







 当机器学习模型在训练集和测试集表现差距大时,可采取多种措施改善,如增加样本数、特征选择、正则化等。过拟合时可通过减少特征、增加正则化;欠拟合时可增加特征、减少正则化。模型评估方法包括绘制图像、划分训练集测试集,以及使用交叉验证集。学习曲线能帮助识别模型的过拟合或欠拟合状态,指导数据收集和模型优化。
当机器学习模型在训练集和测试集表现差距大时,可采取多种措施改善,如增加样本数、特征选择、正则化等。过拟合时可通过减少特征、增加正则化;欠拟合时可增加特征、减少正则化。模型评估方法包括绘制图像、划分训练集测试集,以及使用交叉验证集。学习曲线能帮助识别模型的过拟合或欠拟合状态,指导数据收集和模型优化。
以我们前面讲述的线性回归为例,比如我们在训练集上训练出最优的模型,但是当我们将其使用到测试集时,测试的误差很大,我们该怎么办?
我们一般采取的措施主要包括以下6种:
- 增加训练样本的数目(该方法适用于过拟合现象时,解决高方差。一般都是有效的,但是代价较大,如果下面的方法有效,可以优先采用下面的方式);
- 尝试减少特征的数量(该方法适用于过拟合现象时,解决高方差);
- 尝试获得更多的特征(该方法适用于欠拟合现象时,解决高偏差);
- 尝试增加多项式特征(该方法适用于欠拟合现象时,解决高偏差);
- 尝试减小正则化程度 λ (该方法适用于欠拟合现象时,解决高偏差);
- 尝试增加正则化程度 λ (该方法适用于过拟合现象时,解决高方差);
上面的方法不是随机选择,是在合适的情况下(过拟合和欠拟合)选择合适的方法,对于怎么判断一个模型是过拟合还是欠拟合,我们会在下面给出一些机器学习诊断法。
如何对一个假设进行评估?
我们前面在讲述线性回归和逻辑回归时,只是注重针对训练数据集训练出一个最优的参数,但是我们训练处的模型对于测试集的性能好坏我们没有进行判断,我们只是训练的模型使得损失函数最小,我们前面也讨论过,在训练数据集上损失函数最小并不能代表对于给定的测试数据,测试数据的评估非常准确,比如过拟合现象发生时,那我们如何评价一个假设的好坏呢?
主要的方法包括两种:
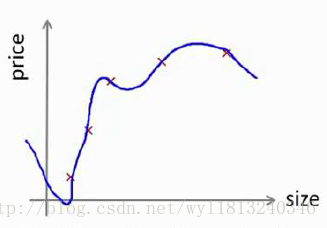
1.对于简答的模型,我们可以采用将 hθ(x) 的图像画出,来判断模型的好坏,但是这种方法对于特征变量不是一个时,这种方法很难实现或者不可能实现。例如我们曾经看到过这样的图像,可以通过 hθ(x) 的图像明显可以看出,该假设存在着过拟合现象。
2.另一种评估假设的方法为:将原来的数据集分为训练集和测试集,一般我们是从原来的数据集中随机选取(保证训练集和测试集中都含有各种类型的数据)70%的数据作为训练集,剩下的30%的样本作为测试集。同时这种将原来数据集划分为训练集和测试集的方法可以用于帮助特征选择、多项式次数的选择以及正则化参数的选择等。数据集划分的过程如下:
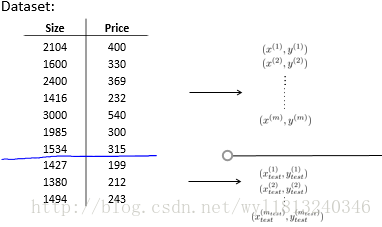
以上面数据集为例,选取前7个为训练集,后3个为测试集。用前7个数据集做训练训练出一个最优的模型,评价这个训练出的模型的好坏可以使用测试集来进行判断,判断的标准可以使用测试集的损失函数来进行定量的衡量。
对于回归问题,测试集的损失函数计算公式如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3402
3402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









