






【痛点共鸣】
你是否遇到过这些烦恼?刚接触YOLOv8就被复杂的开发环境劝退?在Anaconda配置中频频报错?使用PyCharm时遇到各种依赖冲突?标注工具选择困难导致训练效率低下?......
【价值承诺】
"本文针对深度学习初学者的核心痛点,手把手带你完成:① 基于Anaconda的Python虚拟环境搭建 ② PyCharm开发环境配置 ③ X-AnyLabelin高效标注实战 ④ 训练过程中的10大高频报错解决方案 ⑤ YOLOv8模型训练方法 ⑥pt模型转换onnx模型........
【阅读收益】
"读完本文你将获得:
√ 独立搭建YOLOv8开发环境的能力(Anaconda+PyCharm+环境配置)
√ 掌握工业级数据标注技巧
√ 快速定位并解决90%的常见报错
√ 完整的模型训练调参方法论
√ X-AnyLabelin软件的使用
【引导行动】
"无论你是刚入门计算机视觉的学生,还是需要快速落地的算法工程师,这篇耗时3个月整理的万字教程,都将成为你攻克YOLOv8训练难题的终极指南。现在开始,跟我们一起踏上高效的目标检测实战之旅!"
关于yolov8准备工作,下载Anaconda+PyCharm
一.下载Anaconda
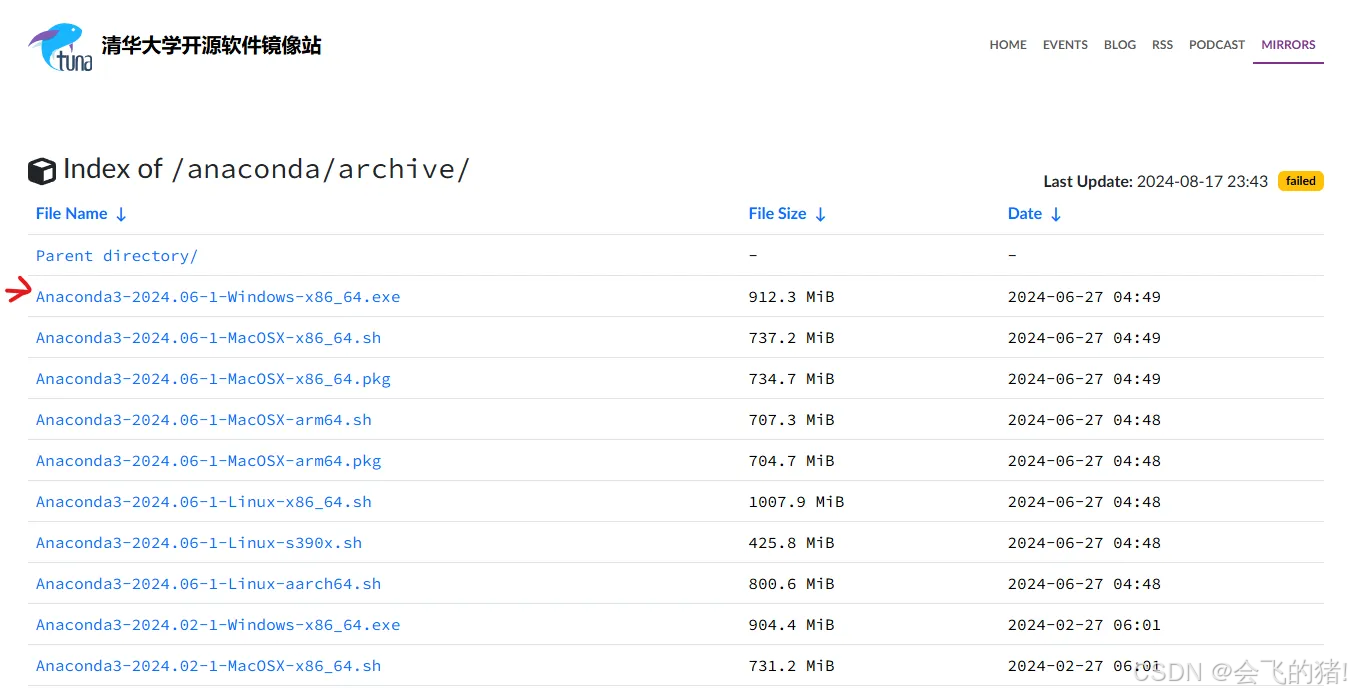
1.到清华大学开源软件镜像站,找到Anaconda,下载最新版本
下载链接:
(我这里选择的是当时最新的版本2024-06-1-Windons-x86_64版本的,这里根据自己的电脑系统选择安装包,假如说: 是linux系统,就选择linux系统安装包.是windows系统选择windows系统安装包)安装步骤简单,不做演示,自行下载.下载好后,到第二步,激活Anaconda.配置环境变量.
2.激活 Anaconda
首先在终端(Terminal,也就是"命令提示符")运行下面的命令生成 anaconda的 .condarc配置文件:
1.开始菜单 -> Windows 系统 -> 命令提示符
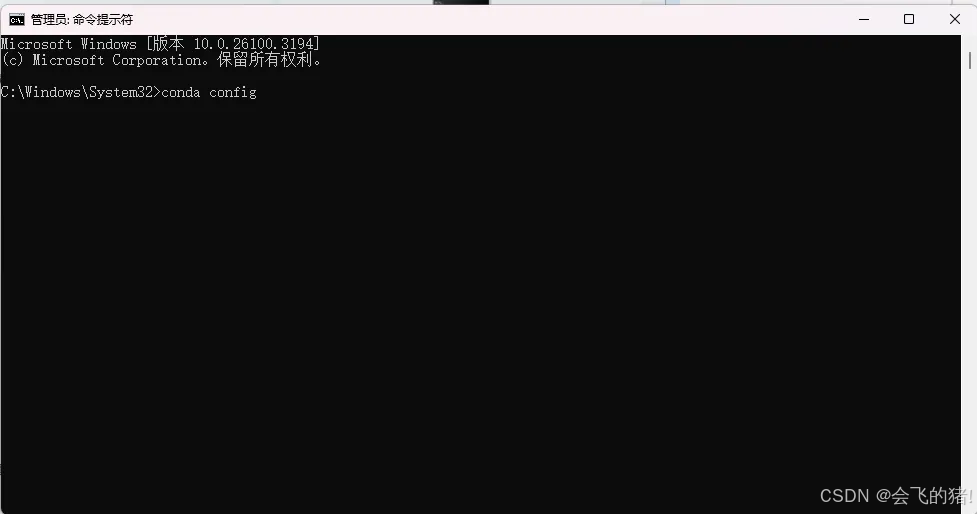
2.在 搜索框 输入"命令提示符" 后搜索,找到命令提示符以管理员身份运行,打开后,输入指令: conda config
//激活指令
conda config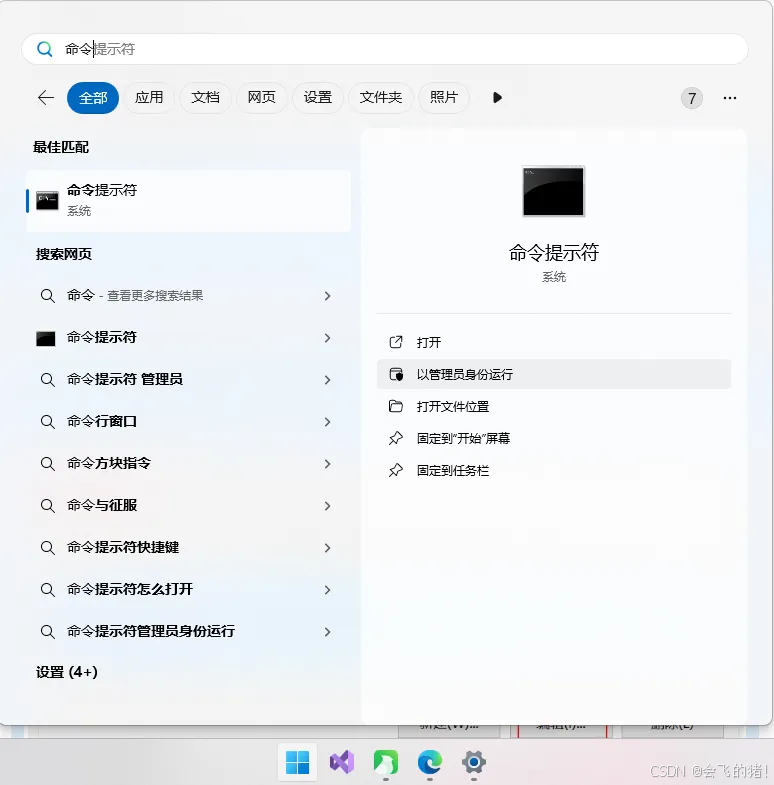
3.报错:"conda 不是内部或外部命令,也不是可运行的程序"的 解决方案.
报错原因:环境没有配置,需要配置环境变量
(1)点击“我的电脑”右键属性--高级系统设置 --环境变量
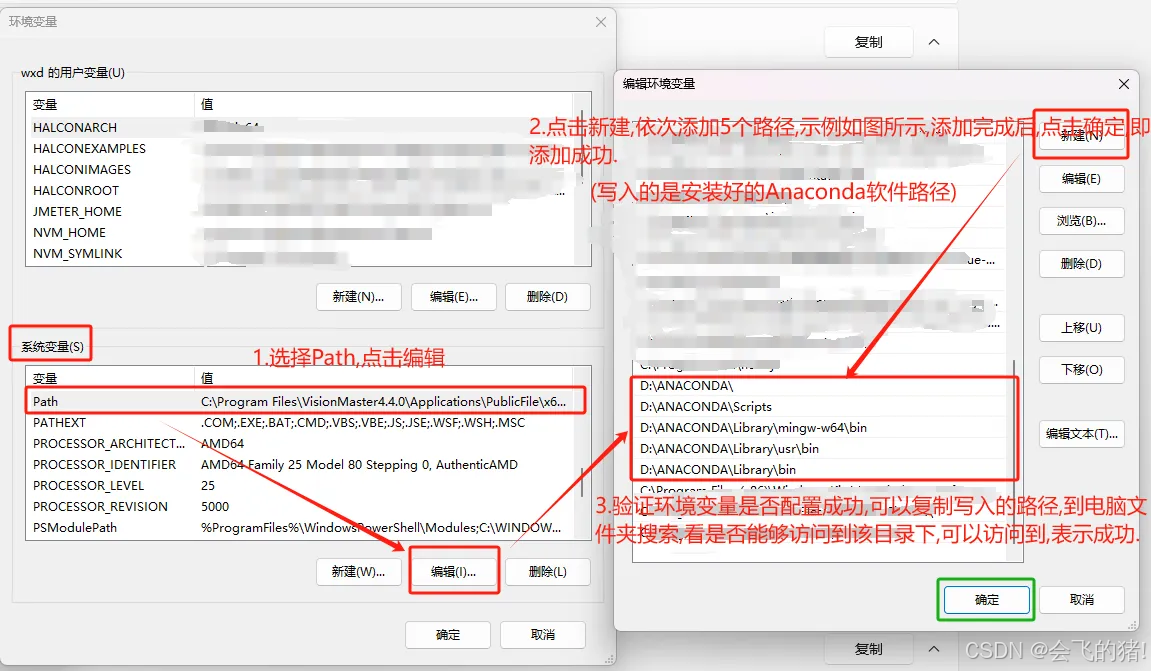
E:\你安装Anaconda的路径\Anaconda3
E:\你安装Anaconda的路径\Anaconda\Scripts
E:\你安装Anaconda的路径\Anaconda\Library\mingw-w64\bin
E:\你安装Anaconda的路径\Anaconda\Library\usr\bin
E:\你安装Anaconda的路径\Anaconda\Library\bin配置好环境变量再次执行激活指令:conda config,没有报错即可.
二.下载PyCharm
下载链接:
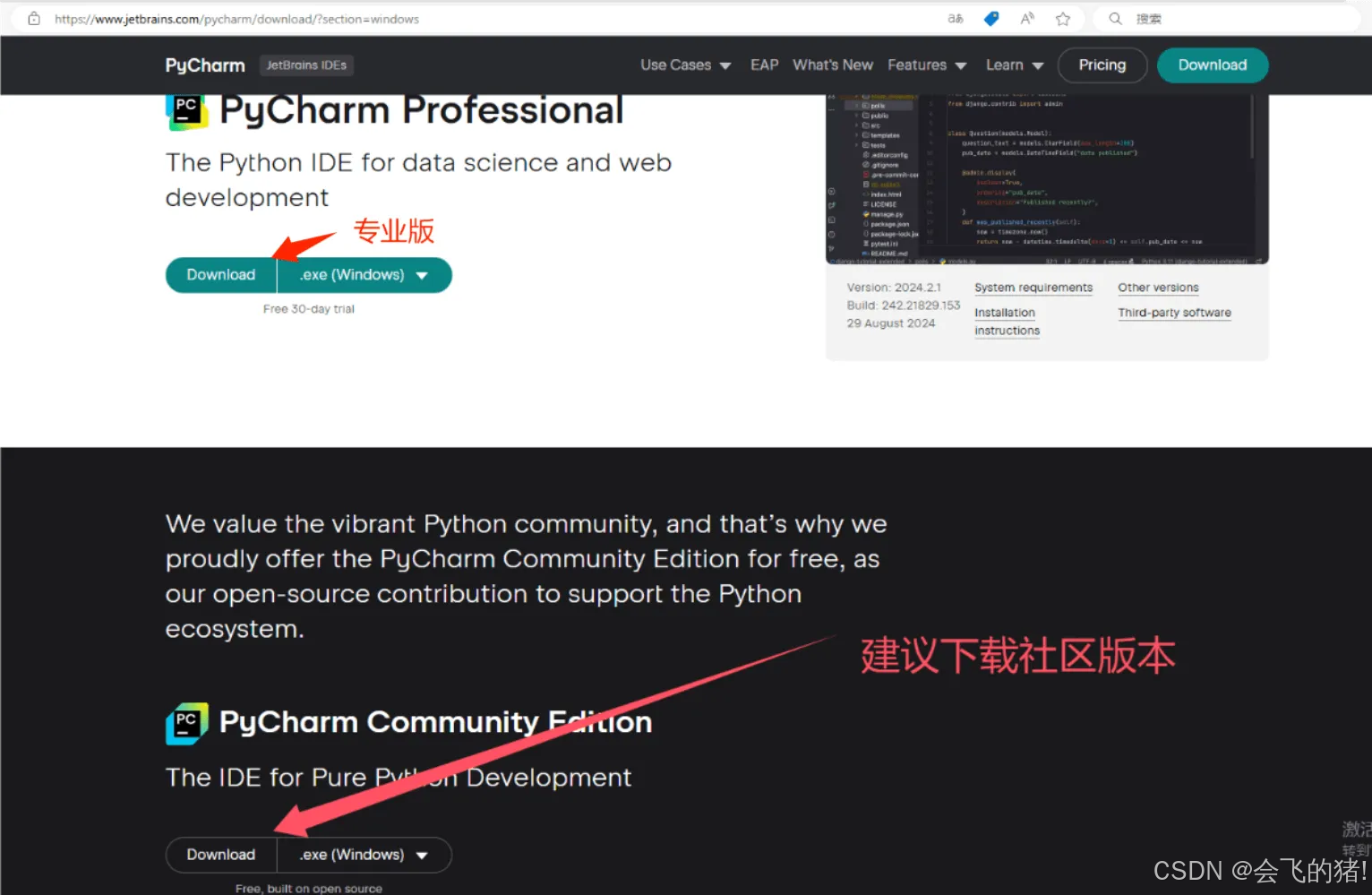
下载社区版本即可.步骤简单.安装即可.
