







【图像分类】2022-CMT CVPR
论文题目:CMT: Convolutional Neural Networks Meet Vision Transformers
论文链接:https://arxiv.org/abs/2107.06263
论文代码:https://github.com/ggjy/cmt.pytorch
发表时间:2021年7月
引用:Guo J, Han K, Wu H, et al. Cmt: Convolutional neural networks meet vision transformers[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 12175-12185.
引用数:67
1. 简介
1.1 摘要
Vision Transformer 已成功应用于图像识别任务,因为它们能够捕获图像中的远程依赖关系。然而,Transformer 和现有的卷积神经网络 (CNN) 在性能和计算成本上仍然存在差距。在本文中,我们的目标是解决这个问题并开发一个网络,该网络不仅可以胜过传统的 Transformer,还可以胜过高性能卷积模型。
我们提出了一种新的基于 Transformer 的混合网络,利用变压器来捕获远程依赖关系,并利用 CNN 对局部特征进行建模。此外,我们对其进行缩放以获得一系列模型,称为 CMT,与以前的基于卷积和 Transformer 的模型相比,获得了更好的准确性和效率。
特别是,我们的 CMT-S 在 ImageNet 上实现了 83.5% 的 top-1 准确率,而在 FLOP 上分别比现有的 DeiT 和 EfficientNet 小 14 倍和 2 倍。所提出的 CMT-S 在 CIFAR10 (99.2%)、CIFAR100 (91.7%)、Flowers (98.7%) 和其他具有挑战性的视觉数据集如 COCO (44.3% mAP) 上也能很好地推广,而且计算成本要低得多。
2. 网络
2.1 整体架构
- 首先,输入 Image 进入 CMT Stem,CMT Stem 架构是一个 3×3 卷积、步幅为 2 和一个输出通道为 32 的茎架构来减小输入图像的大小,后接的是另外两个步幅为 1 的 3×3 卷积以获得更好的局部 信息
- 然后, 2 ∗ 2 2*2 2∗2 Conv stride=2 接 CMT Block*3,重复 4 次后 + 全局平均池化 + 全连接 + softmax 的1000 路分类
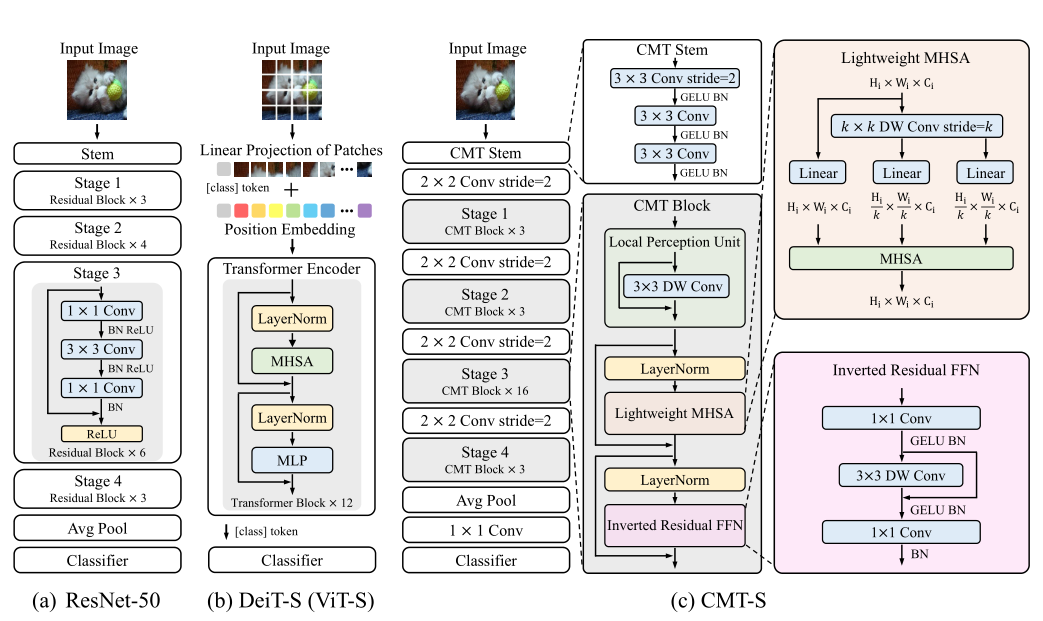
2.2 CMT Block
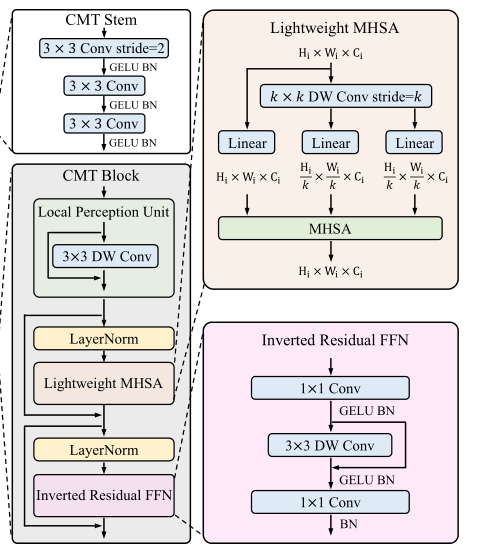
2.3 Lightweight Multi-head Self-attention
原始的self-attention模块中,输入 X 被线性变换为 query、key、value 再进行计算,运算成本高
此模块主要功能就是使用深度卷积计算代替了 key 和 value 的计算,从而减轻了计算开销,具体计算过程,可以看一下原文进行参考
LightAttn
(
Q
,
K
,
V
)
=
Softmax
(
Q
K
′
T
d
k
+
B
)
V
′
\operatorname{LightAttn}(\mathbf{Q}, \mathbf{K}, \mathbf{V})=\operatorname{Softmax}\left(\frac{\mathbf{Q} \mathbf{K}^{\prime T}}{\sqrt{d_{k}}}+\mathbf{B}\right) \mathbf{V}^{\prime}
LightAttn(Q,K,V)=Softmax(dkQK′T+B)V′
3. 代码
# 2022.06.28-Changed for building CMT
# Huawei Technologies Co., Ltd. <foss@huawei.com>
# Author: Jianyuan Guo (jyguo@pku.edu.cn)
import math
import logging
from functools import partial
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.helpers import load_pretrained
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.resnet import resnet26d, resnet50d
from timm.models.registry import register_model
_logger = logging.getLogger(__name__)
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
# A memory-efficient implementation of Swish function
class SwishImplementation(torch.autograd.Function):
@staticmethod
def forward(ctx, i):
result = i * torch.sigmoid(i)
ctx.save_for_backward(i)
return result
@staticmethod
def backward(ctx, grad_output):
i = ctx.saved_tensors[0]
sigmoid_i = torch.sigmoid(i)
return grad_output * (sigmoid_i * (1 + i * (1 - sigmoid_i)))
class MemoryEfficientSwish(nn.Module):
def forward(self, x):
return SwishImplementation.apply(x)
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.conv1 = nn.Sequential(
nn.Conv2d(in_features, hidden_features, 1, 1, 0, bias=True),
nn.GELU(),
nn.BatchNorm2d(hidden_features, eps=1e-5),
)
self.proj = nn.Conv2d(hidden_features, hidden_features, 3, 1, 1, groups=hidden_features)
