







相机坐标系(三维坐标系)
相机的中心被称为焦点或者光心,以焦点𝑂𝑐Oc为原点和坐标轴𝑋𝑐,𝑌𝑐,𝑍𝑐Xc,Yc,Zc组成了相机坐标系
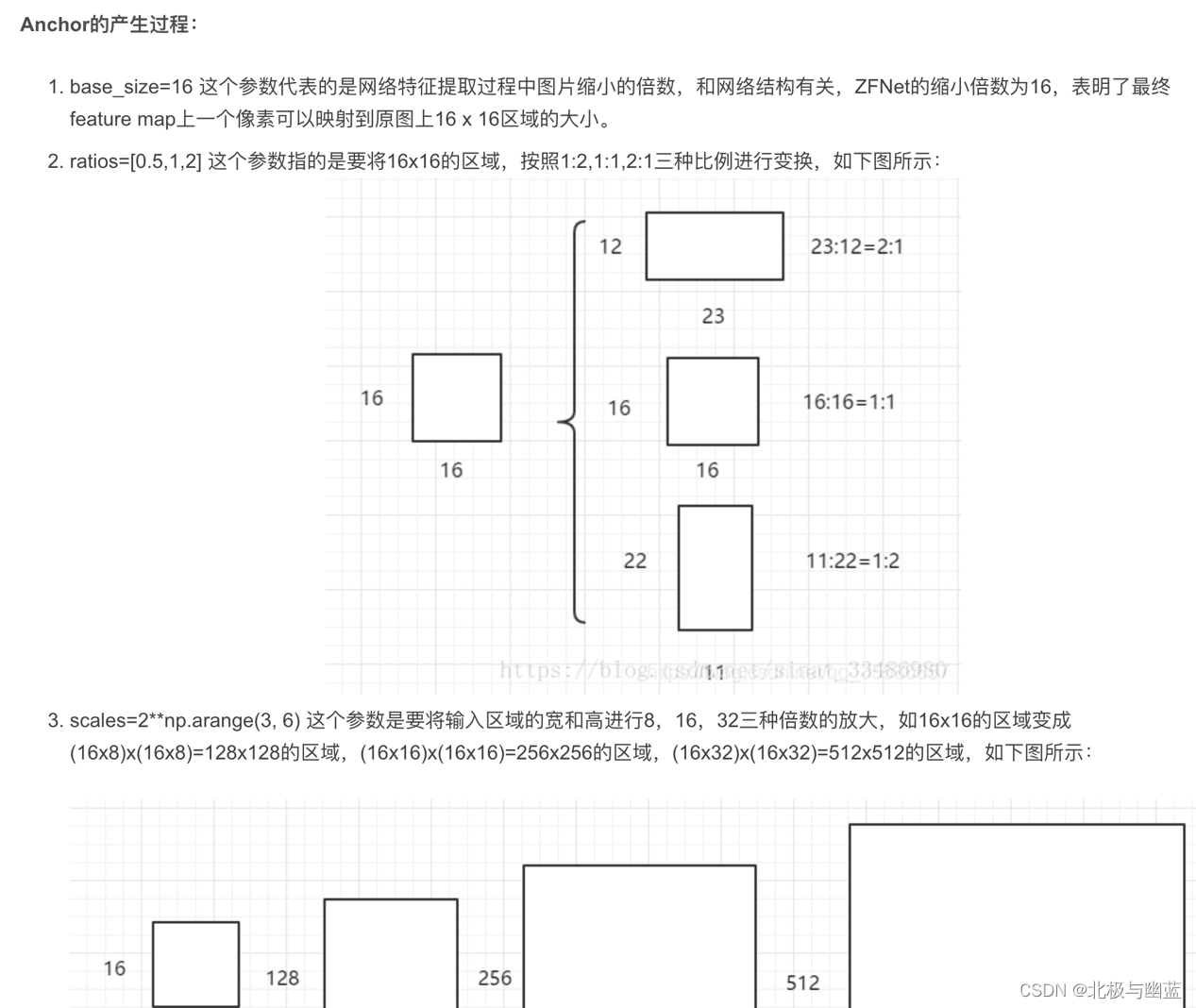
图像坐标系(二维坐标系)
成像平面中,以成像平面的中心𝑂′O′为原点和坐标轴𝑥′,𝑦′x′,y′组成了图像坐标系。
小孔成像实际就是将相机坐标系中的三维点变换到成像平面中的图像坐标系中的二维点。
内外参数组合到一起称为相机矩阵,其作用是将真实场景中的三维点投影到二维的成像平面。
内参数
焦距𝑓
从成像平面坐标系到像素坐标系的变换。
将各自传感器获得的数据转换到车体坐标系下,也就是base坐标系,那么这个过程就叫做传感器的外参标定.例如lidar被安装为x轴向前,y轴向左,z轴向上的右手坐标系,从雷达坐标系转移到车辆坐标系,车辆坐标系为z轴向前,x轴向左,y轴向上的右手坐标系
下面的KITTI采集车上,分别呈现了两种坐标系,坐标系转换其实就是传感器的外参标定,传感器坐标系通过一些刚体变换转换到车体坐标系,变换矩阵由旋转矩阵和平移矩阵组成,通过求解6个量(X,Y,Z,Roll, Pitch,Yaw ):前3个值代表分别沿x,y,z方向平移的距离;后3个值代表分别沿x,y,z方向旋转的角度。
相机坐标系-》平移缩放得到像素坐标系



Inverse Perspective Mapping逆透视变换/反向透视映射/反投影变换(IPM): 通过透视原理对原图像中的物体进行变换,生成新的图像
小结:IPM有多种应用,也有多种实现方式,例如由对应点计算变换矩阵(蛋homography单应矩阵,同一平面的点在不同图像之间的对应关系,所以需要假设地面是平坦的)、由坐标系变换简化得到IPM坐标关系的公式化描述
透视效应使本来平行的事物在图像中相交。IPM变换就是消除这种透视效应,所以也叫逆透视。
The inverse perspective mapping method map the points
in the image coordinate system to real world coordinates
with the camera position, the pitch angle, the yaw angle and
the camera angular aperture in the vertical and horizontal
directions.
- 对应点对变换方法
输入四个对应点对,构建线性方程组求解透视变换矩阵
