







超参数调整
1、基础
1.1 什么是超参数
- 定义:训练前需人工设定的参数(如学习率、批大小、Anchor尺寸),直接影响模型学习过程。
- 与普通参数区别:普通参数(如权重)由模型自动学习,超参数需人工干预。
1.2 调优方法
基于生物进化理论,通过迭代选择-变异-评估优化超参数:
- 选择:保留性能最优的参数组。
- 变异:随机扰动参数值(如学习率±20%)。
- 评估:使用验证集计算适应度(如mAP)。
2、调整步骤
2.1 准备工作
- 确认目标:明确优化指标(如mAP、训练速度)。
- 构建搜索空间:定义参数范围(例:学习率 [1e-4, 1e-3],批大小 [8, 16, 32])。
- 选择工具:推荐 Optuna、Ray Tune 或自定义进化脚本。
2.2 核心步骤
- 初始化参数组:随机生成第一代参数。
- 变异操作:对父代参数进行随机扰动(避免局部最优)。
- 模型训练:使用当前参数训练模型(缩短训练周期以加速,如仅训练1-2轮)。
- 评估与日志:记录指标(mAP、loss)并可视化结果。
- 迭代优化:重复“变异-训练-评估”直至收敛。
3、搜索空间配置
表列出了YOLO11 中用于超参数调整的默认搜索空间参数。每个参数都有一个特定的取值范围,由一个元组 (min, max).
from ultralytics import YOLO
# Initialize the YOLO model
model = YOLO("yolo11n.pt")
# Define search space
search_space = {
"lr0": (1e-5, 1e-1),
"degrees": (0.0, 45.0),
}
# Tune hyperparameters on COCO8 for 30 epochs
model.tune(
data="coco8.yaml",
epochs=30,
iterations=300,
optimizer="AdamW",
space=search_space,
plots=False,
save=False,
val=False,
)
4、自定义搜索空间示例
4.1 代码示例
接下来,介绍如何定义搜索空间并使用 model.tune() 方法来利用 Tuner 在 COCO8 上使用 AdamW 优化器对 YOLO11n 的超参数进行 30 个历元的调整,并跳过绘图、检查点和验证(最后一个历元除外),以加快调整速度。
from ultralytics import YOLO
# Initialize the YOLO model
model = YOLO("yolo11n.pt")
# Define search space
search_space = {
"lr0": (1e-5, 1e-1),
"degrees": (0.0, 45.0),
}
# Tune hyperparameters on COCO8 for 30 epochs
model.tune(
data="coco8.yaml",
epochs=30,
iterations=300,
optimizer="AdamW",
space=search_space,
plots=False,
save=False,
val=False,
)
4.2 结果展示
4.2.1 文件结构
以下是结果的目录结构。培训目录如 train1/ 包含单独的调整迭代,即用一组超参数训练一个模型。超参数 tune/ 目录中包含所有单个模型训练的调整结果:
runs/
└── detect/
├── train1/
├── train2/
├── ...
└── tune/
├── best_hyperparameters.yaml
├── best_fitness.png
├── tune_results.csv
├── tune_scatter_plots.png
└── weights/
├── last.pt
└── best.pt
4.2.2 文件说明
4.2.2.1 best_hyperparameters.yaml
该 YAML 文件包含调整过程中发现的性能最佳的超参数。您可以使用该文件,用这些优化设置来初始化未来的训练。
- 格式: YAMLYAML
- 使用方法超参数结果
- Demo
# 558/900 iterations complete ✅ (45536.81s)
# Results saved to /usr/src/ultralytics/runs/detect/tune
# Best fitness=0.64297 observed at iteration 498
# Best fitness metrics are {'metrics/precision(B)': 0.87247, 'metrics/recall(B)': 0.71387, 'metrics/mAP50(B)': 0.79106, 'metrics/mAP50-95(B)': 0.62651, 'val/box_loss': 2.79884, 'val/cls_loss': 2.72386, 'val/dfl_loss': 0.68503, 'fitness': 0.64297}