self.proj_act = nn.GELU()
self.proj_bn = nn.BatchNorm2d(hidden_features, eps=1e-5)
self.conv2 = nn.Sequential(
nn.Conv2d(hidden_features, out_features, 1, 1, 0, bias=True),
nn.BatchNorm2d(out_features, eps=1e-5),
)
self.drop = nn.Dropout(drop)
def forward(self, x, H, W):
B, N, C = x.shape
x = x.permute(0, 2, 1).reshape(B, C, H, W)
x = self.conv1(x)
x = self.drop(x)
x = self.proj(x) + x
x = self.proj_act(x)
x = self.proj_bn(x)
x = self.conv2(x)
x = x.flatten(2).permute(0, 2, 1)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None,
attn_drop=0., proj_drop=0., qk_ratio=1, sr_ratio=1):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qk_dim = dim // qk_ratio
self.q = nn.Linear(dim, self.qk_dim, bias=qkv_bias)
self.k = nn.Linear(dim, self.qk_dim, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
# Exactly same as PVTv1
if self.sr_ratio > 1:
self.sr = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio, groups=dim, bias=True),
nn.BatchNorm2d(dim, eps=1e-5),
)
def forward(self, x, H, W, relative_pos):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, self.qk_dim // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
k = self.k(x_).reshape(B, -1, self.num_heads, self.qk_dim // self.num_heads).permute(0, 2, 1, 3)
v = self.v(x_).reshape(B, -1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
else:
k = self.k(x).reshape(B, N, self.num_heads, self.qk_dim // self.num_heads).permute(0, 2, 1, 3)
v = self.v(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
attn = (q @ k.transpose(-2, -1)) * self.scale + relative_pos
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, qk_ratio=1, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, qk_ratio=qk_ratio, sr_ratio=sr_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.proj = nn.Conv2d(dim, dim, 3, 1, 1, groups=dim)
def forward(self, x, H, W, relative_pos):
B, N, C = x.shape
cnn_feat = x.permute(0, 2, 1).reshape(B, C, H, W)
x = self.proj(cnn_feat) + cnn_feat
x = x.flatten(2).permute(0, 2, 1)
x = x + self.drop_path(self.attn(self.norm1(x), H, W, relative_pos))
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
f"img_size {img_size} should be divided by patch_size {patch_size}."
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1]
return x, (H, W)
class CMT(nn.Module):
def __init__(self, img_size=224, in_chans=3, num_classes=1000, embed_dims=[46, 92, 184, 368], stem_channel=16,
fc_dim=1280,
num_heads=[1, 2, 4, 8], mlp_ratios=[3.6, 3.6, 3.6, 3.6], qkv_bias=True, qk_scale=None,
representation_size=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., hybrid_backbone=None, norm_layer=None,
depths=[2, 2, 10, 2], qk_ratio=1, sr_ratios=[8, 4, 2, 1], dp=0.1):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dims[-1]
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
self.stem_conv1 = nn.Conv2d(3, stem_channel, kernel_size=3, stride=2, padding=1, bias=True)
