







【目标检测】
[2024 遥感目标检测] RSNet: A Light Framework for The Detection of Multi-scale Remote Sensing Targets
机构:上海海事大学
论文链接:https://arxiv.org/pdf/2410.23073v1
代码链接:无
最近在合成孔径雷达(SAR)船只检测领域的发展,深度学习技术在准确性和速度方面取得了显著进展。然而,在复杂背景下检测小型目标仍然是一个重大挑战。为了应对这些困难,本文提出了RSNet,这是一个旨在增强SAR图像中船只检测能力的轻量级框架。RSNet采用了Waveletpool-ContextGuided (WCG) 主干网络,以提高准确性并减少参数数量,同时还采用了Waveletpool-StarFusion (WSF) 头部网络以高效减少参数。此外,一个轻量共享(LS)模块最小化了检测头部的参数负载。在SAR船只检测数据集(SSDD)和高分辨率SAR图像数据集(HRSID)上的实验表明,RSNet在轻量设计和检测性能之间实现了良好的平衡,超越了许多最先进的检测器,在SSDD和HRSID上分别达到了72.5%和67.6%的AP50:95,且仅使用了1.49M个参数。



实验结果

【Transformer】
[2024 稀疏自注意力] SeerAttention: Learning Intrinsic Sparse Attention in Your LLMs
机构:微软
论文链接:https://arxiv.org/pdf/2410.13276
代码链接:https://github.com/microsoft/SeerAttention
注意力机制是现代大型语言模型(LLMs)的基石。然而,其二次复杂度限制了LLMs的效率和可扩展性,特别是对于具有长上下文窗口的模型。一个有前景的方法是利用注意力的稀疏性来解决这个限制。然而,现有的基于稀疏性的方案主要依赖于预定义的模式或启发式方法来近似稀疏性。这种做法``未能充分捕捉到基于语言任务中注意力稀疏性的动态特性```。本文认为,注意力稀疏性应该是学习出来的,而不是预定义的。为此,文中设计了SeerAttention,这是一种新的注意力机制,它通过一个可学习的门控机制增强了传统的注意力机制,该门控机制能够自适应地选择注意力图中的重要块,并将其余块视为稀疏。这种块级别的稀疏性有效地平衡了准确性和加速效果。为了实现门控网络的高效学习,开发了一个定制的FlashAttention实现,该实现以最小的开销提取注意力图的块级真实值。SeerAttention不仅适用于训练后阶段,而且在长上下文微调中也表现出色。结果显示,在训练后阶段,SeerAttention显著优于最先进的静态或基于启发式的稀疏注意力方法,同时也更具通用性和灵活性,能够适应不同的上下文长度和稀疏率。当应用于YaRN的长上下文微调时,SeerAttention可以在32k上下文长度下实现90%的稀疏率,同时几乎没有困惑度损失,比FlashAttention-2快5.67倍。
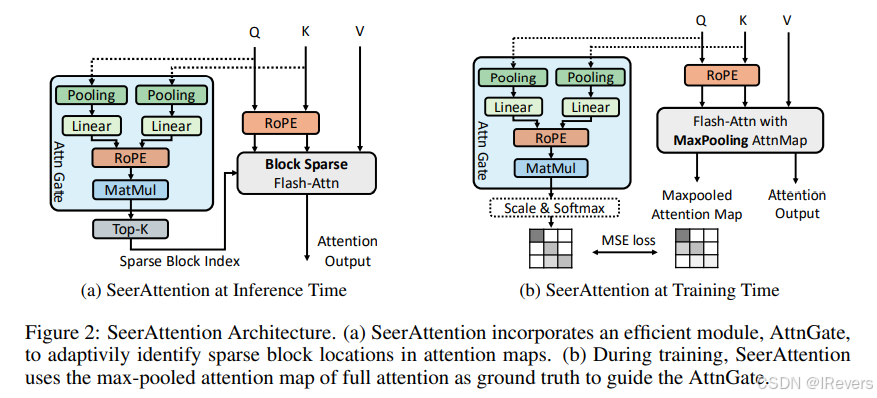
高效的FlashAttention实现

实验结果

[2024] Value Residual Learning For Alleviating Attention Concentration In Transformers
论文链接:https://arxiv.org/pdf/2410.17897
代码链接:https://github.com/Zcchill/Value-Residual-Learning
Transformers可以通过自注意力机制捕捉长距离依赖关系,使token可以直接关注所有其他token。然而,堆叠多个注意力层会导致注意力集中。解决这一问题的一个自然方法是使用跨层注意力,允许早期层的信息直接被后期层访问。然而,这种方法计算成本很高。为了解决这个问题,文中提出了带有残差值的Transformer(ResFormer),它通过添加从第一层的值到所有后续层的残差连接来近似跨层注意力。基于这种方法,其中一个变体是单层值Transformer(SVFormer),其中所有层共享来自第一层的相同值嵌入,从而将近50%减少了KV缓存。全面的实验证据表明,ResFormer减轻了深层中的注意力集中问题,并在大多数层次上增强了表示能力,在训练误差以及下游任务中优于vanilla Transformer、DenseFormer和NeuTRENO。SVFormer的训练速度显著快于vanilla Transformer,并且其表现优于GQA和CLA等其他方法,性能受到序列长度和累积学习率的影响。

实验结果




















 378
378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











