







目录
论文
Unsupervised Person Re-Identification With Wireless Positioning Under Weak Scene Labeling
作者:Yiheng Liu, Wengang Zhou, Qiaokang Xie, Houqiang Li
1. 动机
1.1 全场景标注
前两篇“视觉大数据+无线大数据”的模型主要基于“全场景标注”,即需要标注每个监控场景每个位置的经纬度。
其优点在于,经过坐标系映射,可以直接计算视觉轨迹与无线定位轨迹之间的距离,多模态数据关联更准确;
然而,标注监控场景的定位信息费时费力、难以维护,不适合应用于大规模监控场景。
1.2 弱场景标注
本文提出“弱场景标注”,即标注相机位置,仅需知道行人是否在相机的特定距离范围内。这种方法易于维护,可以扩展到大规模监控场景。
然而,该设定无法直接度量视觉与无线轨迹的距离,因此需要重新建立多模态数据间的关联。
2. 无监督多模态行人重识别训练框架(UMTF)
【下表列出了文中不同记号的含义】
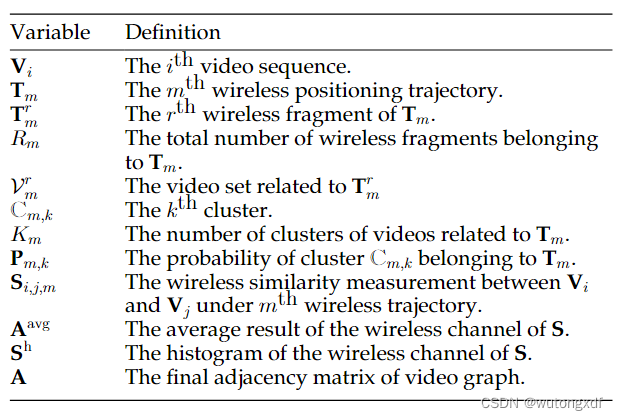
为了在“弱场景标注”下,建立多模态数据关联,作者提出无监督多模态行人重识别训练框架(UMTF),主要包括两个训练阶段:
1)CNN 视觉模型初始训练;
2)CNN 与 多模态图神经网络(MMGN)双模型交替训练。
UMTF 的输入包括:
1)由 C 个相机拍摄到的 N 个视频序列 ;
2)M 个无线信号轨迹 。
2.1 生成视觉伪标签
2.1.1 CNN 视觉模型初始训练
为了获得可用的视觉伪标签,需要先训练一个具备基本行人辨别能力的初始 CNN 模型 。
如上图所示,在初始训练阶段,作者使用了一个多分支网络结构,有一个共享的特征提取模型 以及 C 个独立的分类器(共有 C 个相机)。
