






大模型简介
什么是大模型
大模型是指具有大规模参数和复杂计算结构的机器学习模型,本质上是一个使用海量数据训练而成的深度神经网络模型,其巨大的数据和参数规模,实现了智能的涌现,展现出类似人类的智能。
大模型的发展历程
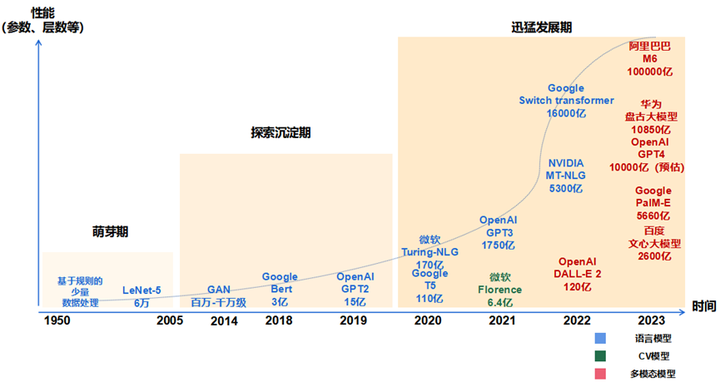
萌芽期(1950-2005):以 CNN 为代表的传统神经网络模型阶段
- 1956 年,从计算机专家约翰·麦卡锡提出“人工智能”概念开始,AI 发展由最开始基于小规模专家知识逐步发展为基于机器学习。
- 1980 年,卷积神经网络的雏形 CNN 诞生。
- 1998 年,现代卷积神经网络的基本结构 LeNet-5 诞生,机器学习方法由早期基于浅层机器学习的模型,变为了基于深度学习的模型,为自然语言生成、计算机视觉等领域的深入研究奠定了基础,对后续深度学习框架的迭代及大模型发展具有开创性的意义。
探索沉淀期(2006-2019):以 Transformer 为代表的全新神经网络模型阶段
- 2013 年,自然语言处理模型 Word2Vec 诞生,首次提出将单词转换为向量的“词向量模型”,以便计算机更好地理解和处理文本数据。
- 2014 年,被誉为 21 世纪最强大算法模型之一的 GAN(对抗式生成网络)诞生,标志着深度学习进入了生成模型研究的新阶段。
- 2017 年,Google 颠覆性地提出了基于自注意力机制的神经网络结构——Transformer 架构,奠定了大模型预训练算法架构的基础。
- 2018 年,OpenAI 和 Google 分别发布了 GPT-1 与 BERT 大模型,意味着预训练大模型成为自然语言处理领域的主流。在探索期,以 Transformer 为代表的全新神经网络架构,奠定了大模型的算法架构基础,使大模型技术的性能得到了显著提升。
迅猛发展期(2020-至今):以 GPT 为代表的预训练大模型阶段
- 2020 年,OpenAI 公司推出了GPT-3,模型参数规模达到了 1750 亿,成为当时最大的语言模型,并且在零样本学习任务上实现了巨大性能提升。随后,更多策略如基于人类反馈的强化学习(RHLF)、代码预训练、指令微调等开始出现, 被用于进一步提高推理能力和任务泛化。
- 2022 年 11 月,搭载了GPT3.5的 ChatGPT横空出世,凭借逼真的自然语言交互与多场景内容生成能力,迅速引爆互联网。
- 2023 年 3 月,最新发布的超大规模多模态预训练大模型——GPT-4,具备了多模态理解与多类型内容生成能力。在迅猛发展期,大数据、大算力和大算法完美结合,大幅提升了大模型的预训练和生成能力以及多模态多场景应用能力。如 ChatGPT 的巨大成功,就是在微软Azure强大的算力以及 wiki 等海量数据支持下,在 Transformer 架构基础上,坚持 GPT 模型及人类反馈的强化学习(RLHF)进行精调的策略下取得的。
大模型的特点
- 巨大的规模: 大模型包含数十亿个参数,模型大小可以达到数百 GB 甚至更大。巨大的模型规模使大模型具有强大的表达能力和学习能力。
- 涌现能力:涌现(英语:emergence)或称创发、突现、呈展、演生,是一种现象,为许多小实体相互作用后产生了大实体,而这个大实体展现了组成它的小实体所不具有的特性。引申到模型层面,涌现能力指的是当模型的训练数据突破一定规模,模型突然涌现出之前小模型所没有的、意料之外的、能够综合分析和解决更深层次问题的复杂能力和特性,展现出类似人类的思维和智能。涌现能力也是大模型最显著的特点之一。