# Best fitness model is /usr/src/ultralytics/runs/detect/train498
# Best fitness hyperparameters are printed below.
lr0: 0.00269
lrf: 0.00288
momentum: 0.73375
weight_decay: 0.00015
warmup_epochs: 1.22935
warmup_momentum: 0.1525
box: 18.27875
cls: 1.32899
dfl: 0.56016
hsv_h: 0.01148
hsv_s: 0.53554
hsv_v: 0.13636
degrees: 0.0
translate: 0.12431
scale: 0.07643
shear: 0.0
perspective: 0.0
flipud: 0.0
fliplr: 0.08631
mosaic: 0.42551
mixup: 0.0
copy_paste: 0.0
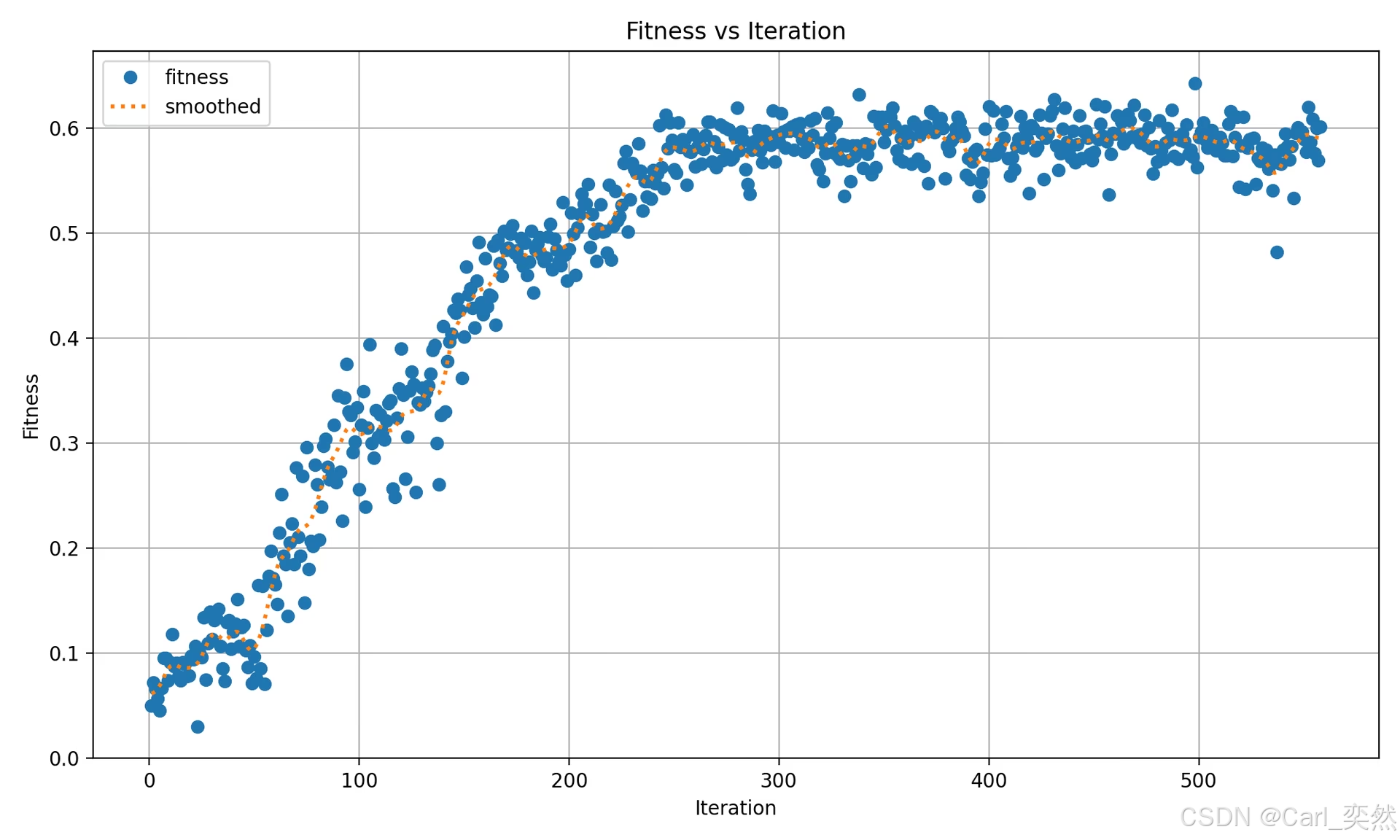
4.2.2.2 best_fitness.png
这是一幅显示适应度(通常是 AP50 这样的性能指标)与迭代次数的对比图。
直观地了解遗传算法在一段时间内的表现。
- 格式:PNGPNG
- 使用方法性能可视化
4.2.2.3 tune_results.csv
CSV 文件,包含调整过程中每次迭代的详细结果。文件中的每一行代表一次迭代,包括适配度得分、精确度、召回率等指标,以及使用的超参数。
- 格式: CSVCSV
- 使用方法每次迭代结果跟踪
Demo
fitness,lr0,lrf,momentum,weight_decay,warmup_epochs,warmup_momentum,box,cls,dfl,hsv_h,hsv_s,hsv_v,degrees,translate,scale,shear,perspective,flipud,fliplr,mosaic,mixup,copy_paste
0.05021,0.01,0.01,0.937,0.0005,3.0,0.8,7.5,0.5,1.5,0.015,0.7,0.4,0.0,0.1,0.5,0.0,0.0,0.0,0.5,1.0,0.0,0.0
0.07217,0.01003,0.00967,0.93897,0.00049,2.79757,0.81075,7.5,0.50746,1.44826,0.01503,0.72948,0.40658,0.0,0.0987,0.4922,0.0,0.0,0.0,0.49729,1.0,0.0,0.0
0.06584,0.01003,0.00855,0.91009,0.00073,3.42176,0.95,8.64301,0.54594,1.72261,0.01503,0.59179,0.40658,0.0,0.0987,0.46955,0.0,0.0,0.0,0.49729,0.80187,0.0,0.0
4.2.2.4 tune_scatter_plots.png
该文件包含由 tune_results.csv帮助你直观地了解不同超参数和性能指标之间的关系。请注意,初始化为 0 的超参数将不会被调整,例如 degrees 和 shear 下图
- 格式:PNGPNG
- 使用方法探索性数据分析

5、总结
超参数调整是目标检测任务中不可或缺的技能。通过系统地调整和优化超参数,我们可以显著提高模型的性能。
尽管如此,深入理解超参数调整的原理和方法仍然是每个计算机视觉从业者的必备技能。
它不仅能帮助我们获得更好的模型性能,还能加深我们对模型行为的理解,为创新性的模型设计和优化提供洞察。
在目标检测任务中,平衡考虑数据质量、模型架构设计和超参数优化,才能达到最佳的检测效果。
我是小鱼:
- CSDN 博客专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)评测一等奖获得者;
关注小鱼,学习【机器视觉与目标检测】最新最全的领域知识。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