self.stem_relu1 = nn.GELU()
self.stem_norm1 = nn.BatchNorm2d(stem_channel, eps=1e-5)
self.stem_conv2 = nn.Conv2d(stem_channel, stem_channel, kernel_size=3, stride=1, padding=1, bias=True)
self.stem_relu2 = nn.GELU()
self.stem_norm2 = nn.BatchNorm2d(stem_channel, eps=1e-5)
self.stem_conv3 = nn.Conv2d(stem_channel, stem_channel, kernel_size=3, stride=1, padding=1, bias=True)
self.stem_relu3 = nn.GELU()
self.stem_norm3 = nn.BatchNorm2d(stem_channel, eps=1e-5)
self.patch_embed_a = PatchEmbed(
img_size=img_size // 2, patch_size=2, in_chans=stem_channel, embed_dim=embed_dims[0])
self.patch_embed_b = PatchEmbed(
img_size=img_size // 4, patch_size=2, in_chans=embed_dims[0], embed_dim=embed_dims[1])
self.patch_embed_c = PatchEmbed(
img_size=img_size // 8, patch_size=2, in_chans=embed_dims[1], embed_dim=embed_dims[2])
self.patch_embed_d = PatchEmbed(
img_size=img_size // 16, patch_size=2, in_chans=embed_dims[2], embed_dim=embed_dims[3])
self.relative_pos_a = nn.Parameter(torch.randn(
num_heads[0], self.patch_embed_a.num_patches,
self.patch_embed_a.num_patches // sr_ratios[0] // sr_ratios[0]))
self.relative_pos_b = nn.Parameter(torch.randn(
num_heads[1], self.patch_embed_b.num_patches,
self.patch_embed_b.num_patches // sr_ratios[1] // sr_ratios[1]))
self.relative_pos_c = nn.Parameter(torch.randn(
num_heads[2], self.patch_embed_c.num_patches,
self.patch_embed_c.num_patches // sr_ratios[2] // sr_ratios[2]))
self.relative_pos_d = nn.Parameter(torch.randn(
num_heads[3], self.patch_embed_d.num_patches,
self.patch_embed_d.num_patches // sr_ratios[3] // sr_ratios[3]))
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
self.blocks_a = nn.ModuleList([
Block(
dim=embed_dims[0], num_heads=num_heads[0], mlp_ratio=mlp_ratios[0], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i],
norm_layer=norm_layer, qk_ratio=qk_ratio, sr_ratio=sr_ratios[0])
for i in range(depths[0])])
cur += depths[0]
self.blocks_b = nn.ModuleList([
Block(
dim=embed_dims[1], num_heads=num_heads[1], mlp_ratio=mlp_ratios[1], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i],
norm_layer=norm_layer, qk_ratio=qk_ratio, sr_ratio=sr_ratios[1])
for i in range(depths[1])])
cur += depths[1]
self.blocks_c = nn.ModuleList([
Block(
dim=embed_dims[2], num_heads=num_heads[2], mlp_ratio=mlp_ratios[2], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i],
norm_layer=norm_layer, qk_ratio=qk_ratio, sr_ratio=sr_ratios[2])
for i in range(depths[2])])
cur += depths[2]
self.blocks_d = nn.ModuleList([
Block(
dim=embed_dims[3], num_heads=num_heads[3], mlp_ratio=mlp_ratios[3], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i],
norm_layer=norm_layer, qk_ratio=qk_ratio, sr_ratio=sr_ratios[3])
for i in range(depths[3])])
# Representation layer
if representation_size:
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
('fc', nn.Linear(self.embed_dim, representation_size)),