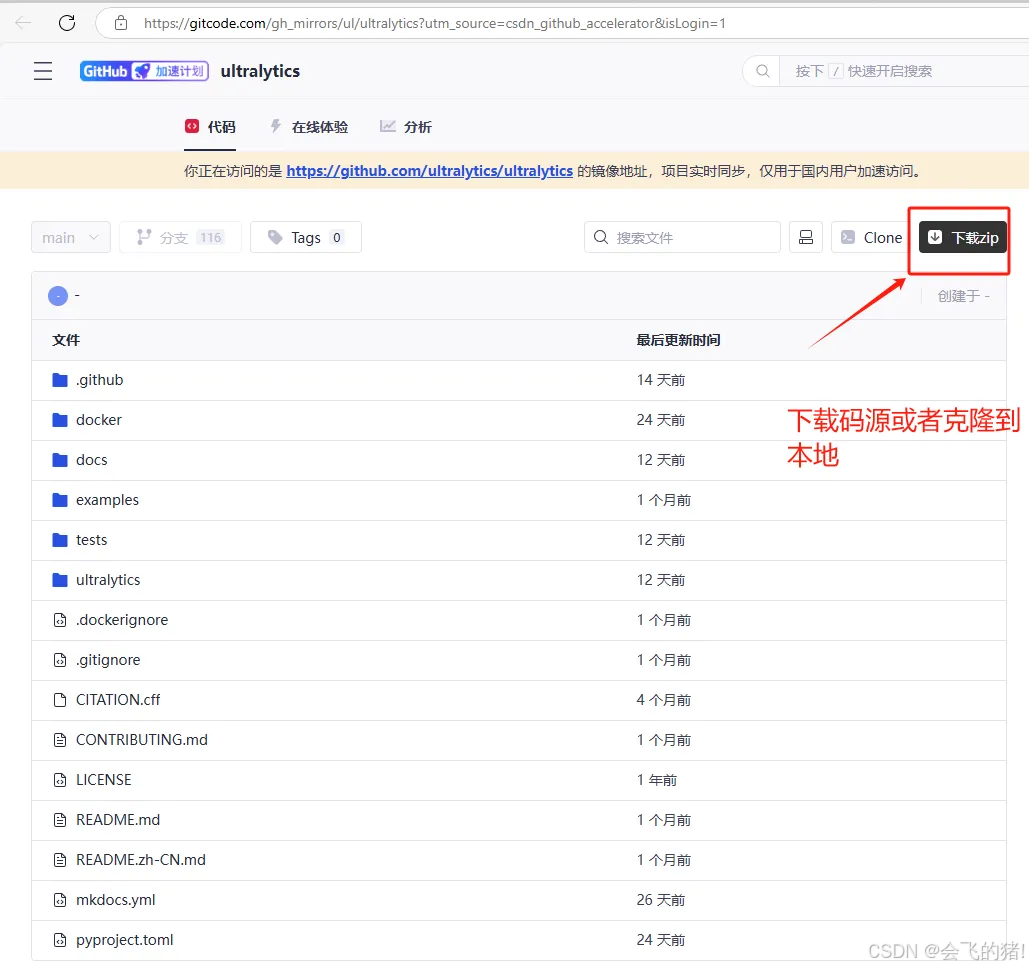
一.到Yolov8下载源代码
下载码源:
二.配置环境
1.打开PyCharm软件后,接着打开Yolov8源码文件夹,如图所示:
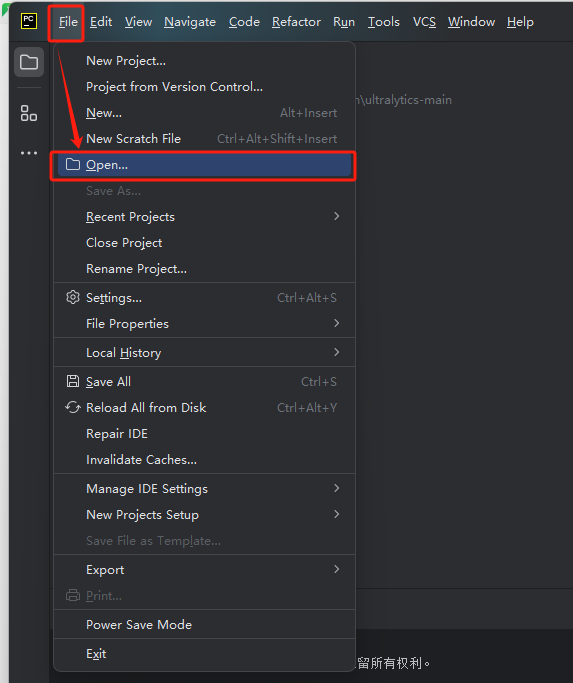
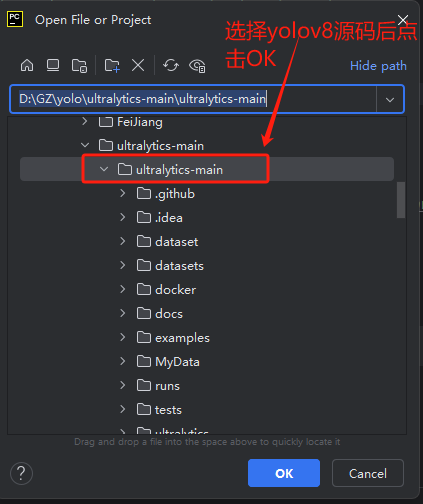
打开后的界面:
2.在PyCharm软件左下角打开终端后,使用命令创建一个yolov8虚拟环境
//创建yolov8虚拟环境指令
conda create -n yolov8 python=3.10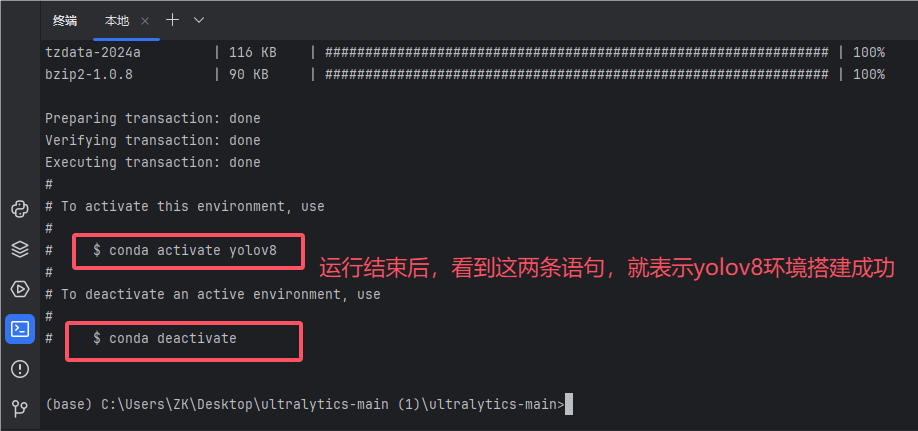
3.切换yolov8的环境
//切换yolov8的环境
conda activate yolov8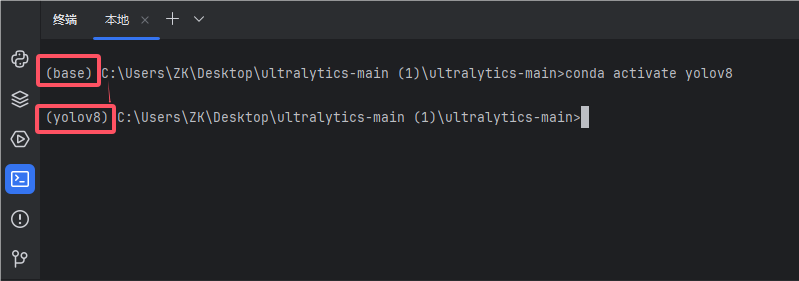
4.为了后续快速下载,Anaconda以及Pip配置清华镜像源
#添加镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
//Pip配置清华镜像源 永久配置
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
//
//查看镜像源
conda config --show channels
删除添加源,恢复默认源
conda config --remove-key channels5.安装yolov8所需要的ultralytics和yolo包
pip install ultralytics
pip install yolo6.安装PyTorch
1.到PyTorch官网:PyTorch
2.选择电脑适配的版本,复制代码在yolov8的环境下运行。
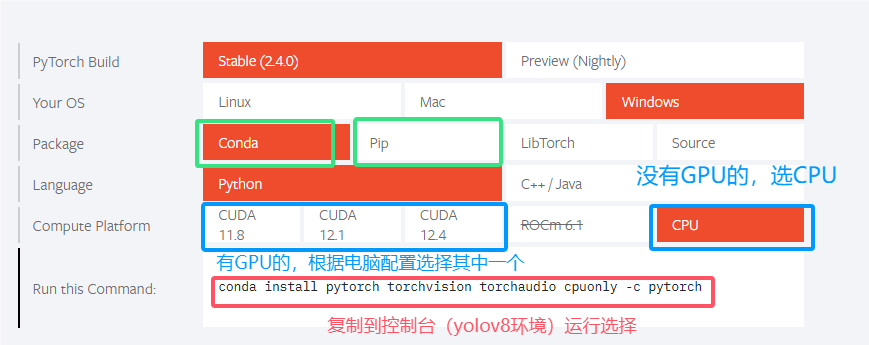
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia若不知道自己的电脑需要什么版本,怎么查看??
1. 打开Anaconda Prompt以管理员身份运行,打开后输入指令: nvidia-smi ,查看CUDA的驱动API版本
//查看CUDA的驱动版本指令
nvidia-smi 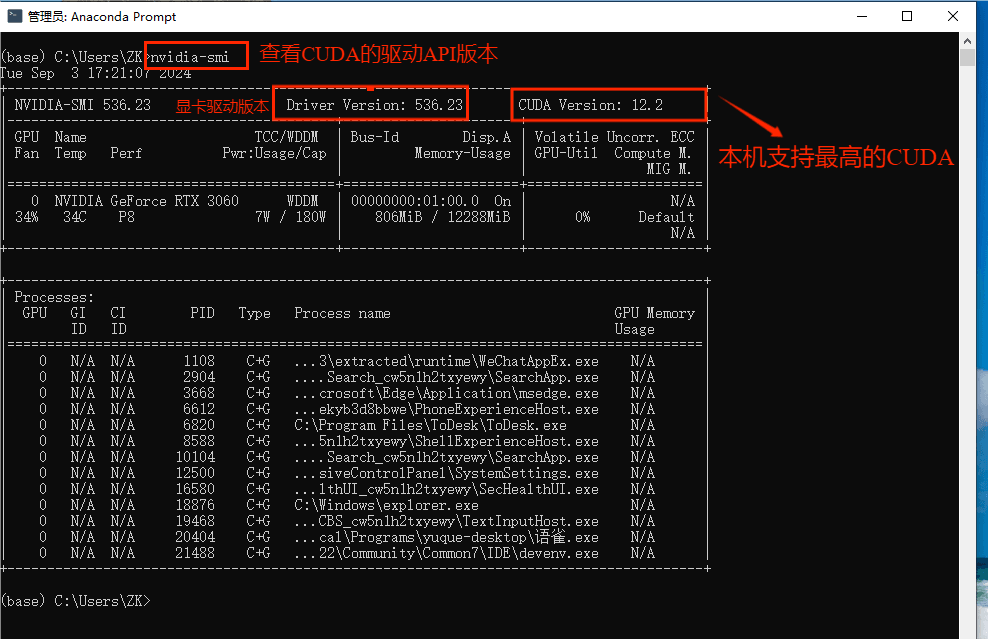
7.验证环境配置是否成功
yolo predict model=yolov8n.pt source='ultralytics/assets/bus.jpg'三.配置环境就常见的报错
(1).ImportError: DLL load failed while importing _imaging: 找不到指定的模块。
解决方法: 重新安装 Pillow 包
//删除 Pillow 包
pip uninstall Pillow
//重新安装 Pillow 包
pip install Pillow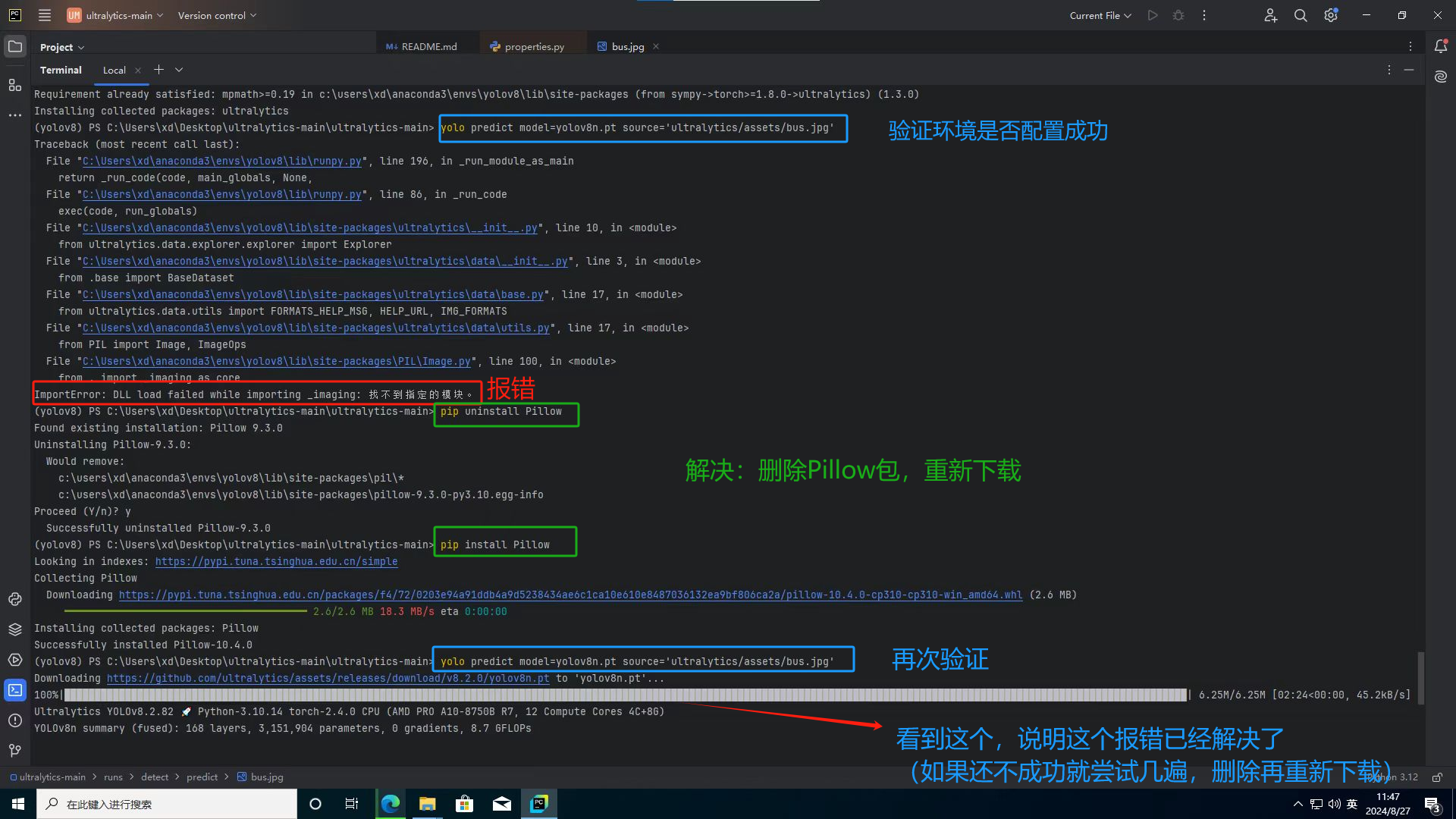
(2).ImportError: cannot import name 'Image' from 'PIL' (unknown location)
解决方法: 重新安装 Pillow 包
//删除 Pillow 包
pip uninstall Pillow
//重新安装 Pillow 包
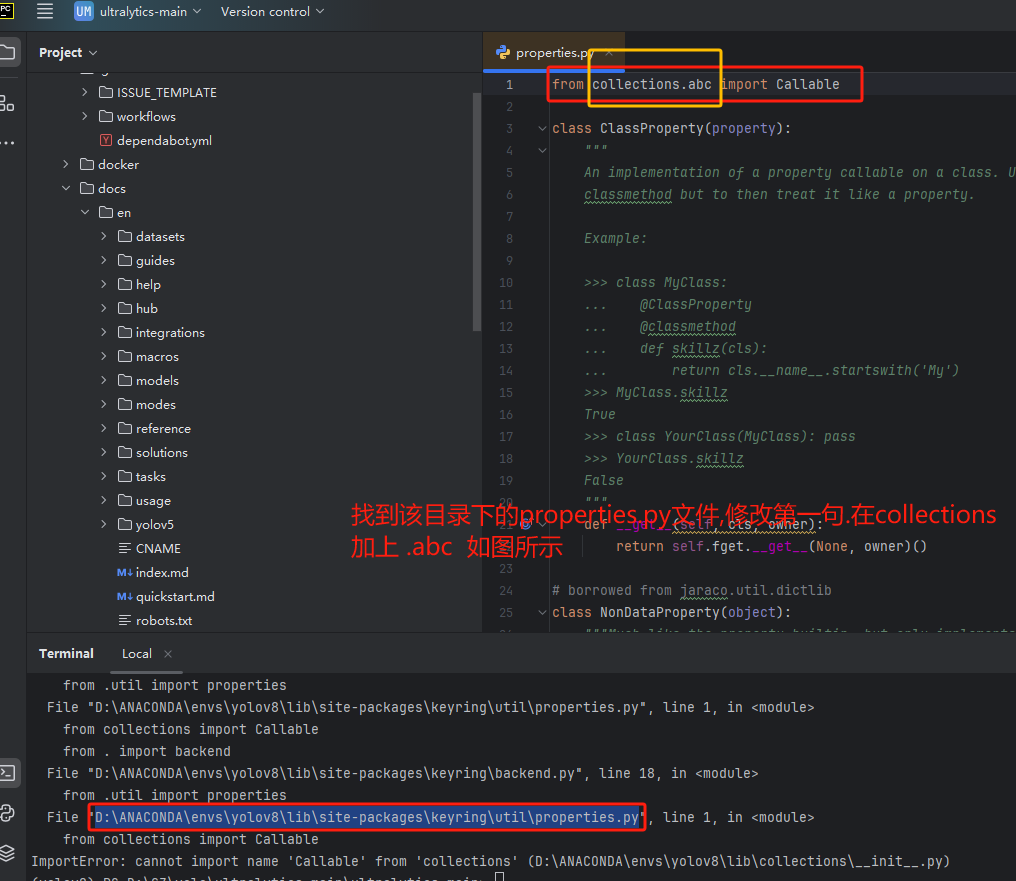
pip install Pillow(3).ImportError: cannot import name 'Callable' from 'collections'
报错图片:
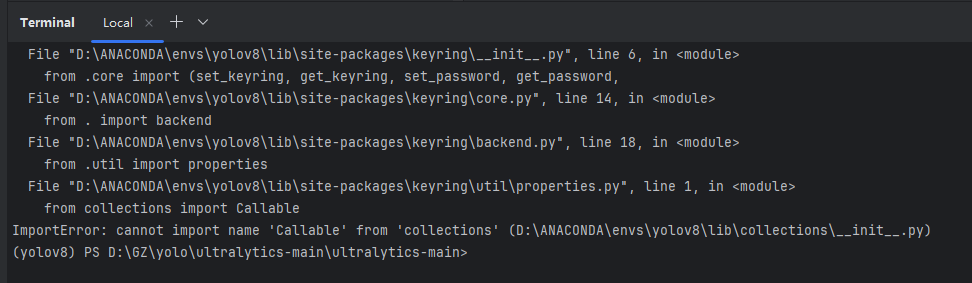
解决方法(如图所示):
(4).Try 'yolo -h' for help. Error: No such command 'predict'.
