









文章目录
CV入门路线
1.CV综述及图像简介
2.Alexnet net《ImageNet Classification with Deep Convolutional Neural Networks》
3.VGG net:《Very Deep Convolutional Networks for Large-Scale Image Recognition》google netv1 v2v3v4 (串讲) :
4.v1:《Going deeper with convolutions》
5.v2:《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
6.v3:《Rethinking the Inception Architecture for Computer Vision
7.v4:《Inception- ResNet and the Impact of Residual Connections on Learning》
8.resnet:《Deep Residual Learning for Image Recognition》
9.densenet:《Densely Connected Convolutional Networks》
10.SEnet: 《Squeeze- and- Excitation Networks》
11.ResNeXt:《Aggregated Residual Transformations for Deep Neural Networks》
图像基础知识
数字图像的本质就是一个元素为像素的矩阵,在计算机中以数组的形式存储,数组的第一个索引对应矩阵的行,第二个索引对应矩阵的列。
世界坐标系通过平移和旋转得到相机坐标系。相机坐标系通过成像模型中的相似三角形原理得到图像坐标系。图像坐标系通过平移和缩放得到像素坐标系。

像素坐标系
以图像左上角为原点建立以像素为单位的直接坐标系u-v。像素的横坐标u与纵坐标v分别是在其图像数组中所在的列数与所在行数。

像素坐标系中的一个像素点(u,v)对应图像数组的元素img(v,u)
图像坐标系
由于(u,v)只代表像素的列数与行数,而像素在图像中的位置并没有用物理单位表示出来,所以,我们还要建立以物理单位(如毫米)表示的图像坐标系x-y。将相机光轴与图像平面的交点(一般位于图像平面的中心处,也称为图像的主点(principal point)定义为该坐标系的原点
O
1
O_1
O1,且x轴与u轴平行,y轴与v轴平行,假设
(
u
0
,
v
0
)
(u_0,v_0)
(u0,v0)代表
O
1
O_1
O1在u-v坐标系下的坐标,dx与dy分别表示每个像素在横轴x和纵轴y上的物理尺寸,则图像中的每个像素在u-v坐标系中的坐标和在x-y坐标系中的坐标之间都存在如下的关系:
u
=
x
d
x
+
u
0
v
=
y
d
y
+
v
0
u=\dfrac{x}{dx}+u_0\\v=\dfrac{y}{dy}+v_0
u=dxx+u0v=dyy+v0
其中,我们假设物理坐标系中的单位为毫米,那么dx的的单位为:毫米/像素。那么x/dx的单位就是像素了,即和u的单位一样都是像素。为了使用方便,可将上式用齐次坐标与矩阵形式表示为:
[
u
v
1
]
=
[
1
d
x
0
u
0
0
1
d
y
v
0
0
0
1
]
[
x
y
1
]