('act', nn.Tanh())
]))
else:
self.pre_logits = nn.Identity()
# Classifier head
self._fc = nn.Conv2d(embed_dims[-1], fc_dim, kernel_size=1)
self._bn = nn.BatchNorm2d(fc_dim, eps=1e-5)
self._swish = MemoryEfficientSwish()
self._avg_pooling = nn.AdaptiveAvgPool2d(1)
self._drop = nn.Dropout(dp)
self.head = nn.Linear(fc_dim, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if isinstance(m, nn.Conv2d) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def update_temperature(self):
for m in self.modules():
if isinstance(m, Attention):
m.update_temperature()
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
x = self.stem_conv1(x)
x = self.stem_relu1(x)
x = self.stem_norm1(x)
x = self.stem_conv2(x)
x = self.stem_relu2(x)
x = self.stem_norm2(x)
x = self.stem_conv3(x)
x = self.stem_relu3(x)
x = self.stem_norm3(x)
x, (H, W) = self.patch_embed_a(x)
for i, blk in enumerate(self.blocks_a):
x = blk(x, H, W, self.relative_pos_a)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x, (H, W) = self.patch_embed_b(x)
for i, blk in enumerate(self.blocks_b):
x = blk(x, H, W, self.relative_pos_b)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x, (H, W) = self.patch_embed_c(x)
for i, blk in enumerate(self.blocks_c):
x = blk(x, H, W, self.relative_pos_c)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x, (H, W) = self.patch_embed_d(x)
for i, blk in enumerate(self.blocks_d):
x = blk(x, H, W, self.relative_pos_d)
B, N, C = x.shape
x = self._fc(x.permute(0, 2, 1).reshape(B, C, H, W))
x = self._bn(x)
x = self._swish(x)
x = self._avg_pooling(x).flatten(start_dim=1)
x = self._drop(x)
x = self.pre_logits(x)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def resize_pos_embed(posemb, posemb_new):
# Rescale the grid of position embeddings when loading from state_dict. Adapted from
# https://github.com/google-research/vision_transformer/blob/00883dd691c63a6830751563748663526e811cee/vit_jax/checkpoint.py#L224
_logger.info('Resized position embedding: %s to %s', posemb.shape, posemb_new.shape)
ntok_new = posemb_new.shape[1]
if True:
posemb_tok, posemb_grid = posemb[:, :1], posemb[0, 1:]
ntok_new -= 1
else:
posemb_tok, posemb_grid = posemb[:, :0], posemb[0]
gs_old = int(math.sqrt(len(posemb_grid)))
gs_new = int(math.sqrt(ntok_new))
_logger.info('Position embedding grid-size from %s to %s', gs_old, gs_new)
posemb_grid = posemb_grid.reshape(1, gs_old, gs_old, -1).permute(0, 3, 1, 2)
posemb_grid = F.interpolate(posemb_grid, size=(gs_new, gs_new), mode='bilinear')
posemb_grid = posemb_grid.permute(0, 2, 3, 1).reshape(1, gs_new * gs_new, -1)
posemb = torch.cat([posemb_tok, posemb_grid], dim=1)
return posemb
def checkpoint_filter_fn(state_dict, model):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
if 'model' in state_dict:
# For deit models
state_dict = state_dict['model']
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k and len(v.shape) < 4:
