






目录
一、简介
1.背景
在现代科技中,机器学习已经成为不可或缺的一部分。从语音识别到图像分类,机器学习算法帮助我们解决了许多复杂的问题。在这些算法中,逻辑回归作为一种基础且强大的分类工具,被广泛应用于各种领域。
2.逻辑回归的概念
逻辑回归是一种用于分类问题的机器学习算法。尽管它的名字中有“回归”,但其主要目的是进行二分类预测。这意味着它可以帮助我们预测某个事件是否会发生,如邮件是否为垃圾邮件,患者是否患有某种疾病等。
逻辑回归可以笼统地理解为逻辑回归=线性回归+sigmoid函数。
Logistic回归的基本思想是通过一个特殊的函数——逻辑函数(也称为Sigmoid函数),将线性回归模型的输出转换为概率值,从而进行分类。
二、逻辑回归的原理
1.线性回归
线性模型的一般形式
其中是由d维属性描述的样本,其中
是x在第i个属性上的取值
向量形式, 其中
为待求解系数(可以理解为权重,特征重要性)
线性回归的目的:学习一个线性模型以尽可能准确地预测值输出等于真实值。
f(x)为预测值 yi为真实值
通过最小二乘法求出和
设为f(x)预测值与yi真实值之间的误差,通过最小均方误差
可以得出
通过求导
2.Sigmoid函数
逻辑回归模型通过一个S形的逻辑函数(Sigmoid函数)将线性回归的输出映射到0到1之间的概率值。其数学表达式为:,其中
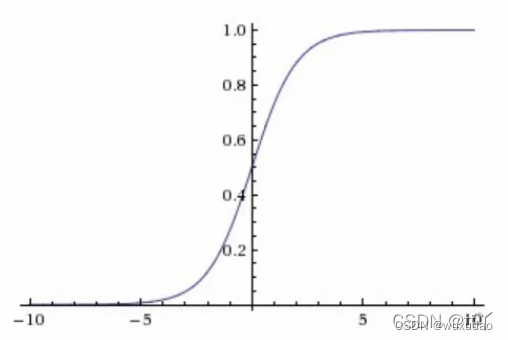
在训练逻辑回归模型时,我们使用交叉熵损失函数来衡量模型预测的准确性。为了找到最优的模型参数,我们常用梯度下降算法。为了防止模型过拟合,我们还可以加入正则化项。
三、逻辑回归的应用
逻辑回归在实际中有广泛的应用,如信用卡欺诈检测、疾病预测和广告点击率预测。成功的模型往往需要有效的特征工程。
四、逻辑回归的优缺点
优点
1.简单且易于实现:
逻辑回归是机器学习中相对简单的算法,易于理解和实现。它通过线性模型和Sigmoid函数进行分类,数学原理清晰明了。
2.计算效率高:
由于其线性性质,逻辑回归的计算效率较高,训练速度快,特别适用于大规模的数据集。
3.可解释性强:
逻辑回归的输出是概率值,容易解释模型的决策过程。权重系数可以直接反映各个特征对分类结果的影响,有助于理解特征的重要性。
4.适用于二分类问题:
逻辑回归特别适用于二分类问题,如垃圾邮件检测、信用卡欺诈检测等。此外,通过扩展可以处理多分类问题(如Softmax回归)。
5.鲁棒性:
对于线性可分的数据,逻辑回归表现良好,且对离群点不太敏感。通过正则化技术(如L1和L2正则化),可以进一步增强模型的鲁棒性,防止过拟合。
缺点
1.线性假设:
逻辑回归假设特征与目标变量之间存在线性关系。这对于非线性数据的表现较差,需要进行特征转换或使用其他非线性模型(如支持向量机、决策树)。
2.易受多重共线性影响:
当特征之间存在高度相关性时,逻辑回归的参数估计会变得不稳定,影响模型性能。可以通过正则化来缓解这一问题。
3.不能自动处理非线性关系:
逻辑回归无法自动捕捉特征之间的非线性关系,需要手动进行特征工程(如多项式特征、交互特征)。
4.对缺失值敏感:
逻辑回归对数据中的缺失值较为敏感,训练前需要进行数据预处理,如填补缺失值或删除缺失值较多的特征。
5.输出概率过于确定:
在某些情况下,逻辑回归的概率输出可能会非常接近0或1,特别是对于不平衡数据集。这样会导致模型对某些类别的预测过于自信,影响分类效果。
五、代码实现
1.假设有一个数据集
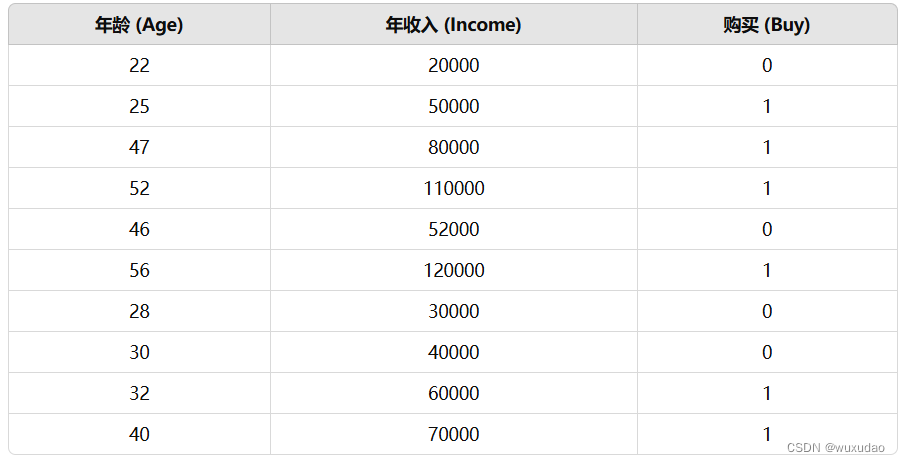
import numpy as np
# 创建数据集
data = {
'Age': [22, 25, 47, 52, 46, 56, 28, 30, 32, 40],
'Income': [20000, 50000, 80000, 110000, 52000, 120000, 30000, 40000, 60000, 70000],
'Buy': [0, 1, 1, 1, 0, 1, 0, 0, 1, 1]
}
# 转换为 NumPy 数组
X = np.array([data['Age'], data['Income']]).T # 特征矩阵
y = np.array(data['Buy']) # 标签向量
# 标准化特征
X_mean = np.mean(X, axis=0)
X_std = np.std(X, axis=0)
X = (X - X_mean) / X_std
# 添加截距项
X = np.hstack([np.ones((X.shape[0], 1)), X])
# 定义 Sigmoid 函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 定义损失函数
def compute_loss(X, y, theta):
m = len(y)
h = sigmoid(X @ theta)
loss = -1/m * (y @ np.log(h) + (1 - y) @ np.log(1 - h))
return loss
# 定义梯度下降函数
def gradient_descent(X, y, theta, learning_rate, iterations):
m = len(y)
for _ in range(iterations):
gradient = 1/m * X.T @ (sigmoid(X @ theta) - y)
theta -= learning_rate * gradient
return theta
# 初始化参数
theta = np.zeros(X.shape[1])
learning_rate = 0.01
iterations = 1000
# 训练模型
theta = gradient_descent(X, y, theta, learning_rate, iterations)
# 预测函数
def predict(X, theta):
return sigmoid(X @ theta) >= 0.5
# 进行预测
predictions = predict(X, theta)
# 计算准确率
accuracy = np.mean(predictions == y)
print(f"模型准确率: {accuracy * 100:.2f}%")
2.结果
![]()
有什么不对的地方请指正!















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