\begin{bmatrix}u\\v\\1\end{bmatrix}=\begin{bmatrix}\dfrac{1}{dx}&0&u_0 \\ 0&\dfrac{1}{dy}&v_0\\0&0&1\end{bmatrix}\begin{bmatrix}x\\y\\1\end{bmatrix}
uv1
=
dx1000dy10u0v01
xy1
相机坐标系到图像坐标系
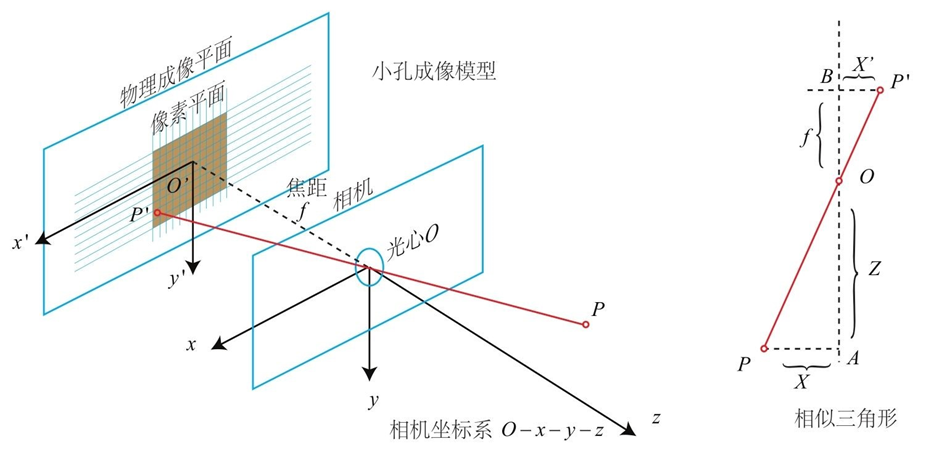
从图中可知,
x
c
x
=
y
c
y
=
z
c
f
\dfrac{x_c}{x}=\dfrac{y_c}{y}=\dfrac{z_c}{f}
xxc=yyc=fzc,其中f为焦距。通过变换可得 ,
x
=
x
c
z
c
f
,
y
=
y
c
z
c
f
x=\dfrac{x_c}{z_c}f,y=\dfrac{y_c}{z_c}f
x=zcxcf,y=zcycf由此可得其增广形式
(
x
y
1
)
=
1
z
c
(
f
0
0
0
0
f
0
0
0
0
1
0
)
(
x
c
y
c
z
c
1
)
\begin{pmatrix}x\\y\\1\end{pmatrix}=\dfrac{1}{z_c}\begin{pmatrix}f&0&0&0 \\ 0&f&0&0\\0&0&1&0\end{pmatrix}\begin{pmatrix}x_c\\y_c\\z_c\\1\end{pmatrix}
xy1
=zc1
f000f0001000
xcyczc1
Opencv API
模块
-
core:最核心的数据结构
-
highgui:视频与图像的读取、显示、存储
-
imgproc:图像处理的基础方法
-
features2d:图像特征以及特征匹配
基础
Mat图像存储容器
//矩阵转置
cv::Mat::t();
cv::transpose(InputArray src,OutputArray dst)
图像的基础操作
1.图像的IO操作
1.1读取图像
1.API
cv2.imread(filepath,flags)
参数:
-
filepath:要读取的图像的完整路径 -
flags:读取方式的标志- cv2.IMREAD_COLOR:以彩色模式加载图像,任何图像的透明度都被忽略,这是默认参数
- cv.IMREAD_GRAYSCALE:以灰度模式加载图像
- cv.IMREAD_UNCHANGED:包括 Alpha通道(透明度) 的加载图像模式
可以使用1、0、-1来代替上面三个标志
参考代码
import numpy as np
import cv2
# 以灰度图的形式读取图像
img=cv2.imread(" .jpg",0)
1.2显示图像
1.API
cv2.imshow(windowName,img)
参数:
windowName:显示图像的窗口名称,以字符串类型表示img要加载的图像
注意:在调用显示图像的API后,要调用cv2.waitKey()给图像绘制留下时间,否则窗口会出现无响应情况,并且图像无法显示出来
参考代码
# opencv中显示
cv.imshow("image",img)
cv.waitKey(0)
# matplotlib中显示
plt.imshow(img[:,:,::-1])
1.3保存图像
1.API
cv.imwrite(file,img,num)
参数:
file:文件名,要保存在哪img:要保存的图像num:第三个参数表示的是压缩级别。默认为3.