解决方法:
先执行 pip uninstall ultralytics
然后重新 pip install ultralytics 即可
(5).OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized. OMP: Hint This means that ......
报错提示消息:
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized. OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.
报错图:

解决办法:
1.右下角找到当前环境,如图所示:例如路径为 C:\ProgramData\anaconda3\envs\yolov8
复制这个路径,去在电脑文件粘贴这个路径,然后在此目录下查找 libiomp5md.dll 删除掉
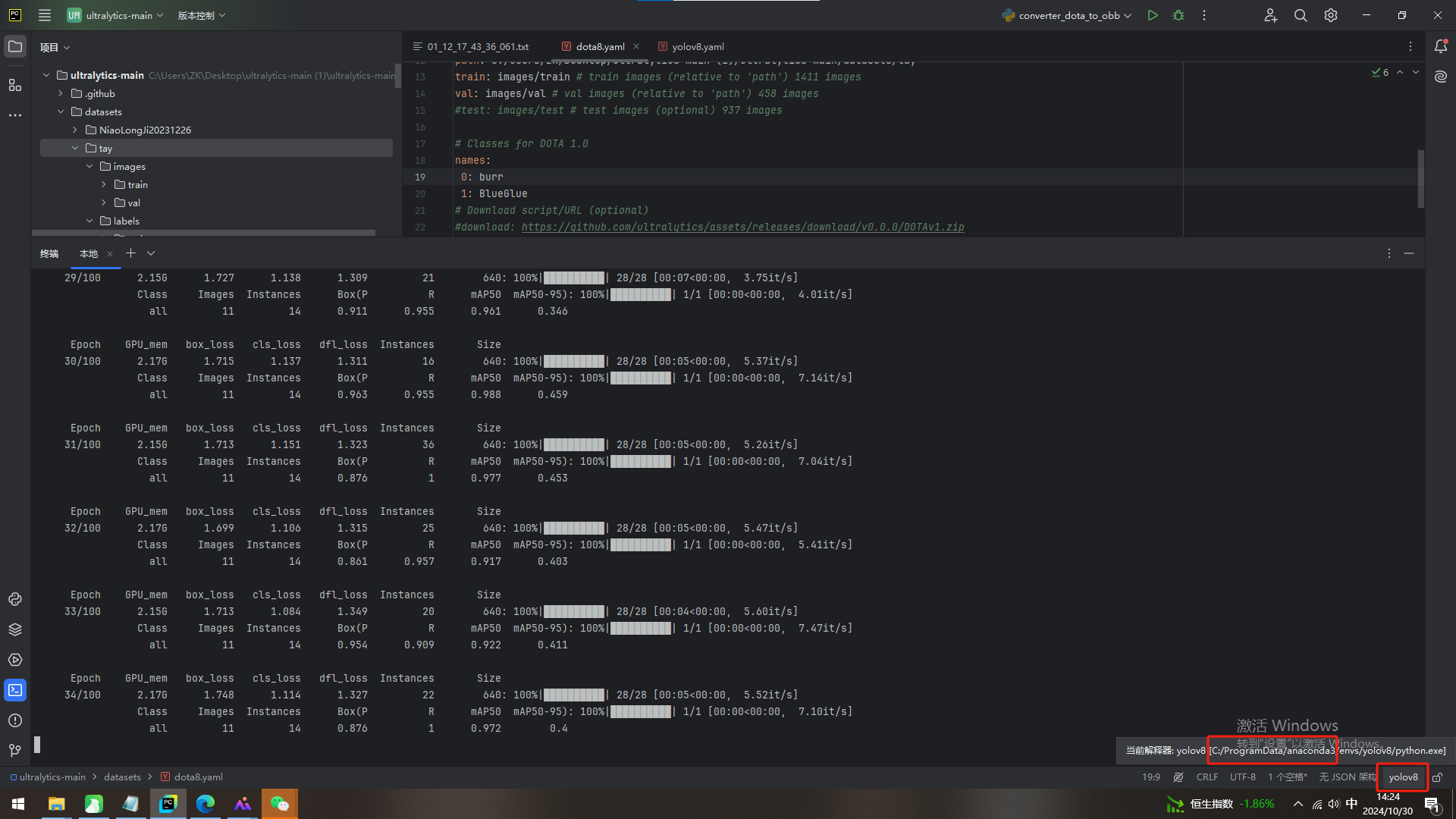
在你安装的anaconda的环境下存在两个libiomp5md.dll文件。所以直接去虚拟环境的路径下搜索这个文件,可以看到在环境里有两个dll文件:

其中第二个是torch路径下的,第一个是虚拟环境本身路径下的,转到第一个目录下把它剪切到其他路径下备份就好(最好把路径也备份一下)
