









 本文介绍了四种优化RAG系统(基于检索和生成的模型)的方法:子问题查询引擎、RAG-Fusion的ReciprocalRankFusion、RAG-end2end的DensePassageRetrieval以及LoRA的低秩适应,以增强模型的检索性能和领域适应性。
本文介绍了四种优化RAG系统(基于检索和生成的模型)的方法:子问题查询引擎、RAG-Fusion的ReciprocalRankFusion、RAG-end2end的DensePassageRetrieval以及LoRA的低秩适应,以增强模型的检索性能和领域适应性。
RAG两大核心组件:检索和生成。本文将总结四种提高RAG系统检索质量的技术:1)子问题查询引擎(来自LlamaIndex),2)RAG-Fusion、3)RAG-end2end和4)LoRA微调。
一、LLM对问题进行分解
RAG系统根据用户的查询使用LLM生成自然语言答案。有时候直接对原问题生成答案效果不佳,这时我们可以通过要求LLM首先将用户的查询分解为子问题,然后,文档检索器可以检索每个较小的问题,这样可以提供更丰富的上下文。
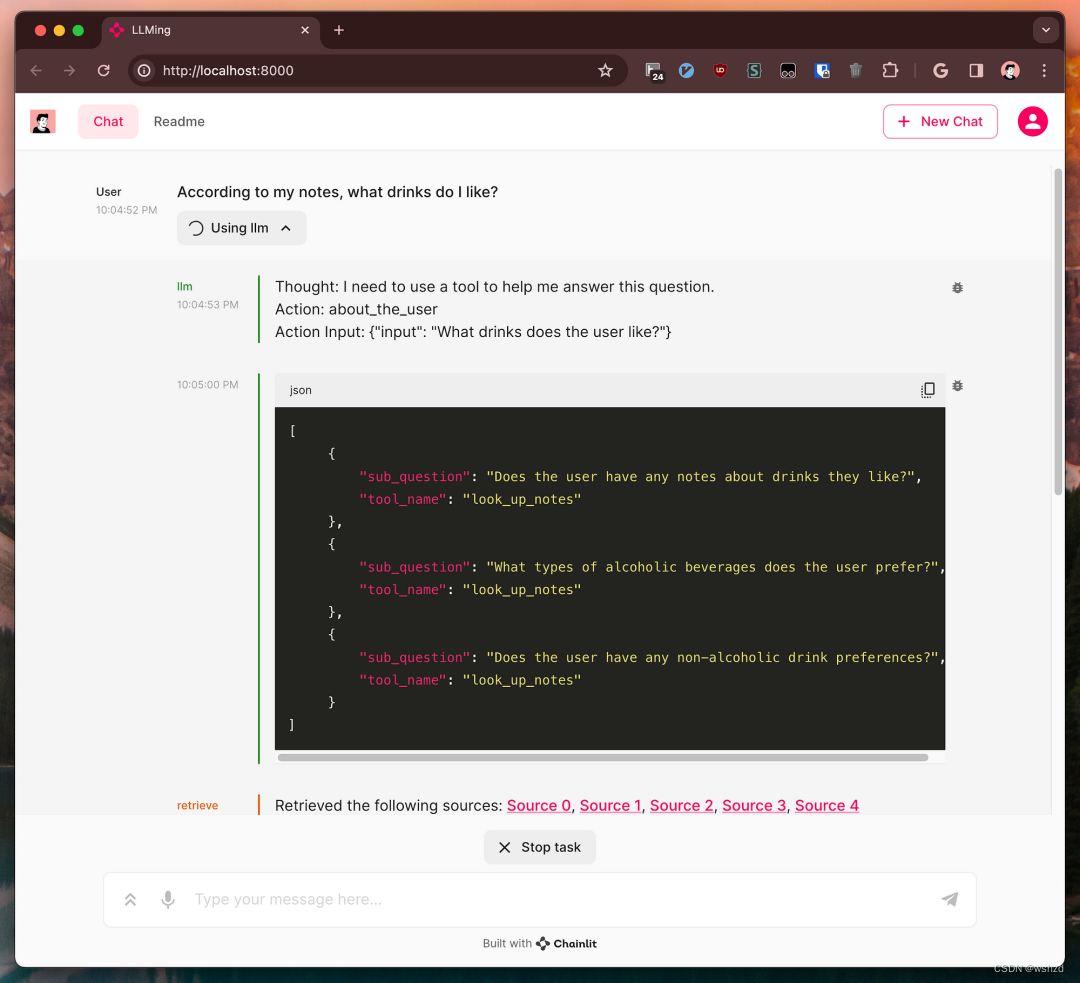
接下来就有一下问题:如何合并这样子查询的答案呢?
