






论文介绍
论文: One-Prompt to Segment All Medical Images
代码: https://github.com/KidsWithTokens/one-prompt
会议与年份:CVPR24
全文概述
本文介绍了一种新的医疗图像分割方法—One-Prompt Segmentation。传统的分割方法需要用户在推理阶段为每个样本提供提示或使用有标签的数据进行迁移学习,但这些方法都存在成本高、效果差等问题。而该方法将单个提示样本与多个任务相关联,通过一个前向传递就可以处理未见过的任务。作者在64个开源医学数据集上训练了单提示模型,并收集了超过3000个由临床医生标注的提示。实验结果表明,该方法在零样本分割方面表现优异,优于其他相关方法。代码和数据已在GitHub上发布。
全文贡献
介绍了一种新颖的单提示分割方法,这是一种强大的但成本低的通用医学图像分割范式。
提出了一种独特的One-Prompt Former模型来融合多个特征尺度上的提示模板特征和查询特征。
设置了四种不同的提示类型以更好地引导特殊医疗目标,从而满足各种临床实践需求。
收集了一个包含78个开源数据集的大规模集合用于训练和测试该模型,并且标注了超过3000个样本,其中包含了由医生提供的提示。
方法
One-Prompt Former主要由注意力块组成,其结构包含两个并行的分支:查询分支(处理查询图像特征)和模板分支(处理模板图像特征以及提示信息)。这两个分支协同工作,将提示信息有效地融入到查询图像的分割过程中。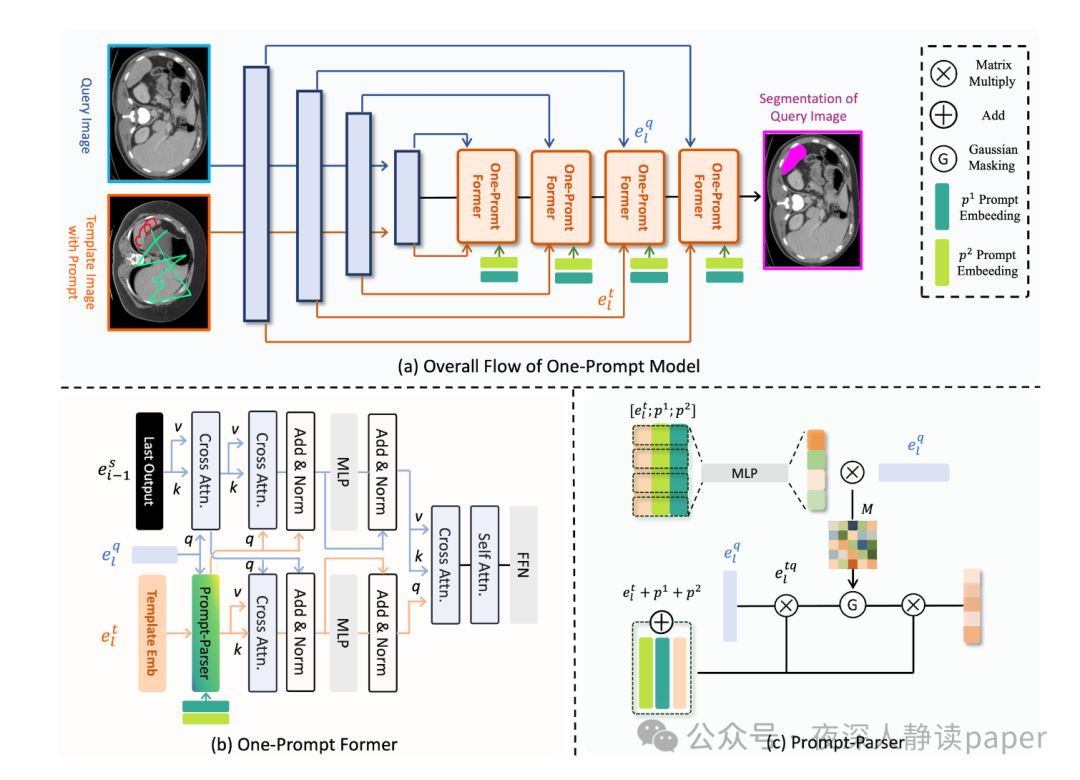
