







多模态技术全解析
1、 VLM的定义与核心原理
1.1 什么是VLM?
-
定义:VLM(Visual Language Model)是一种结合视觉(图像/视频)和语言(文本)处理能力的多模态人工智能模型,能够理解并生成与视觉内容相关的自然语言。
-
核心目标:实现跨模态的交互与推理,解决传统计算机视觉模型(仅处理图像)和自然语言处理模型(仅处理文本)无法完成的复杂任务。
1.2 核心组成
- 视觉编码器:
- 功能:提取图像特征,常用CNN(如ResNet)或视觉Transformer(ViT)。
- 作用:将图像转化为高维特征向量,供后续模态融合使用。
- 语言模型:
- 功能:处理文本输入/输出,如GPT、BERT等。
- 作用:生成自然语言描述,或基于文本指令进行推理。
- 多模态融合:
- 方法:
- 跨模态注意力机制:通过注意力权重关联视觉和文本特征。
- 投影层:将不同模态特征映射到同一空间(如CLIP的对比学习)。
- 适配器(Adapter):轻量化的模块化设计,用于连接不同模态。
- 目标:实现视觉与文本的语义对齐与联合推理。
- 方法:
1.3 训练数据与方法
- 数据来源:
- 大规模图像-文本对(如LAION、COCO、Conceptual Captions)。
- 专业领域数据(如医学影像+诊断报告、自动驾驶场景+交通规则文本)。
- 训练目标:
- 对比学习:最大化正例相似度,最小化负例相似度(如CLIP)。
- 生成式目标:训练模型生成图像描述或回答视觉相关问题。
- 指令微调:通过人工标注的指令-响应,提升任务适配性。
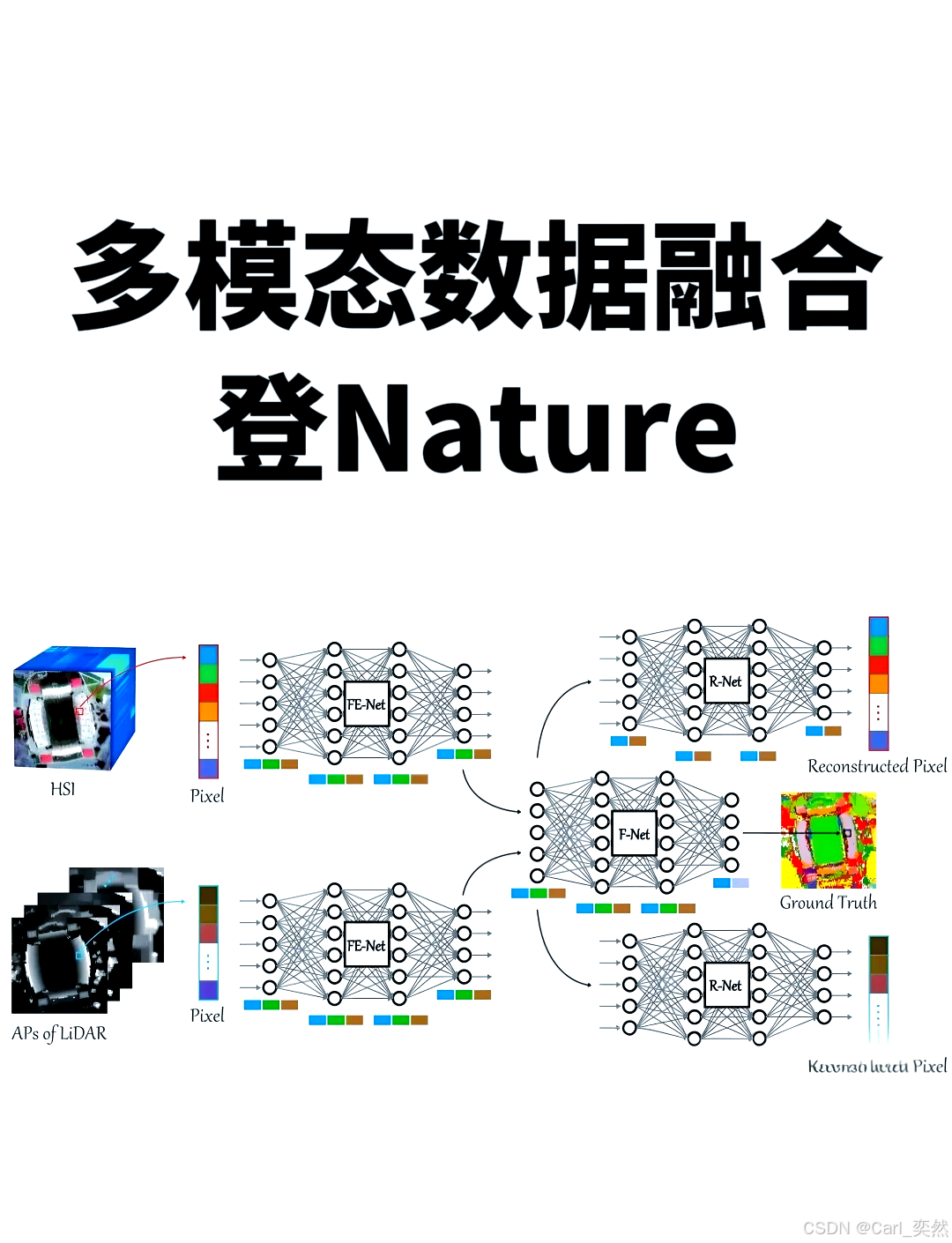
