






本文主要讲解我对于2023年提出的mamba模型的理解和解读,mamba模型的提出为transformer模型存在的计算效率低下,需要大量时间运行程序提出了解决方案。提高了模型的运行效率和计算效率。我主要是根据下面这篇文章入手:

1.mamba模型是通过堆叠多个mamba block而来。Mamba模块是一种结合了H3块和Gated MLP块特点的简化设计,通过重复Mamba块而不是交替使用其他模块来实现高效计算,并在设计中引入了SSM和现代激活函数,从而增强了模型的表现能力。 Mamba模块如下图所示:
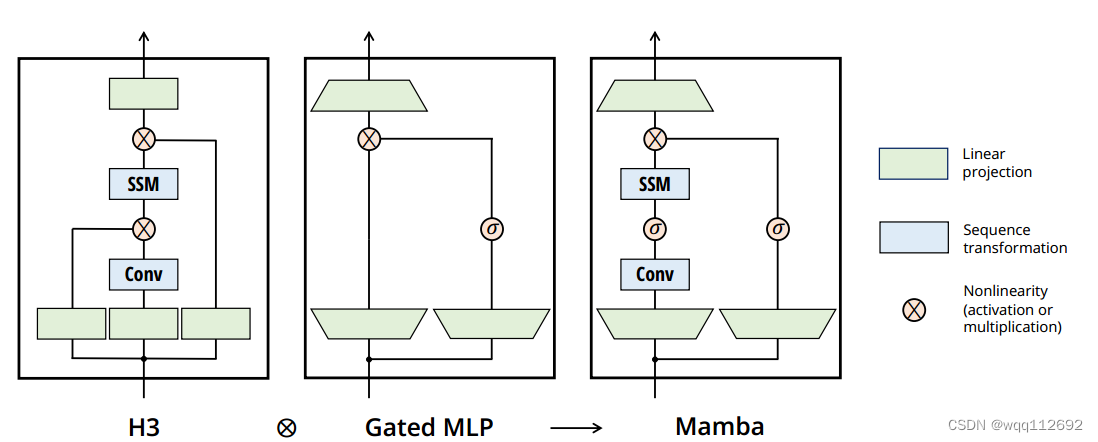
由上图可以看出,mamba模型最重要的部分是SSM状态空间模型。mamba模型说设计的SSM如下图所示:
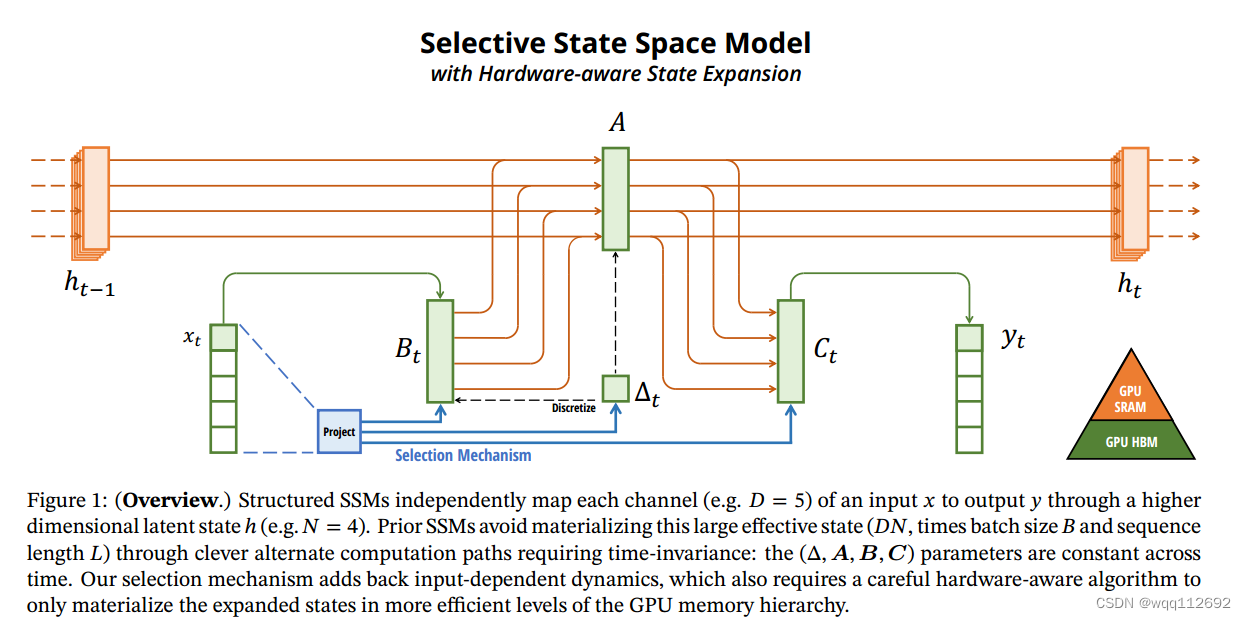
h_t-1:是前一步的隐状态。h_t:是当前的隐状态。x_t:是当前的输入。y_t:是当前的输出。
SSM 以独立的方式将输入x_t的每个通道(例如 D = 5)映射到高维潜在状态h(例如N = 4),然后再输出y_t。模型将输入向量x的每个通道独立地映射到输出向量,通过一个高维的潜在状态h进行转换。Projection(投影模块):用于将输入x_t映射到不同的通道。Selection Mechanism(选择机制):该机制负责动态选择基于输入的状态更新,这需要一个硬件感知算法来保证计算的高效性。
ssm的离散化是启发式门控机制的原则基础。离散化具体过程主要采用zero-order hold (ZOH) 零阶保持法,具体原理如下:

