







李宏毅机器学习之Anomaly Detection
要解决的问题
给定一个数据集,我们想要找到一个函数可以区分输入x是否相似于数据集
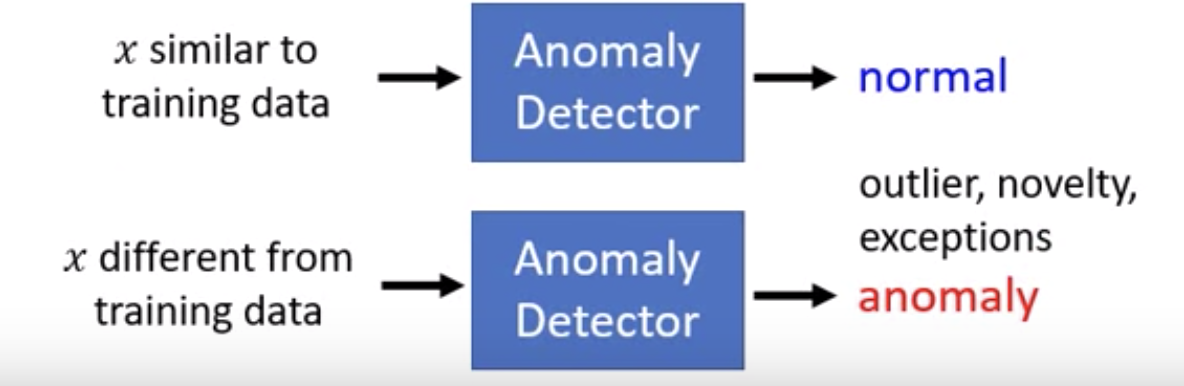
什么是异常

异常侦测的应用

为什么不用二分类来侦测异常呢,正常的为一类,异常的为一类
如果正常的一类就是我们的训练数据集,拥有共性和相近的特征,那异常的一类里面的东西就太离散了,你根本无法穷举所有的异常,换句话说,不是正常的就都是异常,这也是我们为什么不用二分类侦测异常的原因。而且很多时候很难收集到异常的资料。

异常侦测的分类

1. 异常侦测的一般框架(有标签lable的情况)
对于上述的训练集有label的情况,我们应该如何侦测异常呢?

因为是有标签的,所以可以训练一个分类器了

对于输入的数据,会计算出一个信心分数,如果分数很高,就说明它属于这个类别的信心很大,我们设定一个阈值,如果大于阈值,就是正常数据,如果小于阈值,就是异常数据


然后李老师做了个实验,侦测了一下,发现正常的数据还是蛮准的,但是异常数据中识别出是柯阿三的概率比较高,那么为什么呢,柯阿三是谁呢?

柯阿三就是下图的人物,我们可以看出来柯阿三与辛普森家族长的本来就差异挺大QAQ,所以异常值很容易被识别成柯阿三


下面这个文献有时间可以看看


因此如何通过dev set(验证集)来评估我们异常侦测模型的好坏呢?
我们之前二元分类任务是通过正确率来衡量模型的好坏,但是在异常侦测中,准确率并不是一个好的衡量标准,因为往往会有较多的正常数据,极少的异常数据,他们分布很不平均
因此λ设置很小时,把所有的数据都认为是正常的,那会得到很高的accuracy(准确率),但是呢,这不是我们想要的!

当λ阈值设置为0.54时
当阈值设置为0.8时的结果

那么上述的两种不同的λ,哪个好哪个坏呢?很难说
因为根据不同的分值设定,比如:
(1)如果一个正常的东西误判为异常的就扣100分,没有侦测出的异常值就扣1分
(2)或者一个正常的东西误判为异常的就扣1分,没有侦测出的异常值就扣100分

所以一个异常侦测系统的好坏是跟具体情况具体分析















 5130
5130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









