_boundary_horiz + n_boundary_vert)
n_nonboundary_horiz = im.shape[2] * (im.shape[3] - 1) - n_boundary_horiz
n_nonboundary_vert = im.shape[3] * (im.shape[2] - 1) - n_boundary_vert
nonboundary_difference = (horizontal_nonblock_difference + vertical_nonblock_difference) / (
n_nonboundary_horiz + n_nonboundary_vert)
scaler = np.log2(block_size) / np.log2(min([im.shape[2], im.shape[3]]))
bef = scaler * (boundary_difference - nonboundary_difference)
bef[boundary_difference <= nonboundary_difference] = 0
return befPSNR-B代码实现
def calculate_psnrb(img1, img2, crop_border, input_order='HWC', test_y_channel=False):
"""Calculate PSNR-B (Peak Signal-to-Noise Ratio).
Ref: Quality assessment of deblocked images, for JPEG image deblocking evaluation
# https://gitlab.com/Queuecumber/quantization-guided-ac/-/blob/master/metrics/psnrb.py
Args:
img1 (ndarray): Images with range [0, 255].
img2 (ndarray): Images with range [0, 255].
crop_border (int): Cropped pixels in each edge of an image. These
pixels are not involved in the PSNR calculation.
input_order (str): Whether the input order is 'HWC' or 'CHW'.
Default: 'HWC'.
test_y_channel (bool): Test on Y channel of YCbCr. Default: False.
Returns:
float: psnr result.
"""
assert img1.shape == img2.shape, (f'Image shapes are differnet: {img1.shape}, {img2.shape}.')
if input_order not in ['HWC', 'CHW']:
raise ValueError(f'Wrong input_order {input_order}. Supported input_orders are ' '"HWC" and "CHW"')
img1 = reorder_image(img1, input_order=input_order) # 调整图片维度顺序为HWC
img2 = reorder_image(img2, input_order=input_order)
img1 = img1.astype(np.float64) # 图片类型转换
img2 = img2.astype(np.float64)
if crop_border != 0:
img1 = img1[crop_border:-crop_border, crop_border:-crop_border, ...] # 去除图片的边缘像素
img2 = img2[crop_border:-crop_border, crop_border:-crop_border, ...]
if test_y_channel:
img1 = to_y_channel(img1) # Y通道颜色空间转换
img2 = to_y_channel(img2)
# follow https://gitlab.com/Queuecumber/quantization-guided-ac/-/blob/master/metrics/psnrb.py
img1 = torch.from_numpy(img1).permute(2, 0, 1).unsqueeze(0) / 255.
img2 = torch.from_numpy(img2).permute(2, 0, 1).unsqueeze(0) / 255.
# torch.from_numpy(img1)将NumPy数组img1转换为PyTorch张量,unsqueeze(0)将张量的维度扩展一个单位,以添加一个虚拟的批次维度
# permute(2, 0, 1)用于对张量进行维度重排,将原始图像的通道维度从最后一维移动到第一维,
# 行维度移动到第二维,列维度移动到第三维。这是为了与PyTorch默认的通道维度顺序(即[batch_size, channel, height, width])保持一致
# img1和img2被转换为形状为[1, channel, height, width]的PyTorch张量,并且它们的值被归一化到0到1之间
total = 0
for c in range(img1.shape[1]): # img1.shape[1]是通道的数量
mse = torch.nn.functional.mse_loss(img1[:, c:c + 1, :, :], img2[:, c:c + 1, :, :], reduction='none')
# 计算均方误差(Mean Square Error,简称MSE)损失。它用于衡量模型的预测结果与目标值之间的差异
bef = _blocking_effect_factor(img1[:, c:c + 1, :, :]) # 计算阻塞效应因子的临时结果bef
mse = mse.view(mse.shape[0], -1).mean(1)
# 调整mse的形状,将其转换为二维张量,其中每一行表示一个样本(这里只有一个样本),每一列表示样本的一个特征
total += 10 * torch.log10(1 / (mse + bef))
return float(total) / img1.shape[1]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