2、 VLM的应用场景
2.1 通用场景
- 图像描述生成:
- 为图片生成Alt文本,辅助视障人士理解内容(如微软Seeing AI)。
- 自动生成社交媒体图片的标题或标签。
- 视觉问答(VQA):
- 回答图像相关问题。
- 支持复杂推理。
- 多模态对话:
- 结合图像和文本进行交互(如GPT-4V、Gemini的对话功能)。
- 示例:用户上传一张地图并提问“从A到B的最短路线是什么?”。
- 内容审核:
- 识别违规图像(如暴力、色情)并生成审核理由。
- 结合文本上下文判断内容是否敏感。
2.2 行业专用场景
- 教育与医疗:
- 医学影像分析:解释X光、CT、MRI图像,辅助医生诊断(如识别肿瘤位置)。
- 教育辅助:生成科学图表的自然语言解释,或根据公式推导过程生成步骤说明。
- 自动驾驶:
- 场景语义解析:理解交通标志(如“潮汐车道”)并生成驾驶决策。
- 智能人车交互:响应自然语言指令(如“切换驾驶模式”)。
- 高阶安全判断:分析复杂场景(如无保护左转)下的潜在风险。
- 地球观测:
- 遥感数据分析:通过卫星图像识别环境变化(如森林砍伐、城市热岛效应)。
- 灾害监测:分析灾害前后的图像差异(如洪水、地震)并生成报告。
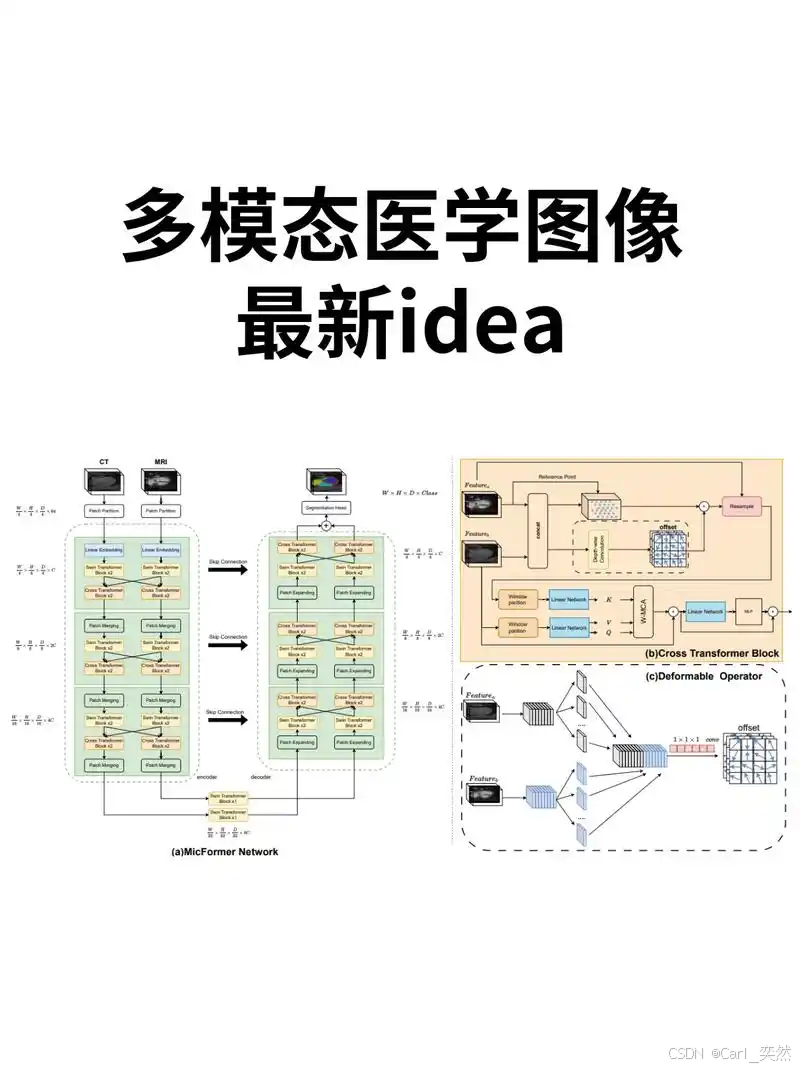
2.3 具身智能与机器人
- 机器人指令执行:
- 基于视觉-语言指令控制机械臂(如“抓取红色杯子”)。
- 实现物理交互(如智能家居设备的语音控制)。
- 工业自动化:
- 通过视觉检测产品缺陷并生成修复建议。
- 结合文本日志分析设备故障原因。
3、 VLM的技术挑战
3.1 模态对齐
- 问题:如何精确匹配图像区域与文本描述?
