







本文作者提出了一种轻量级的目标检测 Transformer-LW-DETR,它在实时目标检测方面优于YOLO系列。除了关注YOLO系列,其他的赛道,我们也应该尝试尝试。
- 论文题目:LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
- 论文地址:https://arxiv.org/pdf/2406.03459
- 代码地址:GitHub - Atten4Vis/LW-DETR: This repository is an official implementation of the paper "LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection".

摘要
在本文中,提出了一种轻量级的检测转换器LW - DETR,它在实时目标检测方面优于YOLOs。该架构是ViT编码器、投影仪和浅层DETR解码器的简单堆叠。本文方法利用了最近的先进技术,如训练有效的技术,如改进的损失和预训练,以及交错窗口和全局注意力,以降低ViT编码器的复杂性。对ViT编码器进行改进,通过聚合多层特征图,以及ViT编码器中的中间特征图和最终特征图,形成更丰富的特征图,并引入窗口主特征图组织,以提高交错注意力计算的效率。实验结果表明,在COCO和其他基准数据集上,该方法优于现有的实时检测器,如YOLO及其变体。
关键词:目标检测·实时性·检测变换器
1 Introduction
实时目标检测是视觉识别中的一个重要问题,在现实世界中有着广泛的应用。目前占主导地位的解决方案是基于卷积网络的,如YOLO系列的。最近的Transformer方法,如检测Transformer( DETR )的重大进展。不幸的是,用于实时检测的DETR仍然没有被充分研究,并且不清楚其性能是否与最先进的卷积方法相媲美。
本文方法优于之前的SoTA实时检测器。性能见下图:
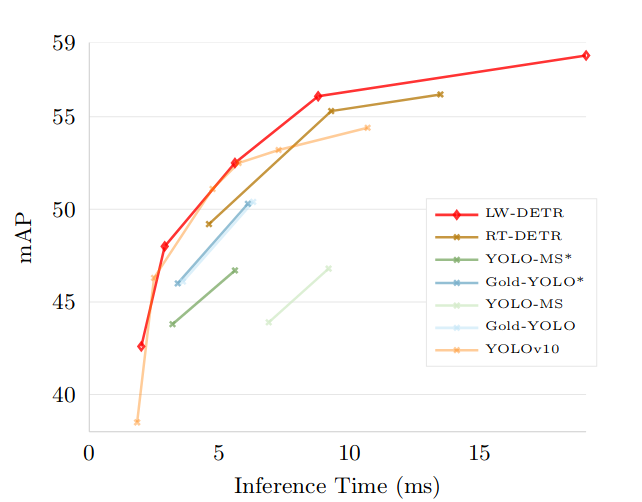
图1显示,所提出的简单基线在COCO上的性能出乎意料地优于以前的实时检测器,例如,YOLO-NAS,YOLOv8和RTMDet 。
在本文中,构建了一个轻量级的DETR方法用于实时目标检测。提出将编码器中的多级特征图、中间特征图和最终特征图进行聚合,形成更强的编码特征图。本文方法利用了有效的训练技术。例如,使用可变形的交叉注意力形成解码器,IoU感知的分类损失,以及编码器-解码器预训练策略。
另一方面,本文方法采用了推理高效的技术。例如,采用交错窗口和全局注意力,将普通ViT编码器中的部分全局注意力替换为窗口注意力,以降低复杂度。通过窗口为主的特征图组织方法对交错注意力进行了有效的实现,有效地减少了代价高昂的内存置换操作。
为了与现有的实时检测算法进行比较,进行了大量的实验。进一步优化了NMS设置,并获得了对现有算法的改进性能。所提出的基线仍然优于这些算法。此外,在更多的检测基准上展示了所提方法的实验结果。
