







问题
- 度量地图还是拓扑图?
GOAT
motivation
- 仿照人和动物的导航系统都需要一个空间环境表征,纯粹的反应式无记忆导航系统不足以满足机器人技术的需要。仿照人和动物的“终身学习”——随着移动机器人进行主动搜索和探索,内部空间表征不断改进。这要求机器人建立、维护和更新对环境中的物体、它们的视觉和语言特性以及它们的最新位置的终生记忆。
- 给定任何新的多模式目标,机器人还应该能够查询内存以确定目标对象是否已存在于内存中或需要进一步探索。
- 路标的视觉特征在人和动物的导航中扮演至关重要的角色,所以需要维护机器人所处环境的多模态表征。
- 多模态感知、探索、终生记忆和目标定位,机器人还需要有效的规划和控制才能在避开障碍物的同时达到目标。
方案
感知系统检测物体实例,将它们定位在场景的自上而下的栅格语义图中,并将每个实例已被查看的图像存储在物体实例记忆中。当指定新目标时,全局策略首先尝试在物体实例记忆中搜索定位目标。如果没有定位到物体实例,则全局策略输出一个探索目标。局部策略最终计算实现长期目标的具体行动。
感知
我们使用 MaskRCNN 和在 MS-COCO 上预训练的 ResNet50主干网络进行对象检测和实例分割。使用MiDaS模型进行单目深度估计
搜索匹配
- 匹配方法:将原始图像视图存储在物体实例记忆中,使我们可以针对每个目标模态使用不同的匹配方法。我们使用 CLIP特征之间的余弦相似度得分将语言目标描述与内存中的对象视图进行匹配。另一方面,为了将图像目标与记忆地图中的对象视图进行匹配,我们使用 SuperGLUE 评估 CLIP 特征匹配和基于关键点的匹配
- 匹配阈值:
- 实例二次采样:是将目标与迄今为止捕获的所有实例的视图进行比较,还是仅与目标类别的实例进行比较。直观上,后者速度更快,精度更高,但召回率可能较低,因为它依赖于准确的对象检测。
- 上下文:匹配时使用的实例上下文
存储视觉地标的原始图像
在语义地图里面去搜索目标
定位
规划
实验结果
GOAT 的总体成功率达到 83%,比之前的方法和消融术高出 32%(绝对改进)。 GOAT 使用环境中的经验而持续提高,从第一个目标的 60% 成功率到探索后的 90% 成功率。
对比基线:CLIP on Wheel
在9个不同的家庭场景中评估了GOAT及三个基线算法,每个家庭场景执行10个情节的任务。由从家庭中可用的物体中随机选择5-10个物体实例组成,总共代表200+不同的物体实例。选择了 15 个不同类别的目标(“椅子”、“沙发”、“盆栽植物”、“床”、“厕所”、“电视”、“餐桌”、“烤箱”、“水槽”、“冰箱” 、“书”、“花瓶”、“杯子”、“瓶子”、“泰迪熊”),拍摄了一张图像目标照片。 [32],并注释了唯一标识该物体的 3 种不同语言描述。为了在家里生成一个情节片段,我们随机抽取了 5-10 个目标序列,在所有可用对象实例中的语言、图像和类别目标中均等分配。