- 示例:区分“猫在沙发上”与“狗在椅子上”。
- 解决方案:
- 区域级注意力机制:聚焦图像局部区域与对应文本片段。
- 层次化融合:将全局特征与局部特征结合(如ViT的patch级注意力)。
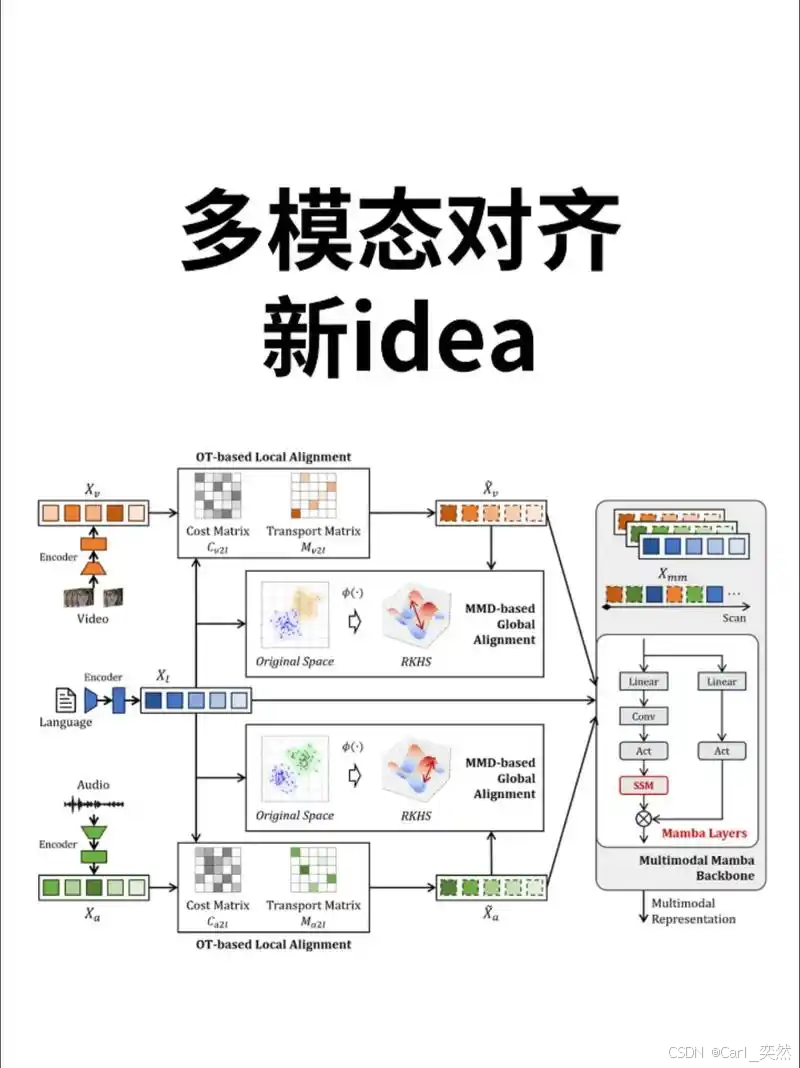
3.2 计算资源
- 挑战:
- 训练需大量GPU算力(如CLIP的训练消耗数千个GPU小时)。
- 推理成本高(如GPT-4V的实时视频处理延迟)。
- 优化方向:
- 轻量化设计:减少参数量(如LoRA微调、模型蒸馏)。
- 边缘部署:压缩模型大小以适应嵌入式设备(如自动驾驶芯片)。
3.3 数据偏差与伦理问题
- 问题:
- 训练数据中的偏见可能导致模型输出不公(如性别/种族刻板印象)。
- 生成内容可能违反伦理规范(如生成虚假新闻图像)。
- 解决方案:
- 去偏见机制:在训练中引入公平性约束(如对抗性正则化)。
- 内容过滤:结合人工审核与自动检测(如AI内容审核系统)。
3.4 可解释性
- 问题:模型决策过程不透明,难以追踪错误根源。
- 解决方案:
- 可视化工具:通过注意力热图展示模型关注的图像区域。
- 可解释性框架:结合因果推理(如SHAP、LIME)分析模型行为。
4、 VLM的未来发展方向
4.1 高效架构设计
- 轻量化模型:
- LoRA微调:通过低秩适配器减少训练参数量。
- 知识蒸馏:将大模型知识迁移到小模型(如TinyCLIP)。
- 动态计算:根据输入复杂度调整计算资源(如动态分辨率处理图像)。
4.2 多模态扩展
- 支持更多模态:
- 视频处理:分析视频序列并生成动态描述(如“视频中车辆从左向右移动”)。
- 3D与音频:结合点云数据(如LiDAR)或语音信号(如语音指令)。
- 跨模态生成:
- 从文本生成图像(如DALL·E)。
- 从图像生成视频(如文本驱动的视频编辑)。
4.3 少样本学习
- 目标:在低资源场景下提升模型适应能力。
- 方法:
- Prompt Engineering:通过设计提示词引导模型输出(如“这张图中的动物是什么?”)。
- 元学习:训练模型快速适应新任务(如Few-Shot VQA)。
4.4 伦理与安全
- 去偏见机制:
- 在训练中引入多样性约束(如公平性损失函数)。
- 开发偏见检测工具(如分析模型输出中的性别/种族分布)。
- 安全控制:
- 限制敏感内容生成(如禁止生成暴力图像)。
- 设计水印技术追踪生成内容来源(如AI生成图像的版权保护)。
4.5 具身智能
- 结合机器人技术:
- 实现基于视觉-语言指令的物理交互(如“打开冰箱门”)。
- 支持自主导航与环境探索(如家用机器人根据指令完成任务)。
5、 典型案例与性能对比
5.1 案例分析
- GPT-4V:
- 能力:支持图像、视频输入,生成自然语言描述。
- 应用:医学图像解释、复杂漫画理解。
- 局限:对专业领域图像(如遥感数据)的准确性较低。
- EarthDial:
- 优势:在多光谱、SAR影像分类任务中优于GPT-4o(准确率提升32.16%)。
- 应用:甲烷羽流检测、城市热岛分析。
- Qwen-VL:
- 架构:结合OpenCLIP ViT编码器与位置感知适配器。
- 性能:在448x448分辨率下支持多任务预训练(如视觉问答、文本生成)。
5.2 性能对比
| 模型 | 任务 | 准确率 | 特点 |
|---|---|---|---|
| CLIP | 图像-文本匹配 | 97.5% | 对比学习范式,强于分类 |
| GPT-4V | 视觉问答 | 82% | 生成能力强,但依赖高质量数据 |
| EarthDial | 甲烷羽流分类 | 77.09% | 多波段融合策略,遥感专用 |
| SmolVLM | 资源受限场景 | 85% | 轻量化设计,适合边缘设备 |
6、 代码示例
6.1 图像描述生成
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
import requests
