







实现RAG是一个挑战,尤其是在有效解析和理解非结构化文档中的表格时,对于扫描的文档或图像格式的文档来说尤其困难。这些挑战至少有三个方面:
- 扫描文档或图像文档的复杂性,如其多元化的结构、非文本元素以及手写和打印内容的组合,这给自动化准确提取表格信息带来了挑战。解析不准确会破坏表的结构,使用不完整的表进行嵌入不仅无法捕获表的语义信息,而且很容易破坏RAG结果;
- 如何提取表格标题并将其有效地链接到各自的表格;
- 如何设计索引结构来有效地存储表的语义信息。
本文将介绍RAG中管理表格数据的关键技术,然后回顾一些现有的开源解决方案,最后实现一个解决方案。
一、关键技术
1.1 表格分析
该模块的主要功能是从非结构化文档或图像中准确提取表结构。最好可以提取出相应的表标题,这样方便开发人员将表标题与表关联起来。
根据我目前的理解,有几种方法,如图1所示:
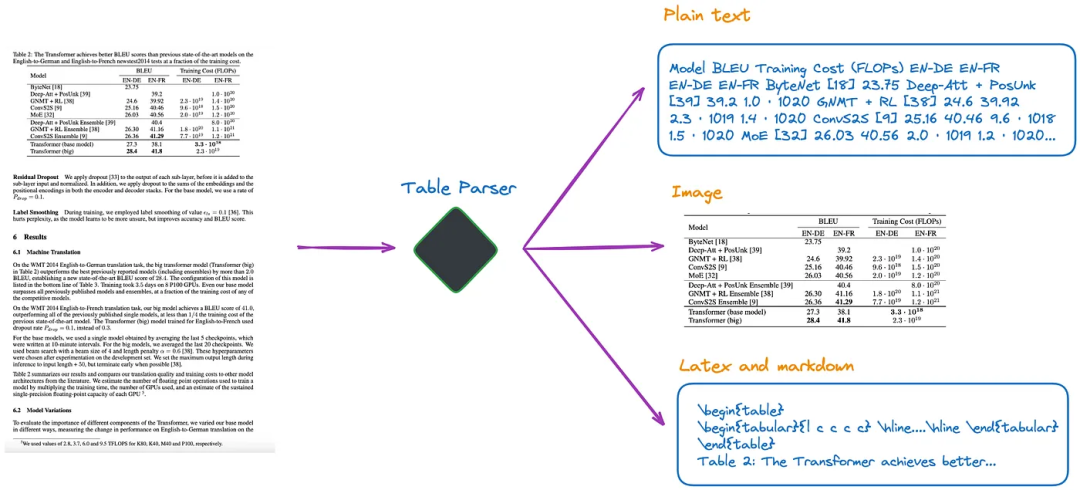
(a)利用多模态LLM(如GPT-4V[1])来识别表格并从每个PDF页面中提取信息
输入:图像格式的PDF页面
输出:JSON或其他格式的表。如果多模态LLM无法提取表格数据,则应总结图像并返回摘要。
(b)利用专业的表格检测模型(如Table Transformer[2]),来辨别表格结构
输入:PDF页面作为图像
输出:表格作为图像
(c)使用开源框架(如unstructured[3]或者目标检测模型[4]。这些框架可以对整个文档进行全面的解析,并从解析的结果中提取与表相关的内容
输入:PDF或图像格式的文档
输出:纯文本或HTML格式的表,从整个文档的解析结果中获得
(d)使用Nougat[5]、Donut[6]等端到端模型来解析整个文档并提取与表相关的内容。这种方法不需要OCR模型
输入:PDF或图像格式的文档
输出:LaTeX或JSON格式的表,从整个文档的解析结果中获得