三个基线算法
- CLIP on Wheels
- GOAT treats all goals as object categories
- GOAT resets the semantic map and Object Instance Memory after every goal

衡量指标
成功率
the Success weighted by Path Length (SPL):成功的测地距离与最佳路径长度的比值
优点
- 可以通过类别标签、目标图像、语言描述指定目标
- 使用地图存储过往的观测经验,而不是隐式存储在神经网络中
- 模块化方案无需重新训练,泛化性强。而端到端方法需要针对每个不同的实施例进行新的数据收集和重新训练。
方案局限性
GNM
motivation
之前的工作探索从被动数据(YouTube视频)中学习视觉表示或端到端策略,这些数据可以在无需收集实际数据的情况下大规模扩展。本工作探索一个互补的方向,研究使用机器人上可用的数据(也是被动的)训练通用导航策略。
方案
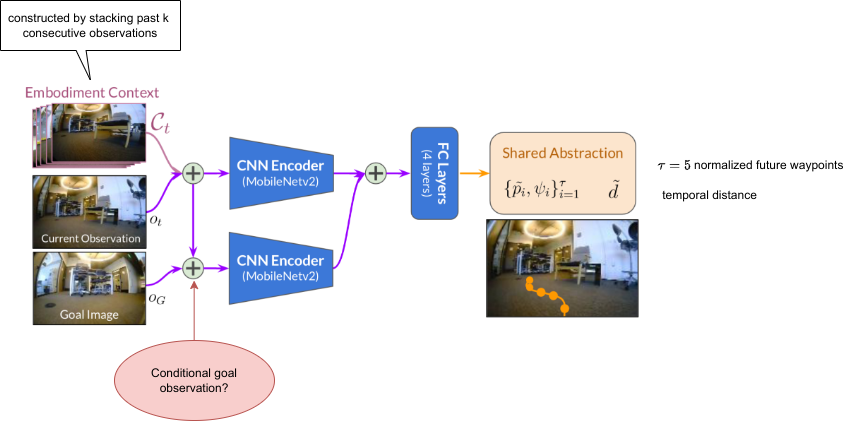
使用拓扑图进行高层规划,使用图像目标策略进行低层控制。
跨机器人的抽象动作空间
我们提出使用共享抽象来允许目标导航策略在跨机器人一致的转换动作空间中运行,使数据点看起来“相似”并且更容易从中学习常见模式。
我们使用相对路径点 p ( x , y ) p(x, y) p(x,y)和偏航变化 ψ \psi ψ的组合作为中间动作空间。提出使用归一化动作空间 { p ~ ( x , y ) , ψ } \{\tilde{p}(x,y),\psi\} {p~(x,y),ψ},其中 p ~ : = 1 α p \tilde{p}:=\dfrac{1}{\alpha}p p~:=α1p。通过与机器人最高速度相对应的机器人特定因子 α \alpha α进行缩放。还预测到目标的时间距离 d d d作为可达性的度量,用来估计拓扑图的连通性。时间距离 d ~ \tilde{d} d~也是在此标准化尺度中估计的。
机器人特定的控制器用来:1. 反归一化waypoints; 2. (使用PID,MPPI等)跟踪轨迹生成底层命令(速度或电机指令)
实施例上下文
当部署在实际机器人上时,策略必须判断特定机器人的功能限制,例如机器人大小、旋转半径。这些参数一般需要手工设置。
我们不是手动定义完全识别机器人的参数,而是从机器人的角度使用一系列连续的过去观测来推断学习的实施例上下文 C t C_t Ct,并在观测之外根据该上下文条件调整学习策略。该上下文包含有关机器人的配置和动态的信息,可用于调节策略的行为。最有效的表示是过去k个连续的观测 { o ( t − k ) : ( t − 1 ) } \{o_{(t−k):(t−1)}\} {o(t−k):(t−1)}上。