参数矩阵A、B_t、C_t、Δ_t:
A:状态转移矩阵。
B_t:控制输入到状态转换的影响。
C_t:控制状态到输出的转换。
Δ_t:离散化参数,用于表示时间不变性。


图片展示了一种结合状态空间模型(SSM)和选择机制(Selection)的算法,标为“Algorithm 2: SSM + Selection (S6)”。下方是算法的详细结构和其解释:


2.mamba模型另外一个重要思想是利用一个硬件加速方法提高计算速度。由于上述变化对模型的计算提出了技术挑战。所有先前的 SSM 模型都必须是时间和输入不变的,这样才能提高计算效率。为此,本文作者采用了一种硬件感知算法,通过扫描而不是卷积来计算模型,但不会将扩展状态具体化,以避免在 GPU 存储器层次结构的不同级别之间进行 IO 访问。由此产生的实现方法在理论上(与所有基于卷积的 SSM 的伪线性相比,在序列长度上呈线性缩放)和现有硬件上都比以前的方法更快(在 A100 GPU 上可快达 3 倍)。
硬件感知的状态扩展:这部分说明了如何通过选择机制引入基于输入的动态,使得状态扩展在 GPU 内存层次结构中更高效地实现。
主要思想是利用现代加速器(如GPU)的特性,将状态ℎ仅在内存层次结构中更高效的级别上进行物质化。特别地,大多数操作(除了矩阵乘法)都受到内存带宽的限制。包括扫描操作,使用内核融合来减少内存IO的数量,从而相比标准实现显著加快速度。具体来说,与其在GPU高带宽内存(HBM)中准备大小为(ℬ, ℒ, ℴ, ℕ)的扫描输入(A, B),直接从较慢的HBM加载SSM参数(Δ, A, B, C)到快速的SRAM,在SRAM中执行离散化和递归,然后将大小为(ℬ, ℒ, ℴ)的最终输出写回HBM。为了避免顺序递归,观察到尽管它不是线性的,但仍然可以使用工作高效的并行扫描算法进行并行化。还必须避免保存中间状态,这些状态对于反向传播是必要的。仔细应用重新计算的经典技术来减少内存需求:中间状态不存储,而是在反向传递中从HBM加载到SRAM时重新计算。因此,融合选择扫描层的内存需求与采用FlashAttention的优化Transformer实现相同。
完整的选择性SSM层和算法如图1所示。
解读:
内存效率提升:通过利用GPU的快速内存(SRAM)进行计算,只在需要时才使用高带宽内存(HBM),从而大大减少了内存带宽限制带来的瓶颈。
内核融合:通过将多个操作融合成一个内核,减少了内存IO的次数,从而提高了计算效率。
并行化:尽管扫描操作本质上是递归的,但可以通过并行扫描算法来实现并行化,从而提升速度。
重新计算技术:在反向传播过程中,不存储中间状态,而是在需要时重新计算中间状态,从而显著减少内存需求。
性能对标:这种优化使得选择性扫描层的内存需求与使用FlashAttention的优化Transformer实现相当。
参考博文:
1.Mamba模型底层技术详解:与Transformer的区别在哪里?

















 4451
4451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