- 更好的性能和泛化能力:大模型通常具有更强大的学习能力和泛化能力,能够在各种任务上表现出色,包括自然语言处理、图像识别、语音识别等。
- 多任务学习: 大模型通常会一起学习多种不同的 NLP 任务,如机器翻译、文本摘要、问答系统等。这可以使模型学习到更广泛和泛化的语言理解能力。
- 大数据训练: 大模型需要海量的数据来训练,通常在 TB 以上甚至 PB 级别的数据集。只有大量的数据才能发挥大模型的参数规模优势。
- 强大的计算资源: 训练大模型通常需要数百甚至上千个 GPU,以及大量的时间,通常在几周到几个月。
- 迁移学习和预训练:大模型可以通过在大规模数据上进行预训练,然后在特定任务上进行微调,从而提高模型在新任务上的性能。
- 自监督学习:大模型可以通过自监督学习在大规模未标记数据上进行训练,从而减少对标记数据的依赖,提高模型的效能。
- 领域知识融合:大模型可以从多个领域的数据中学习知识,并在不同领域中进行应用,促进跨领域的创新。
- 自动化和效率:大模型可以自动化许多复杂的任务,提高工作效率,如自动编程、自动翻译、自动摘要等。
大模型的分类
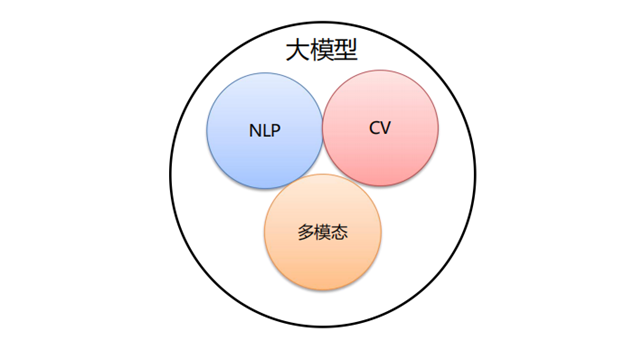
按照输入数据类型的不同,大模型主要可以分为以下三大类:
- 语言大模型(NLP):是指在自然语言处理(Natural Language Processing,NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。这类大模型的主要特点是它们在大规模语料库上进行了训练,以学习自然语言的各种语法、语义和语境规则。例如:GPT 系列(OpenAI)、Bard(Google)、文心一言(百度)。
- 视觉大模型(CV):是指在计算机视觉(Computer Vision,CV)领域中使用的大模型,通常用于图像处理和分析。这类模型通过在大规模图像数据上进行训练,可以实现各种视觉任务,如图像分类、目标检测、图像分割、姿态估计、人脸识别等。例如:VIT 系列(Google)、文心UFO、华为盘古 CV、INTERN(商汤)。
- 多模态大模型:是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。这类模型结合了 NLP 和 CV 的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。例如:DingoDB 多模向量数据库(九章云极 DataCanvas)、DALL-E(OpenAI)、悟空画画(华为)、midjourney。
按照应用领域的不同,大模型主要可以分为 L0、L1、L2 三个层级:
- 通用大模型 L0:是指可以在多个领域和任务上通用的大模型。它们利用大算力、使用海量的开放数据与具有巨量参数的深度学习算法,在大规模无标注数据上进行训练,以寻找特征并发现规律,进而形成可“举一反三”的强大泛化能力,可在不进行微调或少量微调的情况下完成多场景任务,相当于 AI 完成了“通识教育”。
- 行业大模型 L1:是指那些针对特定行业或领域的大模型。它们通常使用行业相关的数据进行预训练或微调,以提高在该领域的性能和准确度,相当于 AI 成为“行业专家”。