虽然此上下文可能不包含完全识别机器人的所有信息,但我们假设它足以有效控制机器人。我们的实验表明,实施例上下文允许在全新的机器人配置上部署相同的策略,而无需任何手工设计的机器人表示。
网络细节
所有观察的网络视觉输入均以 85 × 64 RGB 图像的形式提供。
我们通过使用单独的 MobileNetv2 编码器来训练上下文条件表示:(i) 当前观测
{
o
t
,
C
t
}
\{o_t, C_t\}
{ot,Ct} 和 (ii) 条件化目标观测
这两个嵌入特征被连接并通过三个全连接层传递到两个预测头:归一化时间距离 d t ~ \tilde{dt} dt~ 和一系列 τ = 5 \tau = 5 τ=5 归一化未来路径点 { p ~ i , ψ i } i = 1 τ \{ \tilde{p}_i, \psi _i\}^\tau_{i=1} {p~i,ψi}i=1τ。
训练
我们使用是数据集中从相同轨迹采样的图像-目标对作为“正例”和从不同轨迹采样的图像-目标对为“负例”的组合来获得训练数据对。distance head在正例和负例上训练,action head只在正例上训练。
使用
l
2
l_2
l2回归损失函数,批大小为400-1200,Adam优化器,学习率为
5
×
1
0
−
4
5\times 10^{-4}
5×10−4
长程导航
拓扑图导航:
将图像目标导航策略与拓扑图 M 相结合,其中节点由机器人的观测表示(通过实施例上下文进行增强),边表示节点之间的导航策略的时间距离估计 d ,遵循 ViNG 的设置。
在每个时间步,机器人将 M 中的当前观测值和目标观测值关联起来,即找到与其时间距离最小的节点,并使用 Dijkstra 算法计算子目标的最佳序列
{
s
i
}
\{s_i\}
{si}。
使用当前观测值
{
o
t
,
C
t
}
\{o_t, C_t\}
{ot,Ct}和直接子目标
s
1
s_1
s1查询策略
π
\pi
π,以获得一系列路径点
{
p
~
i
,
ψ
i
}
i
=
1
τ
\{\tilde{p}_i, \psi_i\}^{\tau}_{i=1}
{p~i,ψi}i=1τ,这些路径点由机器人特定的低级控制器跟踪。
实验结果
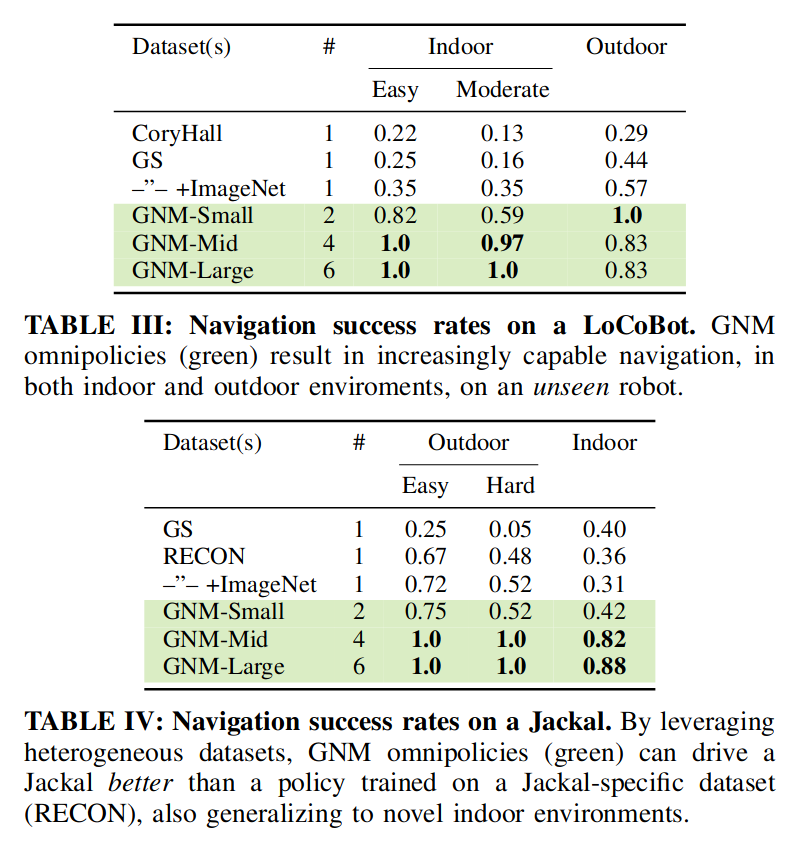
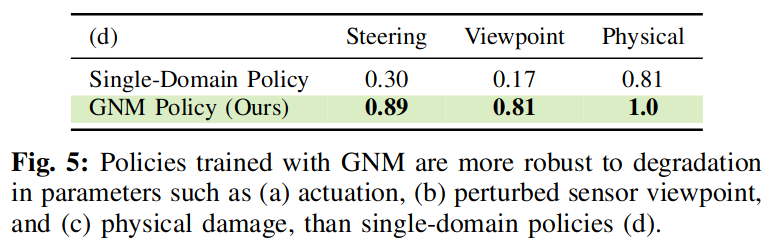
虽然使用速度作为动作空间适用于大多数简单的环境,并且通常优于使用航路点的策略,但这两种策略在需要急转弯等动态操作的环境中都表现不佳。另一方面,基于标准化航路点的策略明显优于其他策略,包括在充满挑战的环境中。这表明,规范化行动空间确实可以使政策更有效地学习并推广到新的机器人。
考虑了两种实施例上下文:
- 过去的时间上连续的k帧观测
- 静态上下文,包含固定的一组k帧过去观测
实验发现加入任一形式的上下文都能显著提高在更艰难环境(有很多障碍物的狭窄走廊,需要急转弯)中的导航表现。在两种表示中,实验发现时间变量更优越,这表明时间信息很重要。