四.数据集制作
一.数据集准备,关于X-AnyLabelin软件的使用
1.下载地址:
通过网盘分享的文件:X-AnyLabeling-CPU.exe链接: https://pan.baidu.com/s/1f_fPhnyhPIA91NmO2g73_w 提取码: m9yc
2.中英文切换:
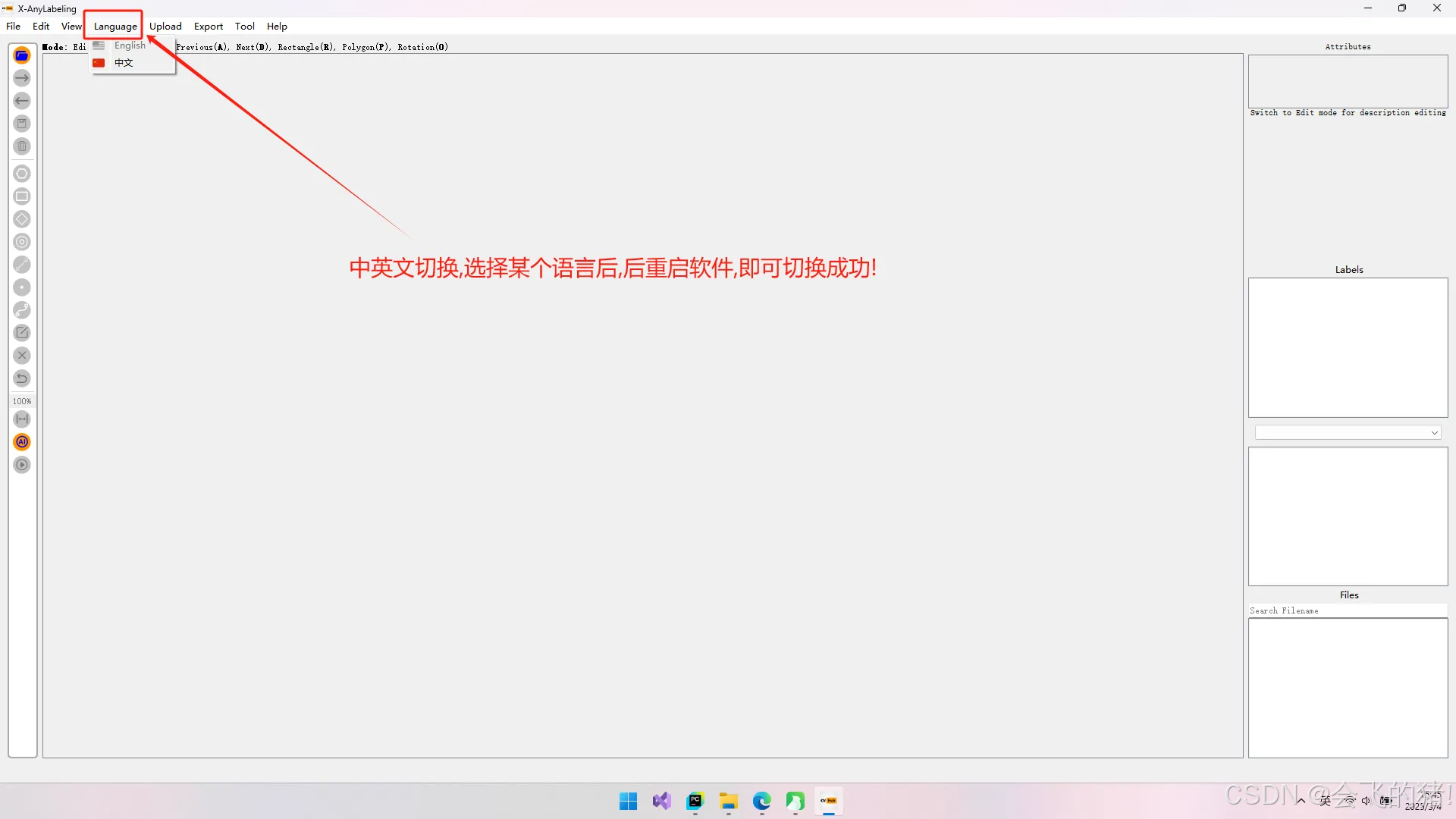
3.如何使用X-AnyLabelin软件标注图片??
1.打开X-AnyLabelin软件.选择打开文件夹,选择需要标注图片的文件夹.
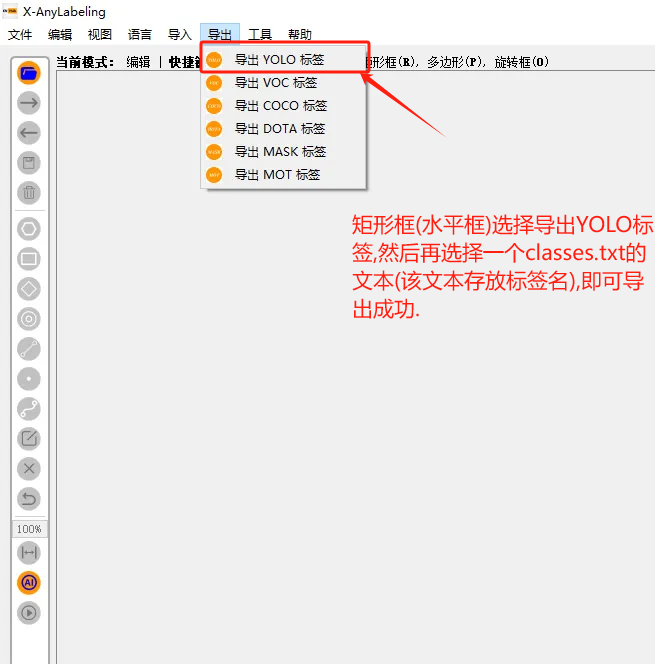
2.水平框(矩形框):(步骤如图所示)
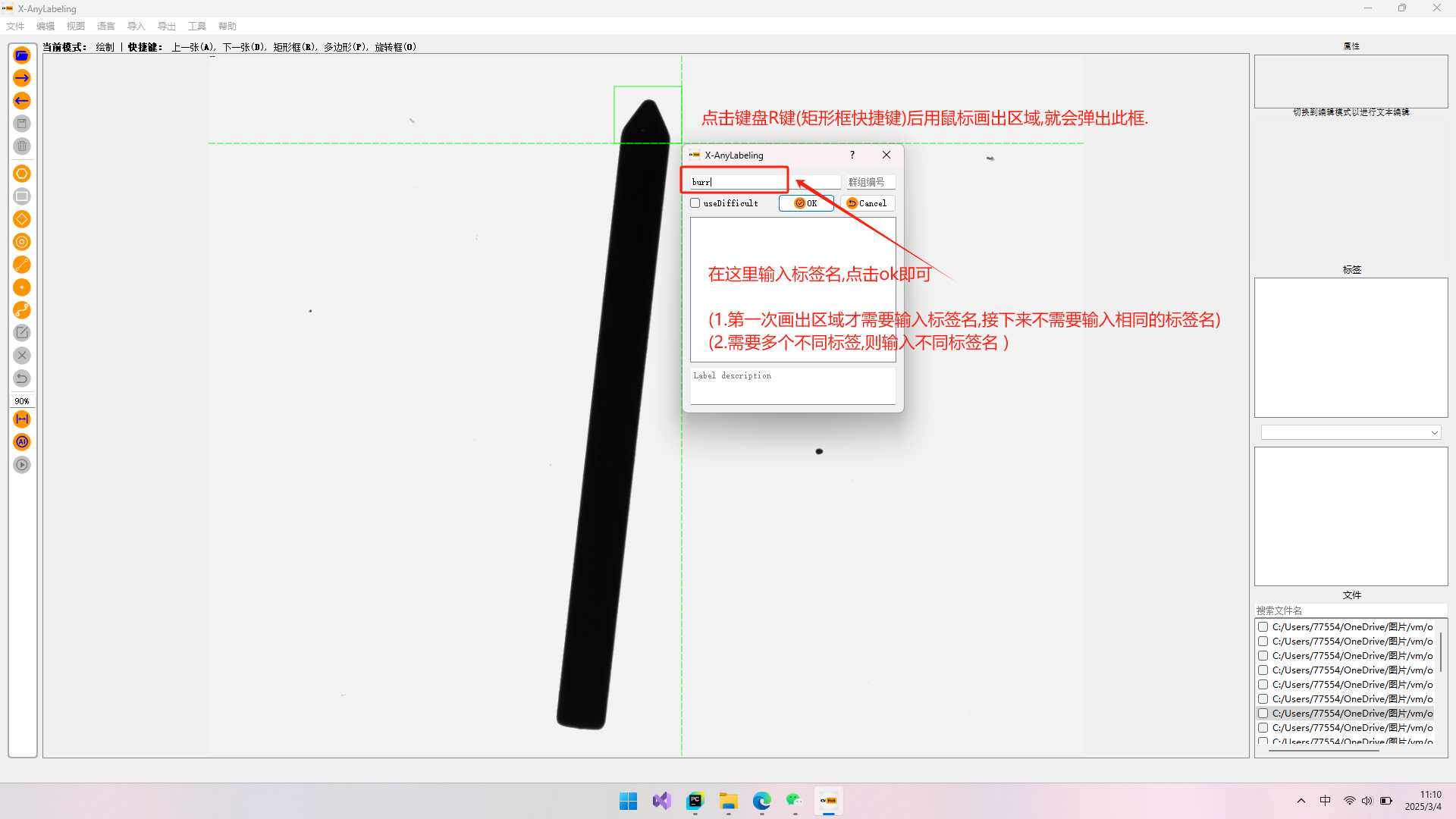
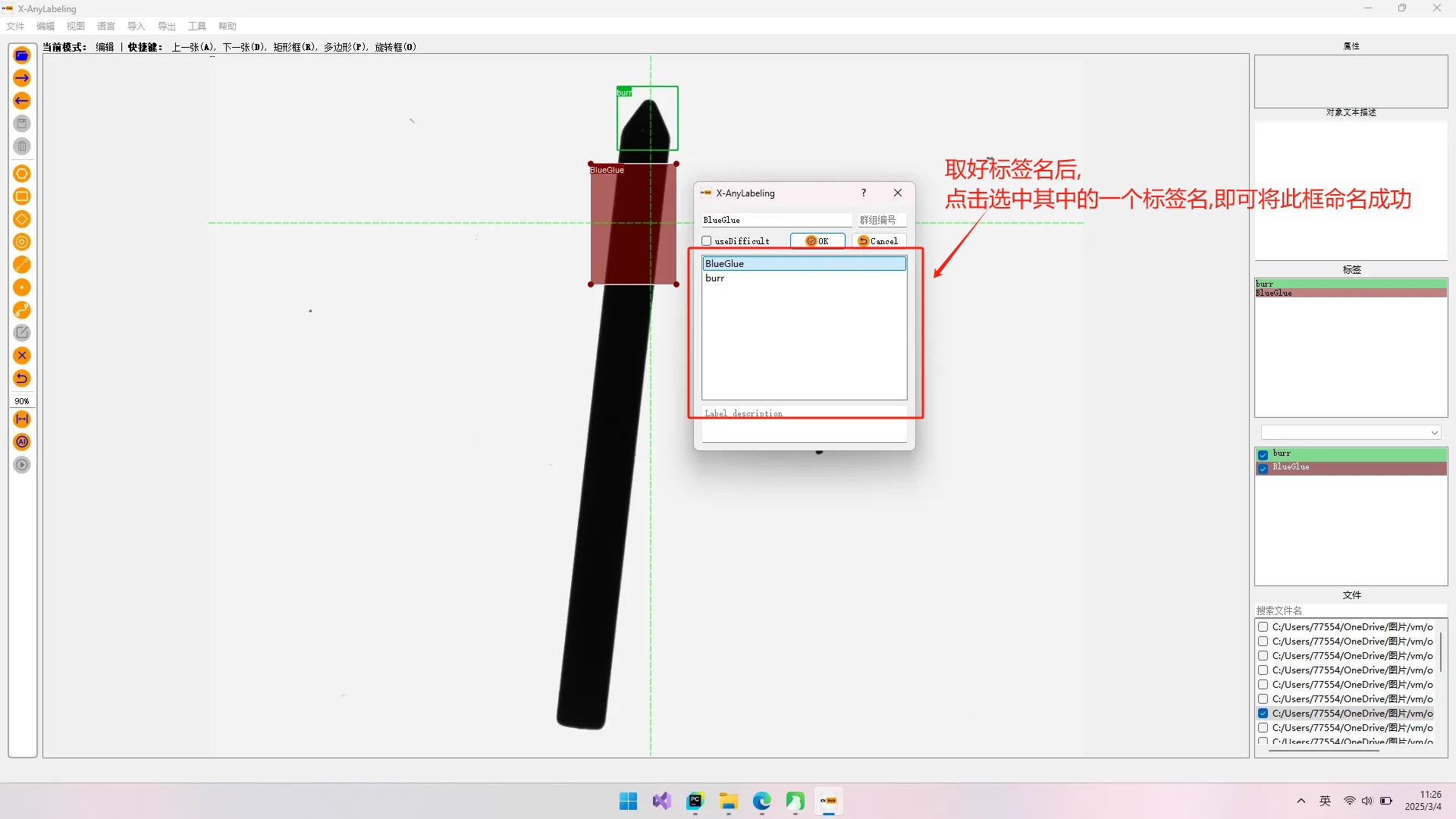
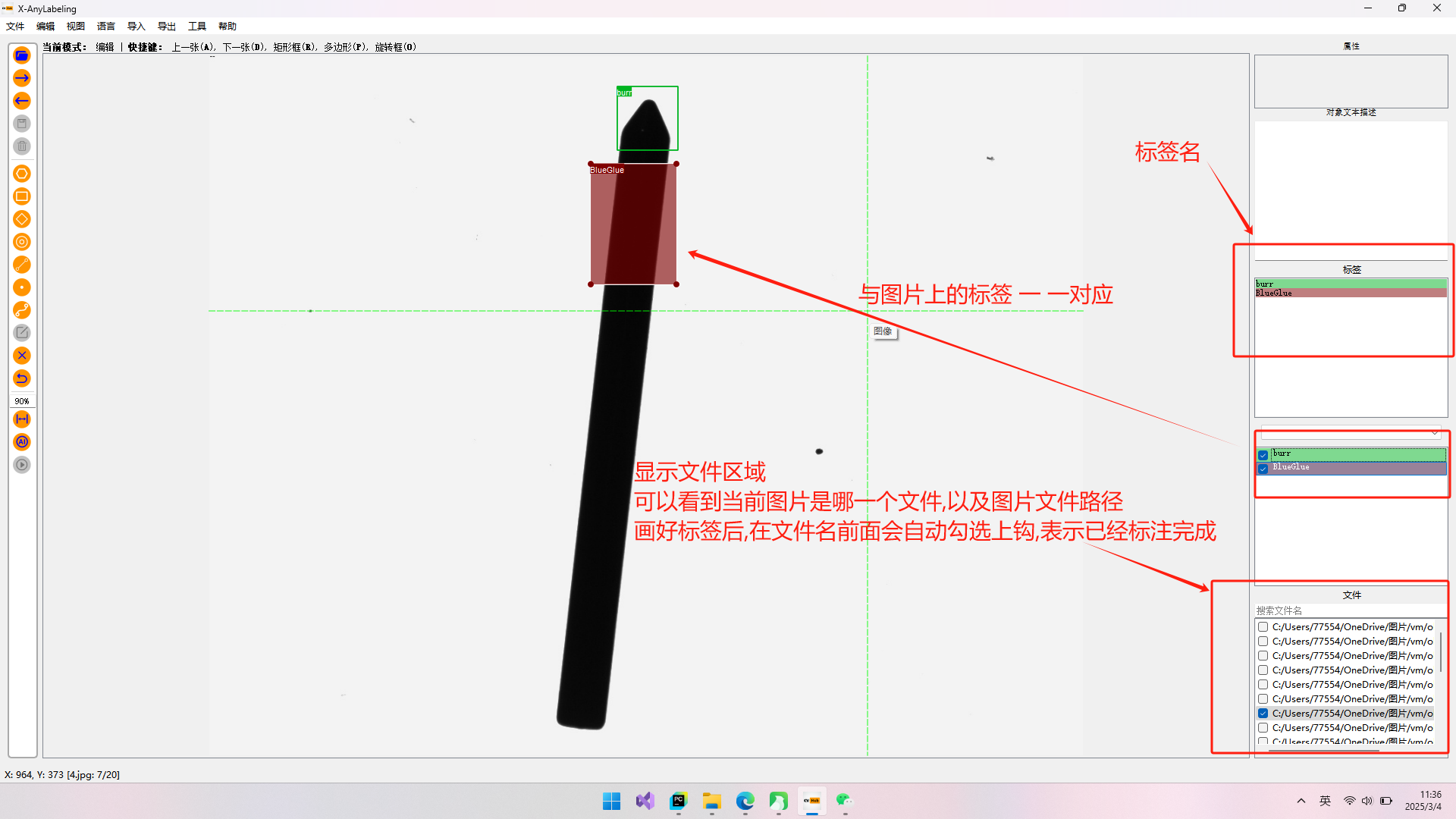
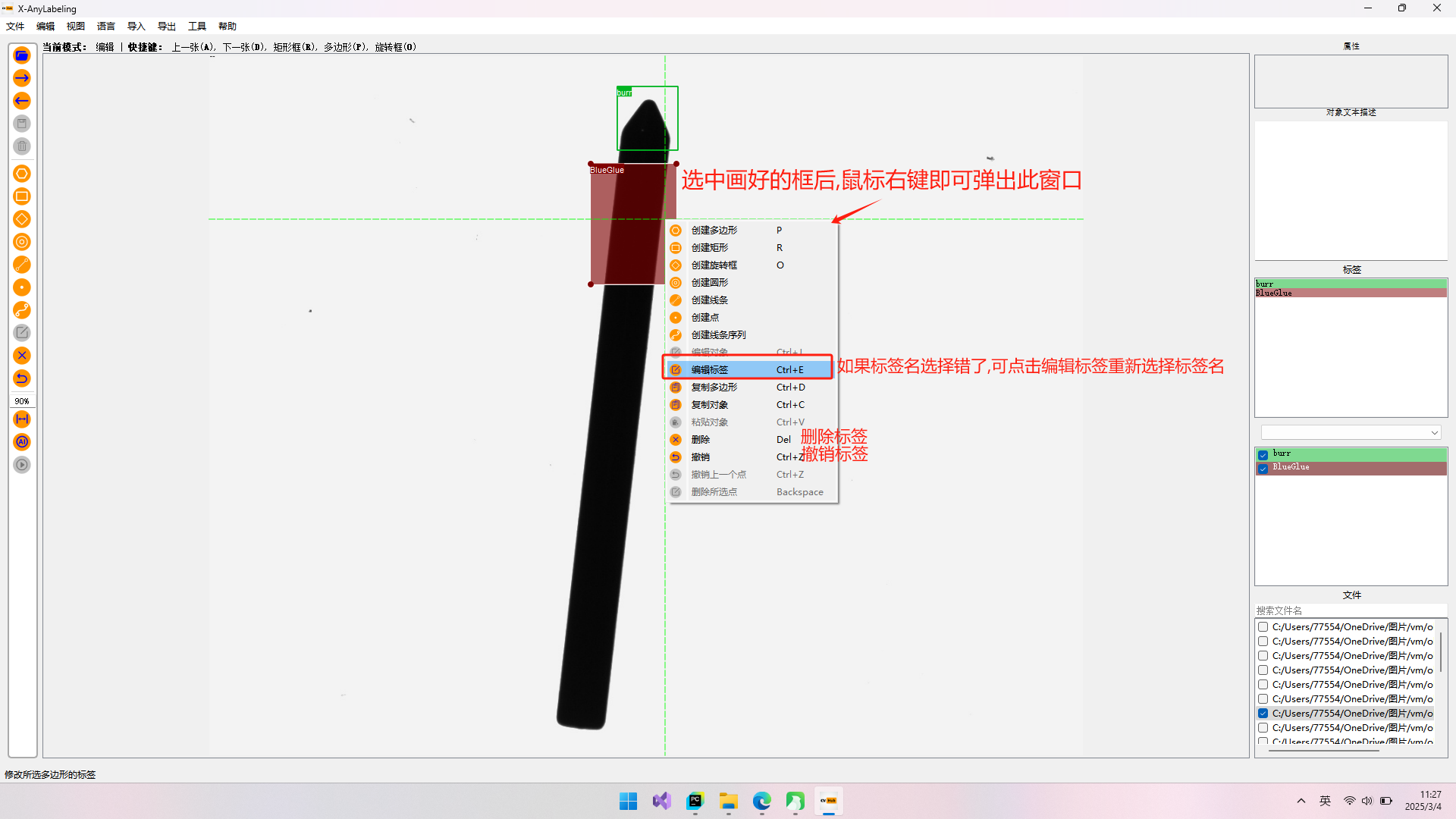
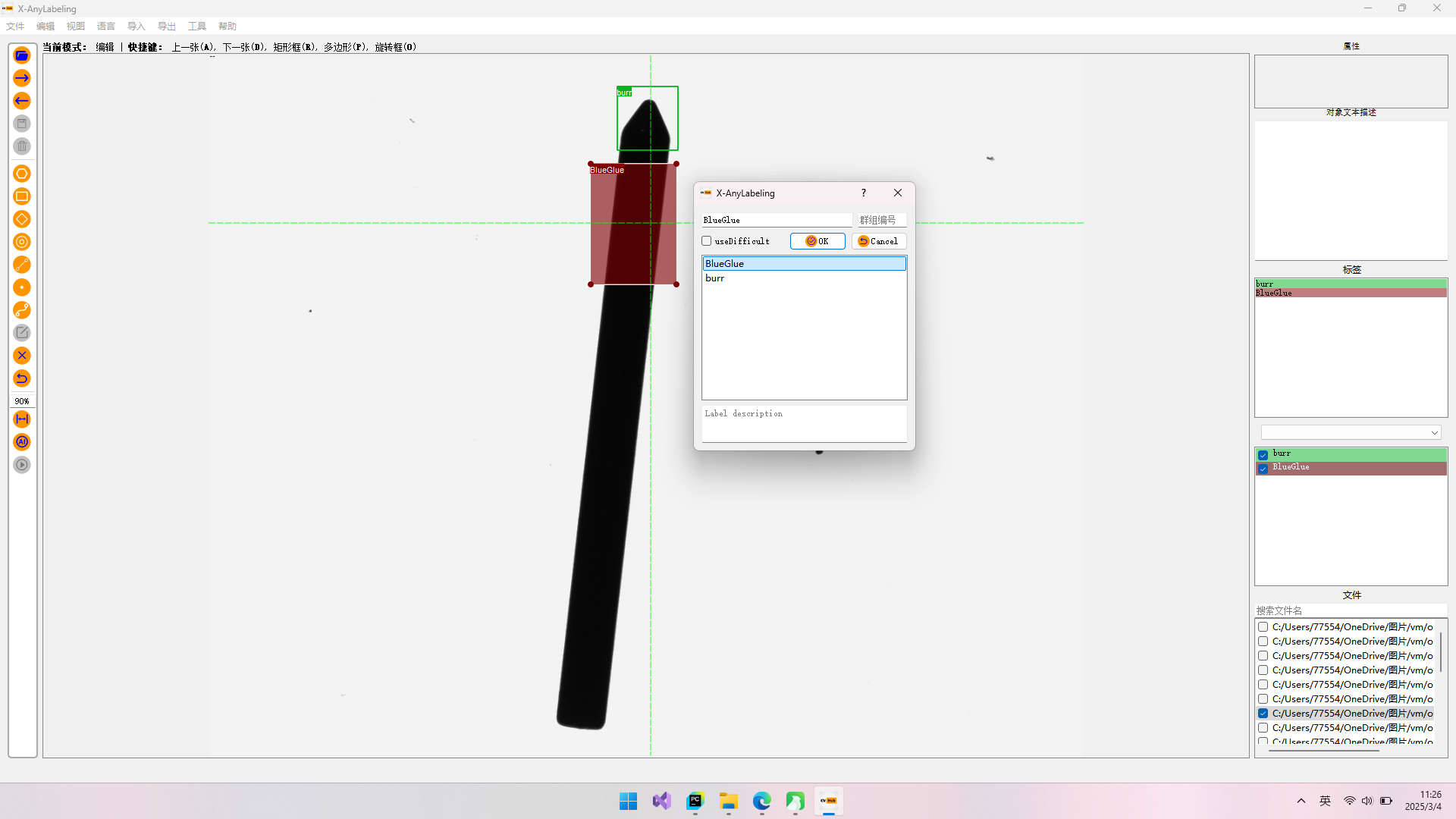
怎么导出矩形框(水平框)?