- 简化相机模型的逆透视变换
利用相机成像过程当中各种坐标系之间的转换关系,对其基本原理进行抽象和简化,对逆透视变换的坐标关系进行公式化描述。这种逆透视变换形式简单,计算速度快,并且适用于复杂道路场景。
Inverse perspective mapping simplifies optical flow computation and obstacle detection 1991
3. Deep Learning based Vehicle Position and Orientation Estimation
用IPM把前视图投影到bev
Stereo inverse perspective mapping: theory and applications 1998
Robust Inverse Perspective Mapping Based on Vanishing Point 2014
Adaptive Inverse Perspective Mapping for Lane Map Generation with SLAM 2016
光流法(optical flow)
光流是瞬时速度,通常将灰度瞬时变化率定义为光流。
optical flow (光流) 表示的是相邻两帧图像中每个像素的运动速度和运动方向。第t帧的时候A点的位置是(x1, y1),那么我们在第t+1帧的时候再找到A点(能在下一帧中找到A点,就需要用到计算光流的各种方法,在openCI中可以实现),假如它的位置是(x2,y2),那么我们就可以确定A点的运动了:(ux, vy) = (x2, y2) - (x1,y1)
1.什么是光流
光流(optical flow)是空间运动物体在观察成像平面上的像素运动的瞬时速度。
光流法是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。
通常将二维图像平面特定坐标点上的灰度瞬时变化率定义为光流矢量。
一言以概之:所谓光流就是瞬时速率,在时间间隔很小(比如视频的连续前后两帧之间)时,也等同于目标点的位移
2.光流的物理意义
一般而言,光流是由于场景中前景目标本身的移动、相机的运动,或者两者的共同运动所产生的。
当人的眼睛观察运动物体时,物体的景象在人眼的视网膜上形成一系列连续变化的图像,这一系列连续变化的信息不断“流过”视网膜(即图像平面),好像一种光的“流”,故称之为光流。光流表达了图像的变化,由于它包含了目标运动的信息,因此可被观察者用来确定目标的运动情况。
