






论文介绍
论文: OmniMedVQA: A New Large-Scale Comprehensive Evaluation Benchmark for Medical LVLM
代码: https://github.com/OpenGVLab/Multi-Modality-Arena
会议与年份:CVPR24

全文概述
本篇论文介绍了针对医疗领域的视觉问答任务(Medical VQA)的新基准测试集——OmniMedVQA。该测试集由来自73个不同医学数据集的超过5万张真实医学图像组成,涵盖了12种不同的模态和20多个解剖学区域。通过实验发现,现有的大型视觉语言模型(LVLM)在解决这些医疗视觉问答问题时表现不佳,甚至专门用于医学领域的LVLM也比通用模型表现差。这表明需要更灵活、更强大的LVLM来应对生物医学领域的需求。本文的研究结果不仅揭示了现有LVLM对真实医学图像理解的局限性,还突显了OmniMedVQA数据集的重要性。作者们已经将代码和数据集公开发布,供其他研究人员使用。
全文贡献
我们提出OmniMedVQA,这是一个针对医疗领域的大型且全面的视觉问答基准。OmniMedVQA包含12种不同的模态,并涵盖了超过20个独特的解剖区域,为评估LVLM在应对医疗挑战方面的基本能力建立了综合基准。
我们对包括8个通用领域LVLM和4个专门针对医疗应用设计的LVLM在内的12种不同类型的LVLM进行了全面评估。据我们所知,这是迄今为止针对医疗领域的最全面的LVLM评估。
我们的评估揭示了几个创新见解,并为未来改善LVLM以适应医疗应用提供了宝贵的指导。
数据集
数据集构建过程
OmniMedVQA数据集的构建基于73个不同的医学数据集,这些数据集覆盖了12种不同的成像模态和超过20个解剖区域。构建过程中,首先收集了大量的医学分类数据集,然后利用GPT的强大上下文推理能力,将这些数据转换为视觉问答(VQA)格式 。此外,为了增加数据集的多样性和评估能力,还通过ChatGPT-3.5 API对问题进行了重新表述,并生成了错误选项,从而构建了多选题问答对。
数据集特点
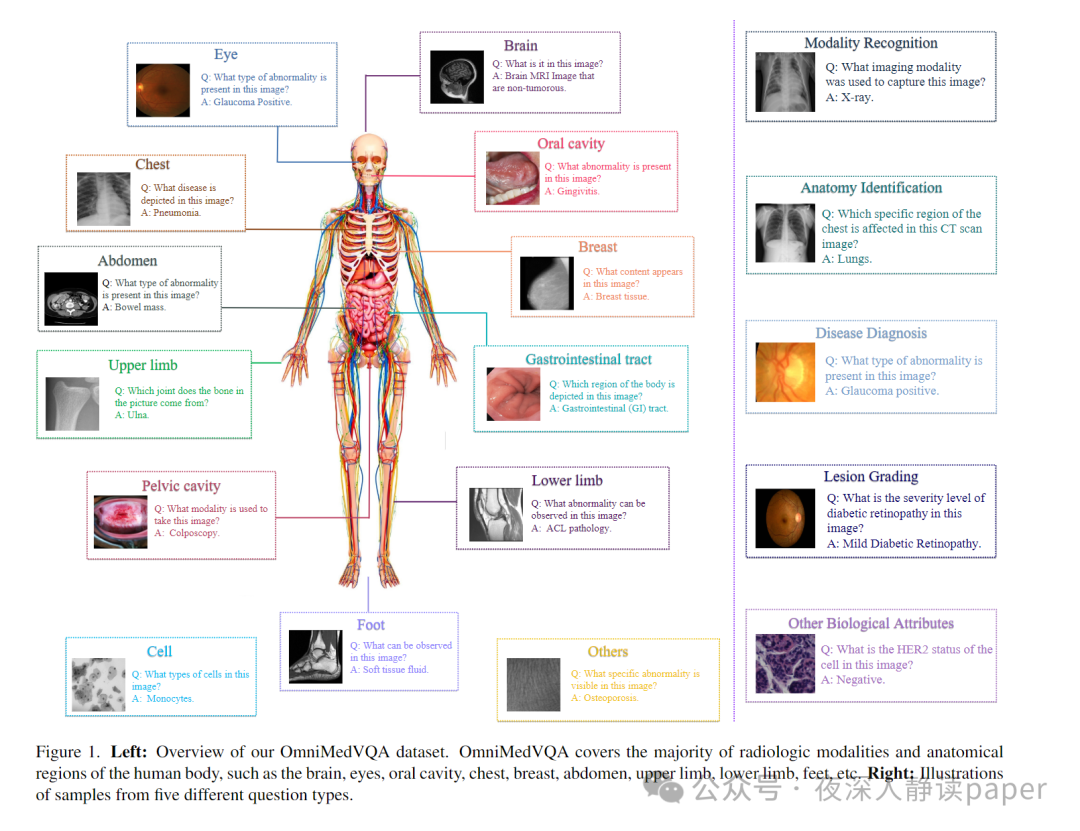