值得一提的是,无论使用何种方法提取表格信息,都应包括表格标题。这是因为在大多数情况下,表格标题是文档或论文作者对表格的简短描述,可以在很大程度上概括整个表格。
在上述四种方法中,方法(d)允许容易地检索表标题,这将在下面的实验中进一步解释。
1.2 索引结构
根据索引的结构,大致可以分为以下几类:
(e)仅使用图像格式的索引表;
(f)仅使用纯文本或JSON格式的索引表;
(g)仅使用LaTeX格式的索引表;
(h)仅为表的摘要编制索引;
(i)“从小到大”或“文档摘要索引”结构,如图2所示:
- 小块的内容可以是来自表的每一行的信息或表的摘要。
- 大块的内容可以是图像格式、纯文本格式或LaTeX格式的表。
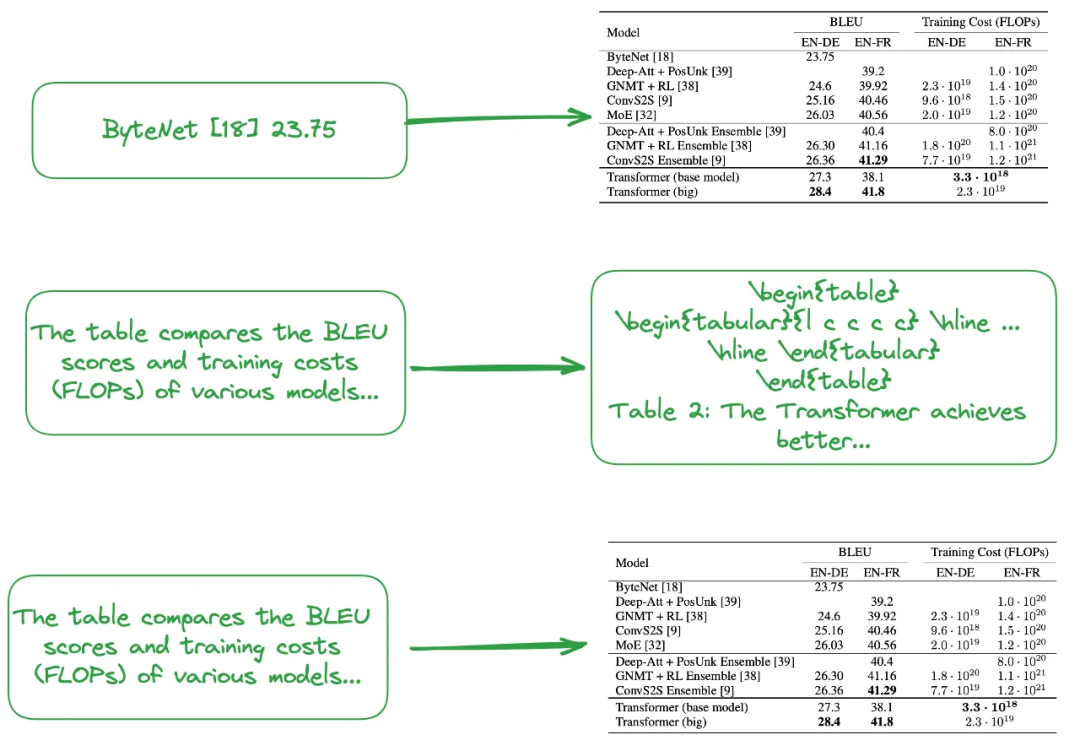
如上所述,表格摘要通常使用LLM生成:
输入:图像格式、文本格式或LaTeX格式的表格
输出:表格摘要
1.3 不需要表解析、索引或RAG的算法
下面介绍一些不需要表解析的算法:
(j)将相关图像(PDF页面)和用户查询发送到VQA模型(如DAN等)或多模态LLM,并返回答案;
要索引的内容:图像格式的文档
发送到VQA模型或多模态LLM的内容:查询+图像形式的相应页面
(k)将相关文本格式的PDF页面和用户的查询发送到LLM,然后返回答案;
要索引的内容:文本格式的文档
发送到LLM的内容:查询+文本格式的相应页面
(l)将相关图像(PDF页面)、文本块和用户的查询发送到多模态LLM(如GPT-4V等),并直接返回答案;
要索引的内容:图像格式的文档和文本格式的文档块
发送到多模态LLM的内容:查询+文档的相应图像形式+相应的文本块
以下是一些不需要索引的方法,如图3和图4所示:
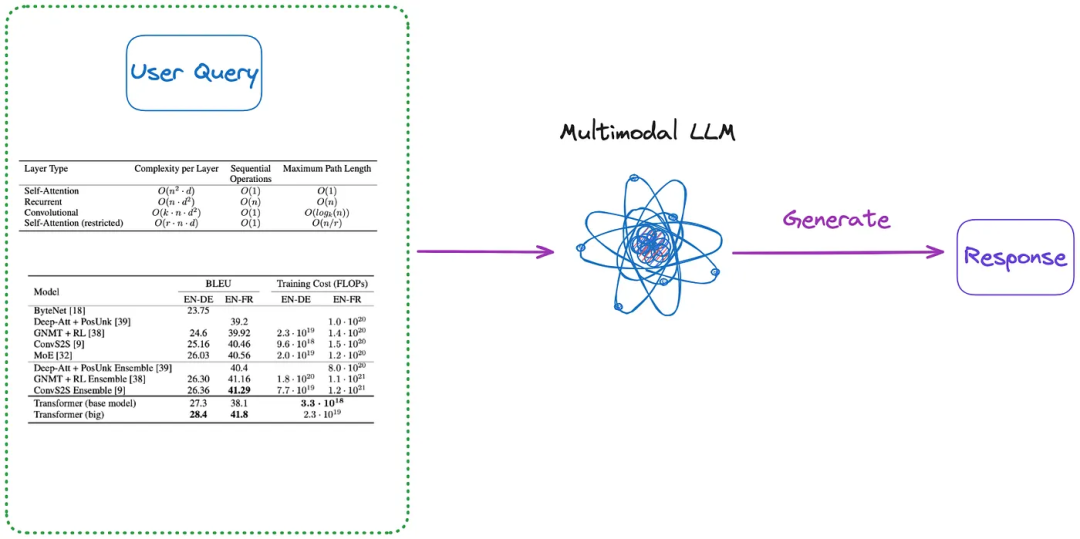