方案局限性
没有明确考虑能力差异,假设所有机器人都是带有前向RGB摄像头的地面机器人。
ViNT
motivation
- 维护环境空间表示的拓扑图
- 用于低级控制的可学习的策略
- 使用可学习的启发式方法在新环境中引导机器人
使用Diffusion Model根据当前观测对不同的未来子目标候选进行采样。在探索过程中,我们会在机器人探索环境时动态构建拓扑图。
获取候选子目标,在候选子目标层级进行规划。
方案
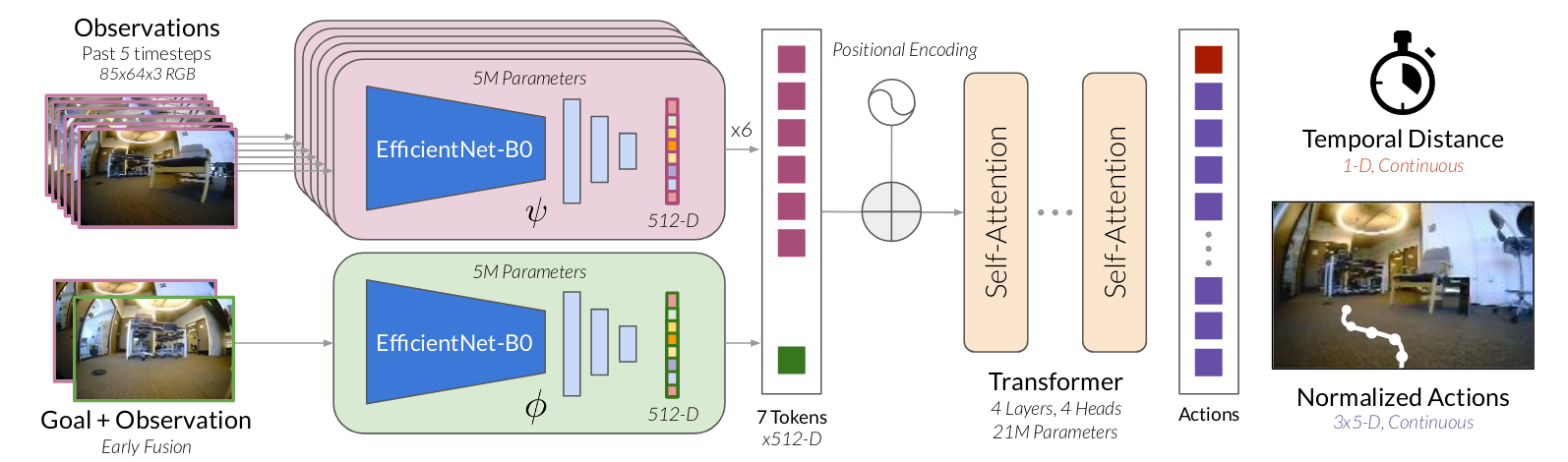
输入为过去和当前的视觉观测 o t − P : t o_{t-P:t} ot−P:t和子目标图像 o s o_s os,输出与GNM相同:达到子目标的时间距离 d t ~ \tilde{dt} dt~和长度为H的未来行动序列 { p ~ i , ψ i } i = 1 H \{ \tilde{p}_i, \psi _i\}^H_{i=1} {p~i,ψi}i=1H。基于Transformer架构进行优化。
输入当前和过去P = 5的视觉观测结果通过 EfficientNet-B0 模型进行编码,得到 d m o d e l = 512 d_{model}=512 dmodel=512的嵌入式特征表征,该模型需要 85 × 64 × 3 图像作为输入,并从最终卷积层输出展平的特征向量 ψ ( o i ) \psi(o_i) ψ(oi)。
我们发现,使用 EfficientNet 编码器 ϕ \phi ϕ直接从目标图像中提取特征 ϕ ( o s ) \phi(o_s) ϕ(os)会导致性能不佳,经常完全忽略目标。我们假设基于图像的目标导航任务的有效特征通常是相对的,编码当前观测与目标之间的差异,而不是目标本身的绝对表示。因此,我们使用目标融合编码器 ϕ ( o t , o s ) \phi(o_t, o_s) ϕ(ot,os)来联合编码当前和目标观测值。沿着通道维度堆叠两个图像,将它们传递给另外的 EfficientNet-B0 编码器,然后展平以获得目标特征表征。
P+2个观测和目标tokens组合起来与位置编码相结合并馈送到Transformer主干网络 f f f 中去。我们使用带有 n L = 4 n_L = 4 nL=4个多头注意力块的解码器Transformer,每个注意力块有 n H = 4 n_H = 4 nH=4个头和 d F F = 2048 d_{FF} = 2048 dFF=2048个隐藏单元。
训练目标函数
在训练过程中,我们首先从数据集
D
D
D中采样一小批轨迹
τ
\tau
τ。然后,我们选择
P
P
P个连续观测值来形成时间上下文
o
t
:
t
−
P
o_{t:t−P}
ot:t−P,并随机选择未来的观测值
o
s
:
=
o
t
+
d