所提出的基线仅仅探索了简单且易于实现的技术,并显示出良好的性能。本文方法可能会从其他设计中受益,例如有效的多尺度特征融合,令牌稀疏化,蒸馏,以及其他训练技术,例如YOLO - NAS中使用的技术。还表明,所提出的方法适用于使用卷积编码器的DETR方法,如ResNet - 18和ResNet - 50,并取得了良好的性能。
2 Related Work
实时目标检测。实时目标检测在现实世界中有着广泛的应用。现有的最先进的实时检测器,如YOLO - NAS ,YOLOv8和RTMDet ,通过检测框架,架构设计,数据增强,训练技术和损失函数,与第一版YOLO 相比有了很大的改进。这些检测器是基于卷积的。在本文中,研究了基于变换器的实时检测解决方案,该方案仍然很少被探索。
用于目标检测的ViT。Vision Transformer ( ViT )在图像分类中表现出良好的性能。将ViT应用于目标检测时,通常使用窗口注意力机制或分层结构来减少内存和计算开销。UVi T 采用渐进窗口注意力。ViTDet实现了具有交错窗口和全局注意力的预训练普通ViT。本文方法沿用ViTDet使用交错窗口和全局注意力,并额外使用窗口-主序特征图组织来减少内存置换开销。
DETR及其变体。 检测Transformer (DETR) 是一种端到端检测方法,消除了许多手工制作组件的必要性,例如 Anchor 点生成和非极大值抑制(NMS)。有许多后续方法用于改进DETR,如架构设计,目标 Query 设计,训练技术和损失函数改进。此外,还通过架构设计,计算优化,剪枝和蒸馏进行了各种工作以降低计算复杂性。本文的兴趣在于构建一个简单的DETR Baseline ,用于实时检测,这些方法尚未探索。
与作者的工作同时,RT-DETR也应用了DETR框架构建实时检测器,重点关注形成编码器的CNN Backbone 网络。有关相对较大的模型的研究较多,而小型模型的研究不足。作者的LW-DETR探讨了普通ViT Backbone 网络和DETR框架用于实时检测的可行性。
3 LW-DETR
3.1 Architecture
LW - DETR由ViT编码器、投影仪和DETR解码器组成。
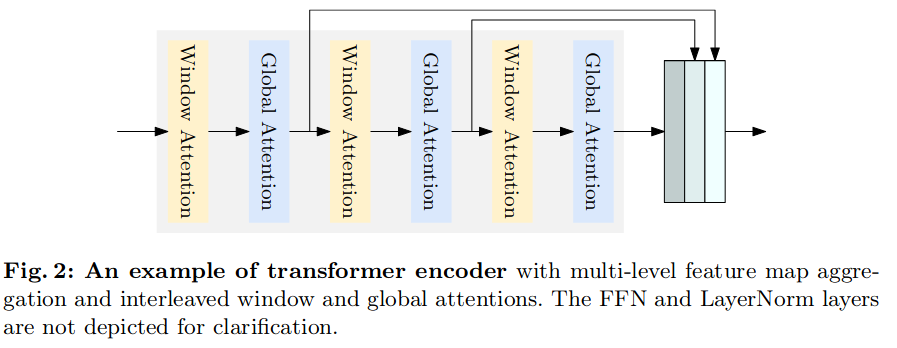
编码器。采用ViT作为检测编码器。普通ViT由切块层和Transformer编码器层组成。初始ViT中的一个Transformer编码器层包含一个覆盖所有标记的全局自注意力层和一个FFN层。全局自注意力的计算成本很高,其时间复杂度是标记( patch )数量的二次方。为了降低计算复杂度,实现了一些窗口自注意力的Transformer编码器层。
如下图图2为具有多级特征图聚合和交错窗口及全局注意力的变换器编码器示例。这里不对FFN和LayerNorm图层进行说明。图2展示了一个编码器的例子。
解码器。解码器为Transformer解码层的堆叠。每层由一个自注意力、一个交叉注意力和一个FFN组成。为了提高计算效率,采用了可变形的交叉注意力机制。DETR及其变体通常采用6个解码器层。在实现中,使用了3个Transformer解码层。这导致时间从1.4 ms减少到0.7 ms,这与本文方法中微小版本的剩余部分的时间成本1.3 ms相比是显著的。采用了一种混合查询选择方案,将对象查询作为内容查询和空间查询的补充。内容查询是可学习的嵌入,类似于DETR。空间查询基于两阶段方案:从Projector中最后一层中选择top - K个特征,预测边界框,并将对应的框转换为嵌入作为空间Query 。