- 垂直大模型 L2:是指那些针对特定任务或场景的大模型。它们通常使用任务相关的数据进行预训练或微调,以提高在该任务上的性能和效果。
安装步骤
硬件要求
大模型的运行需要显卡,对于智谱清言,其显卡显存要求如下:
| 量化等级 | 最低 GPU 显存(推理) | 最低 GPU 显存(高效参数微调) |
| FP16(无量化) | 13 GB | 14 GB |
| INT8 | 8 GB | 9 GB |
| INT4 | 6 GB | 7 GB |
环境准备
cuda安装
统一计算设备架构(Compute Unified Device Architecture, CUDA),是由NVIDIA推出的通用并行计算架构。解决的是用更加廉价的设备资源,实现更高效的并行计算。
执行以下命令下载sh安装包后安装
wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda_12.4.1_550.54.15_linux.run
sudo sh cuda_12.4.1_550.54.15_linux.run需要注意的是,如果系统已经安装过显卡驱动,则安装cuda时可以不对显卡驱动进行安装勾选
conda安装
大模型依赖python环境,由于python的版本很多,不同版本的管理稍显繁杂。conda是一个用来管理python环境的工具,我们需要使用conda来进行python的环境创建。
从Anaconda | The Operating System for AI 官网下载安装包,执行以下命令安装
sh Anaconda3-2024.02-1-Linux-x86_64.sh结束时提示是否初始化,输入yes并回车后,重启终端即可
由于conda国外镜像下载过慢,安装后可以手动设置国内镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/使用以下命令进行验证
conda config --show channelspython虚拟环境创建
安装完成后进行python环境的创建,执行以下命令创建一个python版本为3.11.x,名字为py311的虚拟环境,其会提示下载一些包,输入y并回车即可自动安装
conda create -n py311 python=3.11安装完成后,执行以下命令以切换到py311环境
conda activate py311git-lfs安装
由于需要下载较大的模型文件,需要安装大文件版本控制的git扩展
在官网https://git-lfs.com/下载压缩文件并解压后,进入解压目录,执行以下命令进行安装
sh install.sh模型文件下载
从https://github.com/THUDM/ChatGLM-6B克隆代码到本地
git clone https://github.com/THUDM/ChatGLM-6B.git由于模型文件网站huggingface在国内无法访问,模型文件需要从
https://modelscope.cn/models/ZhipuAI/chatglm3-6b/summary 进行下载
在chatglm代码克隆文件夹下创建文件夹models,进入目录进行模型文件的下载
mkdir models
cd models
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git依赖安装
模型文件都下载完成后,需要执行环境依赖安装