o_s := o_{t+d}
os:=ot+d,其中
d
d
d均匀采样于
[
l
m
i
n
,
l
m
a
x
]
[l_{min}, l_{max}]
[lmin,lmax],作为子目标。相应的
H
H
H 个未来动作
a
^
:
=
a
t
:
t
+
H
\hat{a} := a_{t:t+H}
a^:=at:t+H和距离
d
d
d用作标签并使用最大似然函数进行训练:
L
V
i
N
T
(
ϕ
,
ψ
,
f
)
=
E
τ
E
t
E
d
[
log
p
(
a
^
∣
f
(
ψ
(
o
)
t
:
t
−
P
,
ϕ
(
o
t
,
o
s
)
)
+
λ
log
p
(
d
∣
f
(
ψ
(
o
)
t
:
t
−
P
,
ϕ
(
o
t
,
o
s
)
)
]
\mathcal{L}_{\mathrm{ViNT}}(\phi,\psi,f)=\mathbb{E}_\tau\mathbb{E}_t\mathbb{E}_d \left[\log p(\hat{a}|f(\psi(o)_{t:t-P},\phi(o_t,o_s))+\lambda\log p(d|f(\psi(o)_{t:t-P},\phi(o_t,o_s))\right]
LViNT(ϕ,ψ,f)=EτEtEd[logp(a^∣f(ψ(o)t:t−P,ϕ(ot,os))+λlogp(d∣f(ψ(o)t:t−P,ϕ(ot,os))]
解决长程导航的子目标提议模块
问题:虽然 ViNT 学到的目标条件策略捕获了对导航可达性和障碍的一般理解,但它本身的适用性有限。许多实际任务要么不是由目标图像定义的,要么需要比 ViNT 直接支持的更长的范围。
将ViNT与拓扑图组成的情景记忆相结合,该记忆提供了到达远处途经的短距离子目标。
在未见过的环境中,通过探索性子目标提议模块进一步增强 基于图的规划器,使得ViNT去探索新环境并发现到达目标的路径。
考虑了多种子目标提议机制并发现表现最好的是通过图像Diffusion模型根据当前观测采样得到多个未来子目标候选。
这些子目标候选通过目标导向的启发式函数进行评分,使用类似Astar的搜索过程选择最佳子目标进行导航。
历史观测和未探索边界以拓扑图节点的方式存储,其连接性由ViNT预测的距离决定,会在探索过程中动态构建拓扑图。
该模块使用Diffusion扩散模型生成候选子目标,并建立拓扑图,在拓扑图中使用A*算法进行子目标层级的路径规划
我们在线构建一个拓扑图 M 来充当情景记忆,每个节点作为一个单独的子目标观测,边代表两个子目标之间的路径,当机器人采用该路径时添加,或者模型预测一个子目标可以从另一个子目标到达节点。我们将目标导向的探索视为一个搜索问题,其中机器人在搜索目标的同时逐步构建拓扑图M。为了引导搜索朝着目标前进,机器人使用目标导向的启发式 h(ot, osi , G, M, C) 根据子目标候选者达到目标的可能性(给定附加上下文 C)对子目标候选者进行评分 - 例如,地板计划或卫星图像 [15, 29]。这种启发式可以是几何的(例如,欧几里得距离)或学习的。