简单地说,我们可以将检索到的文档集连接起来,并在生成答案时将它们作为上下文提供给LLM。我们可能完全不知道我们展示检索到的文档的顺序。或者,我们可以做得更好。
在LlamaIndex中提供了Sub Question Query Engine[2]来提升RAG检索性能。对于每个检索到的文档集,都会生成相应子问题的答案。然后,LLM会根据这些子答案,而不是检索到的文档本身,得出最终答案。
二、RAG-Fusion
RAG-Fusion[3]仍然将文档作为上下文提供给LLM。首先,它根据每个文档出现的回忆集数量对文档进行排序。这种技术被称为Reciprocal Rank Fusion (RRF)。RRF假设:
- 与更多子问题相关的文档更有助于回答原始查询。(反例是一篇与每个问题都相关的通用文章,但不够具体,无法为最终答案提供任何价值。)
- LLM可以用更大的权重对排名靠前的结果进行优先级排序,而不是将列表视为无序集。
RRF允许人们通过不同的搜索方法来组合结果,这种模式通常被称为“混合搜索”。
- Azure AI Search[4]使用它来聚合来自传统的逐字文本搜索和基于嵌入的矢量搜索的召回集。
- 还有一个例子是Obisidian-Copilot[5],它是笔记应用Obsidian[6]的一个插件,它将基于BM25的搜索(通过OpenSearch)与语义搜索相结合。
- 如果想自己实现一个,矢量数据库提供商Pinecone有一个教程[7]可以参考。
提供给RRF的各种搜索方法的不同之处仅在于它们如何到达它们的回忆集,而不是具有可供选择的不相交的文档集。至关重要的是,文档首先必须有机会出现在单独的回忆集中,然后才能通过相互出现来重新排序。
三、RAG-end2nd
RAG的一个主要优势是“不需要训练任何模型”,它可以使用现成的嵌入模型和LLM来构建。
RAG-end2nd[8]提出了Dense Passage Retrieval(DPR;“RAG”中的“R”)方法,对编码器(比如BERTs)进行一些微调,性能超过BM25 25%。
四、LoRA
LoRA是大模型微调的技术之一,它来自论文《LoRA: Low-Rank Adaptation of Large Language Models》[9],基本原理是冻结大模型参数,在原始模型中添加少量的可训练参数AB矩阵来适应特定领域知识,由于微调的参数量较少,比较适合低资源的场景和用户。
五、总结
在这篇短文中,回顾了四种提高RAG管道相关性的技术。其中两种依赖于分解原始查询并利用LLM的生成能力,而另外两种则致力于利用特定领域的知识进一步增强模型本身。
参考文献:
[1] https://lmy.medium.com/four-ways-to-improve-the-retrieval-of-a-rag-system-91626ab2ad65
[2] https://docs.llamaindex.ai/en/stable/examples/query_engine/sub_question_query_engine.html
[3] https://github.com/Raudaschl/rag-fusion
[4] https://learn.microsoft.com/en-us/azure/search/hybrid-search-overview
[5] https://eugeneyan.com/writing/obsidian-copilot/
[6] https://obsidian.md/
[7] https://www.pinecone.io/learn/hybrid-search-intro/
[8] https://arxiv.org/abs/2210.02627
[9] https://arxiv.org/abs/2106.09685
















 1340
1340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











