






在当今数字化时代,图像数据无处不在,而卷积神经网络(Convolutional Neural Network,简称 CNN)作为一种强大的深度学习模型,已经成为图像识别领域的核心工具。CNN 以其卓越的性能和广泛的应用,改变了我们处理和理解图像的方式。它能够自动提取图像中的特征,通过卷积层、池化层和激活函数等组件,捕捉图像的局部特征和空间层次结构。CNN 不仅在手写数字识别、图像分类等任务中表现出色,还在目标检测、语义分割等领域展现了强大的能力。

CNN 的基本原理
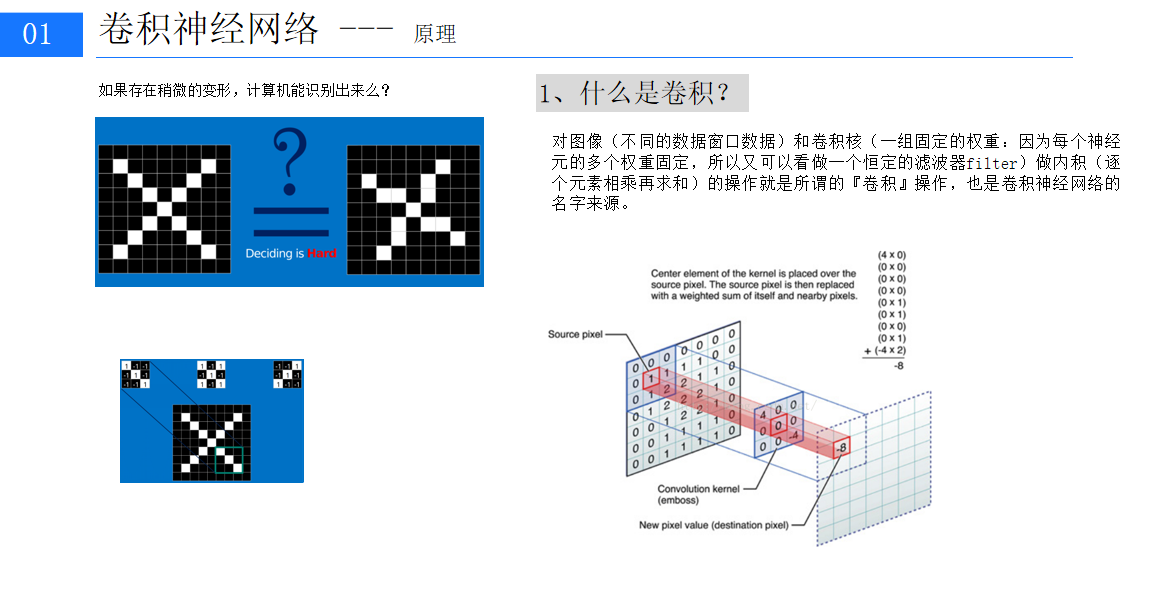
CNN 的核心思想是利用卷积运算来提取图像的特征。与传统的全连接神经网络不同,CNN 通过卷积层、池化层和激活函数等组件,能够自动学习图像中的局部特征和空间层次结构,从而更有效地处理图像数据。
卷积层
卷积层是 CNN 的关键部分,它通过卷积核(也称为滤波器)在输入图像上滑动并进行卷积运算,从而提取图像的局部特征。卷积核是一个小的二维矩阵,它与输入图像的局部区域进行逐元素相乘并求和,生成一个新的特征图(Feature Map)。通过使用多个不同的卷积核,可以提取图像中的多种特征,如边缘、纹理、形状等。例如,在一个简单的图像边缘检测任务中,一个卷积核可以被设计为突出图像中的水平边缘,而另一个卷积核可以检测垂直边缘。随着网络层数的增加,卷积层可以逐步提取更复杂的特征,从低层次的简单特征(如边缘和纹理)到高层次的语义特征(如物体的轮廓和形状)。