点击键盘R键后用鼠标画出区域并取名.矩形框标注完后,选择导出YOLO标签。在这里需要写一个classes.txt文件,内容为标签名字。然后选择该文件导出即可。
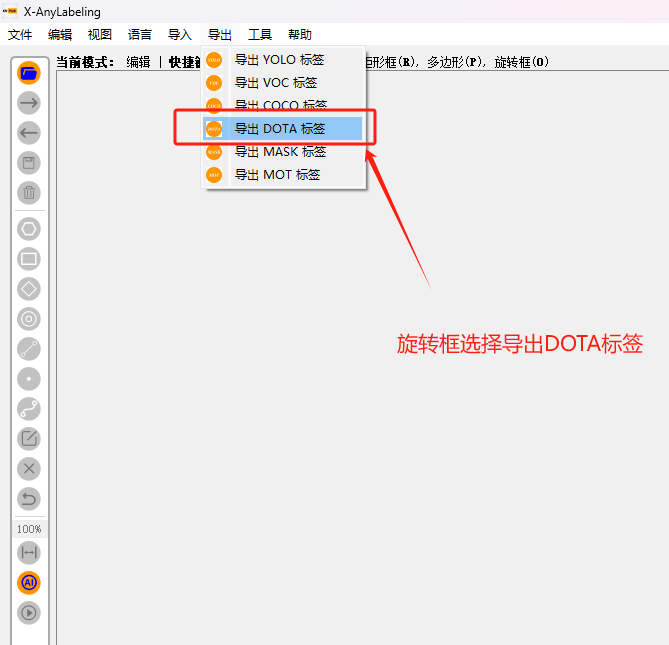
3.旋转框:
点击键盘上的O键后用鼠标画出区域。如果需要调整方向,在画出旋转框后,用鼠标选中刚刚画好的旋转框,然后点击键盘上的Z键,X键,C键,中的其中一个即可旋转,旋转角度即可自由切换。(跟矩形框操作差不多)

旋转框标注完后,选择导出DOTA标签。如图所示:
二.yolov8-OBB旋转框
1.划分数据集:在ultralytics-main下新建一个文件夹,命名为:datasets ,设置如下结构:
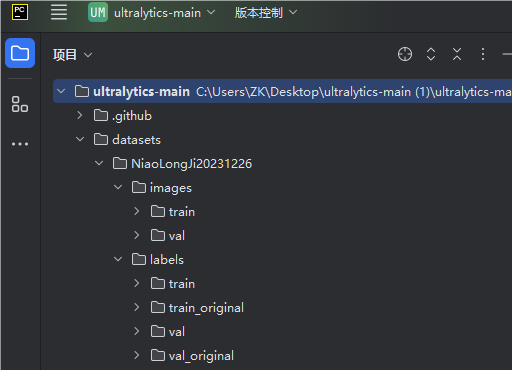
再创建一个文件夹。例如NiaoLongJi20231226。
文件目录解答:
images/train和images/val分别放置DOTA数据集切割后的原始图片文件。
labels/train_original和labels/val_original分别放置原始的标签文件。
labels/train和labels/val为空文件夹。
2.新建dota8-obb.yaml
修改文件路径及标签类别
# Ultralytics YOLO 🚀, AGPL-3.0 license
# DOTA 1.0 dataset https://captain-whu.github.io/DOTA/index.html for object detection in aerial images by Wuhan University
# Documentation: https://docs.ultralytics.com/datasets/obb/dota-v2/
# Example usage: yolo train model=yolov8n-obb.pt data=DOTAv1.yaml
# parent
# ├── ultralytics
# └── datasets
# └── dota1 ← downloads here (2GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
#path: ../datasets/DOTAv1 # dataset root dir
path: C:/Users/ZK/Desktop/ultralytics-main (1)/ultralytics-main/datasets/NiaoLongJi20231226
train: images/train # train images (relative to 'path') 1411 images
val: images/val # val images (relative to 'path') 458 images
#test: images/test # test images (optional) 937 images
# Classes for DOTA 1.0
names:
0: hole
# Download script/URL (optional)
#download: https://github.com/ultralytics/assets/releases/download/v0.0.0/DOTAv1.zip配置文件参数解答:
这个配置文件文件为 YOLOv8 提供了完整的数据集路径和类别信息。
path:定了整个数据集的目录路径(可以写成绝对路径或相对路径)。YOLOv8 在训练和验证过程中会使用该路径来查找图像和标签文件
train: images/train: 指定训练集图像文件夹的位置。
val: images/val: 指定验证集图像文件夹的位置
names::
- 这个节点列出了类别名称,通常用于标识数据集中各个类。(也就是标签名)
- 每个条目在这里表示一个类别,其对应的数字(索引)用来表示类别的 ID,即在训练或推理时使用的类标号。
3.图片格式转换PNG (jpg/bmp转换为png)
在anaconda3环境下
新建一个.py文件,命名为convert_bmp_to_png.py文件。复制下面的代码粘贴。
# -*- coding: utf-8 -*-
# 这段代码是将 bmp格式转png
from PIL import Image
import glob
import os
def convert_bmp_to_jpg(input_dir, output_dir):
# 确保输出目录存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 设置最大图像像素数量
Image.MAX_IMAGE_PIXELS = None # 设置为 None 以解除限制
