







文章启发点:
- 通过使用语义分割的图像作为输入,缩小了模拟数据和真实数据之间的真实差距。我觉得这个方法很有启发性,当训练数据不足时可以选择生成模拟数据训练,但对于纹理信息难以仿真时可以选择生成数据的深层特征形式进行训练,至于提取纹理信息可以由其他数据集进行训练,或者应对这种短期数据不足来验证想法的正确性,并加速收敛。
abstract
准确的环境感知对于自动驾驶至关重要。当使用单目相机时,环境中元素的距离估计是一个重大挑战。当相机视角转换为鸟瞰图(BEV)时,可以更容易地估计距离。对于平坦表面,逆透视映射(IPM)可以将图像准确地转换为BEV。三维对象(如车辆和易受伤害的道路使用者)会因这种转换而变形,因此很难估计其相对于传感器的位置。本文通过多个车载相机视角利用IPM得到BEV视图并设计网络进行校正,然后拼接成360°BEV,校正后的BEV图像被分割成语义类并且包括遮挡区域的预测。
总结就是,利用了IPM和神经网络结合来进行透视变换。
background
IPM相关
IPM假设世界是平的。任何三维对象和不断变化的道路高程都违反了这一假设。
因此,将所有像素映射到平面会导致此类对象的强烈视觉失真。这妨碍了我们在车辆环境中准确定位物体目标。因此,通过IPM变换的图像通常仅作为车道检测或自由空间计算算法的输入.
methodology
A.groundtruth image 如何对遮挡标记:
由于存在各种遮挡情况,为了形成一个适定性问题,需要为BEV中的区域引入一个额外的语义类,这些区域在摄像机透视图中被遮挡。在预处理步骤中,将该类引入地面真值标签图像。对于每个车辆摄像头,投射虚拟光线,通过边缘就能获得遮挡区域。

B.透射预处理

P矩阵可以看作由世界坐标系到图像坐标系的透射矩阵

K可看作相机的内参矩阵,用于相机坐标系到图像坐标系的转换,【R|T】可以看作是相机外参矩阵,代表旋转和平移,用于世界坐标系到相机坐标系的转换。

M代表从道路平面坐标系到世界坐标系的转换

所以得到了从图像坐标系到路面坐标系的转换
注意:猛地一看是不是觉得可以直接转换,事实上是P矩阵是不可逆的,因为一条射线无限多的世界坐标系上的点对应于同一个像素,怎么办呢,为了是计算能够进行,我们假设存在一个M矩阵,使得PM矩阵可逆,并进行接下来的计算。
C.变体模型1:单输入模型
该模型的输入是:对车上每个摄像头(4个)作前面预处理操作即IPM,得到BEV,然后将这四个只有局部视野的BEV视图联合拼接覆盖整个区域,得到一个单应性图片作为输入。
该网络的主要作用:纠正IPM进行逆透视变换引入的误差。
模型架构:选择DeepLabv3+作为单网络输入模型的架构。DeepLabv3+是用于语义图像分割的最先进的CNN。使用MobileNetV2和Xception,测试了两个不同的网络主干。
D.变体模型2:多输入模型
该模型输入是:未处理的车载摄像机图像(4个)。
模型思路:在未变换的摄像机视图中提取特征,因此不完全受到IPM引入的错误的影响。作为处理空间不一致问题的一种方法,将投影变换(IPM)集成到网络中。
模型架构:由于其简单性和易扩展性,选择流行的语义分段架构U-Net。如图分别基于连续池化和上采样的卷积编码器和解码器路径。如下图所示,四个视角的图片未进行预处理,而是分别进行卷积,卷积后的四个输出有两条路径,一条(灰色线)直接进行IPM变换然后拼接(即图四所进行的操作),另一条(绿色)则进行进一步卷积池化下采样,然后四个输出又面临刚才一样的选择。整体来看就是特征金字塔的结构,在卷积池化的不同阶段存在不同尺度的特征图,然后对每种尺度都进行IPM变换拼接,得到不同尺度的鸟瞰图,最后小尺度特征图再上采样到原图尺度进行特征融合(图中是逐级上采样顺序融合),最后softmax语义分割。