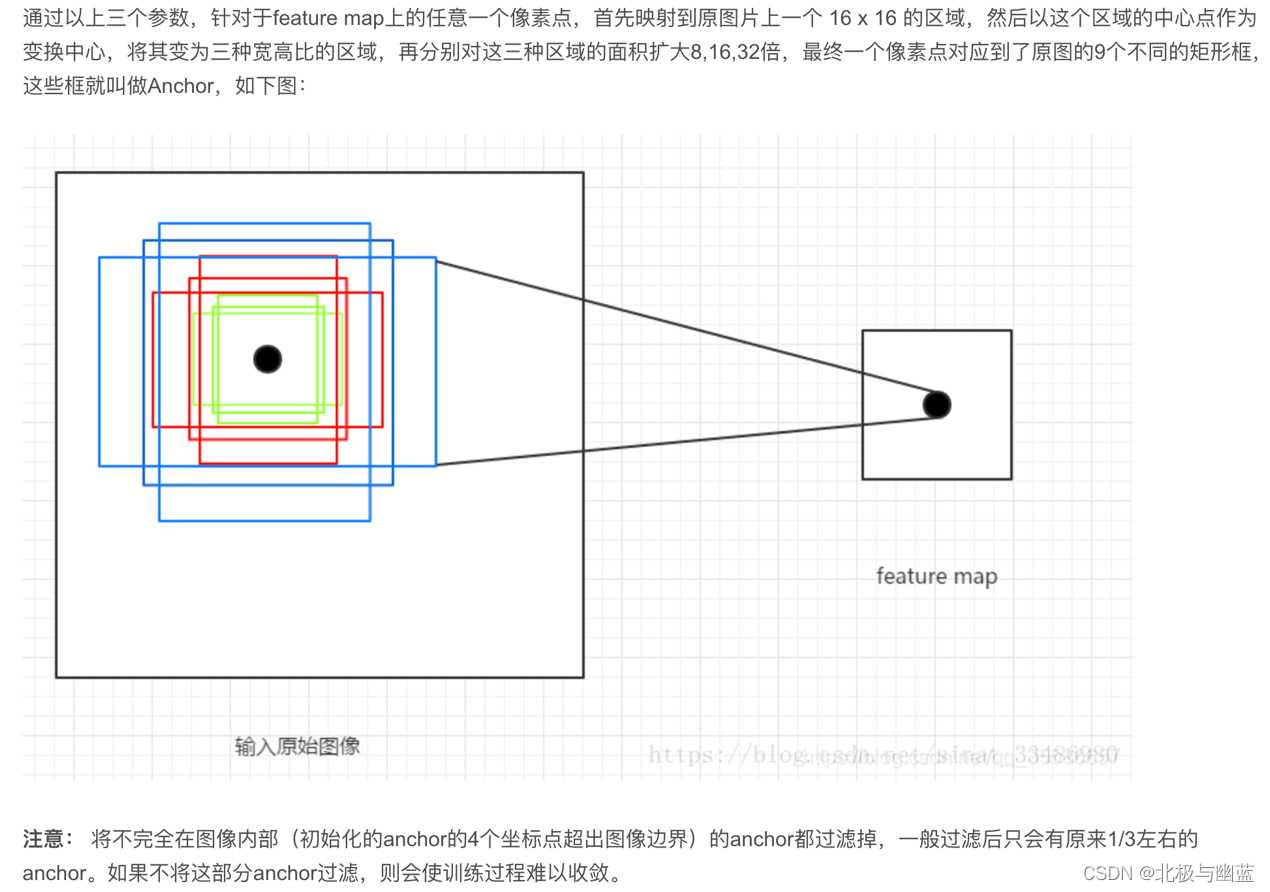
RPN:输入feature map,输出proposals
anchor:RPN的目标是代替Selective Search实现候选框的提取,目标检测的实质是对候选框的回归,而网络不可能自动生成任意大小的候选框,因此Anchor的意义就在于根据feature map在原图片上划分出很多大小、宽高比不相同的矩形框,RPN会对这些框进行一个粗略的分类和回归,选取一些微调过的包含前景的正类别框以及包含背景的负类别框,送入之后的网络结构参与训练。
增量学习
灾难性遗忘:第一,由于每次对模型的参数进行更新时,只能用大量的新类别的样本和少量的旧类别的样本,因此会出现新旧类别数据量不均衡的问题,导致模型在更新完成后,更倾向于将样本预测为新增加的类别;第二,由于只能保存有限数量的旧类别样本,这些旧类别的样本不一定能够覆盖足够丰富的变化模式,因此随着模型的更新,一些罕见的变化模式可能会被遗忘,导致新的模型在遇到一些旧类别的样本的时候,不能正确地识别。
增量学习任务分为,数据增量和类别增量。数据增量过程中,增量任务和原始任务之间没有新类别出现,两者具有相同的类别。
深度卷积(depthwise convolution)是特殊的分组卷积(group convolution),分组数等于输入channel数,也即逐个channel的卷积,卷积核只有kernel_size没有通道数,也即没进行通道之间的运算。
分离卷积(Separable Convolution)也称为逐点卷积. 其核心就是利用1*1卷积在不改变特征图大小情况下任意更改Channel数量的特性, 对Channel维度上的信息进行整合.
经过深度卷积和分离卷积两步后, 其产生的特征图大小和使用标准卷积产生的结果无异.
模型的复杂度,即参数(Parameters,使用Mb作为单位)的个数和(前向推理的)计算量(使用FLOPs(FLoating point OPerations)或MAC(Memory Access Cost)衡量)
MACs(Multiply–Accumulate Operations)乘加累积操作数,常常被人们与FLOPs概念混淆。实际上1MACs包含一个乘法操作与一个加法操作,粗略有MACs = 2 * FLOPs。
正则化
L1L2正则:在目标函数中使用l1范数作为正则项的称为l1正则化,使用l2范数的称为l2正则化。
L1范数是指权值向量w中各个元素的绝对值之和,通常表示为||w||1