会提取一个视频序列
每帧的特征,取平均值作为该视频序列的特征:
。
该阶段的 CNN 模型训练为单摄像机下的训练,每个视频序列视为一个行人类别,使用交叉熵损失训练 C 个分类器,总损失为 C 个交叉熵损失之和。
2.1.2 最近邻关联生成伪标签
视觉 CNN 模型 会提取 N 个视频序列的视觉特征,随后经过最近邻关联(NNA)得到视觉伪标签。
具体来说,处理每个视频序列时,NNA 会根据特征的余弦相似度,在其它各摄像机拍摄的视频中找到该视频序列的最近邻。如果两个视频序列(属于不同的摄像机)是彼此的最近邻,则会被分配相同的伪视觉标签(判定为属于同一人)。
【注】由于彼此为最近邻的约束条件较强,所以不是所有视频序列都被分配了伪视觉标签,作者滤除了那些未被分配标签的视频序列。
2.2 生成多模态伪标签
生成多模态伪标签的过程主要依赖于两个模块:多模态数据关联策略(multimodal data association strategy MMDA);多模态图神经网络(multimodal graph neural network MMGN)。
简单来说,多模态数据关联策略会自适应关联多模态数据,其结果被送入多模态图神经网络;多模态图神经网络融合多模态信息,得到多模态特征 Z,并经过最近邻关联得到多模态标签。
2.2.1 多模态数据关联策略(MMDA)

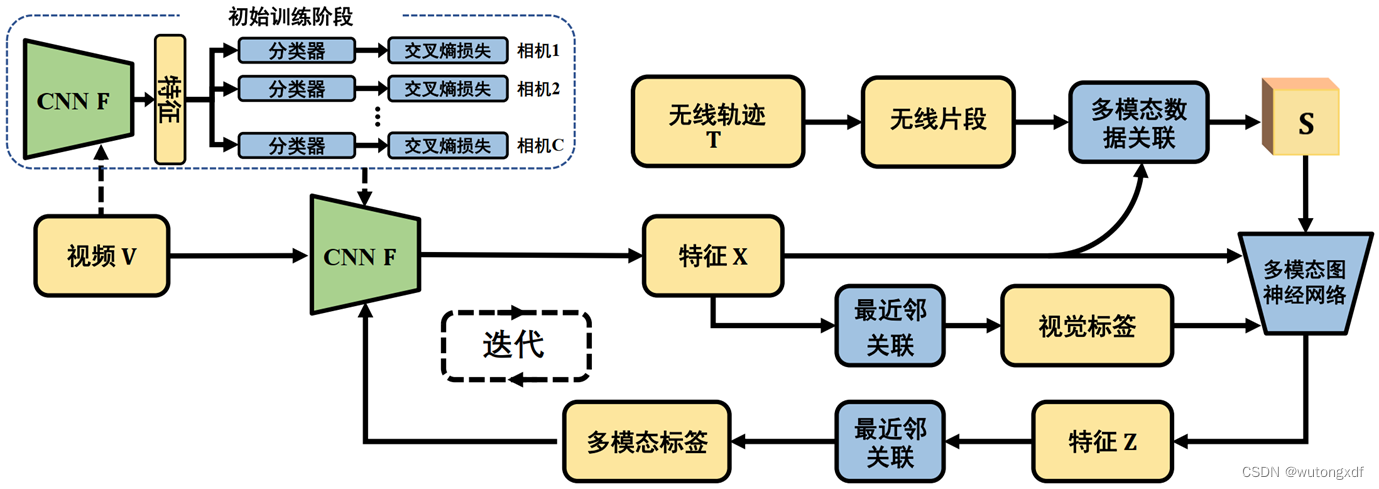
如上图所示,按照论文的设定,每个摄像头周围预设半径的圆形区域被视为无线片段感知区域。假如第 m 个无线定位轨迹 落入无线感知区域,则
第 r 个落入无线感知区域的部分被称为无线片段
。
表示无线定位轨迹
共有
个无线片段。
如上图所示的例子中,当行人经过4个监控摄像机时,有4个无线片段被感知到()。作者使用不同的标记(不同形状的框图)来表示视频序列,具有相同标记的视频序列属于同一个ID。标记中的数字是相应无线片段的序列号。