One-Prompt Former
One-Prompt Former块主要通过交叉注意力将查询分支和模版分支的特征进行融合。
对于查询分支,它接收来自编码器的多尺度查询图像特征作为查询(Query),并使用上一One-Prompt Former块的输出嵌入作为键(Key)和值(Value)。这个过程允许模型将查询图像的特征与之前处理过的特征进行对比,从而更好地理解和整合全局信息。
对于模版分支,则在开始加入了Promt-Parser模块,剩下的结构和查询分支一样。
Prompt-Parser
这一部分其实作者说的并不清晰,下图是Prompt-Parser代码中的的forward部分。下面说一下我的个人理解,如果有读者明白的话,可以评论区留言。前四行的意思大概是说,将讲过MLP后的模板图像、提示嵌入二者与查询图像相乘得到attention。第四行是说直接将查询图像与模板图像、提示嵌入相乘。第五行是说我这两个取个最大值。最后将最大值与模板图像、提示嵌入相乘得到要查询的区域。
实验分析
精度对比
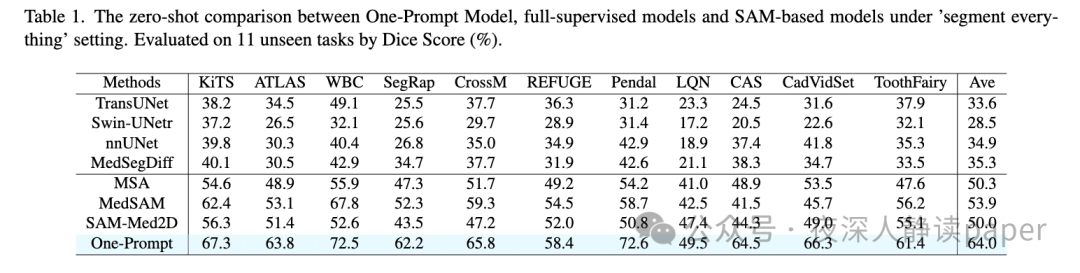
可视化对比
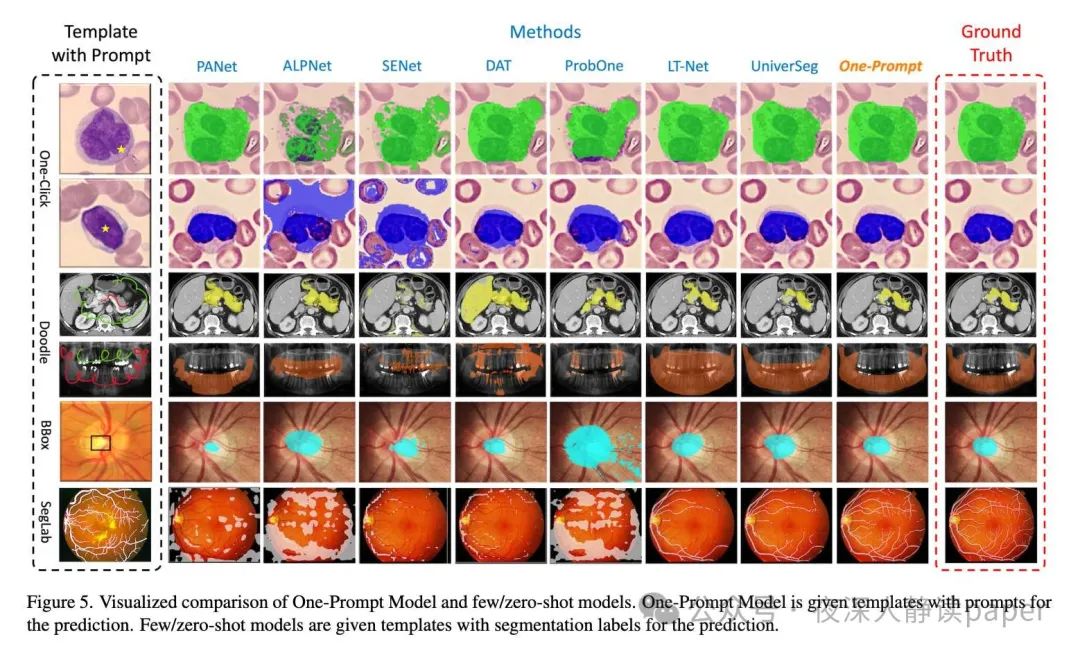


















 76
76

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