投影仪。使用一个投影仪来连接编码器和解码器。投影仪将来自编码器的聚合编码特征图作为输入。该投影器是一个C2f块(跨阶段部分Dense Net的扩展),在YOLOv8中实现。
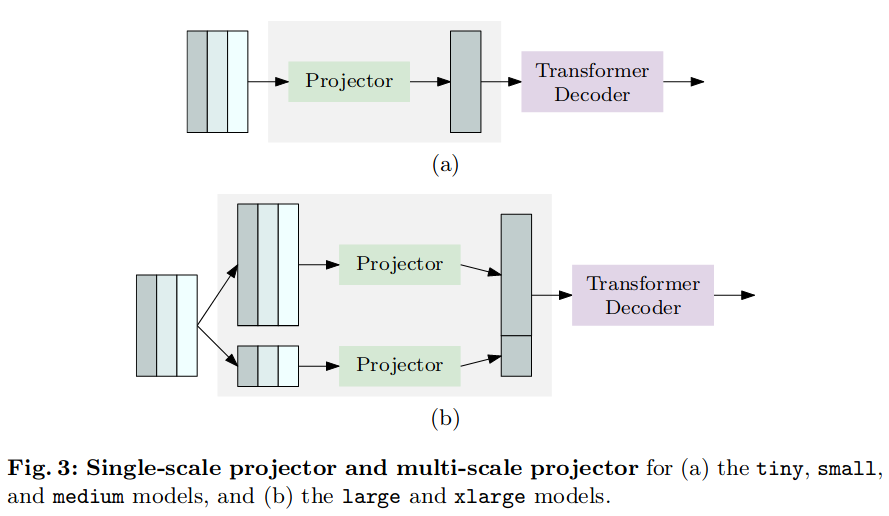
在构建LW - DETR的大型和x型版本时,修改投影仪以输出两个尺度![]() 的特征图,并相应地使用多尺度解码器。该投影仪包含两个平行的C2f块。其中一个处理通过反卷积对输入进行上采样得到的
的特征图,并相应地使用多尺度解码器。该投影仪包含两个平行的C2f块。其中一个处理通过反卷积对输入进行上采样得到的![]() 特征图,另一个处理通过跨步卷积对输入进行下采样得到的
特征图,另一个处理通过跨步卷积对输入进行下采样得到的![]() 特征图。图3展示了单尺度投影仪和多尺度投影仪的流水线。如下图所示。
特征图。图3展示了单尺度投影仪和多尺度投影仪的流水线。如下图所示。
目标函数。我们采用了一种IoU感知的分类损失,IA - BCE损失。

3.2 Instantiation
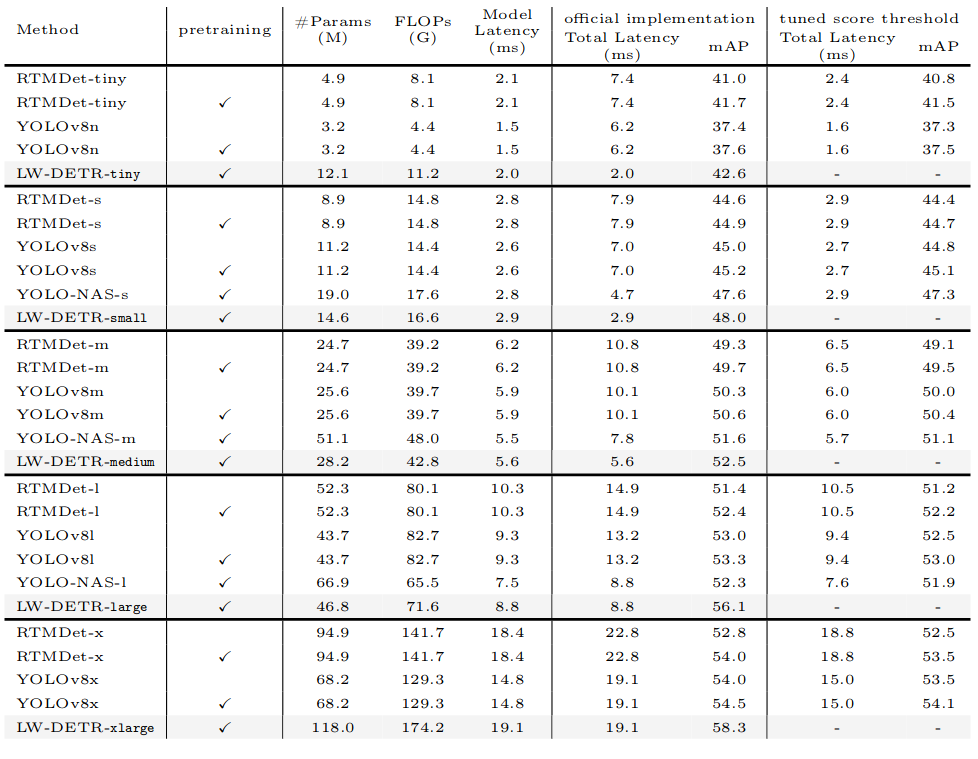
实例化了5个实时检测器:tiny、small、medium、large和x large。详细设置见表1。
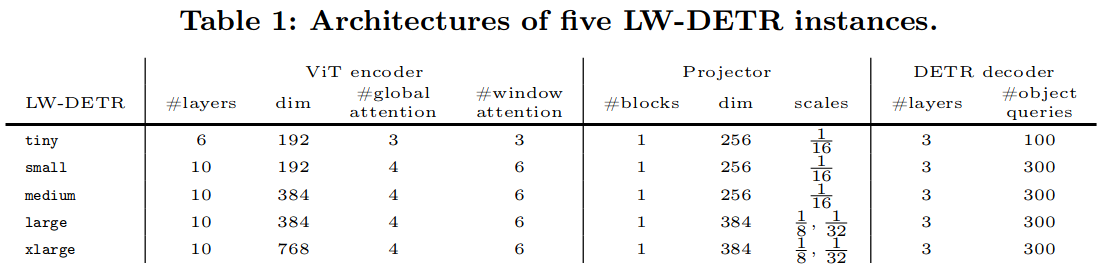
微型检测器由6层的Transformer 编码器组成。每层由多头自注意力模块和前馈网络( FFN )组成。每个图像块被线性映射为192维的表示向量。投影仪输出256通道的单尺度特征图。解码器有100个对象目标Query。
小型检测器包含10个编码器层,300个目标查询。与微型检测器相同,投影仪的输入块表示的维度和输出块的维度分别为192和256。中等检测器与小检测器类似,不同之处在于输入块的维数为384,相应地编码器的维数为384。
大型检测器由10层编码器组成,使用两个尺度的特征图。输入块表示和投影仪输出的维度分别为384和384。x large检测器与large类似,不同之处在于输入块表示的维度为768。
3.3 Effective Training
更多的监督。已经开发了各种技术来引入更多的监督,以加速DETR的训练。采用易于实现且不改变推理过程的Group DETR[ 6 ]。根据文献,使用13个并行的权重共享解码器进行训练。对于每个解码器,从投影仪的输出特征中生成每个组的对象查询。遵循[ 6 ],使用初级解码器进行推理。在Objects365上进行预训练。预训练过程包括两个阶段。首先,在数据集Objects365上使用基于预训练模型的MIM方法CAEv2 [ 71 ]对ViT进行预训练。这导致COCO上有0.7 mAP的增益。
