







这段时间,会有系列真实的竞赛项目陪伴,我会通过修炼笔记的方式记录我这段时间学习数据竞赛的经历,希望每个竞赛都能给我们带来收获和成长! 这个故事会很长,但我会坚持往下走,你看,天上太阳正晴,如果可以,我们一起吧…
1. 写在前面
终于下定决心涉足这个纠结很久的话题了,作为一个懵懂无知的竞赛小白,其实是非常渴望参加一场数据比赛的,因为数据比赛对于AIer来说真的很重要,不知道你是否遇到过这样的一些疑惑,就是涉足一个新领域的时候,比如数据挖掘,先非常努力的花时间学习python,numpy,pandas,scipy,sklearn这些基础知识,但是当后面真的遇到实际问题的时候,却不知道如何下手去分析,再回头想掏之前学会的工具时,发现这些工具依然在,但已记不清它们的使用说明。难不成之前学习过的这些都白学了? 其实不是的,这些工具都在,只不过我们之前没有真正的去用过它, 所以,比赛就是一个让我们大展身手的舞台,通过解决实际问题,我们才能真正掌握之前的工具,也是学习知识的一个融合,毕竟解决实际问题,需要各个领域的知识交融和碰撞。在这个过程中,我们还可以认识一些志同道合的伙伴,一起进步和交流,进行思维的碰撞并得到成长。
所以这个数据竞赛修炼系列我会把我的所思所学都记录下来并分享,一是因为解决问题的思路可以迁移和变换,这样或许会帮助更多的人,二是通过整理和总结,可以使得知识和技能在自己脑海中逗留的时间长一些吧。
首先声明这个系列的每一篇都会很长,并且会有一大波代码来袭,毕竟每一篇都是一个完整的数据竞赛,每一篇都需要很长的时间消化整理,因为我想用最朴素,最详细的语言把每个比赛的思路和代码说给你听。
今天是数据竞赛修炼笔记的第一篇,带来的比赛是2018年科赛网上的一个比赛快手用户活跃度的预测,我们拿到了一份快手平台记录的关于快手用户的30天一个行为数据集(记录用户注册,登录,视频观看与发布,互动的记录),我们的目标就是根据这个行为数据集预测在未来七天的活跃用户。
首先我们会对任务的目标和数据进行分析,然后会概览模型的架构,从模型的角度提取特征和标签构建数据集,然后基于tensorflow建立模型并训练得到结果。最后会再结合一些好的解决方案,对解决这个问题的思路和知识点进行总结。
大纲如下:
- 任务目标与数据分析
- 整理模型架构
- 构建用户特征,生成汇总表
- 制作标签
- 建立模型并训练,得到最后的结果
- 知识点和思路的总结(两个知识点温习:pandas的iterrows()和groupby())
Ok, let’s go!
开始之前,需要导入包:
import numpy as np
import pandas as pd
import tensorflow as tf
from deep_tools import f
from deep_tools import DataGenerator
2. 任务目标和数据分析
在这一部分,我们先看看拿到的是一份什么样的数据,然后分析一下我们这个任务到底怎么应该去做。
我们会拿到四个表格,分别是:
- 用户注册日志表,记录的是用户什么时候使用什么方式(微信,qq)什么设备(手机,pad)进行注册的快手账号,会有四个字段的信息,注意,day这一列,由于我们搜集的是30天的数据,所以这里的取值是1-30, 表示的是用户第几天的行为,后面那几份数据也是一样。
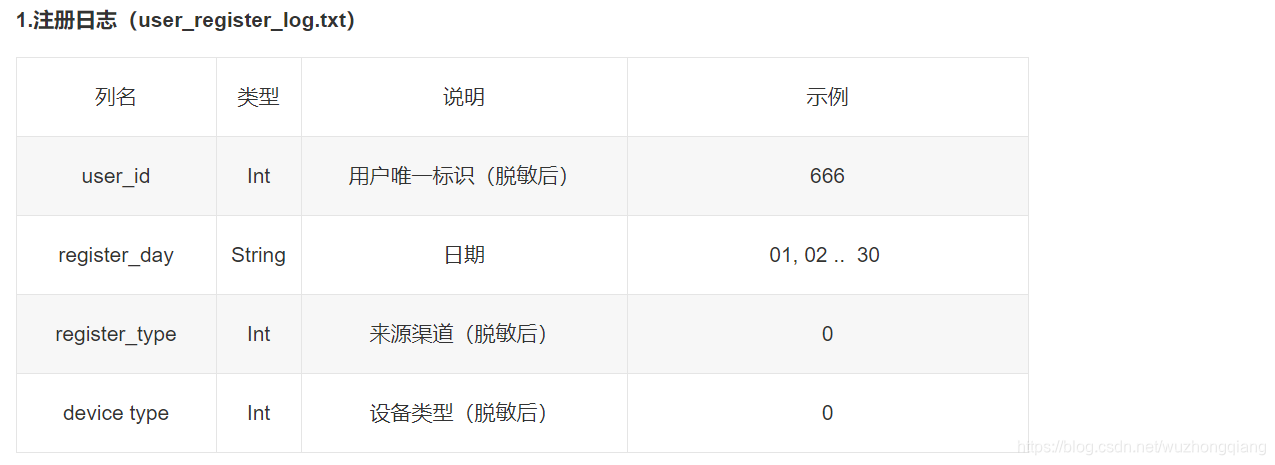
- APP启动日志表,记录的是用户在第几天登录过快手app, 两个字段的信息