探索时在线构建拓扑图,节点是图像观测,边是时间距离,当机器人采取路径时将路径添加到边。已经建过图,在导航时在
结果
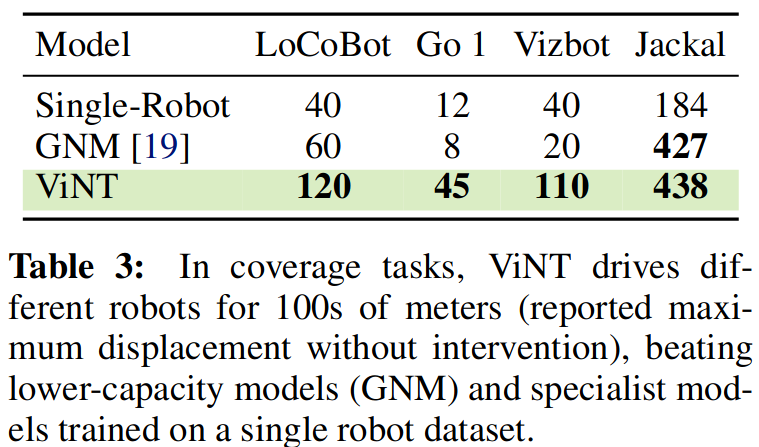
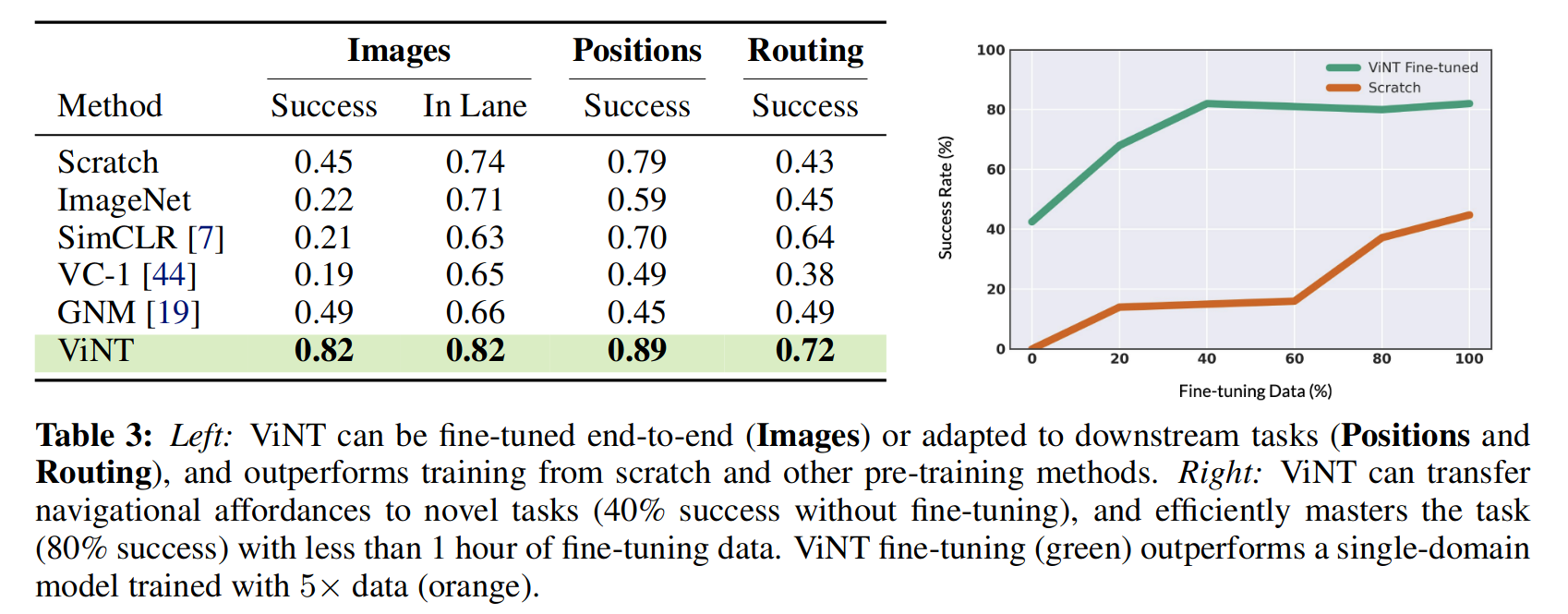 虽然 ViNT 仅使用简单的自监督训练目标函数在离线数据上进行训练,发现它的防撞能力可推广到动态障碍物和行人
虽然 ViNT 仅使用简单的自监督训练目标函数在离线数据上进行训练,发现它的防撞能力可推广到动态障碍物和行人
局限性
- 部署成本较高,推理时间长。
与许多大型模型一样,ViNT 在推理时承担着较重的计算负担,这可能会给四轴飞行器等功率受限的平台带来挑战。虽然我们的设计旨在实现高效推理,但与更简单的前馈卷积网络相比,我们基于 Transformer 的模型在部署时的运行成本仍然要高得多。 - 对不同结构的机器人泛化能力有限
尽管 ViNT 在我们的实验中可以有效地推广到各个机器人,但它假设了一定程度的结构相似性。例如,它无法控制四轴飞行器的高度或处理动作表示的其他变化,也无法适应激光雷达等新传感器。
NoMaD
训练一个单独的统一模型同时处理目标导航和无目标探索任务
与 NoMaD 最接近的相关工作是 ViNT,它使用目标条件导航策略和单独的高容量子目标提议模型。子目标提议模型被实例化为 300M 参数图像Diffusion模型,根据机器人当前的观察生成候选子目标图像。 NoMaD 以不同的方式使用扩散模型:我们不是通过扩散和调节这些代来生成子目标图像,而是直接根据机器人的扩散观察来建模动作。根据经验,我们发现 NoMaD 在无向探索方面比 ViNT 系统高出 25% 以上。此外,由于 NoMaD 不生成高维图像,因此它需要的参数减少了 15 倍以上,从而提供了一种更紧凑、更高效的方法,可以直接在功能较弱的机载计算机(例如 NVIDIA Jetson Orin)上运行。
motivation
使用一个同一的diffusion policy联合表示任务不可知行为(结合了图搜索、前沿探索和高度表达策略的框架中表示探索性任务)和目标导向的任务特定行为。
我们的目标是设计一个用于视觉导航的控制策略 π,它将机器人当前和过去的 RGB 观察结果作为输入 o t : = o t − P : t \bold{o}_t := o_{t−P :t} ot:=ot−P:t 并输出未来动作的分布 a t : = a t : t + H \bold{a}_t:= a_{t:t+H} at:=at:t+H。该策略还可以接收用于指定导航任务的目标RGB 图像 o g o_g og。当提供目标 o g o_g og 时,π 必须采取行动,朝着目标取得进展,并最终实现目标。在看不见的环境中,目标图像 o g o_g og可能不可用,π必须通过采取安全合理的导航动作(例如,避开障碍物、沿着走廊等)来探索环境,同时提供对环境中有效充分覆盖。
