






 本文介绍了2018年提出的BAM注意力模块,它是一种通用的注意力模型,能提升深度神经网络性能。BAM通过通道注意力和空间注意力机制,减少计算与参数需求,适用于各种卷积神经网络结构。
本文介绍了2018年提出的BAM注意力模块,它是一种通用的注意力模型,能提升深度神经网络性能。BAM通过通道注意力和空间注意力机制,减少计算与参数需求,适用于各种卷积神经网络结构。
BAM注意力机制原论文地址:https://arxiv.org/abs/1807.06514
注意力机制是一种神经网络模型中常用的技术,用来模拟人类在处理任务时的注意力分配过程。它能够使得神经网络在处理复杂任务时,能够集中精力关注重要的信息,同时忽略无关的信息,从而提高模型的性能和效率。
今天这篇文章主要讲述的是2018年提出的一个注意力模块BAM.
这项工作中,作者把重心放在了Attention对于一般深度神经网络的影响上,然后提出了一个简单但是有效的Attention模型—BAM,它可以结合到任何前向传播卷积神经网络中,BAM模型通过两个分离的路径 channel和spatial, 得到一个Attention Map。
之前的大多数注意力模块都是将注意力用于特定的任务,然而BAM(“瓶颈注意模块”)明确作为一种有效提高网络表征能力的方式,是一个简单而有效的注意模块,可用于任何CNN。对于3D特征图,BAM会生成3D注意力图来强调重要元素,推断3D注意图的过程分解为两个分支流程,BAM的结构图如下图所示,可以大大减少计算开销和参数开销。特征图的通道可以看作特征检测器,两个分支(spatial和channel)明确地学习应该关注“什么”和“哪里”。
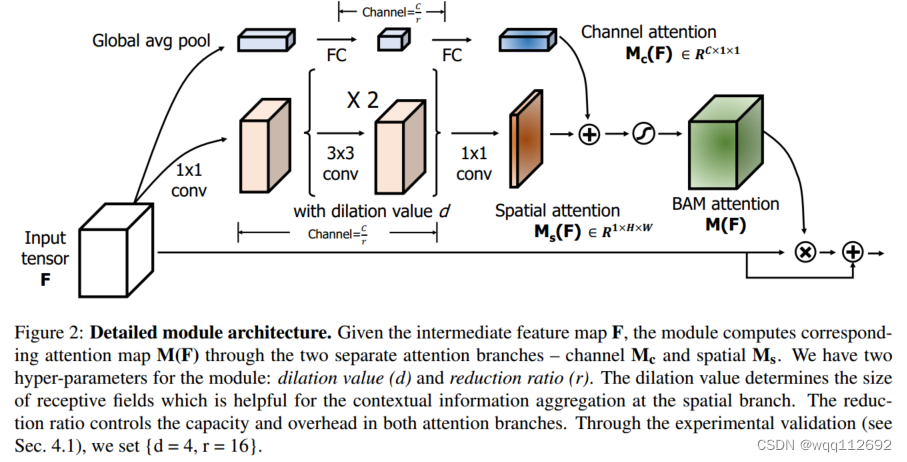
在神经网络中,BAM常常用在模型的各个模块的交界处,因此被称为“瓶颈注意模块”。如下图所示

BAM的具体实现如下:
import numpy as np
import torch
from torch import nn
from torch.nn import init
class Flatten(nn.Module):
def forward(self,x):
return x.view(x.shape[0],-1)
class ChannelAttention(nn.Module):
def __init__(self,channel,reduction=16,num_layers=3):
super().__init__()
self.avgpool=nn.AdaptiveAvgPool2d(1)
gate_channels=[channel]
gate_channels+=[channel//reduction]*num_layers
gate_channels+=[channel]
self.ca=nn.Sequential()
self.ca.add_module('flatten',Flatten())
for i in range(len(gate_channels)-2):
self.ca.add_module('fc%d'%i,nn.Linear(gate_channels[i],gate_channels[i+1]))
self.ca.add_module('bn%d'%i,nn.BatchNorm1d(gate_channels[i+1]))
self.ca.add_module('relu%d'%i,nn.ReLU())
self.ca.add_module('last_fc',nn.Linear(gate_channels[-2],gate_channels[-1]))
def forward(self, x) :
res=self.avgpool(x)
res=self.ca(res)
res=res.unsqueeze(-1).unsqueeze(-1).expand_as(x)
return res
class SpatialAttention(nn.Module):
def __init__(self,channel,reduction=16,num_layers=3,dia_val=2):
super().__init__()
self.sa=nn.Sequential()
self.sa.add_module('conv_reduce1',nn.Conv2d(kernel_size=1,in_channels=channel,out_channels=channel//reduction))
self.sa.add_module('bn_reduce1',nn.BatchNorm2d(channel//reduction))
self.sa.add_module('relu_reduce1',nn.ReLU())
for i in range(num_layers):
self.sa.add_module('conv_%d'%i,nn.Conv2d(kernel_size=3,in_channels=channel//reduction,out_channels=channel//reduction,padding=1,dilation=dia_val))
self.sa.add_module('bn_%d'%i,nn.BatchNorm2d(channel//reduction))
self.sa.add_module('relu_%d'%i,nn.ReLU())
self.sa.add_module('last_conv',nn.Conv2d(channel//reduction,1,kernel_size=1))
def forward(self, x) :
res=self.sa(x)
res=res.expand_as(x)
return res
class BAMBlock(nn.Module):
def __init__(self, channel=512,reduction=16,dia_val=2):
super().__init__()
self.ca=ChannelAttention(channel=channel,reduction=reduction)
self.sa=SpatialAttention(channel=channel,reduction=reduction,dia_val=dia_val)
self.sigmoid=nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
sa_out=self.sa(x)
ca_out=self.ca(x)
weight=self.sigmoid(sa_out+ca_out)
out=(1+weight)*x
return out
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