其次,遵循[ 7,67]重新训练编码器,并以监督的方式在Objects365上训练投影仪和解码器。
3.4 Efficient Inference
采用了交错窗口和全局注意力:用窗口自注意力层替换了一些全局自注意力层。例如,在一个6层的ViT中,第一,第三和第五层是用窗口注意力来实现的。窗口注意力是通过将特征图分割成互不重叠的窗口,并在每个窗口上分别执行自注意力来实现的。
采用了一种窗口为主的特征图组织方案来进行高效的交叉注意力,该方案逐窗口组织特征图。ViTDet实现[ 36 ]中,特征图是逐行组织的(行主组织),需要进行代价高昂的置换操作,将特征图从主行过渡到窗口主组织,以获得窗口注意力。本文实现去除了这些操作,从而减少了模型延迟。
本文用一个玩具的例子来说明窗口主要的方法。给定一个4 × 4的特征图:

3.5 Empirical Study
延迟改善。ViTDet采用的交错窗口和全局注意力将计算复杂度从23.0 GFlops降低到16.6 GFlops,验证了用更便宜的窗口注意力替换昂贵的全局注意力的好处。这是因为在主行特征图组织中需要额外的代价高昂的排列操作。窗口为主的特征图组织减轻了副作用,并导致较大的延迟减少0.8 ms,从3.7 ms减少到2.9 ms。
性能改进。多级特征聚合带来0.7 mAP的增益。IOU感知分类损失和更多的监督使m AP得分从34.7提高到35.4和38.4。显著的改进来自于对Objects365的预训练,达到了8.7 m AP,说明转换器确实从大数据中获益。更长的训练计划可以给出进一步的改进,形成LW - DETR - small模型。
4 Experiments
作者在表3中报告了五个LW-DETR模型的结果。LW-DETR-tiny在T4 GPU上以500 FPS的速度达到42.6 mAP。LW-DETR-small和LW-DETR-medium分别以超过340 FPS和超过178 FPS的速度获得48.0 mAP和52.5 mAP。大型和超大型模型分别以113 FPS和52 FPS的速度达到56.1 mAP和58.3 mAP。
5 Limitation and future works
目前,仅展示了LW - DETR在实时检测中的有效性。这是第一步。扩展LW - DETR用于开放世界检测,并将LW - DETR应用于更多的视觉任务,如多人姿态估计和多视角3D目标检测,需要更多的研究。把这些留给以后的工作。
6 Conclusion
本文研究表明,与现有的实时检测器相比,检测Transformer取得了有竞争力甚至更优越的结果。方法简单高效。该方法的成功源于多层次的特征聚合和高效的训练和推理技术。希望本文的经验可以为在视觉任务中使用Transformer构建实时模型提供见解。
说明:本文内容仅用于学习,如有侵权,请联系作者删除。
至此,本文分享的内容就结束啦! 遇见便是缘,感恩遇见 !!!💛 💙 💜 ❤️ 💚 💛 💙 💜 ❤️ 💚



















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