将目标条件导航和开放式探索放进一个单独的模型中,基于ViNT模型进行改进。
虽然 ViNT 在目标条件导航方面表现出最先进的性能,但它无法执行无向探索,并且需要外部子目标提议机制。 NoMaD 扩展了 ViNT,以实现目标条件导航和无向导航。
改进思路
- 引入基于注意力机制的目标掩蔽技术Goal Masking,
m
m
m可用于屏蔽目标标记
ϕ
(
o
t
,
o
g
)
\phi(o_t, o_g)
ϕ(ot,og),从而阻塞策略的目标条件路径。
c t = f ( ψ ( o i ) , ϕ ( o t , o g ) , m ) c_t=f(\psi(o_i),\phi(o_t,o_g),m) ct=f(ψ(oi),ϕ(ot,og),m)
通过设置目标掩码 m = 1 m=1 m=1,下游计算 c t c_t ct时将不会使用目标token。通过设置 m = 0 m=0 m=0,目标token将与观察标记一同使用用于下游计算 c t c_t ct。
在训练期间,目标掩码 m m m是从概率为 p m p_m pm 的伯努利分布中采样的。实际训练期间使用固定值 p m = 0.5 p_m=0.5 pm=0.5 ,对应于相同数量的目标导航和无向探索训练样本。 - 使用Diffusion policy 提供机器人可以采取的无碰撞动作的先验表达
从高斯分布中随机采样未来动作序列 a t K a^K_t atK并执行K次去噪迭代,以产生一系列噪声水平逐渐降低的中间动作序列 { a t K , a t K − 1 , … , a t 0 } \{\bold{a}_t^K,\bold{a}_t^{K-1},\dots,\bold{a}_t^0\} {atK,atK−1,…,at0}直到形成所需无噪声输出 a t 0 \bold{a}_t^0 at0
a t k − 1 = α ⋅ ( a t k − γ ϵ θ ( c t , a t k , k ) + N ( 0 , σ 2 I ) ) \mathbf{a}_t^{k-1}=\alpha\cdot(a_t^k-\gamma\epsilon_\theta(c_t,\mathbf{a}_t^k,k)+\mathcal{N}(0,\sigma^2I)) atk−1=α⋅(atk−γϵθ(ct,atk,k)+N(0,σ2I))
其中 ϵ θ \epsilon_\theta ϵθ是由 θ \theta θ参数化的噪声预测网络,依赖于观测上下文 c t c_t ct。
在训练过程中,我们通过向真实动作序列添加噪声来训练 ϵ θ \epsilon_\theta ϵθ。通过均方误差 (MSE) 损失将预测噪声与实际噪声进行比较。
训练损失函数:
L