# 遍历输入目录中的文件
for filename in os.listdir(input_dir):
if filename.endswith(".bmp"):
# 构建文件路径
input_path = os.path.join(input_dir, filename)
output_path = os.path.join(output_dir, os.path.splitext(filename)[0] + ".png")
# 打开 BMP 文件并保存为 JPG
with Image.open(input_path) as img:
img.convert("RGB").save(output_path, "PNG")
if __name__ == "__main__":
input_folder = "C:/Users/ZK/Desktop/正光图片20240906/正光图片20240906" # 替换为实际的输入文件夹路径
output_folder = "C:/Users/ZK/Desktop/正光图片20240906/1111" # 替换为实际的输出文件夹路径
convert_bmp_to_jpg(input_folder, output_folder)新建一个.py文件,命名为convert_jpg_to_png.py文件。复制下面的代码粘贴。
# -*- coding: utf-8 -*-
# 这段代码是将jpg格式转png
from PIL import Image
import glob
import os
def convert_bmp_to_jpg(input_dir, output_dir):
# 确保输出目录存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 设置最大图像像素数量
Image.MAX_IMAGE_PIXELS = None # 设置为 None 以解除限制
# 遍历输入目录中的文件
for filename in os.listdir(input_dir):
if filename.endswith(".jpg"):
# 构建文件路径
input_path = os.path.join(input_dir, filename)
output_path = os.path.join(output_dir, os.path.splitext(filename)[0] + ".png")
# 打开 BMP 文件并保存为 JPGconvert_bmp_to_jpg.py
with Image.open(input_path) as img:
img.convert("RGB").save(output_path, "PNG")
if __name__ == "__main__":
input_folder = "C:/Users/ZK/Desktop/Crops/Crops" # 替换为实际的输入文件夹路径
output_folder = "C:/Users/ZK/Desktop/Crops/123" # 替换为实际的输出文件夹路径
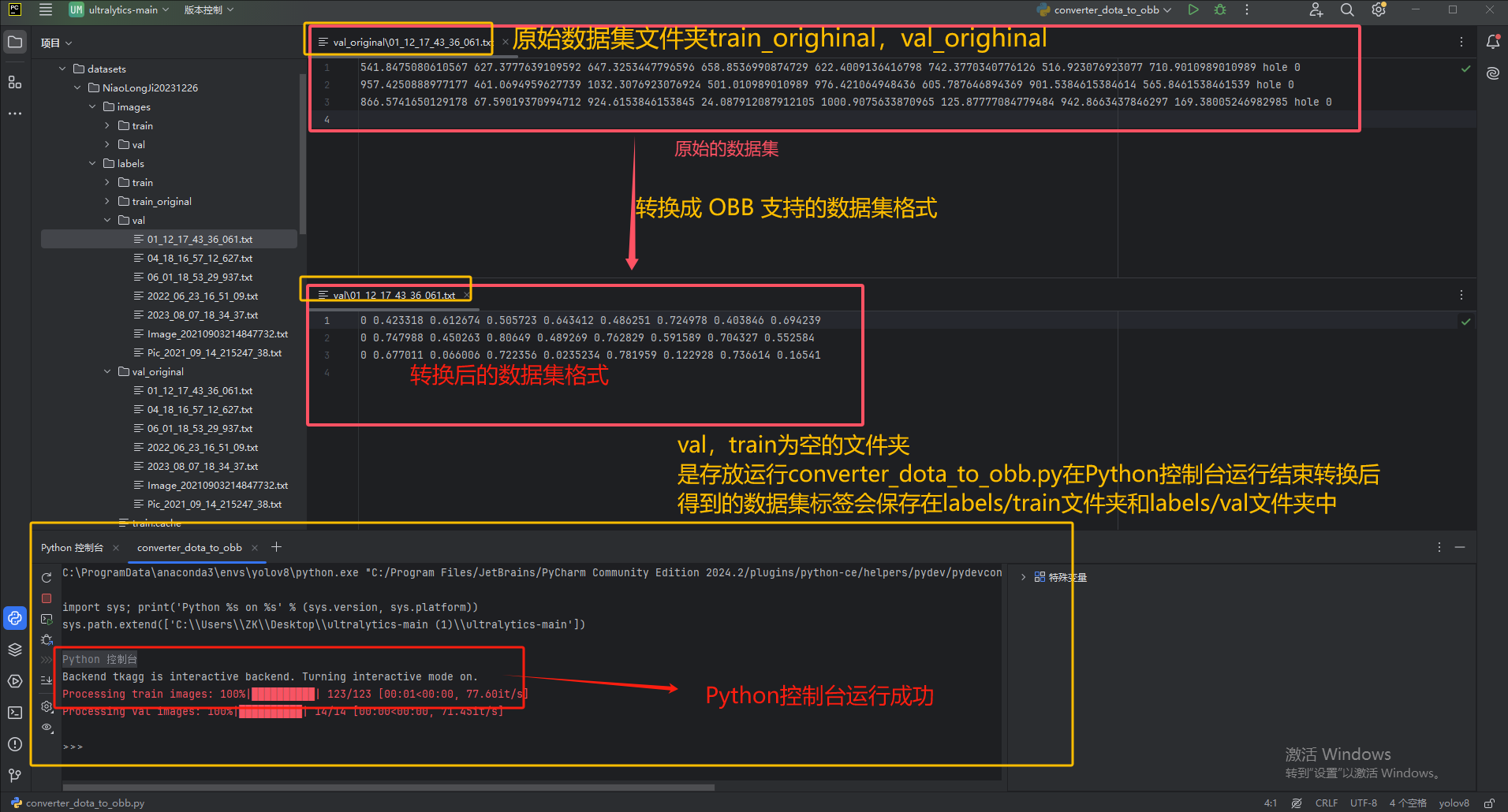
convert_bmp_to_jpg(input_folder, output_folder)4.将原始数据集格式转换成OBB支持的数据集格式(原图片格式为png,否则没有效果)
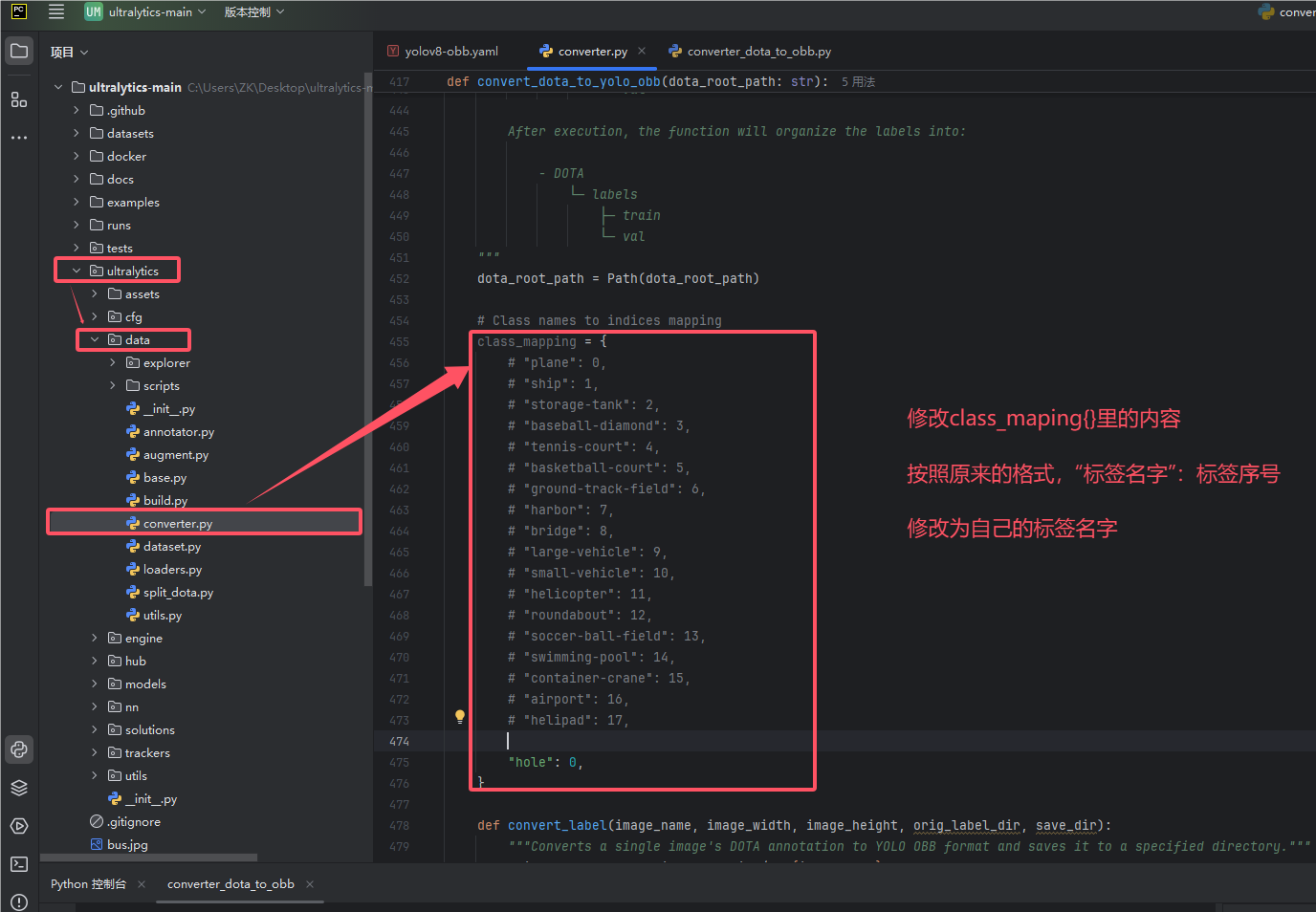
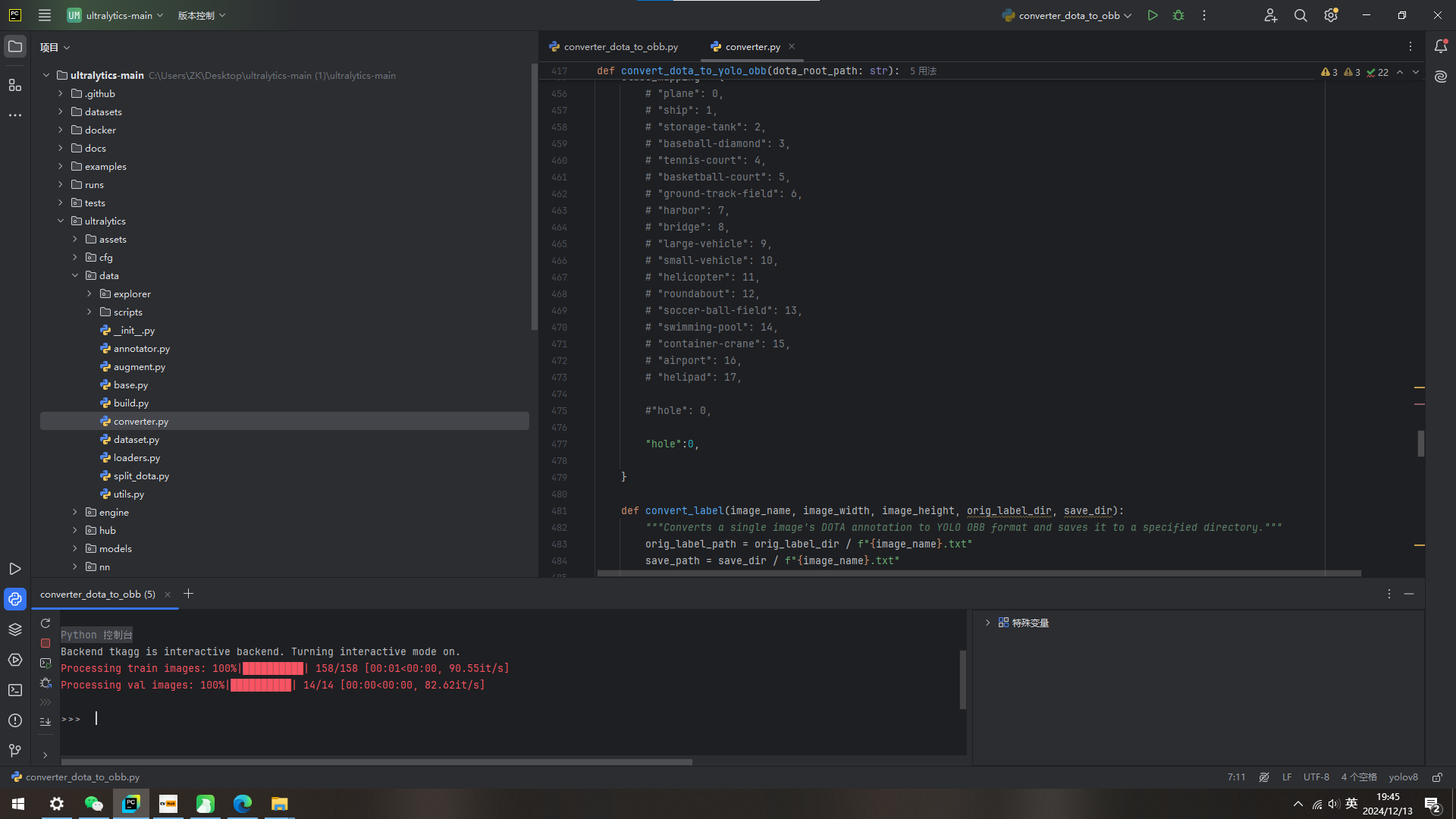
第一步:找到converter.py文件夹,进入convert_dota_to_yolo_obb中的class_mapping = {}修改
第二步新建一个converter_dota_to_obb.py文件实现标签转换
from ultralytics.data.converter import convert_dota_to_yolo_obb
convert_dota_to_yolo_obb(r'C:\Users\ZK\Desktop\ultralytics-main (1)\ultralytics-main\datasets\NiaoLongJi20231226')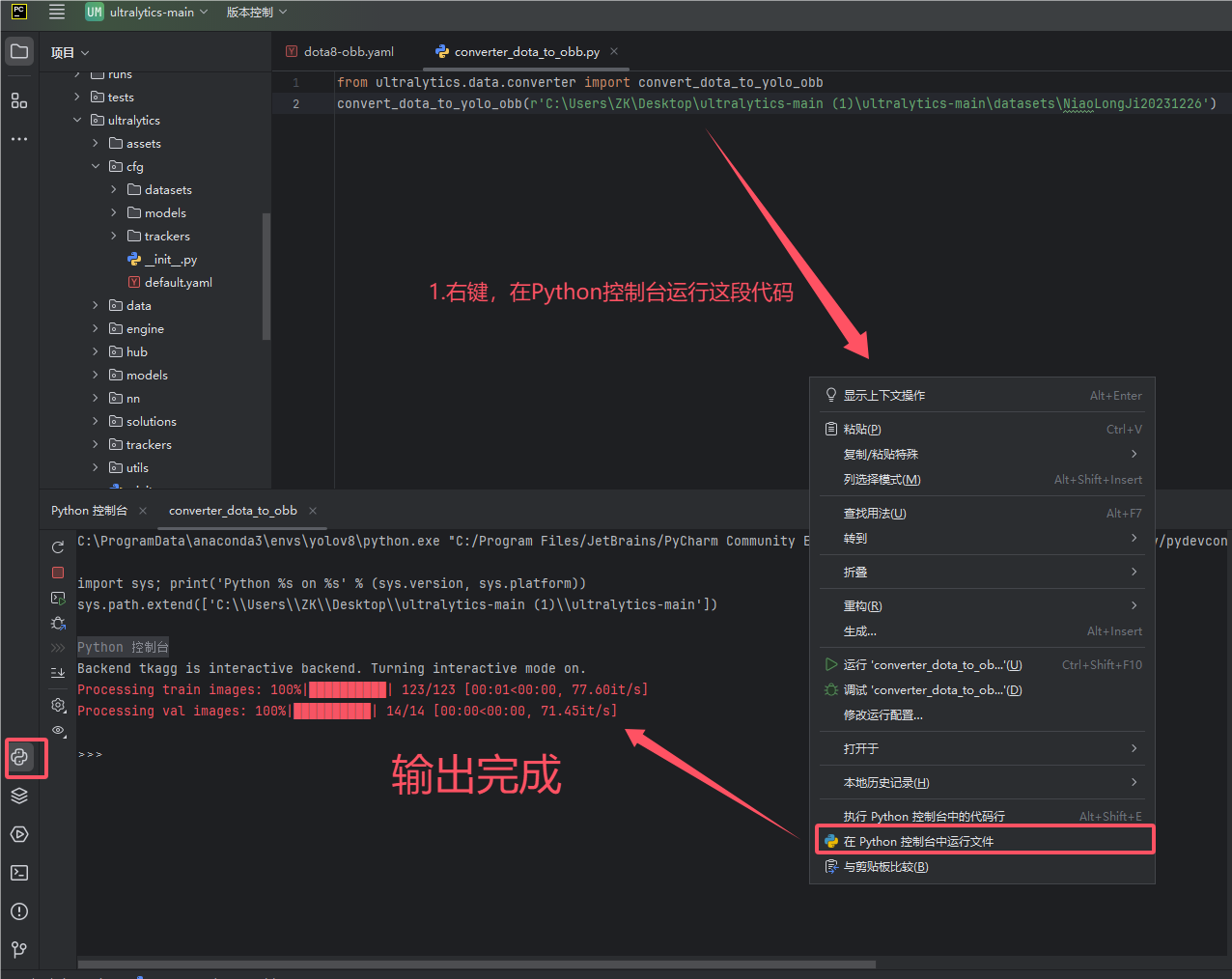
操作目的:将原始数据集格式转换成OBB支持的数据集格式
这里可能会遇到的报错以及解决方法:
报错1:ModuleNotFoundError: No module named 'numpy'
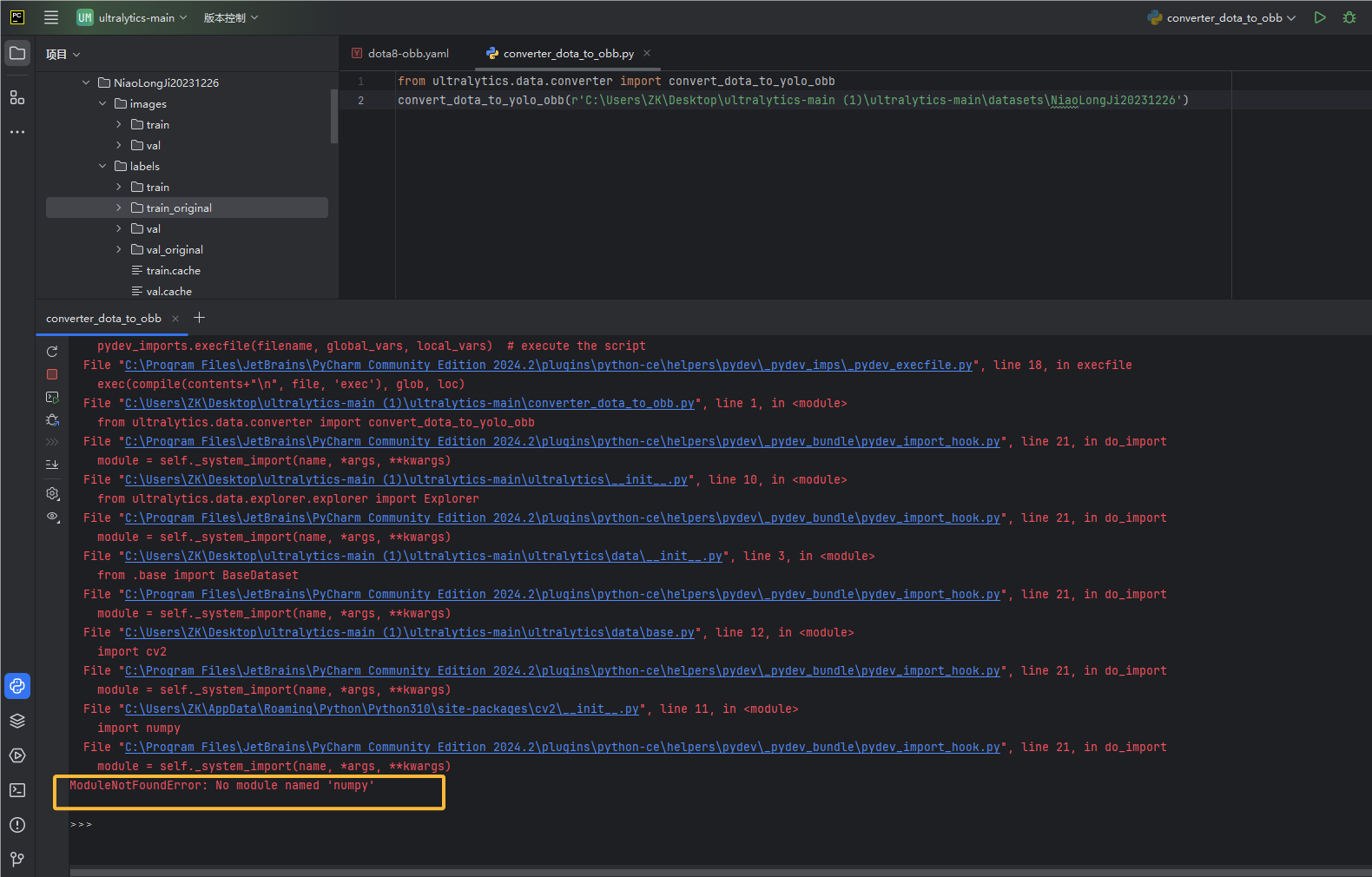
解决:
1.安装numpy的时候需要先更新pip,使用最新版的pip来安装:
python -m pip install --upgrade pip2.安装numpy