2.参考代码
cv.imwrite(" .png",img)
1.4 图像复制
img.copy()
2 绘制几何图形
2.1 绘制直线
cv.line(img,start,end,color,thickness)
参数:
- img:要绘制直线的图像
- start,end:直线的起点和终点
- color:线条的颜色
- thickness:线条宽度
2.2 绘制圆形
cv.circle(img,centerpoint,r,color,thickness)
参数:
- img:要绘制直线的图像
- centerpoint,r:圆心和半径
- color:线条的颜色
- thickness:线条宽度
2.3 绘制矩形
cv.rectangle(img,leftupper,rightdown,color,thickness)
参数:
img:要绘制直线的图像leftupper,rightdown:矩形的左上角和右下角坐标,元组形式(x,y) (x+w,y+h)color:线条的rgb颜色,元组形式,例如(0,255,0)thickness:线条宽度
2.4 向图像中添加文字
cv.putText(img,text,station,font,fontsize,color,thickness)
参数:
- img:要绘制直线的图像
- text:要写入的文本数据、
- station:文本的放置位置
- font:字体
- Fontsize:字体大小
- color:线条的颜色
- thickness:线条宽度
3 获取图像的属性
cv2.boundingRect(img)
返回图像的四值属性,分别是x,y,w,h; x,y是矩阵左上点的坐标,w,h是矩阵的宽和高。
| 属性 | API |
|---|---|
| 形状 | img.shape |
| 图像大小 | img.size |
| 数据类型 | img.dtype |
4.图像通道拆分和合并
#通道拆分
b,g,r=cv.split(img)
#通道合并
img=cv.merge((b,g,r))
5.色彩空间的改变
API:
cv2.cvtColor(input_image,flag)
参数:
input_image:进行颜色空间转换的图像flag:转换类型- cv2.COLOR_BGR2GRAY:BGR ↔ \leftrightarrow ↔Gray
- cv2.COLOR_GRAY2RGB:Gray ↔ \leftrightarrow ↔BGR
- cv2.COLOR_BGR2HSV:BGR ↔ \leftrightarrow ↔HSV
图像的算数操作
1.图像的加法
cv.add(img1,img2)
2.图像的混合
d s t = α ⋅ i m g 1 + β ⋅ i m g 2 + γ dst=\alpha\cdot img1+\beta\cdot img2+\gamma dst=α⋅img1+β⋅img2+γ
API:
cv.addWeighted(img1,权重1,img2,权重2,偏置)
图像处理
1.图像缩放
API:
cv.resize(src,dsize,fx=0,fy=0,interpolation)
参数:
-
src:输入图像
-
dsize:绝对尺寸,直接指定调整后图像的大小,以元组形式给出,如(2*cols,2*rows)
-
fx,fy:相对尺寸,将dsize设置为None,然后将fx和fy设置成比例因子即可
-
interpolation:插值方法
双线性插值法 cv.INTER_LINEAR
最邻近插值 cv.INTER_NEAREST
像素区域重采样 cv.INTER_AREA
双三次插值 cv.INTER_CUBIC
2.图像平移
API:
cv.warpAffine(img,M,dsize)
参数:
-
img:输入图像
-
M:2*3移动矩阵
对于(x,y)处的像素点,要把它移动到 ( x + t x , y + t y ) (x+t_x,y+t_y) (x+tx,y+ty)处时,M矩阵应如下设置:
M = [ 1 0 t x 0 1 t y ] M=\begin{bmatrix}1&0&t_x\\0&1&t_y\end{bmatrix} M=[1001txty]
M[:-1,:]代表方向, t x , t y t_x,t_y tx,ty代表移动距离
注意:将M设置为np.float32类型的Numpy数组。 -
dsize:输出图像的大小
注意:输出图像的大小,它应该是(宽度,高度)的形式。请记住,width=列数,height=行数。
3.图像旋转
API:
cv.getRotationMatrix2D(center,angle,scale)
cv.warpAffine(img,M,dsize)
参数:
-
center:旋转中心
-
angle:旋转角度
-
scale:缩放比例
返回旋转矩阵M,之后调用cv.warpAffine
需要注意的是,对于图像而言,宽度方向是x,高度方向是y,坐标的顺序和图像像素对应下标一致。所以原
点的位置不是左下角而是右上角,y的方向也不是向上,而是向下。
4.仿射变换
图像的仿射变换涉及到图像的形状位置角度的变化,是深度学习预处理中常到的功能,仿射变换主要是对图像
的缩放,旋转,翻转和平移等操作的组合�
视频操作
创建视频对象
cap=cv2.VideoCapture(参数)
arguments:
-
参数是0,表示打开笔记本的内置摄像头;参数是1,则打开外置摄像头;其他数字则代表其他设备;
-
参数是视频文件的路径则打开指定路径下的视频。
读取视频帧
使用视频对象的read()函数,C++还可以使用>>操作符
retval,frame=cap.read()
- image是返回的捕获到的帧,如果没有帧被捕获,则该值为空。
- retval表示捕获是否成功,如果成功则该值为True,不成功则为False。
一般情况下,如果需要读取一个摄像头的视频数据,最简便的方法就是使用函数cv2.VideoCapture.read()。但是,如果需要同步一组或一个多头(multihead)摄像头(例如立体摄像头或Kinect)的视频数据时,该函数就无法胜任了。可以把函数cv2.VideoCapture.read()理解为是由函数cv2.VideoCapture.grab()和函数cv2.VideoCapture.retrieve()组成的。函数cv2.VideoCapture.grab()用来指向下一帧,函数cv2.VideoCapture.retrieve()用来解码并返回一帧。因此,可以使用函数cv2.VideoCapture.grab()和函数cv2.VideoCapture.retrieve()获取多个摄像头的数据。
函数cv2.VideoCapture.grab()用来指向下一帧,其语法格式是:
retval= cv2.VideoCapture.grab( )
如果该函数成功指向下一帧,则返回值retval为True。
函数cv2.VideoCapture.retrieve()用来解码,并返回函数v2.VideoCapture.grab()捕获的视频帧。该函数的语法格式为:
retval, image = cv2.VideoCapture.retrieve( )
- image为返回的视频帧,如果未成功,则返回一个空图像。
- retval为布尔型值,若未成功,返回False;否则,返回True。
对于一组摄像头,可以使用如下代码捕获不同摄像头的视频帧:
success0 = cameraCapture0.grab()
success1 = cameraCapture1.grab()
