







self.register_buffer就是pytorch框架用来保存不更新参数的方法。
列子如下:
self.register_buffer("position_emb", torch.randn((5, 3)))
第一个参数position_emb传入一个字符串,表示这组参数的名字,第二个就是tensor形式的参数torch.randn((5, 3),并一次初始化后保存于模型,不会有梯度传播给它,能被模型的model.state_dict()记录下来,可以理解为模型的常数。当然,你想保留固定值,使用如下代码:
self.register_buffer("position_emb", torch.tensorrt([[2,5],[8,9]]))
进一步探讨训练对该参数是否有影响,答案是:没影响。具体可看下面实现的列子代码:
import torch
from torch.nn import Embedding
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.emb = Embedding(5, 3)
self.register_buffer("position_emb", torch.randn((5, 3)))
def forward(self,vec):
input = torch.tensor([0, 1, 2, 3, 4])
emb_vec1 = self.emb(input)
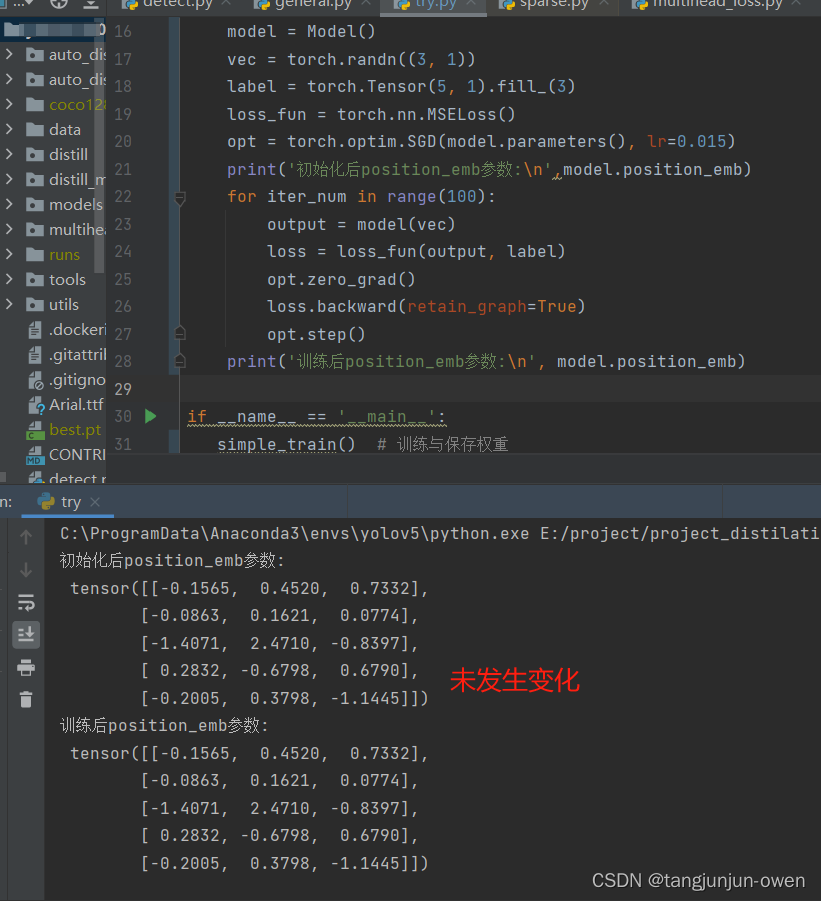
emb_vec1=emb_vec1+self.position_emb
output = torch.einsum('ik, kj -> ij', emb_vec1, vec)
return output
def simple_train():
model = Model()
vec = torch.randn((3, 1))
label = torch.Tensor(5, 1).fill_(3)
loss_fun = torch.nn.MSELoss()
opt = torch.optim.SGD(model.parameters(), lr=0.015)
print('初始化后position_emb参数:\n',model.position_emb)
for iter_num in range(100):
output = model(vec)
loss = loss_fun(output, label)
opt.zero_grad()
loss.backward(retain_graph=True)
opt.step()
print('训练后position_emb参数:\n', model.position_emb)
if __name__ == '__main__':
simple_train() # 训练与保存权重
实现结果如下:
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