进入chatglm代码克隆文件夹,执行以下命令进行依赖安装
pip install -r requirements.txt检查安装成功
在安装完上述包后,可以使用chatglm代码克隆文件夹下basic_demo里的demo进行模型安装检验,但还是需要一定的调整才可使用
- 拷贝web_demo_gradio.py文件到web_demo_gradio_int4.py
cp web_demo_gradio.py web_demo_gradio_int4.py- 修改web_demo_gradio_int4.py内容,如下
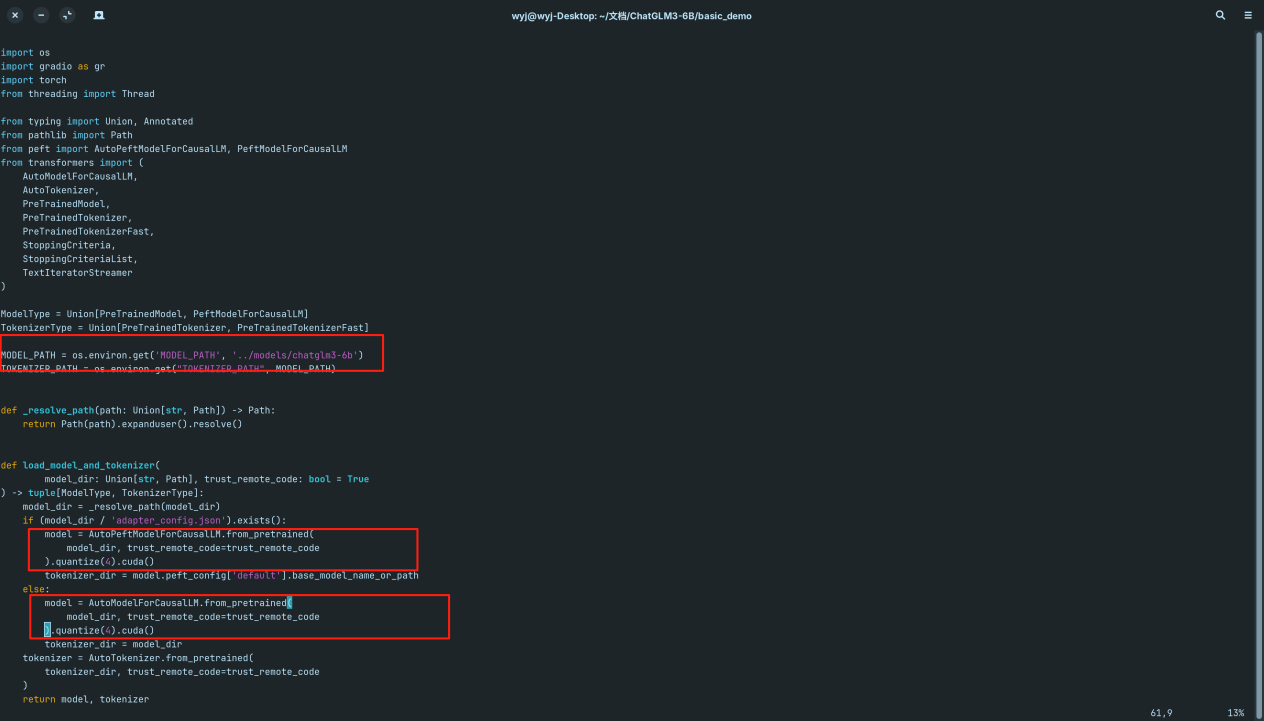
改为使用本地模型文件,并进行int4量化后再进行使用
最后我们使用此文件进行大模型demo调用
python web_demo_gradio_int4.py使用
使用示例
对话
工具调用
模型的微调
多轮对话格式
多轮对话微调示例采用 ChatGLM3 对话格式约定,对不同角色添加不同 loss_mask 从而在一遍计算中为多轮回复计算 loss。
对于数据文件,样例采用如下格式
仅训练对话能力,按照以下格式整理数据。
[
{
"conversations": [
{
"role": "system", -- 系统提示词,指明模型扮演的角色等信息
"content": "<system prompt text>"
},
{
"role": "user", -- 用户输入
"content": "<user prompt text>"
},
{
"role": "assistant", -- 模型回复
"content": "<assistant response text>"
},
// ... Muti Turn
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
}
]
}
// ...
]
请注意,这种方法在微调的step较多的情况下会影响到模型的工具调用功能
如果想微调模型的对话和工具能力,按照以下格式整理数据。
[
{
"tools": [
// available tools, format is not restricted
],
"conversations": [
{
"role": "system",
"content": "<system prompt text>"
},
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant thought to text>"
},
{
"role": "tool",
"name": "<name of the tool to be called",
"parameters": {
"<parameter_name>": "<parameter_value>"
},
"observation": "<observation>" -- 工具调用、代码执行结果
// don't have to be string
},
{
"role": "assistant",
"content": "<assistant response to observation>"
},
// ... Muti Turn
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
}
]
}
// ...