if success0 and success1:
frame0 = cameraCapture0.retrieve()
frame1 = cameraCapture1.retrieve()
释放视频对象
cap.release()
属性设置
属性获取
cv2.VideoCapture.get(propID)
- 参数propID对应着cv2.VideoCapture类对象的属性
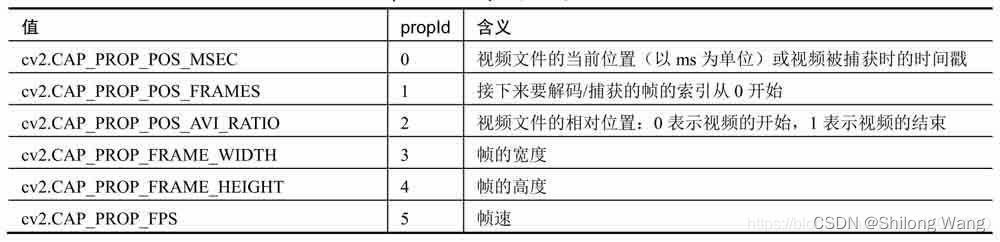
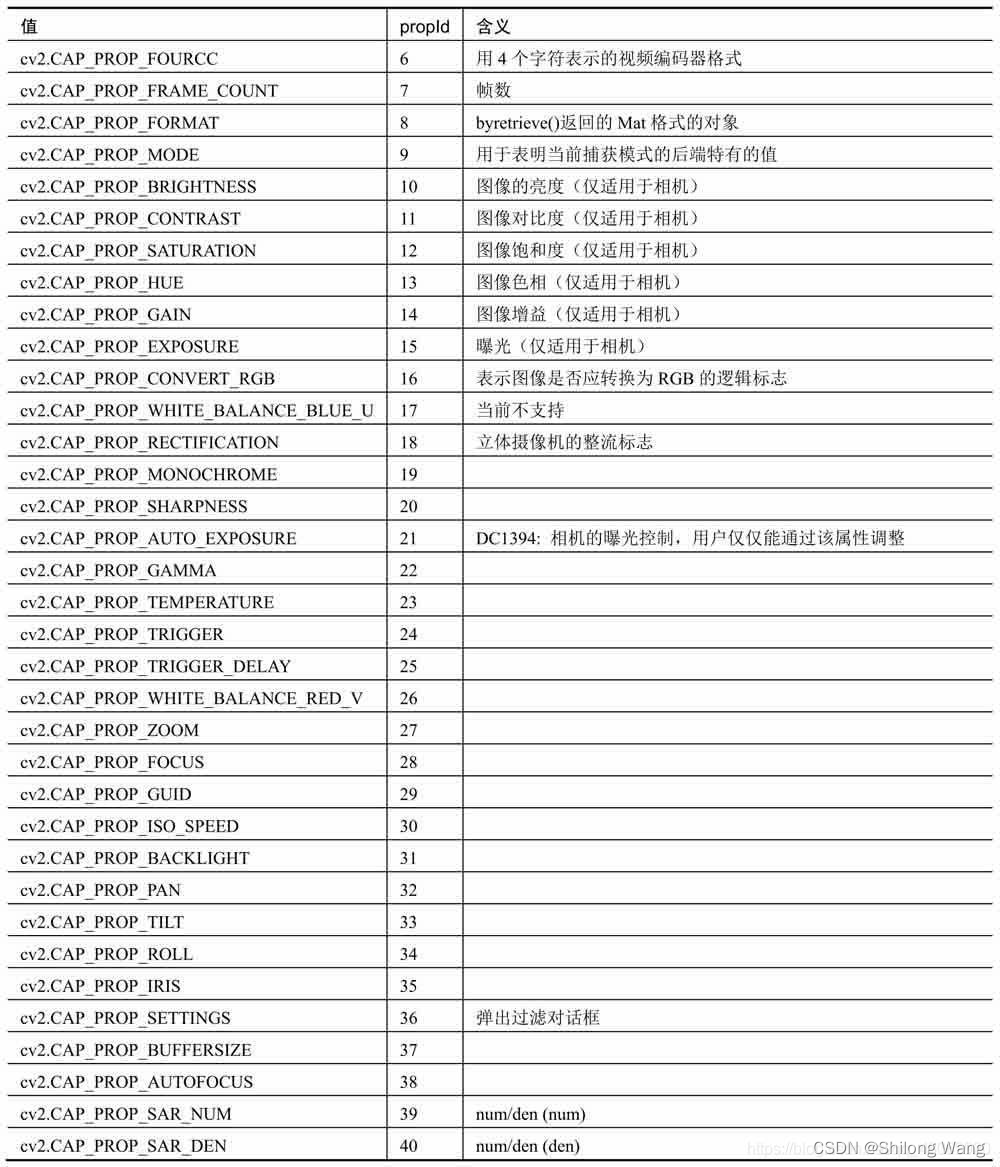
播放视频文件
import cv2
cap = cv2.VideoCapture('output.avi')
while(cap.isOpened()):
ret, frame = cap.read()
cv2.imshow('frame',frame)
c = cv2.waitKey(1)
if c==27: #ESC键
break
cap.release()
cv2.destroyAllWindows()
畸变校正
opencv提供了可以直接使用的校正算法,即通过calibrateCamera()得到的畸变系数,生成校正后的图像。我们可以通过undistort()函数一次性完成;也可以通过initUndistortRectifyMap()和remap()的组合来处理。
1、initUndistortRectifyMap()和remapMAP()
void initUndistortRectifyMap( InputArray cameraMatrix, InputArray distCoeffs,
InputArray R, InputArray newCameraMatrix,
Size size, int m1type, OutputArray map1, OutputArray map2 );
函数说明:
这个函数用于计算畸变图片和校正后图片的转换关系,为了重映射,将结果以映射的形式表达。无畸变的图像看起来就像原始的图像,就像这个图像是用内参为newCameraMatrix的且无畸变的相机采集得到的。
在单目相机例子中,newCameraMatrix一般和cameraMatrix相等,或者可以用cv::getOptimalNewCameraMatrix来计算,获得一个更好的有尺度的控制结果。
在双目相机例子中,newCameraMatrix一般是用cv::stereoRectify计算而来的,设置为P1或P2。 此外,根据R,新的相机在坐标空间中的取向是不同的。例如,它帮助配准双目相机的两个相机方向,从而使得两个图像的极线是水平的,且y坐标相同(在双目相机的两个相机谁水平放置的情况下)。 该函数实际上为反向映射算法构建映射,供反向映射使用。也就是,对于在已经修正畸变的图像中的每个像素(u,v),该函数计算原来图像(从相机中获得的原始图像)中对应的坐标系。
参数说明:
- cameraMatrix——输入的摄像头内参数矩阵(3X3矩阵)
- distCoeffs——输入的摄像头畸变系数矩阵(5X1矩阵)
- R——输入的第一和第二摄像头坐标系之间的旋转矩阵
- newCameraMatrix——输入的校正后的3X3摄像机矩阵
- size——摄像头采集的无失真图像尺寸
- m1type——map1的数据类型,可以是CV_32FC1或CV_16SC2
- map1——表示原图像像素坐标->目标图像u坐标的映射矩阵;
- map2——表示原图像像素坐标->目标图像v坐标的映射矩阵;
函数输出得到map1和map2,然后使用remap()函数:
void remap( InputArray src, OutputArray dst,