一、环境准备与数据加载
在开始之前,我们需要安装 PyTorch 和 torchvision。PyTorch 是一个强大的深度学习框架,而 torchvision 提供了许多与图像相关的数据集和工具。
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
接下来,我们加载手写数字数据集 MNIST。MNIST 数据集包含 60,000 张训练图像和 10,000 张测试图像,每张图像都是 28×28 的灰度图像,对应一个数字标签(0-9)。
'''下载训练数据集(包含训练图片+标签)'''
training_data = datasets.MNIST(
root="data",
train=True,
download=True,
transform=ToTensor()#Tensor是在深度学习中提出并广泛运用的数据类型,它与深度学习框架(如PyTorch,TensorFlow)
) #Numpy 数组只能在cpu上运行。Tensor可以在GPU上运行,这在深度学习中可以显著提高计算速度。
print(len(training_data))
'''下载测试数据集(包含训练图片+标签)'''
test_data = datasets.MNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
print(len(test_data))
这里,我们使用 ToTensor 将图像数据转换为 PyTorch 张量(Tensor)。张量是 PyTorch 中的基本数据类型,类似于 NumPy 的数组,但它可以在 GPU 上运行,从而加速计算。
二、数据可视化
为了更好地理解数据,我们可视化一些训练图像。
'''展示手写字图片,把训练数据集中的前59000张图片展示一下'''
from matplotlib import pyplot as plt
figure = plt.figure()
for i in range(9):
img, label = training_data[i+59000] #提取第59000张图片
figure.add_subplot(3,3,i+1) #图片窗口中创建多个小窗口 ,小窗口用于显示图片 3*3
plt.title(label)
plt.axis("off") # plt.show(I) #显示矢量,
plt.imshow(img.squeeze(),cmap="gray")# 将numpy数组data的数据转化为图像
a = img.squeeze()#从张量img中去掉维度最高的也就是1,如果改维度的大小不为1 则张量不会改变
plt.show()
train_dataloader = DataLoader(training_data,batch_size=64)#64张图片为一个包
test_dataloader = DataLoader(test_data,batch_size=64)
这段代码从训练数据集中提取了 9 张图像,并将它们显示在一个 3×3 的网格中。img.squeeze() 是将图像张量从形状 (1, 28, 28) 转换为 (28, 28),以便正确显示。
三、构建卷积神经网络模型
接下来,我们构建一个卷积神经网络(CNN)模型。CNN 是处理图像数据的常用模型,因为它能够自动提取图像的特征。
class CNN(nn.Module):
def __init__(self): # 输入大小(1,28,28)
super(CNN, self).__init__() # 初始化父类
self.conv1 = nn.Sequential( # 将多个层组合到一起,创建了一个容器
nn.Conv2d( #2d一般用于图像,3d用于视频数据(多一个时间维度),1d一般用于结构化的序列数据
in_channels=1, #、图像通道个数,1表示灰度图(确定了卷积核 组中的个数)
out_channels=8, # 要得到几多少个特征图,卷积核的个数
kernel_size=3, # 卷积核大小,3*3
stride=1, # 步长
padding=1,
),
nn.ReLU(), # (8,28,28)
nn.MaxPool2d(kernel_size=2) # (8,14,14)
)
self.conv2 = nn.Sequential(
nn.Conv2d(8, 16, 3, 1, 1), # (16,14,14)
nn.ReLU(), # (16,14,14)
nn.MaxPool2d(2) # (16,7,7)
)
self.conv3 = nn.Sequential(
nn.Conv2d(16, 32, 3, 1, 1), # (32,7,7)
nn.ReLU(),
)
self.out = nn.Linear(32 * 7 * 7, 10)
def forward(self, x): # 前向传播 数据的流向 就是神经网络层连接起来,函数名称不能改。
x = self.conv1(x) # 将图像进行展开
x = self.conv2(x)
x = self.conv3(x) # (32,7,7)
x = x.view(x.size(0), -1)
x = self.out(x)
return x
model = CNN().to(device)#把刚刚创建的模型传入到GPU
print(model)
这个模型包含三个卷积层(conv1、conv2、conv3)和一个全连接层(out)。每个卷积层后面都接了一个 ReLU 激活函数和一个最大池化层(MaxPool2d),用于提取特征和降低维度。最后,我们将卷积层的输出展平为一维张量,输入到全连接层进行分类。
四、模型训练与测试
在训练模型之前,我们需要定义损失函数和优化器。
loss_fn = nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写数字识别中一共有10个数字,输出会有10个结果
optimizer = torch.optim.Adam(model.parameters(),lr=0.01)#创建一个优化器,SGD为随机梯度下降算法
##params:要训练的参数,一般我们传入的都是model.parameters()。
##lr: learning_rate 学习率,也就是步长。
这里,我们使用交叉熵损失函数(CrossEntropyLoss)和 Adam 优化器。交叉熵损失函数适用于多分类问题,而 Adam 优化器是一种常用的优化算法,它结合了多种优化方法的优点。
接下来,我们定义训练和测试函数。
def train(dataloader,model,loss_fn,optimizer):
model.train()# 告诉模型,我要开始训练,模型中w进行随机化操作,已经更新w,在训练过程中,w会被修改的
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train() 和 model.eval().
# 一般用法是:在训练开始之前写model.train() 在测试时写上model.eval()。
batch_size_num = 1
for X,y in dataloader: #其中batch为每一个数据的编号
X,y = X.to(device),y.to(device) #把训练数据集和标签传入cpu或GPU
pred = model.forward(X) #.forward可以被省略,父类中已经对次功能进行了设置。自动初始化w
loss = loss_fn(pred,y) #通过交叉熵损失函数计算损失值loss
#Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络
optimizer.zero_grad() #梯度值清零
loss.backward() #反向传播计算得到每个参数的梯度值w
optimizer.step() #根据梯度更新网络w参数
loss_value = loss.item() #从tensor数据中提取数据出来,tensor获取损失值
if batch_size_num % 100 == 0:
print(f"loss:{loss_value:>7f} [number:{batch_size_num}]")
batch_size_num += 1
def test(dataloader,model,loss_fn):
size = len(dataloader.dataset)#10000
num_batches = len(dataloader)#打包的数量
model.eval() #测试,w就不能再更新。
test_loss,correct = 0,0
with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。
for X,y in dataloader:
X, y = X.to(device),y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred,y).item()#test_loss是会自动累加每一个批次的损失值
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
a = (pred.argmax(1) == y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值
b = (pred.argmax(1) == y).type(torch.float)
test_loss /= num_batches #能来衡量模型测试的好坏
correct /= size #平均的正确率
print(f"Test result: \n Accuracy:{(100*correct)}%,Avg loss:{test_loss}")
在训练函数中,我们对每个批次的数据进行前向传播、计算损失、反向传播和参数更新。在测试函数中,我们计算模型在测试数据集上的准确率和平均损失。
最后,我们运行训练和测试代码。
for j in range(10):
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader,model,loss_fn)
这里,我们将模型移动到 GPU(如果可用),并训练 10 个 epoch。每个 epoch 都会遍历一次训练数据集。
运行结果

五、总结
通过这个简单的例子,我们实现了基于 PyTorch 的手写数字识别模型。我们学习了如何加载数据、构建模型、训练和测试模型。虽然这个模型比较简单,但它为我们深入学习深度学习和 PyTorch 提供了一个很好的起点。

















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