N
o
M
a
D
(
ϕ
,
ψ
,
f
,
θ
,
f
d
)
=
M
S
E
(
ε
k
,
ε
θ
(
c
t
,
a
t
0
+
ε
k
,
k
)
)
+
λ
⋅
M
S
E
(
d
(
o
t
,
o
g
)
,
f
d
(
c
t
)
)
\begin{aligned}\mathcal{L}_{\mathrm{NoMaD}}(\phi,\psi,f,\theta,f_d)&=MSE(\varepsilon^k,\varepsilon_\theta(c_t,\mathbf{a}_t^0+\varepsilon^k,k))\\&+\lambda\cdot MSE(d(\mathbf{o}_t,o_g),f_d(c_t))\end{aligned}
LNoMaD(ϕ,ψ,f,θ,fd)=MSE(εk,εθ(ct,at0+εk,k))+λ⋅MSE(d(ot,og),fd(ct))
其中
ψ
,
ϕ
\psi,\phi
ψ,ϕ对应于观测图像和目标图像的视觉编码器,
f
f
f对应于Transformer层,
θ
\theta
θ对应于扩散过程的参数,
f
d
f_d
fd 对应于时间距离预测器。扩散策略使用 Square Cosine Noise Scheduler [42] 和
K
=
10
K = 10
K=10 去噪步骤进行训练。我们对去噪迭代数
k
k
k 进行均匀采样,并且还使用迭代
k
k
k 处定义的方差对相应的噪声
ε
k
\varepsilon^k
εk 进行采样。
噪声预测网络
ε
θ
\varepsilon_\theta
εθ 由具有 15 个卷积层的 1D 条件 U-Net组成。
使用学习率为
1
0
−
4
10^{-4}
10−4的AdamW优化器训练,使用cosine scheduling和warmup来稳定训练过程,其他超参数与ViNT相同。使用 EfficientNet-B0将观测和目标编码为 256 维嵌入,然后输入具有 4 层和 4 个头的 Transformer 解码器。
方法
长程导航
拓扑图 M \mathcal{M} M节点对应机器人在环境中的视觉观察,边对应与两个节点之间的可导航路径。探索未见过的环境时在线构建拓扑图。这个基于图的框架还支持达到高级目标 G 的能力,该目标可以是任意远的,并指定为 GPS 位置、地图上的位置、语言指令等。
局限性
- 只能接收图像模态输入,无法使用更自然的自然语言或坐标输入。
- 使用frontier-based exploration策略,探索效率较低。下一步使用基于语义和先验知识的探索策略可以进一步提高探索的效率。
SayPlan
分层拓扑图
大模型给waypoint,传统导航控制
















 3852
3852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