# 加载预训练模型和处理器
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
# 加载图像
url = "https://example.com/image.jpg" # 替换为实际图片URL
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
# 图像描述生成
inputs = processor(image, return_tensors="pt")
out = model.generate(**inputs)
caption = processor.decode(out[0], skip_special_tokens=True)
print("生成的描述:", caption)
6.2 视觉问答
from transformers import InstructBlipProcessor, InstructBlipForConditionalGeneration
from PIL import Image
import torch
# 加载模型和处理器
processor = InstructBlipProcessor.from_pretrained("Salesforce/instructblip-vicuna-7b")
model = InstructBlipForConditionalGeneration.from_pretrained("Salesforce/instructblip-vicuna-7b")
# 加载图像和问题
image = Image.open("path_to_image.jpg").convert("RGB")
question = "What is the main subject in this image?"
# 模型推理
inputs = processor(images=image, text=question, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(**inputs)
answer = processor.decode(outputs[0], skip_special_tokens=True)
print("答案:", answer)
6.3 轻量化VLM模型
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import get_peft_model, LoraConfig
# 加载预训练模型
model_name = "Qwen/Qwen-VL"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 配置LoRA参数
peft_config = LoraConfig(
r=8, # 低秩秩数
lora_alpha=16, # 缩放因子
target_modules=["q", "v"], # 目标注意力头
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
# 应用LoRA
model = get_peft_model(model, peft_config)
model.print_trainable_parameters() # 查看可训练参数
7、 总结
VLM技术通过多模态融合解决了传统单一模态模型的局限性,已在通用场景、行业专用场景和具身智能领域取得突破。
我是小鱼:
- CSDN 博客专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)评测一等奖获得者;
关注小鱼,学习【机器视觉与目标检测】 和【人工智能与大模型】最新最全的领域知识。


















 1438
1438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