- 视频创建日志表, 记录的是用户在第几天创作过视频

- 用户行为日志表,这个比较关键,也是我们后面制作特征的主要渠道来源,由用户的行为才能看出用户是不是活跃

下面,我们就导入数据,详细的看一下这些数据吧
"""读取数据集"""
register = pd.read_csv('user_register_log.txt', sep='\t', names=['user_id', 'register_day', 'register_type', 'device_type'])
launch = pd.read_csv('app_launch_log.txt', seq='\t', names=['user_id', 'launch_day'])
create = pd.read_csv('video_create_log.txt', seq='\t', names=['user_id', 'create_day'])
activity = pd.read_csv('user_activity_log.txt', seq='\t', names=['user_id', 'act_day', 'page', 'video_id', 'author_id', 'act_type'])
通过上面的四行代码,我们就可以把txt的数据读入并转成了pd的DataFrame格式,注意上面的分隔符要制定成\t。然后我们看其中一个表里面是什么样的数据。这是记录用户行为的表(其他的类似):

接下来,我们对数据和任务进行一个解析。
- 关于数据
我们拿到的是一个连续的30天之内用户的一个行为数据,包含了四个数据集,分别记录用户的注册,登录,创建视频,使用行为的信息, 但是有一个问题要注意,就是不一定每个用户的信息都是30天的记录,因为,我们这里有一个注册信息表,里面有一个register_day的字段,这个字段不一定所有用户都是1,即不一定每个用户都是在第一天进行注册的。比如,假设一个用户在第七天才注册的,那么前七天就没有这个用户的信息,假设一个用户是在第25天注册的,那么这个用户只有后五天的数据。 所以这是这个任务的一个难点所在,就是每个用户的被记录的时间序列长度并不是一样的, 所有后面我们分析的时候,对于一个用户,得先分析是在哪一天注册的,我们再从这一天开始去算。 - 关于任务
我们拿到了每个用户的这样的数据,是要预测未来的活跃度,注意这个未来,不是接下来的一两天,而是挺长的一段时间,一个周期这样的。我们这里是预测未来七天内的, 比如有个用户第七天注册了,我们预测的是他第七天到第十四天的活跃度的可能性。这就是我们的目标,基于之前的一段序列数据,来预测未来七天的活跃度的可能性。这很明显,是一个时间序列的预测任务。
理解了数据和任务,下面我们可以考虑如何去解决这个问题,注意这样的实际项目可能和我们那种kaggle的入门赛还不一样,那样的问题一上来就直接给定好了数据特征和标签之类的东西,我们做的是特征工程,然后建立模型解决就可以了。
而这种实际问题上,给定的数据不可能拿来直接用,得需要我们自己提取特征和标签。 但是我们目前可能看到这些数据之后一脸懵逼,不知道如何下手分析,那么我们不妨换一种思路,从模型入手,看看什么样的模型适合这种问题,然后倒推出针对这种模型,我们应该给他一个什么样的输入。这样,我们再去做相应的输入出来,这也是考虑问题的一种方式吧。 所以这次先从模型开始。