# For old models that I trained prior to conv based patchification
O, I, H, W = model.patch_embed.proj.weight.shape
v = v.reshape(O, -1, H, W)
elif k == 'pos_embed' and v.shape != model.pos_embed.shape:
# To resize pos embedding when using model at different size from pretrained weights
v = resize_pos_embed(v, model.pos_embed)
out_dict[k] = v
return out_dict
def _create_cmt_model(pretrained=False, distilled=False, **kwargs):
default_cfg = _cfg()
default_num_classes = default_cfg['num_classes']
default_img_size = default_cfg['input_size'][-1]
num_classes = kwargs.pop('num_classes', default_num_classes)
img_size = kwargs.pop('img_size', default_img_size)
repr_size = kwargs.pop('representation_size', None)
if repr_size is not None and num_classes != default_num_classes:
# Remove representation layer if fine-tuning. This may not always be the desired action,
# but I feel better than doing nothing by default for fine-tuning. Perhaps a better interface?
_logger.warning("Removing representation layer for fine-tuning.")
repr_size = None
model = CMT(img_size=img_size, num_classes=num_classes, representation_size=repr_size, **kwargs)
model.default_cfg = default_cfg
if pretrained:
load_pretrained(
model, num_classes=num_classes, in_chans=kwargs.get('in_chans', 3),
filter_fn=partial(checkpoint_filter_fn, model=model))
return model
@register_model
def cmt_ti(pretrained=False, **kwargs):
"""
CMT-Tiny
"""
model_kwargs = dict(qkv_bias=True, **kwargs)
model = _create_cmt_model(pretrained=pretrained, **model_kwargs)
return model
@register_model
def cmt_xs(pretrained=False, **kwargs):
"""
CMT-XS: dim x 0.9, depth x 0.8, input 192
"""
model_kwargs = dict(
qkv_bias=True, embed_dims=[52, 104, 208, 416], stem_channel=16, num_heads=[1, 2, 4, 8],
depths=[3, 3, 12, 3], mlp_ratios=[3.77, 3.77, 3.77, 3.77], qk_ratio=1, sr_ratios=[8, 4, 2, 1], **kwargs)
model = _create_cmt_model(pretrained=pretrained, **model_kwargs)
return model
@register_model
def cmt_s(pretrained=False, **kwargs):
"""
CMT-Small
"""
model_kwargs = dict(
qkv_bias=True, embed_dims=[64, 128, 256, 512], stem_channel=32, num_heads=[1, 2, 4, 8],
depths=[3, 3, 16, 3], mlp_ratios=[4, 4, 4, 4], qk_ratio=1, sr_ratios=[8, 4, 2, 1], **kwargs)
model = _create_cmt_model(pretrained=pretrained, **model_kwargs)
return model
@register_model
def cmt_b(pretrained=False, **kwargs):
"""
CMT-Base
"""
model_kwargs = dict(
qkv_bias=True, embed_dims=[76, 152, 304, 608], stem_channel=38, num_heads=[1, 2, 4, 8],
depths=[4, 4, 20, 4], mlp_ratios=[4, 4, 4, 4], qk_ratio=1, sr_ratios=[8, 4, 2, 1], dp=0.3, **kwargs)
model = _create_cmt_model(pretrained=pretrained, **model_kwargs)
return model
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
model=cmt_ti(num_classes=10)
y=model(x)
print(y.shape)
参考资料

















 182
182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









