







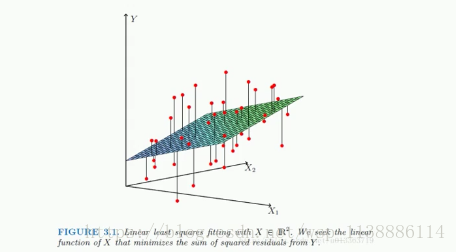
一、多元线性回归
多元线性回归示例:
y=b+a1∗x1+a2∗x2+⋅⋅⋅+an∗xn
y
=
b
+
a
1
∗
x
1
+
a
2
∗
x
2
+
·
·
·
+
a
n
∗
x
n
房价预测案例:
多重共线性(Multicollinearty):
是指线性回归模型中的 解释变量(X)之间
由于存在高度相关关系而使模型估计失真或难以估计准确
多重共线性的影响:
上述模型参数($a_1,a_2...$)估值不准,有时候会导致出现相关性反转。
如何发现多重共线性
对X变量探索两两之间的相关性(相关矩阵)
逐步回归概念是一种多元回归模型进行变量筛选的方法,筛选最少的变量来获取最大化预测能力
三种方法:
向前选择法
向后剔除法
逐步回归法
二、正则化防止过拟合
-
L2正则化–岭回归 Ridge Regression
-
min∑i=1n(Yi−Yi^)=min∑i=1nε^2i m i n ∑ i = 1 n ( Y i − Y i ^ ) = m i n ∑ i = 1 n ε ^ i 2
在最小化残差平方和的基础上,增加L2范数的惩罚项:
∑i=1n(yi−β0−∑j=1pβjxij)2+λ∑j=1pβ2j=RSS+λ∑j=1pβ2j ∑ i = 1 n ( y i − β 0 − ∑ j = 1 p β j x i j ) 2 + λ ∑ j = 1 p β j 2 = R S S + λ ∑ j = 1 p β j 2
L1正则化–lasso回归
-
min∑i=1n(Yi−Yi^)=min∑i=1nε^2i m i n ∑ i = 1 n ( Y i − Y i ^ ) = m i n ∑ i = 1 n ε ^ i 2
在最小化残差平方和的基础上,增加L1范数的惩罚项:
∑i=1n(yi−β0−∑j=1pβjxij)2+λ∑j=1p|βj|=RSS+λ∑j=1p|βj| ∑ i = 1 n ( y i − β 0 − ∑ j = 1 p β j x i j ) 2 + λ ∑ j = 1 p | β j | = R S S + λ ∑ j = 1 p | β j |
三、非线性回归:多项式回归
-
方法:
- 非线性回归的转换——取对数
多项式回归代码实现:
sklearn.preprocession.PolynomialFeatures(
degree = 2, #阶数
interaction_only = False,
include_bias = True
)
sklearn.linear_model.LinearRegression(
fit_intercept = True,
noemalize = False,
copy_X = True
)3.1 回归模型评估指标
-
解释方差(Explianed variance score):
-
Explianed_variance(y,y^)=1−Var{y−y^}Var{y} E x p l i a n e d _ v a r i a n c e ( y , y ^ ) = 1 − V a r { y − y ^ } V a r { y }
绝对平均误差(Mean absolute error):
-
MAE(y,y^)=1nsamplies∑i=0nsamplies−1|yi−y^| M A E ( y , y ^ ) = 1 n s a m p l i e s ∑ i = 0 n s a m p l i e s − 1 | y i − y ^ |
均方误差(Mean squared error):
-
MSE(y,y^)=1nsamplies∑i=0nsamplies−1(yi−y^)2 M S E ( y , y ^ ) = 1 n s a m p l i e s ∑ i = 0 n s a m p l i e s − 1 ( y i − y ^ ) 2
决定系数(
R2
R
2
score)
-
R2(y,y^)=1−∑nsamplies−1i=0(yi−yi^)2∑nsamplies−1i=0(yi−y¯)2 R 2 ( y , y ^ ) = 1 − ∑ i = 0 n s a m p l i e s − 1 ( y i − y i ^ ) 2 ∑ i = 0 n s a m p l i e s − 1 ( y i − y ¯ ) 2
代码:
sklearn.metrics
from sklearn.metrics import explained_variance_score
explained_variance_score(y_true,y_pred)
from sklearn.metrics import mean_absolute_error
mean_absolute_error(y_true,y_pred)
from sklearn.metrics import mean_squared_error
mean_squared_error(y_true,y_pred)
from sklearn.metrics import r2_score
r2_score(y_true,y_pred)四、决策树(分类回归树)分类标准
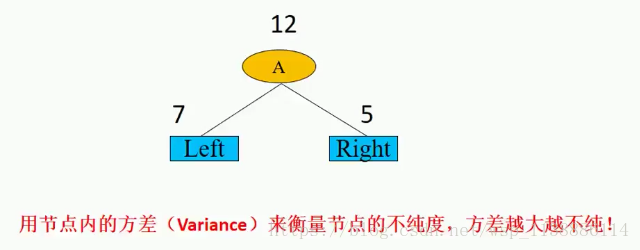
>
Gain(A) = Variance(父) - Variance(子) #Gain(A)信息增益
五、相关和回归
5.1 相关和回归的关系
都是研究变量相互关系的分析方法
相关分析是回归分析基础和前提,回归分析是变量之间相关程度的具体形式
相关分析:正相关,负相关
相关形式: 线性, 非线性
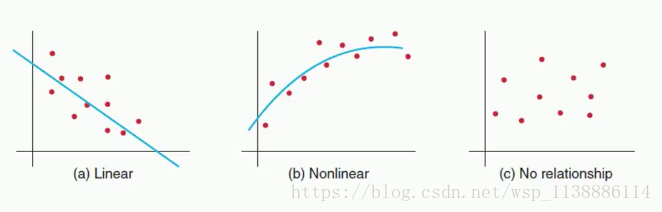
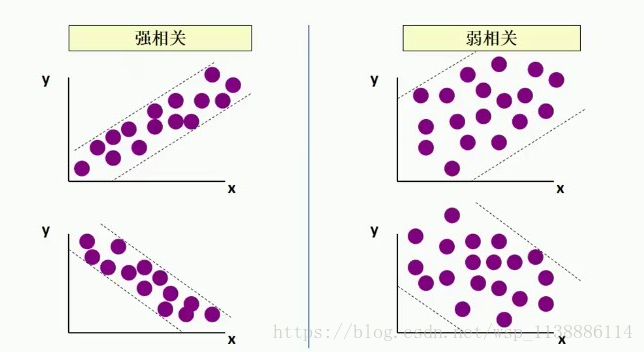
>
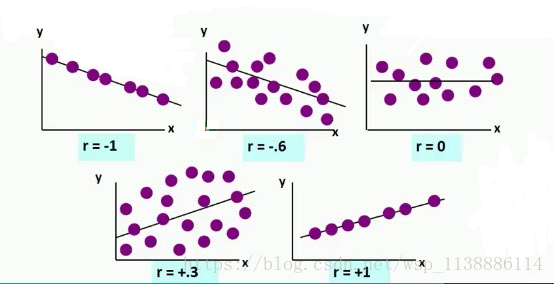
5.2 线性相关性度量:皮尔逊相关系数
r=∑ni=1(xi−x¯)(yi−y¯)∑ni=1(xi−x¯)2−−−−−−−−−−−√∑ni=1(yi−y¯)2−−−−−−−−−−−√
r
=
∑
i
=
1
n
(
x
i
−
x
¯
)
(
y
i
−
y
¯
)
∑
i
=
1
n
(
x
i
−
x
¯
)
2
∑
i
=
1
n
(
y
i
−
y
¯
)
2
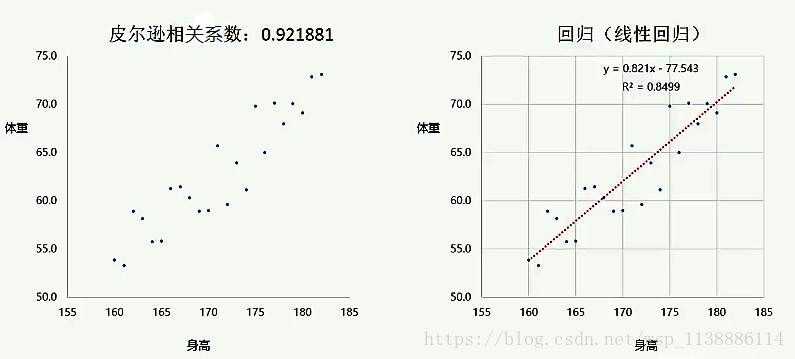
相关VS回归:
六、一元线性回归
6.1 一元线性回归模型