(m)首先,应用类别(a)到(d)中的一种方法,将文档中的所有表格解析为图像形式,然后直接将所有表格图像和用户的查询发送到多模态LLM(如GPT-4V等)并返回答案。
要索引的内容:无
发送到多模态LLM的内容:查询+所有解析的表(图像格式)
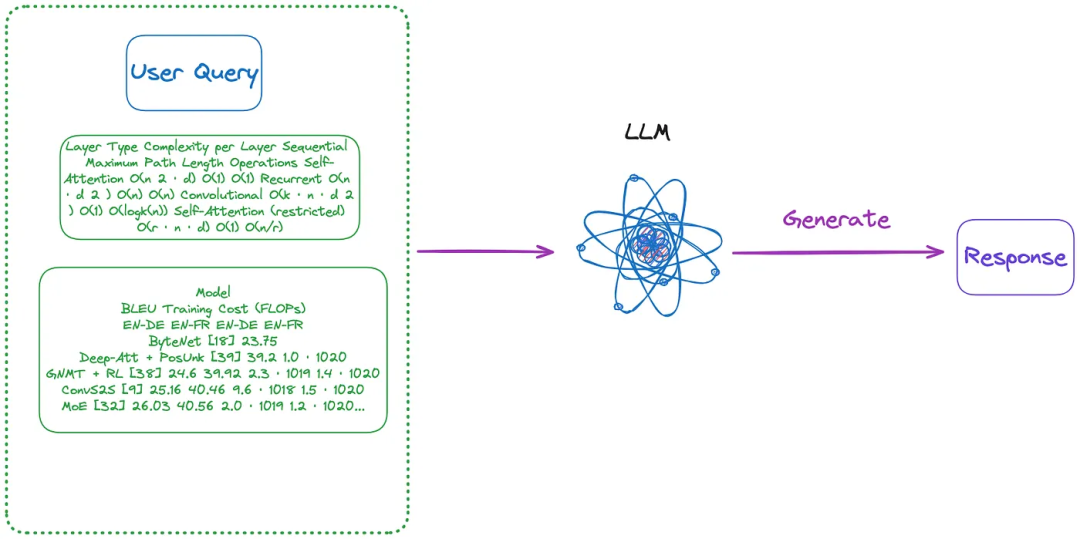
(n)使用(m)提取的图像格式的表格,然后使用OCR模型识别表格中的所有文本,然后直接将表格中的全部文本和用户的查询发送到LLM并直接返回答案。
要索引的内容:无
发送到LLM的内容:用户查询+所有表内容(文本格式)
值得注意的是,有些方法不依赖于RAG过程:
第一种方法不使用LLM,在特定的数据集上进行训练,并使模型(如类似BERT的transformer)能够更好地支持表理解任务,如TAPAS[7]。
第二种方法使用LLM,采用预训练、微调方法或提示,使LLM能够执行表理解任务,如GPT4Table[8]。
二、现有的开源解决方案
上一节总结并对RAG中表格关键技术进行了分类。在提出本文实现的解决方案之前,让我们探索一些开源解决方案。
LlamaIndex支持四种方法[9],前三种都是使用多模态模型:
- 检索相关图像(PDF页面)并将其发送到GPT-4V以响应查询;
- 将每个PDF页面视为一个图像,让GPT-4V对每个页面进行图像推理,为图像推理构建文本矢量存储索引,根据图像推理矢量存储查询答案;
- 使用Table Transformer从检索到的图像中裁剪表信息,然后将这些裁剪的图像发送到GPT-4V以进行查询响应;
- 对裁剪的表图像应用OCR,并将数据发送到GPT4/GPT-3.5以回答查询。
根据本文提出方法进行分类总结:
- 第一种方法类似于本文中的类别(j),不需要表格解析。然而,结果表明,即使答案在图像中,也无法产生正确的答案;