OmniMedVQA数据集是一个大规模、多样化且全面的医学视觉问答基准,包含118,010张来自真实医疗场景的图像,覆盖12种不同成像模态和20多个解剖区域,旨在评估大型视觉语言模型在医学领域的性能,其多模态和多区域的特点使其成为测试和改进LVLMs在医学影像理解和问答能力的重要资源。
数据集所涉及到的12中模态
OmniMedVQA数据集包含了以下12种不同的成像模态:
Colposcopy(宫颈检查):319张图像,338个QA项。
CT(计算机断层扫描):14,457张图像,15,836个QA项。
Digital Photography(数字摄影):2,308张图像,2,786个QA项。
Fundus Photography(眼底摄影):10,108张图像,10,815个QA项。
Infrared Reflectance Imaging(红外反射成像):9,477张图像,9,785个QA项。
MR(磁共振成像):31,917张图像,32,705个QA项。
Optical Coherence Tomography(光学相干断层扫描):3,791张图像,4,646个QA项。
Dermoscopy(皮肤镜检查):5,967张图像,6,762个QA项。
Endoscopy(内窥镜检查):1,432张图像,1,877个QA项。
Microscopy Images(显微镜图像):19,785张图像,21,743个QA项。
X-Ray(X射线):7,594张图像,9,711个QA项。
Ultrasound(超声检查):10,855张图像,10,991个QA项评估过程
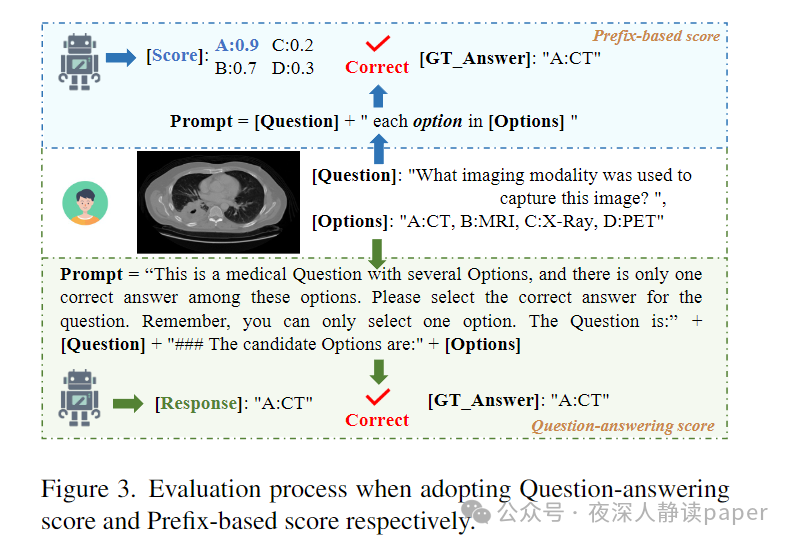
在论文中,评估过程旨在全面测试12种不同的大型视觉语言模型(LVLMs)在OmniMedVQA数据集上的性能,其中包括8个通用领域模型和4个专门针对医疗领域的模型。评估涉及构建输入提示,将问题和候选选项结合,并传递给LVLMs以生成响应。为了全面评估模型性能,采用了两种评估指标:问答得分和基于前缀的得分。问答得分直接衡量模型选择与真实答案的匹配程度,而基于前缀的得分则衡量模型对每个选项生成文本内容的可能性,反映模型的内在知识水平。
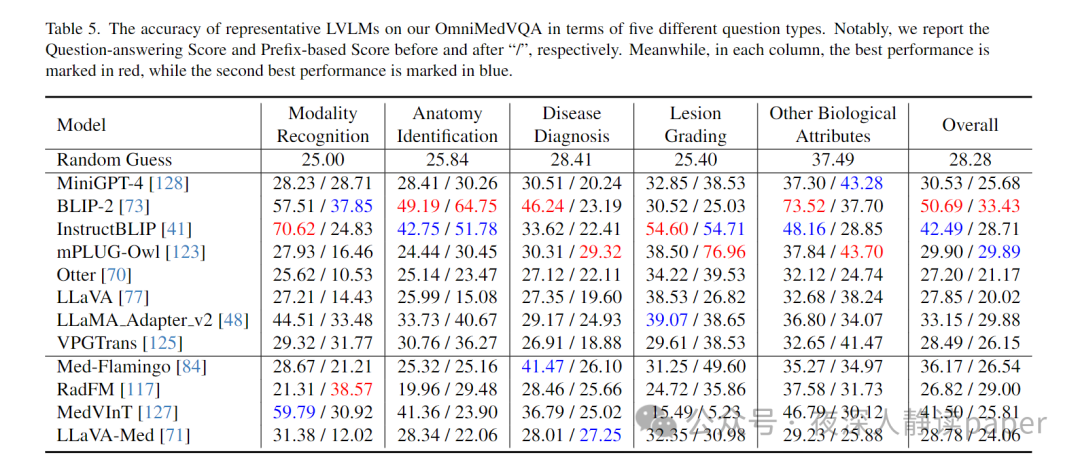
实验分析
精度对比


















 182
182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