InputArray map1, InputArray map2,
int interpolation, int borderMode=BORDER_CONSTANT,
const Scalar& borderValue=Scalar());
remap 函数使用指定的映射转换原图像
d
s
t
(
x
,
y
)
=
s
r
c
(
m
a
p
x
(
x
,
y
)
,
m
a
p
y
(
x
,
y
)
)
{\rm dst}(x,y)={\rm src}\left(map_x(x,y),map_y(x,y)\right)
dst(x,y)=src(mapx(x,y),mapy(x,y))
其中非整数像素坐标的像素值使用提供的插值方法计算。
m
a
p
x
map_x
mapx和
m
a
p
y
map_y
mapy可以分别被编码为单独浮点映射map1和map2,或者被联合编码为一个交叉浮点映射map1,也可以使用convertMaps函数转换为定点映射。映射从浮点表示转换为定点表示可以使映射速度更快,对于定点映射的情况,map1包含点对(cvFloor(x),cvFloor(y)),map2包含插值系数表的索引。
- src:输入图像,即原图像,需要单通道8位或者浮点类型的图像
- dst:输出图像,即目标图像,需和原图形一样的尺寸和类型
- map1
它有两种可能表示的对象:(1)表示(x,y)坐标对值;(2)CV_16SC2 , CV_32FC1, or CV_32FC2类型的x坐标值 - map2:它有两种可能表示的对象:(1)空映射,如果map1表示(x,y)坐标对;(2)CV_16UC1, CV_32FC1类型的y坐标值
- interpolation:插值方式,有四种插值方式:
- INTER_NEAREST——最近邻插值
- INTER_LINEAR——双线性插值(默认)
- INTER_CUBIC——双三样条插值(默认)
- INTER_LANCZOS4——lanczos插值(默认)
- boraderMode:边界模式,默认BORDER_CONSTANT
- borderValue:边界颜色,默认Scalar()黑色
2、undistort()
void undistort( InputArray src, //输入原图
OutputArray dst,//输出矫正后的图像
InputArray cameraMatrix,//内参矩阵
InputArray distCoeffs,//畸变系数
InputArray newCameraMatrix=noArray() );
有时不需要矫正整个图像,而仅仅计算图像中特定点的位置,这是可以使用undistortPoints函数:
void undistortPoints( InputArray src, OutputArray dst,
InputArray cameraMatrix, InputArray distCoeffs,
InputArray R=noArray(), InputArray P=noArray());
undistortPoints函数与undistort()的区别在于:参数src,dst是二维点的向量,std::vectorcv::Point2f ,P对应cameraMatrix。该参数与立体校正方面的使用有关。调用方式:
undistortPoints(inputDistortedPoints, outputUndistortedPoints, cameraMatrix, distCoeffs, cv::noArray(), cameraMatrix);

















 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











