






最近学习了以下强化学习,想了解一下控制变量下不同强化学习策略之间的差异有多大,于是就拿gym的PongNoFrameskip-v4环境为例,分别用无探索噪音的DDQN、DeulingNet、Prioritized-DDQN和有100K退火噪音的DDQN进行对比,使用的代码来自GitHub大佬,链接如下:GitHub - XinJingHao/Deep-Reinforcement-Learning-Algorithms-with-Pytorch: Clean and robust implementations of Reinforcement Learning algorithms by Pytorch
PongNoFrameskip-v4环境游戏界面:
四种策略的训练过程如下,主要对比的是训练收敛速度。
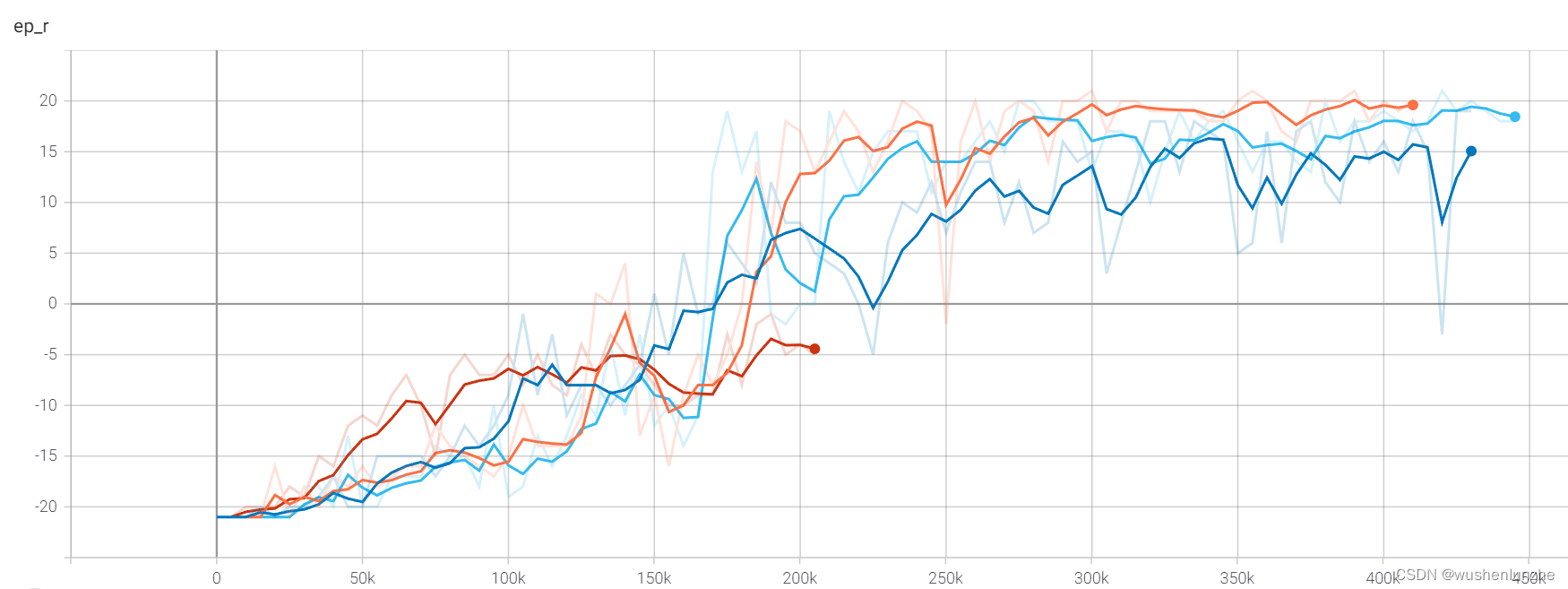
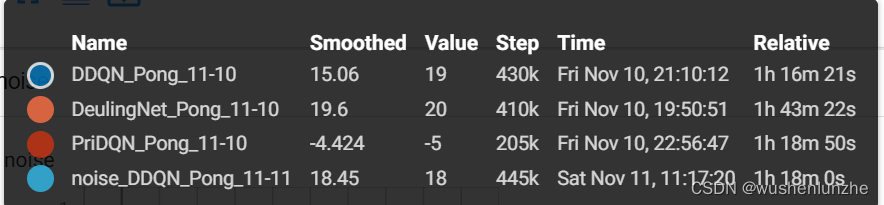
从上图可见DeulingNet貌似是效果最好的,优先经验选择的不知道为什么分数迟迟不能上去,别看它才训练到第200k来步,其实已经过去了1h18min,别的网络这时候都快收敛了。
此对比仅作参考,本人电脑比较渣,拿的1650跑的,还是个轻薄本,有条件了再买个好电脑 。但看数据的话其实训练效果大差不差,况且虽然其他变量都一致,这个游戏可能也无法充分发挥每个学习策略的优势,就比如优先经验法不知道为什么效果很差,而且还耗时,在这个实验里效果完全不能看。最后我实际渲染时发现这个游戏的对手其实比较呆的,只会跟着球跑,训练出来无一例外都是智能体在同一位置快速把球击回去,然后对方就接不到了,稍微出点意外球不是按固定路径了大概率接不到,以后有可能拿别的更合适的游戏试试,主要跑一次太耗时了。















 1473
1473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