以第一个无线片段为例,在无线片段 对应的时间范围内,有5个行人的视频序列被相应的摄像机捕获,它们被表示为一个视频集
。相应的,对于无线片段
,目标行人的视频序列(红圈)被混合在视频集
中。多模态数据关联策略致力于将目标人的无线轨迹与其视频序列(红圈)正确地关联起来。
为实现上述目标,作者首先使用模型 提取视频集
中视频序列的特征,并使用 k-means 算法获得
个聚类簇
。
由于聚类所处理的视频数量可能会在一个大范围内变动,因此,作者设计了一个自适应估计聚类中心数量( 即估计 的值)的方法。
每当一个行人经过一个相机的监控区域时,都会相应地捕捉到一个视频序列和一个无线片段。因此,可以用一个无线信号轨迹平均拥有的无线片段的数量,粗略地估计一个行人拥有的视频序列的数量:。
对于第 m 个无线定位轨迹 ,与其无线片段
相关的视频集
中,共有
个视频序列,进而可以估计出视频集合中大致包含了多少个行人的视频:
。
然而,在实际情况下,由于遮挡等因素的影响,某一监控场景中行人的视频可能并不是连续的,这使得行人在该监控场景中虽然仅有单个无线片段,却可能对应了多个视频序列。这种情况下,一个人拥有的无线片段数量并不能准确反映一个人拥有的视频序列数量。此外,由于行人的行进路线不同,这也使上述估计存在偏差。
因此,作者将上述估计作为聚类中心数量的重要参考,引入比例系数 ,调节最终
的取值与上述估计值之间的比例关系:
至此,作者使用自适应聚类的方法,对视频集 (上图中
)中的视频聚类,获得
个
簇,聚类出的每个簇
代表一个行人。作者用
表示簇(行人)
经过了几个监控场景(无线信号
经过的监控场景的子集)。
随后,作者通过簇中行人经过的监控场景与无线信号经过的场景的匹配程度,衡量簇所代表的行人是目标行人的概率:。
例如,上图中的第一个簇 ,它经过了 2,3,4 这三个场景,因而