pip install numpy3.接下来在命令行窗口运行
python4.在运行下面这个指令
from numpy import *报错2:ModuleNotFoundError: No module named 'psutil'
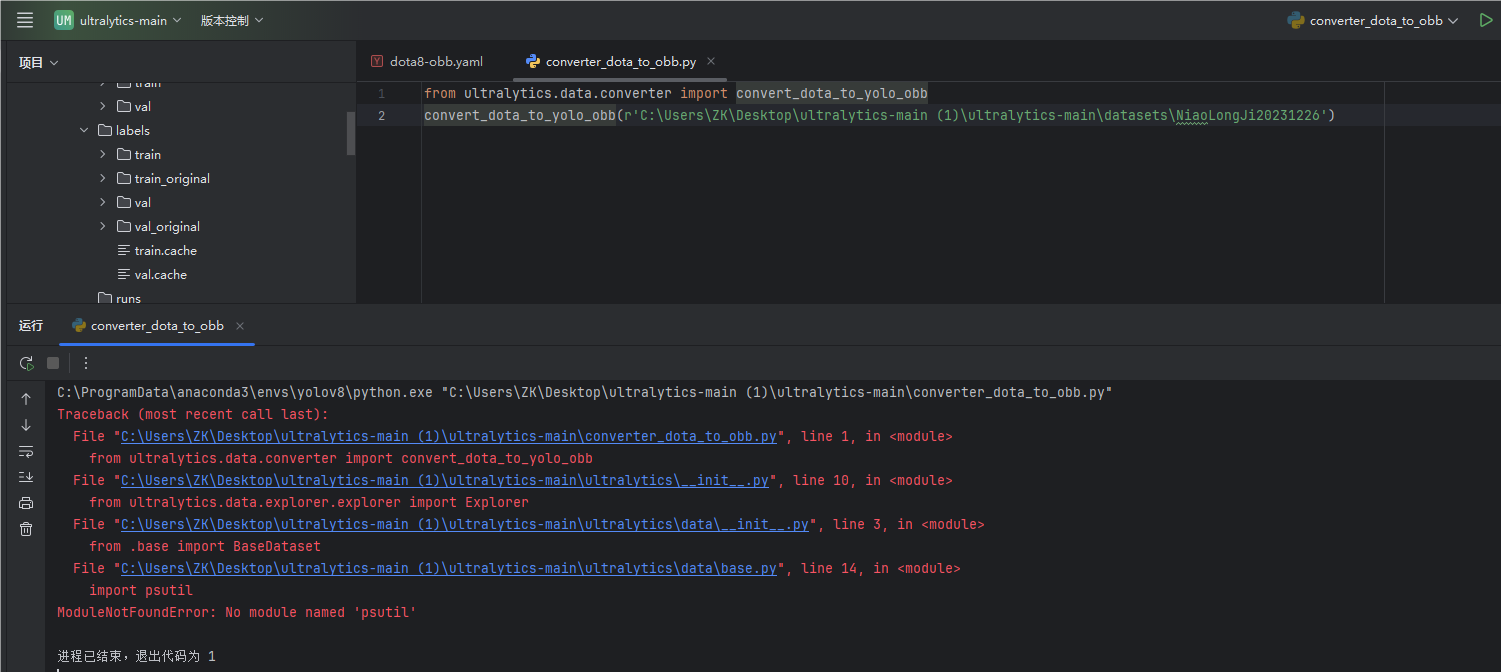
原因:缺少了psutil包
解决方案:下载
pip install psutil
或
conda install psutil
报错 KeyError:"hole"
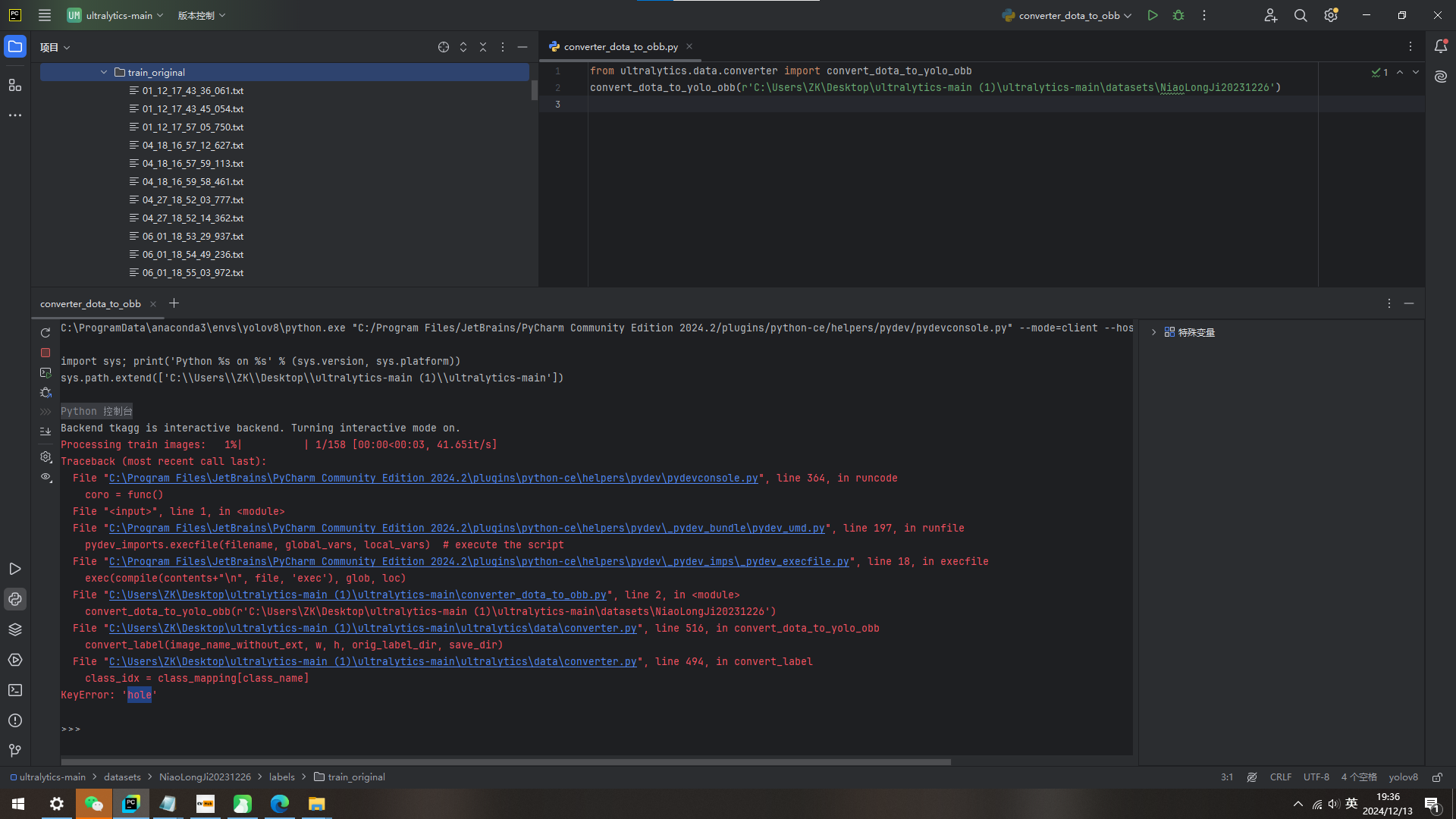
报错原因:
converter.py文件的class_mapping{ }里的内容没有修改
解决:
修改converter.py这个文件,在class_mapping{ }里添加标签名,按照示例的格式修改即可
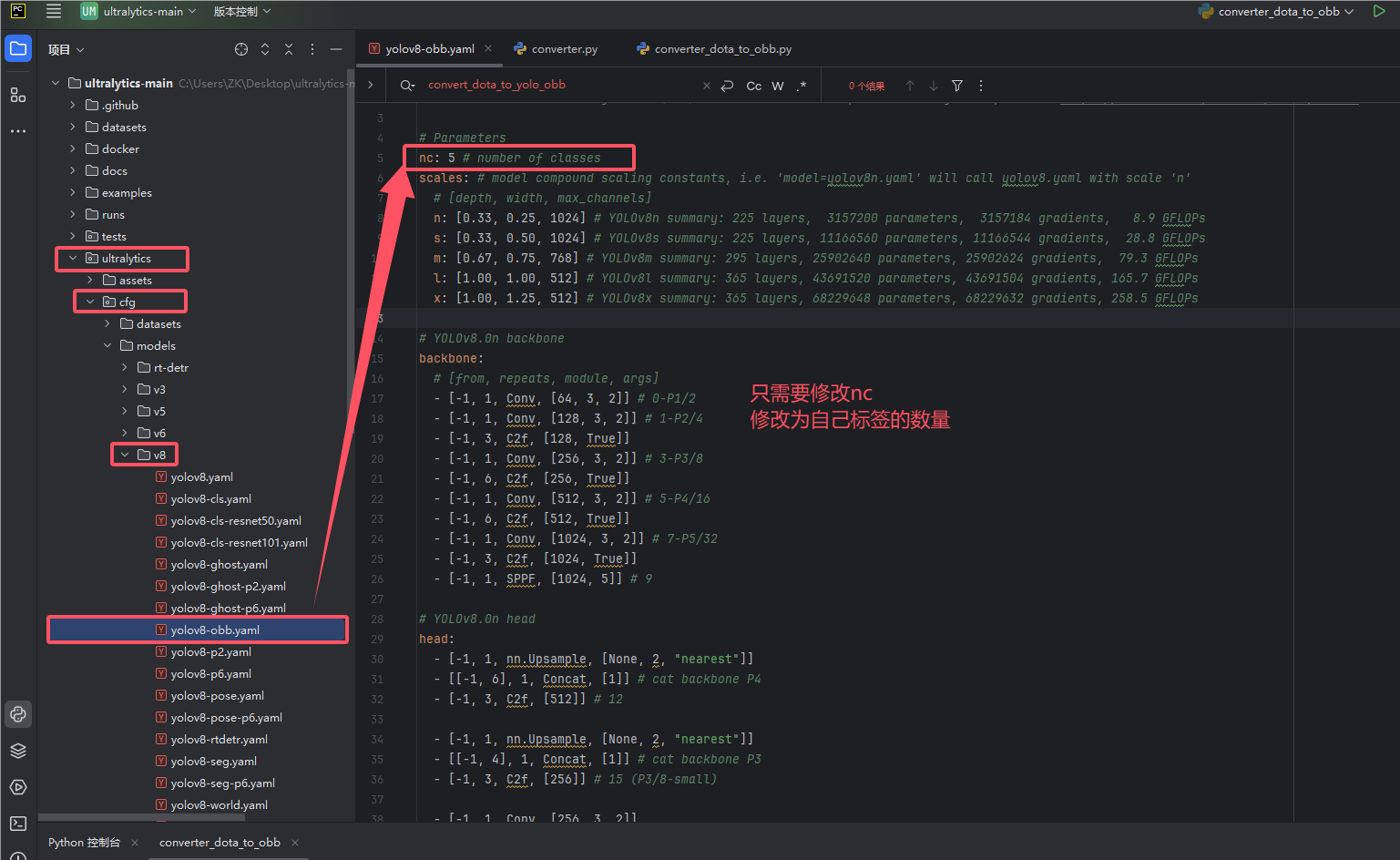
5.将原始的数据集转换成功后,修改yolov8-obb.yaml文件
1.找到yolov8-obb.yaml文件。
2.修改为自己的标签数量
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 Oriented Bounding Boxes (OBB) model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 5 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, OBB, [nc, 1]] # OBB(P3, P4, P5)
三.yolov8n 矩形框(水平框)
1.划分数据集:在ultralytics-main下新建一个文件夹,例如 命名为:datasets ,设置如下结构:
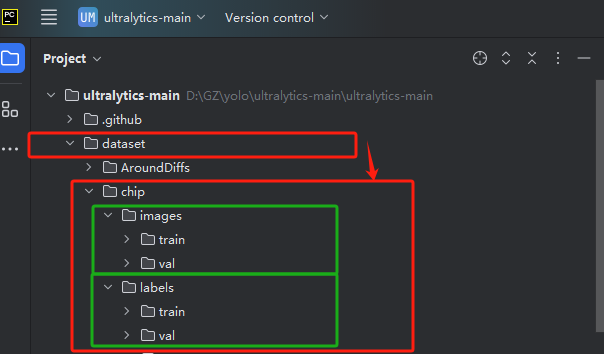
再创建一个文件夹。例如chip文件夹
目录结构解答:
images/train放置 存放所有的训练图片
images/val放置 验证集图片
labels/train为存放所有的标注标签
labels/val为存放验证集验证集标注标签
2.需要准备一个yaml文件.新建一个dota8.yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# DOTA 1.0 dataset https://captain-whu.github.io/DOTA/index.html for object detection in aerial images by Wuhan University
# Documentation: https://docs.ultralytics.com/datasets/obb/dota-v2/
# Example usage: yolo train model=yolov8n-obb.pt data=DOTAv1.yaml
# parent
# ├── ultralytics
# └── datasets
# └── dota1 ← downloads here (2GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
#path: ../datasets/DOTAv1 # dataset root dir
path: C:/Users/ZK/Desktop/ultralytics-main (1)/ultralytics-main/datasets/chip
train: images/train # train images (relative to 'path') 1411 images
names:
0: burr
1: BlueGlue
配置文件参数解答:
这个配置文件文件为 YOLOv8 提供了完整的数据集路径和类别信息。
path:定了整个数据集的目录路径(可以写成绝对路径或相对路径)。YOLOv8 在训练和验证过程中会使用该路径来查找图像和标签文件
train: images/train:指定训练集图像文件夹的位置。
val: images/val: 指定验证集图像文件夹的位置
names::
- 这个节点列出了类别名称,通常用于标识数据集中各个类。(也就是标签名)
- 每个条目在这里表示一个类别,其对应的数字(索引)用来表示类别的 ID,即在训练或推理时使用的类标号。
五.开始训练
训练开始前需要严格按照文章的"四.数据集的制作"进行操作.
1.要准备好配置文件.yaml,检查配置文件的路径是否写对,标签名是否修改正确......
2.文件结构、图片格式严格按照标准整理....
3.环境是否搭建成功....
这些都准备好后,训练就可开始了
1.在yolo环境下执行,如不是yolo环境,记得切换到yolov8环境