]
- 关于工具描述的 system prompt 无需手动插入,预处理时会将 tools 字段使用 json.dumps(..., ensure_ascii=False) 格式化后插入为首条 system prompt。
- 每种角色可以附带一个 bool 类型的 loss 字段,表示该字段所预测的内容是否参与 loss 计算。若没有该字段,样例实现中默认对 system, user 不计算 loss,其余角色则计算 loss。
- tool 并不是 ChatGLM3 中的原生角色,这里的 tool 在预处理阶段将被自动转化为一个具有工具调用 metadata 的 assistant 角色(默认计算 loss)和一个表示工具返回值的 observation 角色(不计算 loss)。
- 目前暂未实现 Code interpreter 的微调任务。
- system 角色为可选角色,但若存在 system 角色,其必须出现在 user 角色之前,且一个完整的对话数据(无论单轮或者多轮对话)只能出现一次 system 角色。
数据集格式
{"conversations": [{"role": "user", "content": "key#value*key#value"}, {"role": "assistant", "content": "xxx"}]}
配置文件
微调配置文件位于 config 目录下,包括以下文件:
ds_zereo_2 / ds_zereo_3.json: deepspeed 配置文件。
lora.yaml / ptuning.yaml / sft.yaml: 模型不同方式的配置文件,包括模型参数、优化器参数、训练参数等。 部分重要参数解释如下:
data_config 部分
train_file: 训练数据集的文件路径。
val_file: 验证数据集的文件路径。
test_file: 测试数据集的文件路径。
num_proc: 在加载数据时使用的进程数量。
max_input_length: 输入序列的最大长度。
max_output_length: 输出序列的最大长度。
training_args 部分
output_dir: 用于保存模型和其他输出的目录。
max_steps: 训练的最大步数。
per_device_train_batch_size: 每个设备(如 GPU)的训练批次大小。
dataloader_num_workers: 加载数据时使用的工作线程数量。
remove_unused_columns: 是否移除数据中未使用的列。
save_strategy: 模型保存策略(例如,每隔多少步保存一次)。
save_steps: 每隔多少步保存一次模型。
log_level: 日志级别(如 info)。
logging_strategy: 日志记录策略。
logging_steps: 每隔多少步记录一次日志。
per_device_eval_batch_size: 每个设备的评估批次大小。
evaluation_strategy: 评估策略(例如,每隔多少步进行一次评估)。
eval_steps: 每隔多少步进行一次评估。
predict_with_generate: 是否使用生成模式进行预测。
generation_config 部分
max_new_tokens: 生成的最大新 token 数量。
peft_config 部分
peft_type: 使用的参数有效调整类型(如 LORA)。
task_type: 任务类型,这里是因果语言模型(CAUSAL_LM)。
Lora 参数:
r: LoRA 的秩。
lora_alpha: LoRA 的缩放因子。
lora_dropout: 在 LoRA 层使用的 dropout 概率
P-TuningV2 参数:
num_virtual_tokens: 虚拟 token 的数量。
微调
运行微调
通过以下代码执行 单机单卡 运行
python finetune_hf.py data/AdvertiseGen/ THUDM/chatglm3-6b configs/lora.yaml从保存点进行微调
如果按照上述方式进行训练,每次微调都会从头开始,如果你想从训练一半的模型开始微调,你可以加入第四个参数,这个参数有两种传入方式:
python finetune_hf.py AdvertiseGen/ THUDM/chatglm3-6b configs/lora.yaml yes自动从最后一个保存的 Checkpoint开始训练
python finetune_hf.py AdvertiseGen/ THUDM/chatglm3-6b configs/lora.yaml XX断点号数字 例 600 则从序号600 Checkpoint开始训练
使用微调后的模型
在 inference_hf.py 中验证微调后的模型
可以在 finetune_demo/inference_hf.py 中使用微调后的模型,仅需要一行代码就能简单的进行测试。
python inference_hf.py your_finetune_path --prompt your prompt这样,得到的回答就微调后的回答了。















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