3. 整体模型架构
关于模型的问题,我们做的虽然说预测用户的活跃度,但可以转化成一个二分类的问题,最后输出就是未来七天时间内,这个用户是否活跃(0或者1)。既然是二分类的问题,那么这里的模型选择就比较多了,什么xgb,lgb,这些优秀的机器学习算法都可以,但是我们分析一下,我们最后拿到的这个数据应该是针对某一个用户,会有从他注册到后面行为的一系列信息,而这些都是时间上进行相关的,比如一个用户第七天注册了,那么我们就有这个用户第七天到第30天的各种行为,也是一种时间序列的预测。关于这种时间序列的预测,如果要使用机器学习的方式,就需要用滑动窗口去切割数据集,并且特征提取上需要使用历史信息的统计特征。
我们这里使用神经网络的方式,也就是RNN来完成这个任务,这样不需要对输入序列做过多处理,也不使用滑动窗口。毕竟时间的监督学习任务,RNN还是比较擅长的,能够捕捉到时间的这种关联信息。
使用RNN,一般地会想到如下解决方案:
以几天内的用户行为序列为输入,以未来七天该用户是否活跃为标签,标注该序列。这是一种Many2One的解决方案。但是这样做的话为了充分利用数据,需要对训练数据做大量的滑窗,以实现数据增广,计算成本高。另外,每个序列只有一个标签,梯度难以传导,导致训练困难。所以我们可以考虑Many2Many结构,即每个输入都对应输出之后7天是否活跃,充分利用监督信息,减轻梯度传到负担,使训练更加容易。我们就可以构建出RNN的大体模型长这样:
这样我们的网络架构就构思出来了,但是这里还有一个细节,就是序列是变长的,就是用户的记录天数是不同的,每个batch中取相同长度的序列,不同batch长度不同,每次随机取某一长度的batch。这时候我们需要使用动态RNN,根据时间序列的长度自己调整。

有了网络架构,那么我们怎么去构建数据呢? 我们知道网络上面的都是一些label值,也就是0或者1的这些,表示活跃不活跃。 下面的序列就是我们的输入数据,但是t1,t2,…tn这些数据应该是长什么样子呢?
下面就是这个问题的核心工作: 构建用户特征,也就是我们的输入应该是什么样子的。
4. 构建用户特征序列
这一块是我们的重点,我们想一下,既然网络的输入是时间序列,那么肯定输入的数据有一个维度是时间,那么我们不妨这样,对于每一个用户,我们找一下他的信息和时间有什么关联。很容易就会想到,如果一个用户注册了,那么从注册之后的每一天,快手都会记录他每一天的行为(是不是登录,是不是点赞,创建视频等),那么我们可以这样,每一个用户给他建立一个二维的表,表的每一行代表注册后快手记录他的每一天, 每一列代表每一天干的事情。 我们根据所给的表格提取出这些相应的信息,那么每个用户的特征序列其实就构建完毕了。 所以根据这样的一个思路,我们可以构建特征出来。步骤如下:
-
保存每个用户的记录数据
既然之前我们说过,每个用户的记录序列长度是不一样子的,所以这个地方我们应该首先先统计每个用户到底有几天的记录数据,把这个长度我们先保存下来。这个就是我们上面说的那个二维表的行数,这个比较简单,直接用总天数减去他注册的时间就可以啦。"""计算序列长度: 持续时间 = 数据总时间 - 注册时间""" register['seq_length'] = 31 - register['register_day'] register.head()可以看一下这个注册信息表对了一列长度信息(不一定都是30):