是yolo环境,可不用执行此步骤,直接进行训练即可.
//切换到yolov8环境
conda activate yolov82.切换好环境后,即可开始训练:
//开始训练
//旋转框 指令
yolo train model=yolov8n-obb.pt data=dota8-obb.yaml epochs=500 imgsz=320
//水平框 指令
yolo train model=yolov8n.pt data=dota8.yaml epochs=500 imgsz=640旋转框指令和水平框指令差别就在于,使用的pt模型不同。指令参数根据自己需要的来调整
指令参数解答:
1.train:这是指定要执行的操作模式。train 表示训练模型。
2. model=: 这是一个参数指示符,告诉程序接下来的值是要使用的模型。
-obb 意味着这个版本专门针对旋转框目标检测
3.data=dota8-obb.yaml:
- 这是训练数据的配置文件路径。
dota8-obb.yaml是一个 YAML 文件,通常包含了数据集的信息,如训练和验证集的路径、类别名称(也就是标签名称)等。
4. batch:训练时每次处理的图像数量
5. workers=1数据加载的工作线程数量。设置为 1 表示使用一个线程加载数据。
6.epochs: 指的是训练轮数,可以根据实际修改。500: 指定训练模型运行 500 轮
7.device:0指的是GPU,如果没有GPU,也可以将0改成cpu
8.imgsz:参数指示符,告诉程序接下来的值是图像大小.320: 指定图像在输入到模型之前会被调整为 320x320 像素.通常有像素320x320,640x640.......
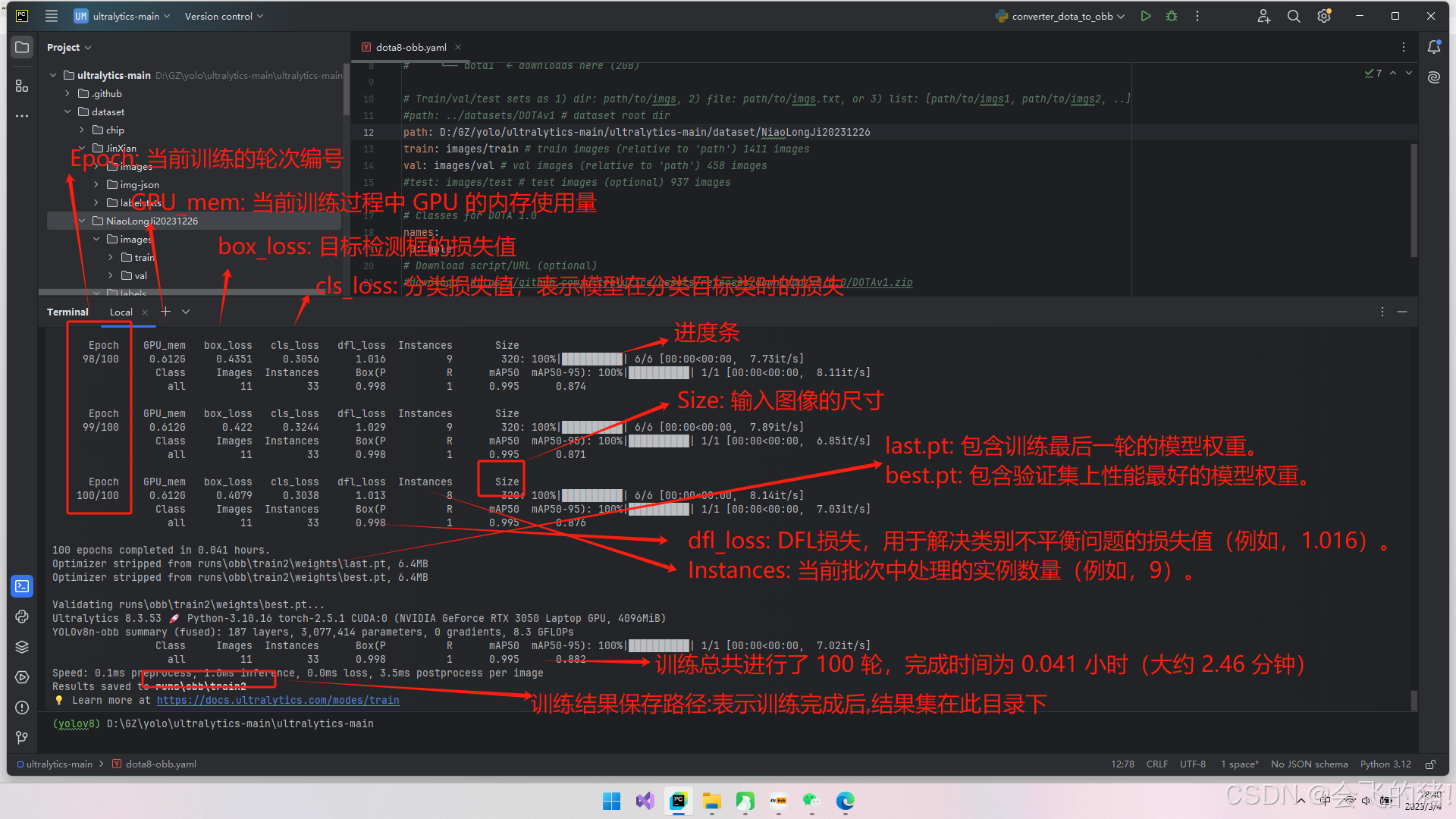
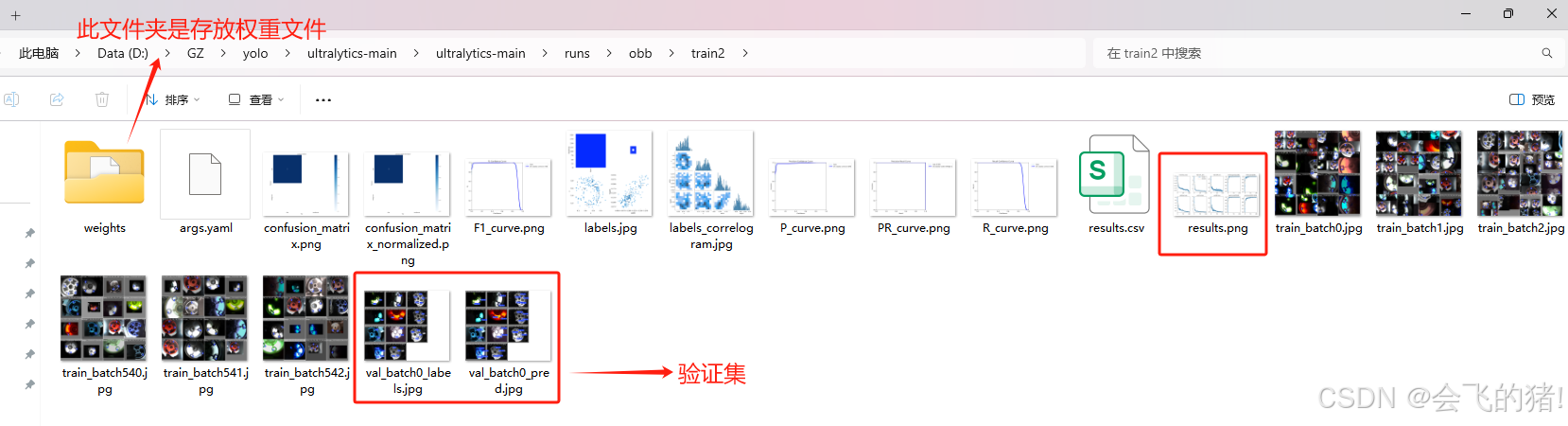
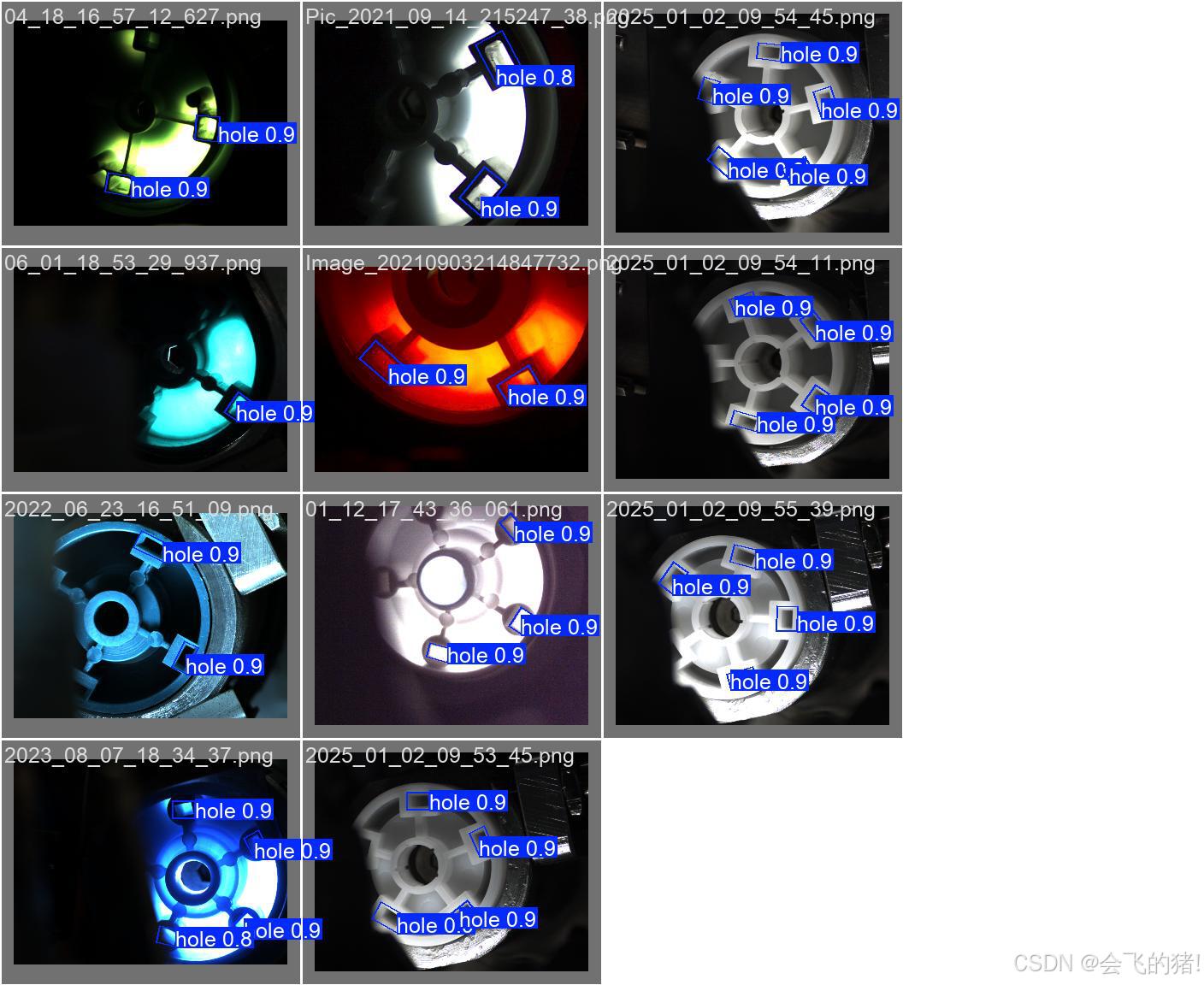
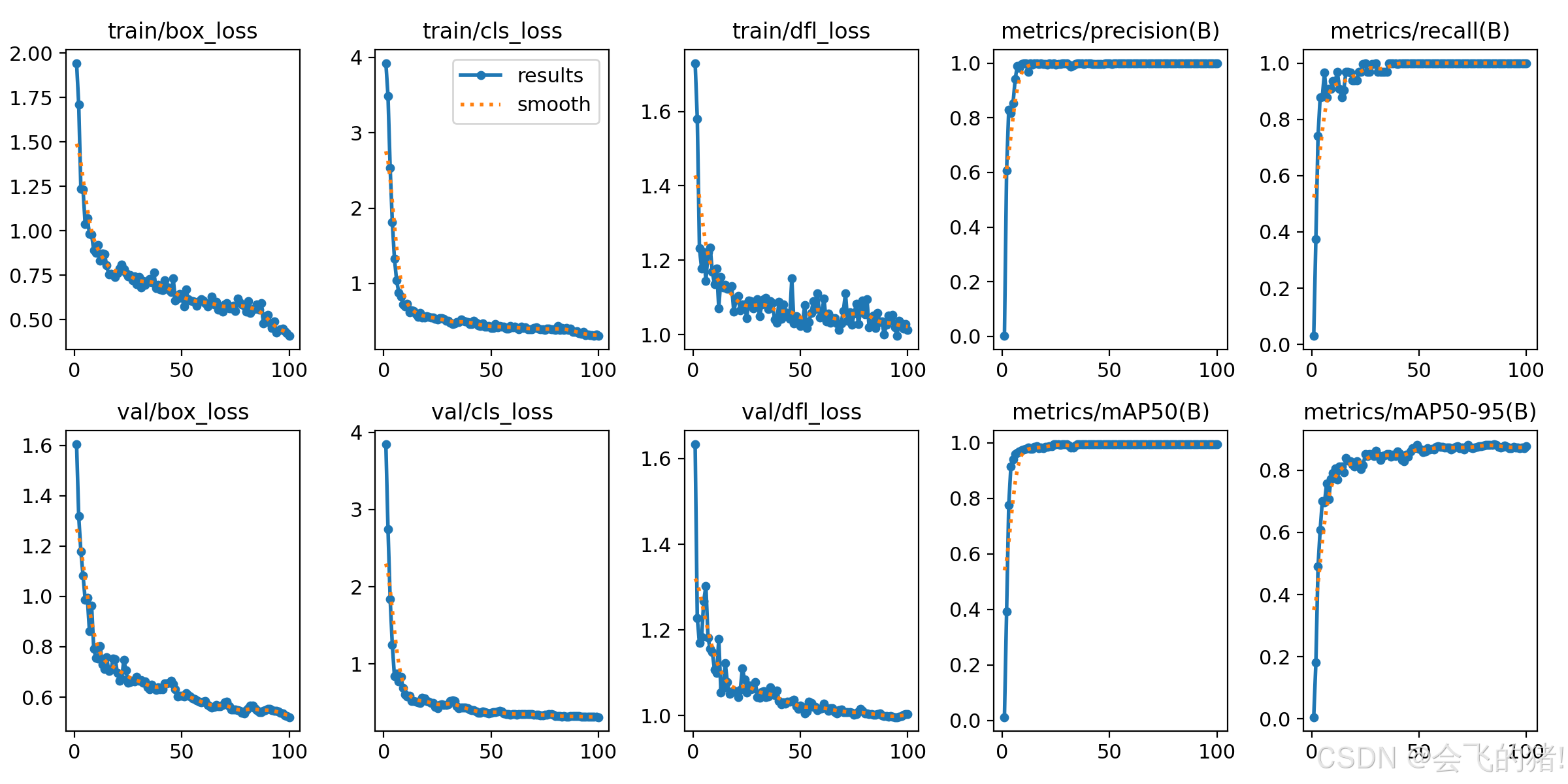
训练图展示

六.pt模型转换到onnx模型,导出onnx模型
1.导出模型指令:
//obb旋转框
yolo task=obb mode=export model=runs/obb/train11/weights/best.pt format=onnx
//水平框
yolo export model= E:\GZ\yolo\ultralytics-main\ultralytics-main\runs\detect\train7\weights\best.pt format=onnx opset=11指令参数解答:
1.task :参数指定了模型的任务类型
2.mode=export:mode 参数指定了你要执行的操作模式。export 表示你要导出模型,这通常意味着将训练好的模型转换为不同的格式(在这个例子中是 ONNX 格式)。
3.model: 参数指定了要导出的模型的路径
4.format=onnx:format 参数指定了导出模型的目标格式。ONNX(Open Neural Network Exchange)是一种开放的格式,用于在不同的深度学习框架之间交换模型。导出为 ONNX 格式可以使得模型在其他支持 ONNX 的框架中使用,如 TensorFlow、Caffe2 等。
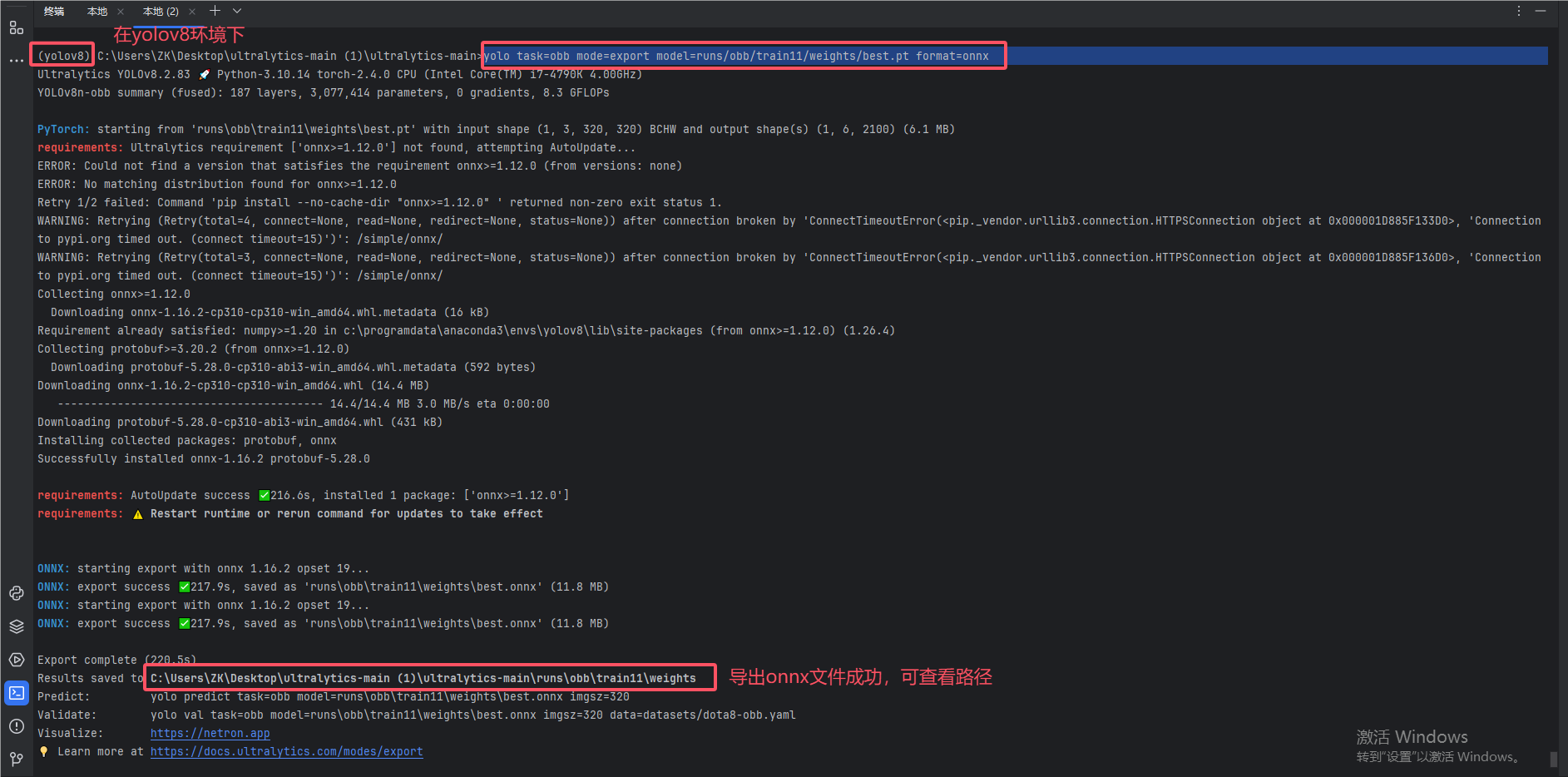
2.导出onnx模型可能遇到的错误
报错1:ModuleNotFoundError: No module named 'onnx'
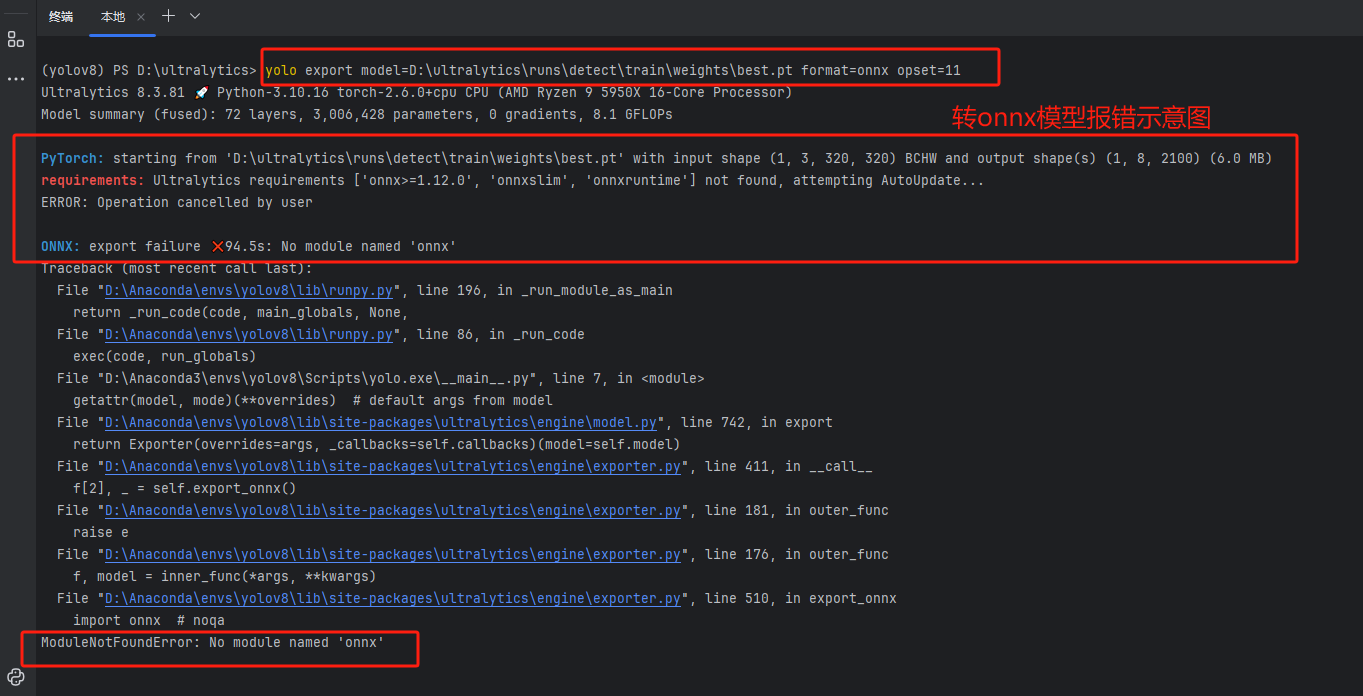
解决方法:
这个错误提示是因为找不到名为'onnx'的模块。可能是因为没有安装该模块或者安装不正确。需要先安装该模块,可以使用pip命令进行安装,如下所示:
pip install onnx安装完成后,再次运行程序即可。
执行pip install onnx 命令可能遇到,如下图所示的报错,不要慌,说明网络不好.重新执行pip install onnx指令.
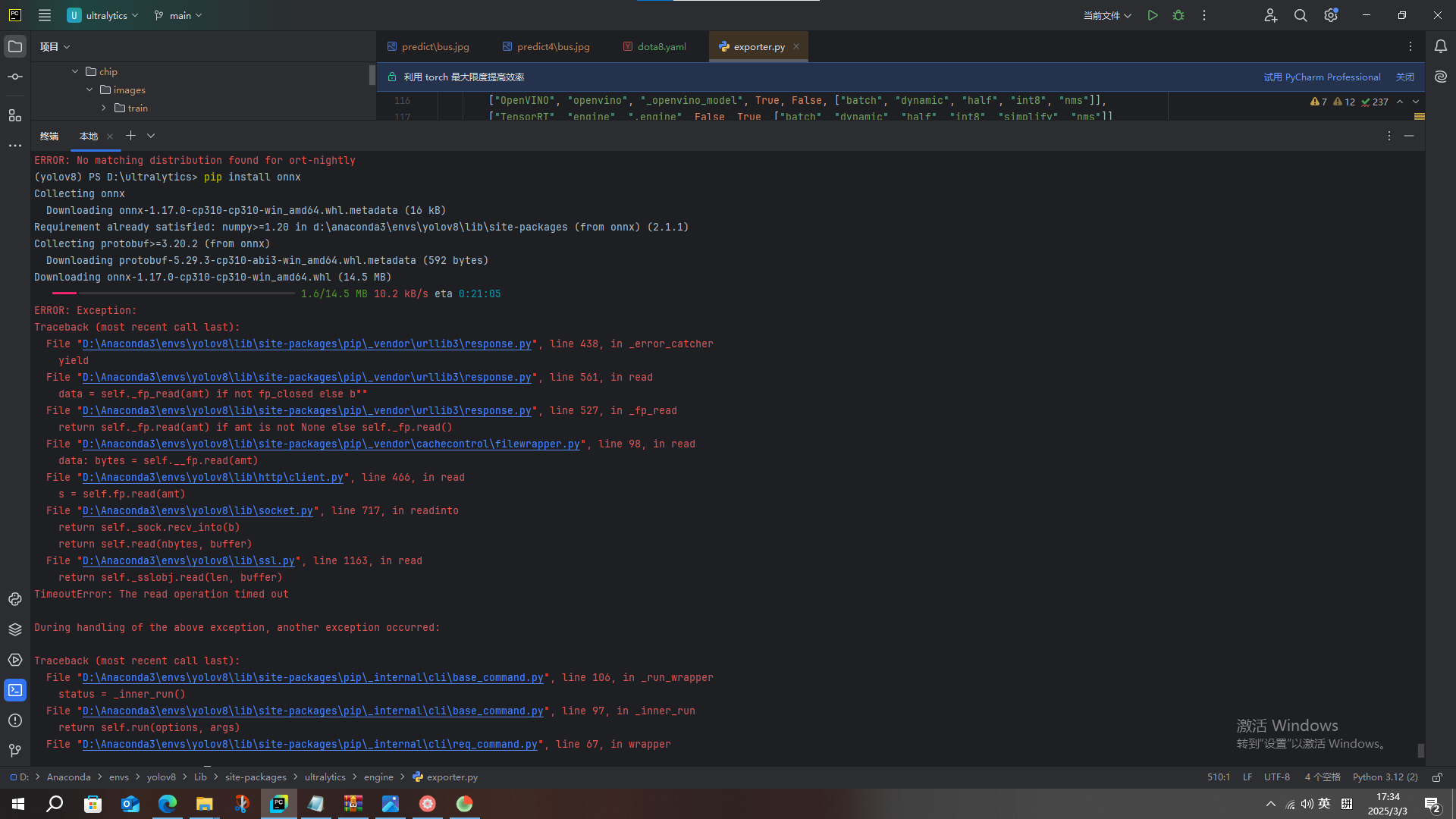
如果你使用的是conda环境,你可以使用以下命令来安装:
conda install -c anaconda onnx报错2:ModuleNotFoundError: No module named 'onnxruntime'
解决方法:
使用pip来安装:
pip install onnxruntime或者,使用conda安装
conda install -c anaconda onnxruntime

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











