






论文名称:Taming Transformers for High-Resolution Image Synthesis
发表时间:CVPR2021
作者及组织: Patrick Esser*, Robin Rombach*, Bjorn Ommer, 来自Heidelberg Collaboratory for Image Processing, IWR, Heidelberg University, Germany。
前言
本文类似VQVAE,区别在于引入了GAN的思想来强制codebook学到更逼真的图像成分表示,另外,自回归模型替换成了长序建模更强的Transformer来替代PixelCNN。(在codebook上进行自回归是因为Transformer计算代价大)。
1、方法
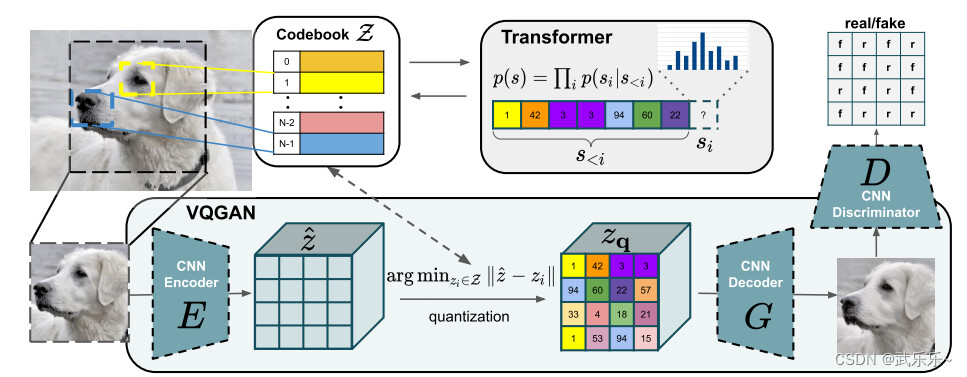
1.1.codebook学习
这块类似VQVAE,损失函数类似:
L
V
Q
(
E
,
G
,
Z
)
=
∣
∣
x
−
x
^
∣
∣
2
+
∣
∣
s
g
[
E
(
x
)
]
−
z
q
∣
∣
2
2
+
β
∣
∣
s
g
[
z
q
]
−
E
(
x
)
∣
∣
2
2
\begin{equation} L_{VQ}(E,G,Z) = ||x- \hat x||^2+||sg[E(x)] - z_q||_2^2+\beta||sg[z_q]-E(x)||_2^2 \tag{1} \end{equation}
LVQ(E,G,Z)=∣∣x−x^∣∣2+∣∣sg[E(x)]−zq∣∣22+β∣∣sg[zq]−E(x)∣∣22(1)
其中
x
^
\hat x
x^ 表示Decoder的生成图,
s
g
[
.
]
sg[.]
sg[.] 表示梯度停止,即一个重构损失和一个codebook损失。
1.2.+GAN
由于CNN会压缩图像,可能导致codebook在像素级别上质量差,于是加了一个判别器 D D D ,来判断每块特征图 r e a l / f a k e real/fake real/fake 。
L G A N ( E , G , Z , D ) = [ l o g D ( x ) + l o g ( 1 − D ( x ^ ) ) ] \begin{equation} L_{GAN}({E,G,Z}, D) = [logD(x) + log(1-D(\hat x))] \tag {2} \end{equation} LGAN(E,G,Z,D)=[logD(x)+log(1−D(x^))](2)
其中 x x x 是原始图像, x ^ \hat x x^ 是Decoder生成图。 另外,VQGAN使用了 p e r c e p t u a l l o s s perceptual\ loss perceptual loss 来替换了公式1中的重构损失。最终codebook最终损失为公式1和2的和。
1.3.自回归
在codebook训练完成后,将其置为推理阶段,然后推理图像并根据codebook得到gt索引,并用Transformer来自回归预测下一个索引。自回归损失用 一个交叉熵即可:
L
t
r
a
n
s
f
o
r
m
e
r
=
E
x
−
p
(
x
)
[
−
l
o
g
p
(
s
)
]
p
(
s
)
=
∏
i
=
1
n
p
(
s
i
∣
s
<
i
)
\begin{equation} L_{transformer} = E_{x - p(x)}[-logp(s)] \\ p(s) = \prod_{i=1}^{n}p(s_i|s<i) \end{equation}
Ltransformer=Ex−p(x)[−logp(s)]p(s)=i=1∏np(si∣s<i)
1.4.生成
在自回归模型训好后,便可让自回归模型生成有意义的索引,然后借助
D
D
D 便能生成图像。但若想生成百万像素还是有困难,因此,作者采用了一个滑动窗口生成策略:
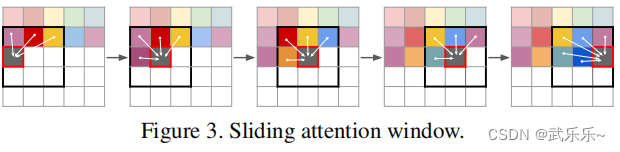
借助Transformer只能看见以前的信息的性质,便能分块生成大图。
2、效果

思考
针对不同训练任务需要训练不同的codebook+自回归,比较麻烦。

















 1983
1983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