。而无线信号经过的场景是4个(
),所以
,这个簇所代表的行人与无线信号所代表的行人的轨迹不完全匹配。
【注】若某行人的无线轨迹多次经过某一监控区域,按照作者的设定,每次都会产生一个新的无线片段。
最后,作者进一步处理多模态数据关联得到的数据以用于行人重识别。
对于一个视频簇, 值越高(越接近于1),表明这个簇越有可能属于目标行人,视频簇中的视频序列也越有可能属于同一个人。因此,
也可以视为视频簇中各个视频间基于无线信号匹配得到的相似性。据此,作者定义视频序列
与视频序列
基于第 m 个无线信号轨迹得到的无线相似性(wireless similarity):
由此我们得到了一个三维的稀疏矩阵 。由于只有当视频序列
与视频序列
在一个视频簇中时,
才会有非零值,所以 S 是稀疏的。
2.2.2 多模态图神经网络(MGNN)
获得视频的特征表达即视频之间的相似性后,作者以视频序列为顶点(每个顶点表示为 的特征向量),以相似性值作为边,构建视频图。
一种构建邻接矩阵的方式,是直接将多个无线信号下得到的相似性矩阵取平均,得到 :
。
然而,当无线信号很多(M很大)时,这种方式会导致过平滑问题,且会丢失不同无线信号轨迹上无线相似性的分布信息。
由此,作者提出了多模态图神经模块(multimodal graph convolutional module MGM)。通过直方图统计的方式,将变长的无线维度 M 处理为定长 32:。在避免过平滑问题的同时,也保留了视频之间基于无线的相似度的统计信息。
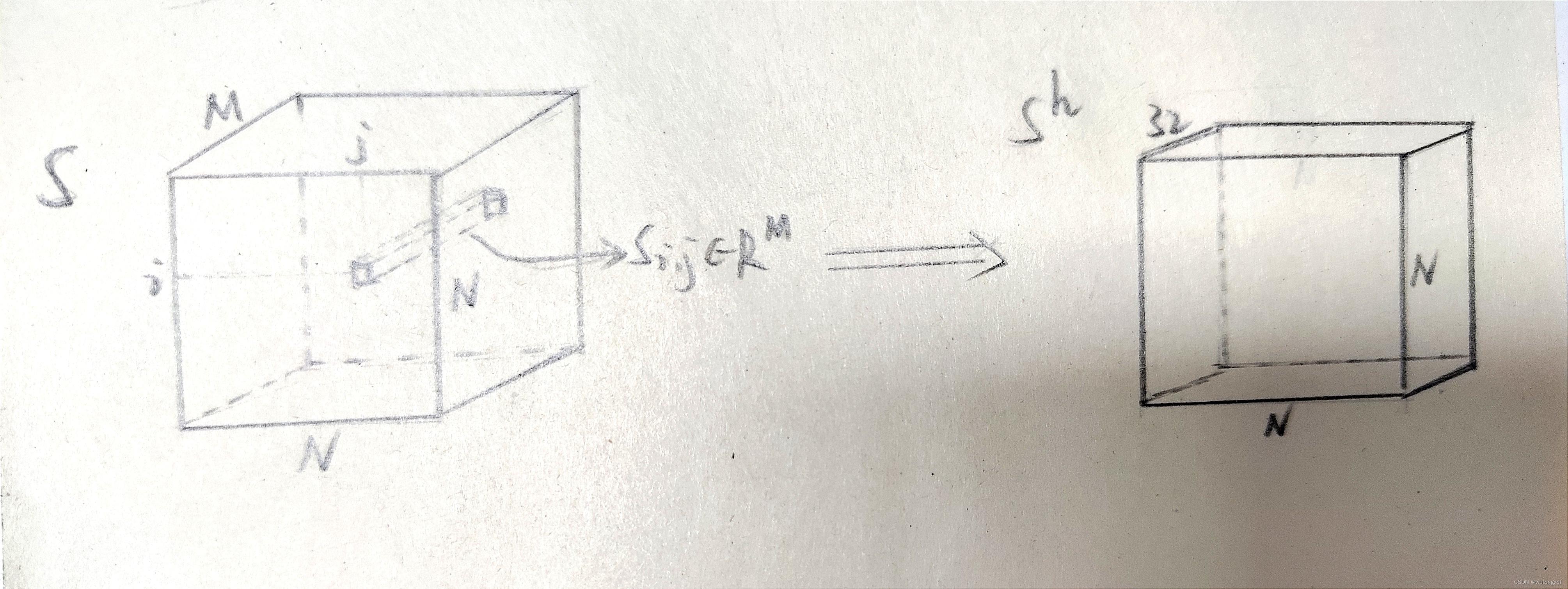
。其中,
表示将 [0, 1] 划分成32个等长区间的直方图。
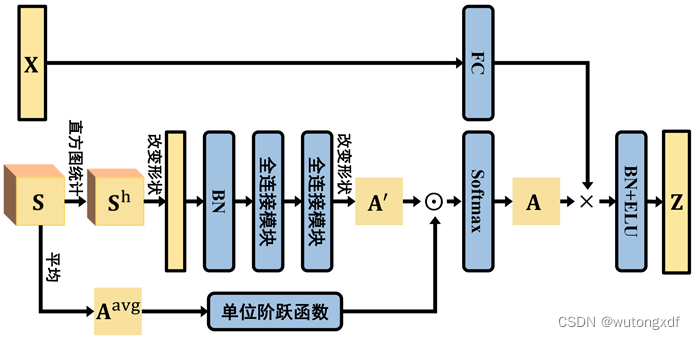
上图为一个多模态图神经模块(MGM)。如图所示, 获得 后,先将
改变形状,从