-
创建用户记录字典
根据前面的记录天数,创建一个字典,来存储不同记录天数的用户到底有哪些, key表示记录长度,value表示用户id。比如只有1天记录的有哪些用户,2天记录的有哪些,…30天完整记录的用户有哪些),这个的目的就是因为我们的用户序列都不等长,也就是每个用户的记录天数不一定一样,这样就导致如果统一喂入神经网络的话,没法组成一个矩阵的形式, 但如果根据记录天数把用户给分开了,那么同一个记录天数下会有很多用户,这些序列是等长的, 那么我们就可以把这些划分成一个batch给神经网络,就好处理了。就是网络的输入接收的每个batch的序列长度要求是相同的,但是不同batch的序列可以不同。
方式也很简单,建立一个空字典键是1-30天,然后遍历一遍register表,根据最后一列的seq_length, 把对应的user_id填到相应的天数中,这样这个字典就保存了每一个不同天数下都哪些用户了。
"""根据前面的记录天数,创建一个字典,来存储不同记录天数的用户到底有哪些 """ user_queue = {i: [] for i in range(1,31)} for index, row in register.iterrows(): # 这个iterrows是对DataFrame进行行遍历,是在数据框中的行进行迭代的一个生成器,它返回每行的索引及一个包含行本身的对象。 user_queue[row[-1]].append(row[0]) # row[-1]是seq_length, row[0]是user_id -
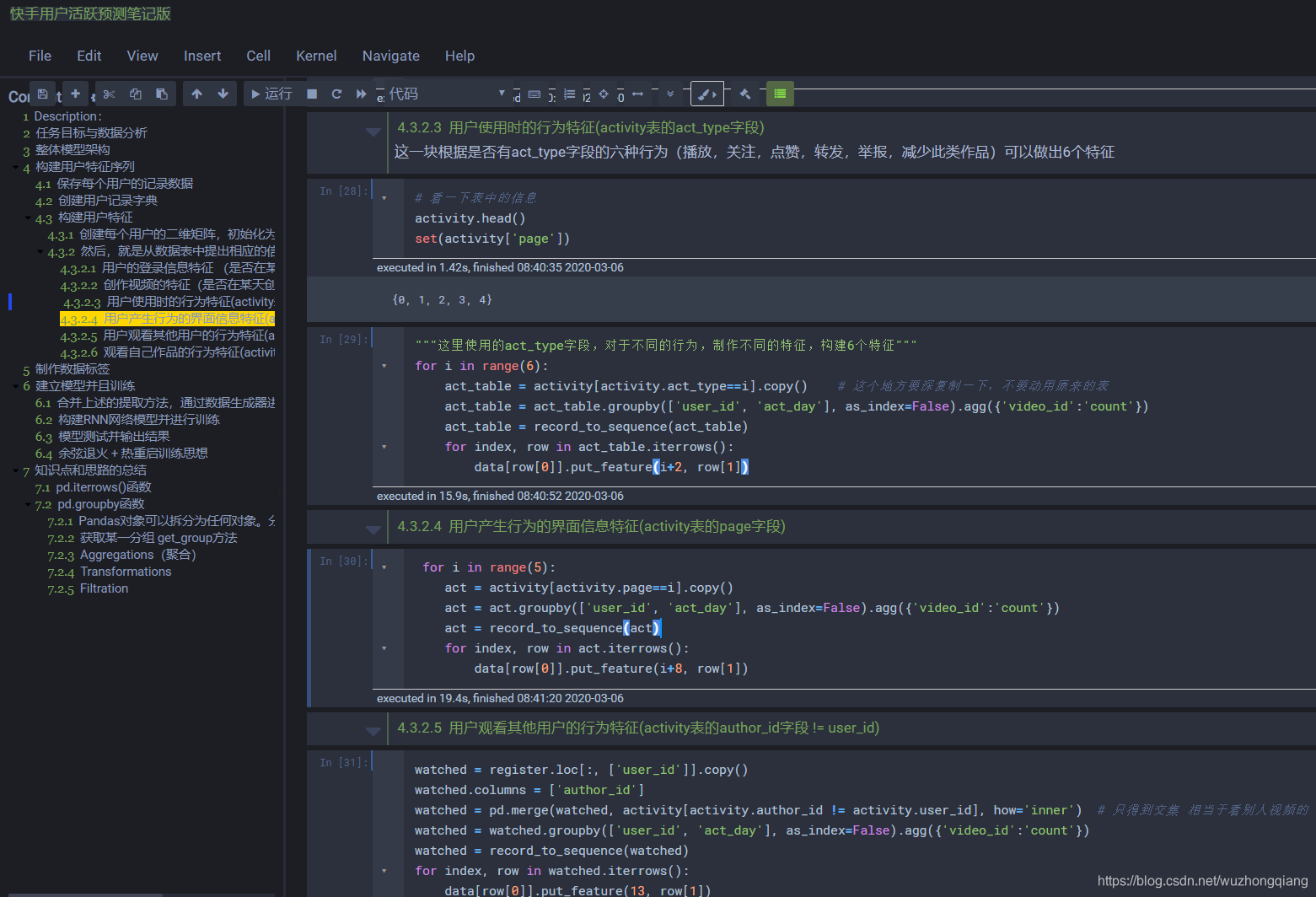
接下来,构建用户特征
这一块,我们得考虑究竟怎么去提取特征呢? 首先,得有一个特征的个数,就是针对每个用户,每天的记录,我们得提取多少个特征。 这些特征就是用户的行为,比如什么时候登陆,登陆之后,点没点赞,创没创建视频这些东西(都从数据集里面提取)。 所以对于一个用户来说,我们的输入数据最后应该是一个矩阵,每一行代表着记录的天数,每一列代表一个特征,看下面的图也知道为什么之前要统计不同记录对应的用户了吧,每个用户对应一个矩阵,然后很多个用户合起来就是一个3维的向量,这一个至少是一个立方体的形式。 如果用户的记录不一样的话,就没法进行用户的合并,所以我们这里有了这样一个字典之后,我们就可以把每个记录的用户看成一个batch放入神经网络了。

