







 本文介绍了深度学习模型压缩的两种方法:基于教师-学生网络,通过迁移学习将复杂网络的知识转移给小型学生网络;以及精细模型设计,如MobileNets、ResNeXt和ShuffleNet,通过巧妙的网络结构减少计算量。这些方法在保持性能的同时,显著减小了模型的复杂度和计算需求。
本文介绍了深度学习模型压缩的两种方法:基于教师-学生网络,通过迁移学习将复杂网络的知识转移给小型学生网络;以及精细模型设计,如MobileNets、ResNeXt和ShuffleNet,通过巧妙的网络结构减少计算量。这些方法在保持性能的同时,显著减小了模型的复杂度和计算需求。
深度学习模型压缩方法综述(一)
深度学习模型压缩方法综述(二)
深度学习模型压缩方法综述(三)
前言
在前两章,我们介绍了一些在已有的深度学习模型的基础上,直接对其进行压缩的方法,包括核的稀疏化,和模型的裁剪两个方面的内容,其中核的稀疏化可能需要一些稀疏计算库的支持,其加速的效果可能受到带宽、稀疏度等很多因素的制约;而模型的裁剪方法则比较简单明了,直接在原有的模型上剔除掉不重要的filter,虽然这种压缩方式比较粗糙,但是神经网络的自适应能力很强,加上大的模型往往冗余比较多,将一些参数剔除之后,通过一些retraining的手段可以将由剔除参数而降低的性能恢复回来,因此只需要挑选一种合适的裁剪手段以及retraining方式,就能够有效的在已有模型的基础上对其进行很大程度的压缩,是目前使用最普遍的方法。然而除了这两种方法以外,本文还将为大家介绍另外两种方法:基于教师——学生网络、以及精细模型设计的方法。
基于教师——学生网络的方法
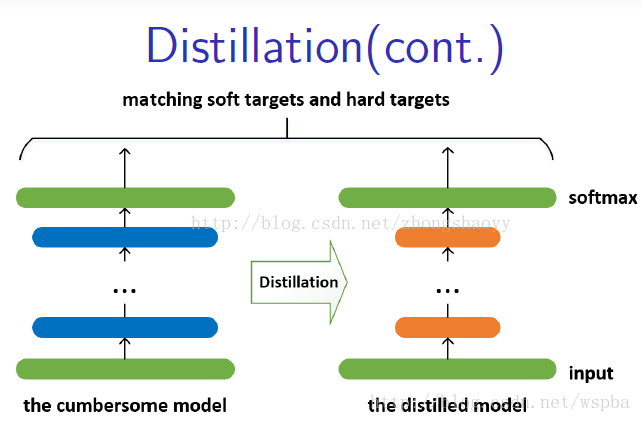
基于教师——学生网络的方法,属于迁移学习的一种。迁移学习也就是将一个模型的性能迁移到另一个模型上,而对于教师——学生网络,教师网络往往是一个更加复杂的网络,具有非常好的性能和泛化能力,可以用这个网络来作为一个soft target来指导另外一个更加简单的学生网络来学习,使得更加简单、参数运算量更少的学生模型也能够具有和教师网络相近的性能,也算是一种模型压缩的方式。
Distilling the Knowledge in a Neural Network 论文地址
较大、较复杂的网络虽然通常具有很好的性能,但是也存在很多的冗余信息,因此运算量以及资源的消耗都非常多。而所谓的Distilling就是将复杂网络中的有用信息提取出来迁移到一个更小的网络上,这样学习来的小网络可以具备和大的复杂网络想接近的性能效果,并且也大大的节省了计算资源。这个复杂的网络可以看成一个教师,而小的网络则可以看成是一个学生。
这个复杂的网络是提前训练好具有很好性能的网络,学生网络的训练含有两个目标:一个是hard target,即原始的目标函数,为小模型的类别概率输出与label真值的交叉熵;另一个为soft target,为小模型的类别概率输出与大模型的类别概率输出的交叉熵,在soft target中,概率输出的公式调整如下,这样当T值很大时,可以产生一个类别概率分布较缓和的输出:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