-
寻找最佳拟合直线:最小二乘法
-
该方法是寻找最佳拟合直线的参数(斜率和截距)
min∑i=1n(Yi−Yi^)2=min∑i=1nεi^2 m i n ∑ i = 1 n ( Y i − Y i ^ ) 2 = m i n ∑ i = 1 n ε i ^ 2
参数估计 回归表达式: Yi^=β0^+β1^xi Y i ^ = β 0 ^ + β 1 ^ x i -
斜率: β1^=SSxySSxx=∑(xi−x¯)yi−y¯)∑(xi−x¯)2 斜 率 : β 1 ^ = S S x y S S x x = ∑ ( x i − x ¯ ) y i − y ¯ ) ∑ ( x i − x ¯ ) 2
截距: β0^=y¯−β1^x¯ 截 距 : β 0 ^ = y ¯ − β 1 ^ x ¯
七、课程总结
分类与回归 区别与联系
相似之处:
都是有监督学习
最重要的两种预测模型
决策树既可以分类 也可以做回归
二元分类模型的经典算法逻辑回归算法,本质上也是一种回归算法
区别:
回归目标变量是连续型变量
分类目标变量是类别型变量
常见的饿回归算法和模型
1 基于最小二乘法的一元/多元线性回归
2 多项式回归(非线性)
3 Ridge 回归(L2正则化回归),岭回归
4 Lasso 回归(L1正则化回归),套索回归
5 决策树(CART,分类回归树)
6 逻辑回归


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