这一块的思路呢? 我们是要构建用户特征,所以我们定义一个用户序列的类,把所有相关的操作都放到用户序列的里面"""定义一个user_seq类""" class user_seq: def __init__(self, register_day, seq_length, n_features): """ register_day: 用户第几天进行的登录 seq_length: 用户序列的长度,就是记录了几天登录信息, 行数 n_features: 每天提出的特征个数, 列数 """ self.register_day = register_day self.seq_length = seq_length self.array = np.zeros([seq_length, n_features]) # 这就是上面那个用户对应的矩阵形式,初始化位0 self.page_rank = np.zeros([self.seq_length]) self.pointer = 1 # 提取特征填入特征矩阵 def put_feature(self, feature_number, string): for i in string.split(','): pos, value = i.split(':') # 注册后的第几天进行了登录,1为指示符 self.array[int(pos)-self.register_day, feature_number] = 1 # 从注册后开始记录 def get_array(self): return self.array # 得到标签 如果一个用户在未来七天活跃了,那么标记为1 def get_label(self): self.label = np.array([None] * self.seq_length) # 一个seq_length长度的数组 active = self.array[:, :12].sum(axis=1) # 这里选了一部分特征做了个sum,意思是不管是转发,登录,啥的,只要做了就算一次活动 for i in range(self.seq_length-7): # 这地方得控制一下,如果一个用户15-30的数据,那么我们标签最多只能到23天,因为30天之后的数据我们没有 self.label[i] = 1 * (np.sum(active[i+1:i+8]) > 0) # 这里对于当前的i,如果未来七天内活跃过,那么标签就是1 return self.label-
首先,会构建出每个用户的特征矩阵,就是上面的那种矩阵构建出来,初始化为0, 这里假设特征列为15,即f=15
"""创建用户的记录矩阵""" n_features = 15 data = {row[0]:user_seq(register_day=row[1], seq_length=row[-1], n_feagures=n_features) for index, row in register.iterrows()}这样,每一个用户就都会用了一个二维特征表