变为
的 N*N 个 32维特征向量,经过 batch normalization(BN)后输入两层全连接模块(FC block),获得
。
随后,通过下列公式计算得到邻接矩阵 :
其中, 表示按元素相乘。
表示单位阶跃函数,即
,通过计算
,滤除掉
中没有无线关联的视频序列对(即
的视频对
与
)。
将 N 个视频序列的特征矩阵 经过一个全连接层变换(
)后,与邻接矩阵 A 进行矩阵乘法计算,再经过 BN 和 exponential linear unit (ELU) 后,得到视频序列的多模态特征表示:
。
上述流程,构成了一个多模态图神经模块(MGM)。
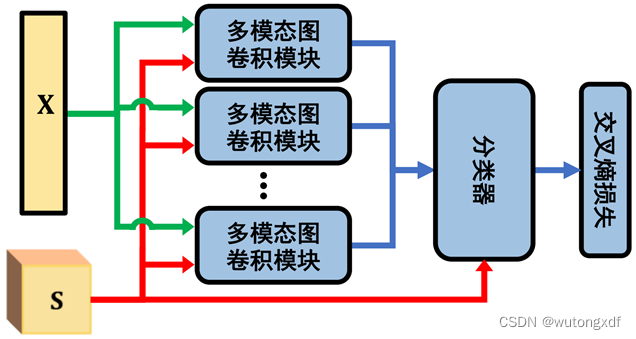
如上图,多个(6个)多模态图神经模块(MGM)叠加使用构成了最终的多模态图神经网络(MMGN)。MMGN 采用交叉熵损失,利用视觉伪标签进行训练。
【注】分类器也是一个 MGM,只不过移除了最后的 BN 和 ELU 层。
MMGN 的输入为视频序列的原始特征矩阵 ,输出为视频序列的多模态特征表示
。对 Z 进行最近邻关联(NNA),可获得多模态伪标签。
2.3 双模型交替训练
用视觉伪标签训练 MMGN,输出视频序列的多模态特征表示 Z,对 Z 进行最近邻关联,获得多模态伪标签;
用多模态伪标签训练 CNN,输出视频序列的视觉特征 X,对 X 进行最近邻关联,获得视觉伪标签。
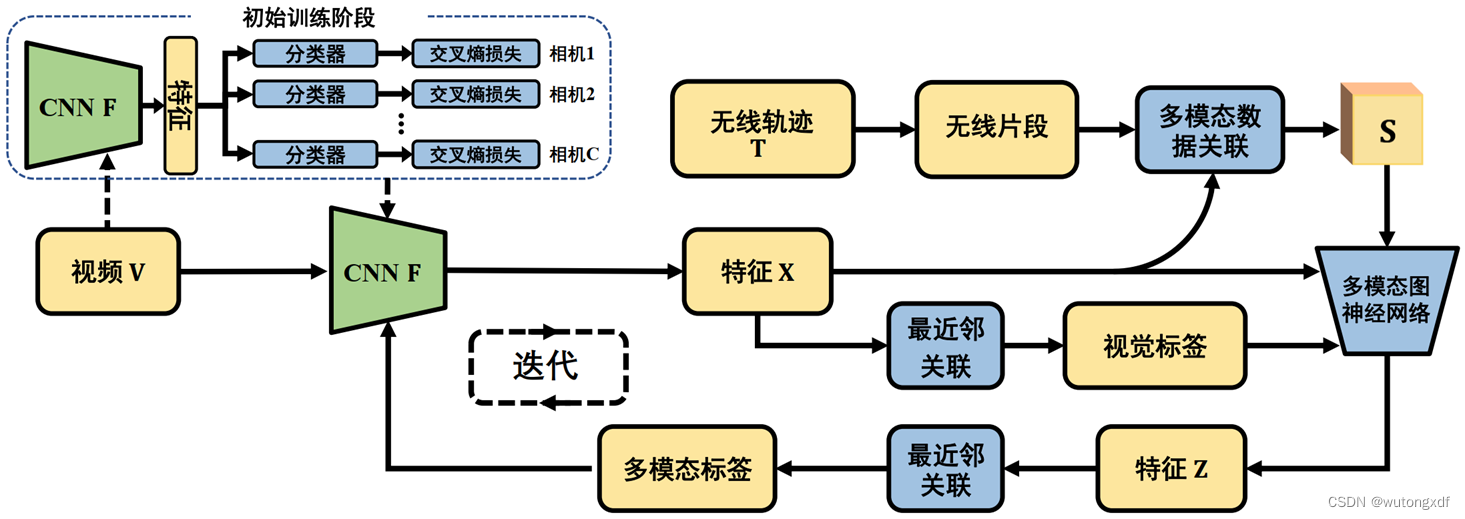
两个模型各自预测伪标签,并相互指导、共同提升,在多次迭代后达到稳定。由此,作者借助多模态数据训练出来一个更有区分力的 CNN 模型 。















 226
226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