- 第二种方法涉及表格解析,对应于类别(a)。索引内容是基于GPT-4V返回的结果的表内容或摘要,其可以对应于类别(f)或(h)。这种方法的缺点是GPT-4V识别表格并从图像中提取其内容的能力是不稳定的,特别是当图像包括表格、文本和其他图像的混合时,这在PDF格式中很常见;
- 第三种方法,类似于类别(m),不需要索引;
- 第四种方法类似于类别(n),也不需要索引。其结果表明,由于无法从图像中提取表格信息,因此会产生不正确的答案。
通过试验发现,第三种方法的综合效果最好。然而,根据我的测试,第三种方法很难检测表格,更不用说正确地将表标题与表合并了。
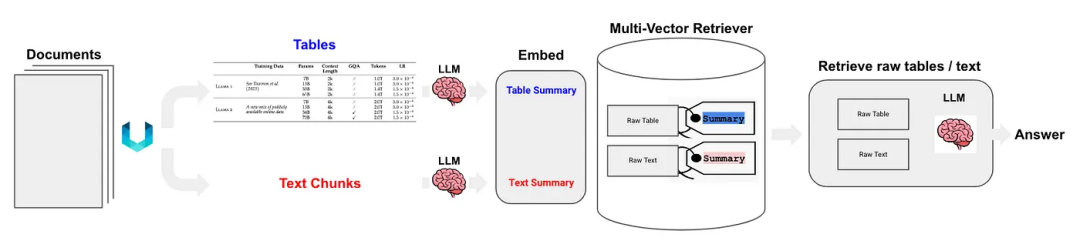
Langchain还提出了一些解决方案,半结构化RAG[10]的关键技术包括:
- 表格解析使用unstructured,即类别(c);
- 索引方法是文档摘要索引,对应类别(i),小块内容:表摘要,大块内容:原始表内容(文本格式)。
如图5所示:
半结构化和多模态RAG[11]提出了三种解决方案,其架构如图6所示。
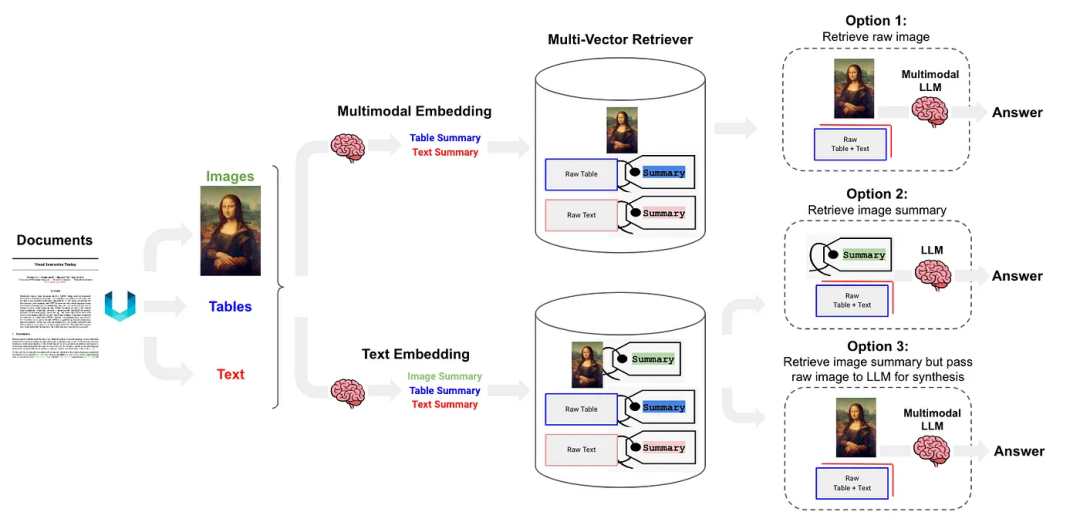
可选方案1:类似于本文的类别(l)。它包括使用多模态嵌入(如CLIP)来嵌入图像和文本,使用相似性搜索进行检索,并将原始图像和块传递给多模式LLM进行答案合成。
可选方案2:利用多模态LLM,如GPT-4V、LLaVA或FUYU-8b,从图像中生成文本摘要。然后,嵌入和检索文本,并将文本块传递给LLM进行答案合成。
- 表解析使用非结构化,即类别(d);
- 索引结构为文档摘要索引(catogery(i)),小块内容:表摘要,大块内容:文本格式的表。
可选方案3:使用多模态LLM(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1629
1629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