-
遍历上面的数据表,开始提取相应的特征,把这些特征填入相应用户的相应记录的相应特征中
这一块,就是基于之前的数据表提取特征,分为下面几块提取- 用户的登录信息特征(launch表)
这一块就是每个用户在某天是否登录, 先看一下launch表

下面提取特征, 填入到用户的二维表:
launch[‘launch_freq’] = 1
launch_table = launch.groupby([‘user_id’, ‘launch_day’], as_index=False).agg({‘launch_freq’:‘sum’})
然后, 根据用户的id进行整合一下,把相同用户的结果放在一起(代码中有个recode_to_sequence(table)函数)
launch_table = record_to_sequence(launch_table)
结果是下面这样:

接下来,就是把这个登录的信息填入到特征矩阵,是否登录作为第一个特征
for index, row in launch_table.iterrows(): # 根据登录信息对用户特征表进行填充
data[row[0]].put_feature(0, row[1])
后面的这几个提取特征和第一个思路一样,具体见代码,都是先根据id和特征分组统计,然后相同id的合并,然后添入特征矩阵。
- 用户创作视频的信息特征(create表)
- 用户使用时的行为特征,例如点赞,转发等(activity表的act_type)
- 用户产生行为的界面信息特征(activity表的page字段)
- 用户观看其他用户的行为特征(activity表的author_id字段 != user_id)
- 观看自己作品的行为特征(activity表的author_id字段 == user_id)
由于这块的代码篇幅太长,所以这里只讲大体思路,至于上面的代码都放入了GitHub,后面会给出链接。
- 用户的登录信息特征(launch表)
-
5. 制作数据标签
通过上面的操作,我们就构建好了神经网络的输入,当然这里这样构建特征是为神经网络服务的,如果是想用机器学习的一些方式,就可以提取一些统计的特征,比如平均值,方差,中位数的这些东西用xgb什么的跑,但是这种时间之间的特征可能就捕捉不到了。
下面,我们就是制作数据的标签了: 在未来七天内是否会使用APP, 这个的思路就是对用户从注册开始就进行统计,对于每1天的数据展开,如果其未来七天内这个用户活跃过,就标记为1
label = {user_id:user.get_label() for user_id, user in data.items()}
这里用到了user_seq类汇总的git_label函数,这个函数做了个这样的事情:首先建立了一个用户记录等长的数组,然后用户二维表的每一天的活动进行了求和,然后从注册的第一天开始遍历,如果未来七天有一天有活动,那么标签为1,否则为0
最后会得到一个这样的结果:

最后一句:
data = {user_id: user.get_array() for user_id, user in data.items()}
这样data是一个字典,键是1-30的某一天,对应的值是3维的矩阵(好多用户,每个用户的二维表)
这样特征被标签就构建完毕。 下面就是建立动态RNN模型进行训练测试了。
6. 建立模型并且训练
通过上面的方式,我们已经把数据特征和标签都已经制作完毕,接下来就是建立RNN模型进行训练了,这里使用tensorflow来建立模型。
6.1 合并上述的提取方法,通过数据生成器获得
这一块就是把上面的方法写到了deep_tools里面,用DataGenerator就可以获得最终的结果了。
register=pd.read_csv('user_register_log.txt',sep='\t',names=['user_id','register_day','register_type','device_type'])
launch=pd.read_csv('app_launch_log.txt',sep='\t',names=['user_id','launch_day'])
create=pd.read_csv('video_create_log.txt',sep='\t',names=['user_id','create_day'])
activity=pd.read_csv('user_activity_log.txt',sep='\t',names=['user_id','act_day','page','video_id','author_id','act_type'])
data_generator=DataGenerator(register,launch,create,activity)
6.2 构建RNN网络模型并进行训练
前面说过,这里由于每个batch的时间序列长度可能不一样,所以需要使用动态RNN,单元GRU和LSTM效果差不多,都可以
n_features = 12
n_hu = 8
with tf.variable_scope('train'): # tf.variable_scope用来指定变量的作用域
# 变量与输入
lr = tf.placeholder(tf.float32, [], name='learning_rate') # 定义学习率
# 隐藏层到输出层的参数w, b w_shape(n_hu,1) b_shape(1) n_huWie隐藏单元的个数
W_out = tf.get_variable('W_out', [n_hu, 1])
b_out = tf.get_variable('b_out', [1])
# x和y x_shape(batch_size, seq_length, n_features)
x = tf.placeholder(tf.float32, [None, None, n_features])
y = tf.placeholder(tf.float32, [None, None])
# batch_size和seq_length的大小
batch_size = tf.shape(x)[0]
seq_length = tf.shape(x)[1]
# RNN 层
cell = tf.nn.rnn_cell.GRUCell(n_hu) # n_hu表示每个GRUcell里面的单元个数
initial_state = cell.zero_state(batch_size, dtype=tf.float32) # 指定初识状态,因为之前没有训练过
outputs, state = tf.nn.dynamic_rnn(cell, x, initial_state=initial_state) # 使用的动态Rnn
# outputs(batch_size, max_seq_length, n_hu) 这是所有时间步的输出
# state (batch_size, n_hu) 这是最后一个时间步的输出
# 具体:https://blog.csdn.net/u010960155/article/details/81707498
# 输出层
outputs = tf.reshape(outputs, [-1, n_hu]) # (batch_size*max_seq_length, n_hu)
logits = tf.matmul(outputs, W_out) + b_out # (batch_size*max_seq_length)
logits = tf.reshape(logits, tf.stack([batch_size, seq_length]))
这里选择部分预测结果与标签当做训练损失的计算,这个由于比赛已经结束,没法进行线上训练,所以只能线下训练,选择前16天进行训练,16-23天测试
# 选择部分预测结果与标签当做训练损失计算
logits_local_train = logits[:, :-14] # 这里-14或者是更小,因为本地训练,我们用前16天训练,16-23天测试。
label_local_train = y[:, :-14]
设置训练选项, 加入正则化,Adam优化算法
# 设置损失函数
# 正则化项
regularizer = tf.contrib.layers.l2_regularizer(0.00001)
penalty = tf.contrib.layers.apply_regularization(regularizer, tf.trainable_variables())
obj_local = tf.losses.sigmoid_cross_entropy(label_local_train, logits_local_train) + penalty
optimizer = tf.train.AdamOptimizer(lr)
set_local = optimizer.minimize(obj_local)
# 选择部分预测结果与标签当做测试损失计算
logits_local_test = logits[:, -8]
label_local_test = y[:, -8] # 这里也可以选择其他的天
训练函数:
def train(n_obs=1000, step=1000, lr_feed=0.01):
#date_seq = [31] + list(range(2, 16)) + [16] * 15
variables = [set_local, obj_local, label_local_train, logits_local_train]
for i in range(step):
length, id_list, data_x, data_y = data_generator.next_batch(n_obs)
_, los, lab, log = sess.run(variables,
feed_dict={x:data_x, y:data_y, lr:lr_feed})
这里训练这个,取数据的思路得解释一下:next_batch操作这里取数据的时候,这个序列长度并不是随机取的。 如果看next_batch函数的时候就会注意到, 首先是先有了local_random_list, 然后从这里面取序列的长度, 那么这个local_random_list做了个什么事情呢? 他不是1-30的序列长度随机选,因为不同序列长度的用户个数不一样,而大部分应该集中在15天及以后,1-14天的那种用户可能很少,这样就有可能不够一个batch_size。 所以尽量的选15天以后的,这个local_random_list里面的元素就是从15开始,然后越往后的元素个数越多,那么相应被选择的几率就越大。 这样无非就是选择序列的时候,对应的用户让他多一些,这样好取够batch_size。
然后有了这个序列长度,我们就可以取相应的用户了,pointer指针就是为了从头开始选择用户数据,够一个batch_size为止,如果超了用户数目的长度,就回到头上,然后打乱用户数据,再取。 (这里建议看一下代码,只描述可能不知道咋回事, 在deep.tools.py)
然后就是训练了:
sess = tf.Session()
sess.run(tf.global_variables_initializer())
train(n_obs=1000, step=2000, lr_feed=0.01)
6.3 模型测试并输出结果
比赛使用的f1值进行评估, 关于f1值可以查看算法模型评估之混淆矩阵,accuracy,查准率,查全率,AUC(ROC)等小总结:

测试函数
def test():
n_NA = 14 # 本地训练, 我们是1-16天训练,16-23天预测,所以这个地方最大是30-14
# 优化目标和数据
variables_1 = [obj_local, logits_local_train, label_local_train]
variables_2 = [logits_local_test, label_local_test]
obs_count, cum_loss, correct = 0, 0, 0
user, prob, real = [], [], []
# 训练损失
for length, id_list, data_x, data_y in zip(*data_generator.get_set('train')):
_obj, _logits_train, _label_train = sess.run(variables_1,
feed_dict={x:data_x, y:data_y, lr:0.001})
obs_count += (length - n_NA) * len(id_list)
cum_loss += _obj * (length - n_NA) * len(id_list)
correct += np.sum((1 * (_logits_train>0) == _label_train))
# 测试损失
for length, id_list, data_x, data_y in zip(*data_generator.get_set('test')):
_ = sess.run(variables_2, feed_dict={x:data_x, y:data_y, lr:0.001})
_logits_test, _label_test = _
real += list(_label_test)
user += list(id_list)
prob += list(1 / (1+np.exp(-_logits_test.reshape([-1]))))
# 打印训练损失
print('train_loss', cum_loss/obs_count)
# 测试损失
result = pd.DataFrame({'user_id':user, 'prob':prob, 'label':real})
print('test_score:', f(result))
return result
test()
最终结果如下:

会输出最终的f1值和一个表,这个表里面就是给定id,预测未来七天是否活跃的结果。
6.4 余弦退火 + 热重启训练思想
这里顺带记录一个训练的技巧:
越来越接近loss值的全局最小值时,学习率应该变得越来越小来使得模型尽可能接近最小值。 然后突然提高学习率,来“跳出”局部最小值并找到通向全局最小值的路径。
def cos_annealing_local(epoch=5):
all_result=None
for i in range(epoch):
train(step=2000,lr_feed=0.01)
train(step=2000,lr_feed=0.001)
result=test()
print(sess.run(penalty))
result.columns=['label','prob%s'%i,'user_id']
if i==0:
all_result=result
else:
all_result=pd.merge(all_result,result)
return all_result
这个效果会提升一点。
7. 知识点和思路的总结
关于知识点的总结这块,这次我们在处理特征的时候用的最多的是pandas的DataFrame的行遍历iterrows和groupby函数,所以重点总结一下这两个函数的使用,但是由于篇幅原因,写到了另外一篇博客里面https://blog.csdn.net/wuzhongqiang/article/details/104714458
而关于思路这块,这个比赛方案的思路是一个接近top的一个方案。所以感觉人家的想法还是很不错的,至少我第一次拿到这个题目一脸懵逼,所以这一块还得多学习。
简单总结一下: 我们这次做的是一个快手用户活跃度的预测,可以看做一个二分类的问题,针对这个预测问题,首先,我们从构建网络的整体结构出发,去倒推我们的输入是什么样子,根据网络结构,我们把用户的特征以二维表的形式构建,每一行代表时间,每一列代表特征(行为活动),这样就可以取提取特征,得到最终的训练数据。 对于变长序列,我们采用了动态RNN的方式建立网络,然后取batch的时候,我们选择的序列长度是其包含的数据尽量的多一些。 关于训练,我们这里get到了一种叫做余弦退火热重启的思想。 最后我们还知道了线上训练和线下训练还是有些区别的。
关于这个比赛的详细代码和笔记,我已经放到了GitHub上,可以自行查阅:
https://github.com/zhongqiangwu960812/AIGame/tree/master/GameOfKesci

















 9978
9978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