Experiment
训练数据
完全采用模拟数据进行的网络训练。做了两个数据集,一个是多摄像机,九个语义类;一个单摄,三个语义类,这个是为了测试实际应用。合成数据集1总共包含约33000个用于训练的样本和3700个用于验证的样本,其中每个样本是一组多个输入图像和一个地面真值标签。合成数据集2包含大约32000个用于训练的样本和3200个用于验证的样本。
训练结果
A-利用合成数据:

带*指的是没有应用单应性变化 ,只用了卷积网络(即消融实验)。

没有IPM(*)的模型的性能始终低于其对应模型。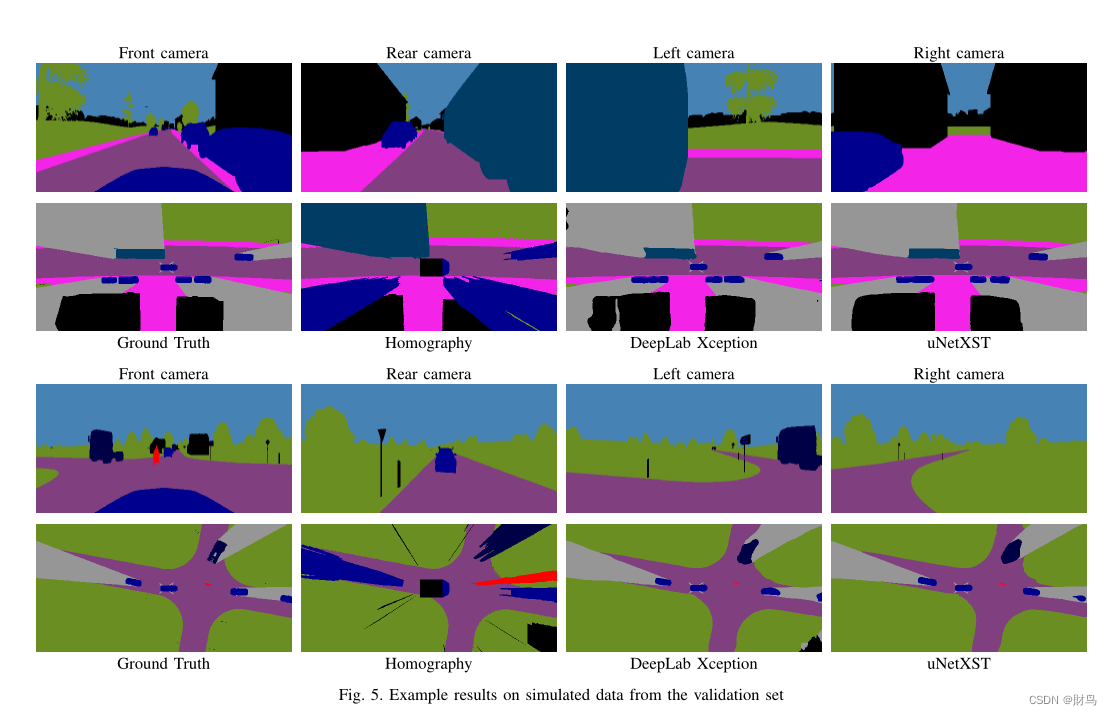
与单应图像相比,我们的两种方法都成功地消除了IPM引入的误差。此外,他们合理地预测了BEV中的区域,这些区域从车辆摄像头的角度被遮挡。
B-真实世界应用
为了在真实世界数据上测试,需要一种获得语义分割的摄像机图像的方法,作为模型的输入。为此,我们使用额外的CNN进行语义分割。测试结果如图:

这两个模型都对其他交通参与者的位置和维度做出了合理的预测,但uNetXST模型产生了更平滑、质量更好的结果。
原文:《A Sim2Real Deep Learning Approach for the Transformation of Images from Multiple Vehicle-Mounted Cameras to a Semantically Segmented Image in Bird’s Eye View*》
https://arxiv.org/pdf/2005.04078v1.pdf
代码:A Sim2Real Deep Learning Approach for the Transformation of Images from Multiple Vehicle-Mounted Cameras to a Semantically Segmented Image in Bird's Eye View | Papers With Code
仅个人阅读分享,存在问题欢迎指出。














 7469
7469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