L2范数是指权值向量w中各个元素的平方和然后再求平方根,通常表示为||w||2
L2与weight decay
有的说L2正则是添加正则项在损失函数中,weight decay是添加正则项在参数更新过程中。在标准SGD的情况下,通过对衰减系数做变换,可以将L2正则和Weight Decay看做一样。但是在Adam这种自适应学习率算法中两者并不等价。
但暂时就把weight decay理解为正则化里的超参,能调整正则化的强弱
全卷积语义分割:全卷积结构+上采样使结果大小和输入一样+跳跃结构改善上采样的粗糙度
Feature Pyramid Networks主要解决目标检测在处理多尺度变化问题上的不足。提出利用深度卷积神经网络固有的多尺度金字塔结构来以极小的计算量构建特征金字塔的网络结构。
Depthwise Separable Convolution是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。
Depthwise Convolution,是分组数等于channel数的分组卷积,一个卷积核负责一个通道,也即只在HW上卷积。Depthwise Convolution完成后的Feature map数量与输入层的通道数相同。这种运算对输入层的每个通道独立进行卷积运算,没有利用不同通道在相同空间位置上的信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
Pointwise Convolution就是1*1卷积。卷积核尺寸为 1×1×M,M为上一层的通道数,所以这里的卷积运算会将上一步Depthwise Convolution的结果在深度方向上进行加权组合。
为了解决组内Pointwise卷积的通道通信困难问题,ShuffleNet v1提出了通道洗牌(Channel Shuffle)操作。

最早Depthwise Separable Convolution就是Depthwise卷积+pointwise卷积,为了改进性能把整个pointwise改为了分组pointwise,
引入shuffle后为Depthwise卷积+分组pointwise卷积+shuffle。
shufflenet v2提出四条设计准则,并基于此改进了v1。
















 3952
3952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









