



已更新全部1-3问代码和文章,完整内容请看文末简介
物流理赔风险识别及服务升级问题
摘要
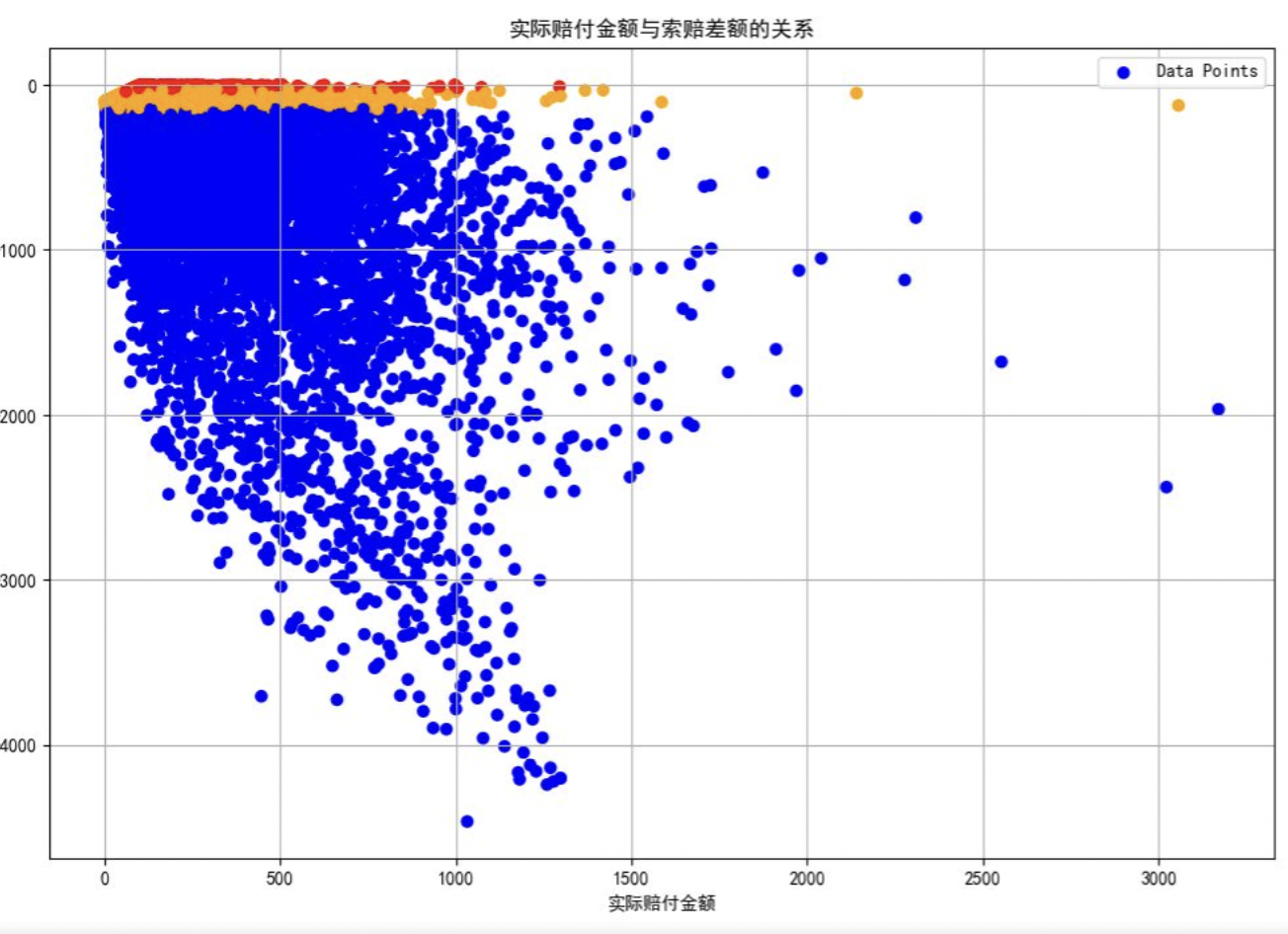
在本研究中,我们针对问题一,提出了一种基于分位数回归与保序回归的风险标注方法。首先,计算了每条运单的索赔差额,并基于实际赔付金额将数据进行等频分箱。接着,使用80%和97%分位数作为合理诉求与诉求偏高、诉求偏高与严重超额的边界,并通过保序回归平滑分位数边界,确保随着赔付金额的增加,风险分类的阈值逐渐上升。最后,为避免“严重超额”类别样本占比过高,我们对分类结果进行了校准。
针对问题二构建一个基于随机森林回归的模型,预测物流运单的实际赔付金额。通过对数据集中的数值型和类别型特征进行标准化和独热编码处理,模型成功地捕捉了影响赔付金额的关键因素,包含实际赔付金额差额和运输节点事故率。模型评估结果表明,随机森林回归能够有效预测大多数运单的赔付金额,尤其在中低赔付金额的预测上表现出色。然而,残差分析揭示,随着预测金额的增加,模型在高赔付金额区域的误差逐渐放大,提示未来需要进一步优化模型以处理特殊情况。通过特征重要性分析,我们发现结果是对赔付金额预测贡献最大的特征,为后续优化和决策提供了有力依据。
问题三通过随机森林回归模型对物流理赔数据进行分析,旨在预测未来运单的实际赔付金额。在数据预处理阶段,我们对缺失值进行了处理,选取了与赔付金额高度相关的特征,并对数据进行了标准化和独热编码。模型训练后,结果表明,随机森林回归模型在预测赔付金额方面表现出较高的准确性,R²值接近0.95,均方误差较低。可视化分析显示,模型能够有效区分“合理诉求”和“诉求偏高”类别,而在“严重超额”类别的预测中存在一定的误差,主要由于该类别样本稀少且赔付金额波动较大。特征重要性分析表明,运单保价金额和起始节点的发单量对模型预测贡献最大。
关键词:随机森林、保序回归

目录
物流理赔风险识别及服务升级问题 1
摘要 1
一、 问题重述 3
1.1 问题背景 3
1.2 要解决的问题 3
二、 问题分析 5
2.1 任务一的分析 5
2.2 任务二的分析 5
2.3 任务三的分析 5
三、 问题假设 6
四、 模型原理 7
4.1 随机森林模型 7
4.2 保序回归模型 8
五、 模型建立与求解 10
5.1 问题一建模与求解 10
5.2 问题二建模与求解 15
5.3 问题三建模与求解 19
六、 模型评价与推广 29
6.1 模型的评价 29
6.1.1模型优点 29
6.1.2模型缺点 30
6.2 模型推广 31
附录【自行删减】 32
本文所建立模型具有以下优点 :
1.方法合理,贴合业务逻辑.本文在风险标注环节引入分位数回归与保序回归相结合的策略,不仅保障了风险阈值的单调性,还充分考虑了赔付金额与索赔差额之间的非线性关系,具有良好的解释性与实用性。
2.建模体系完整,预测性能优异.在赔付金额预测方面,采用随机森林回归模型,能够有效挖掘特征间复杂的非线性关系。模型在测试集上的决定系数(R²)接近 0.95,说明其在中低赔付金额区间具有较高的拟合精度,能够为企业提供可靠的数值预测支撑。
3.特征工程完善,适应性强.对于包含多类型特征的数据,本文通过标准化、独热编码等预处理操作,使模型在高维特征空间中仍具有良好的泛化能力。此外,模型通过特征重要性分析揭示了保价金额、运输节点事故率等关键因素,为后续业务优化提供了依据。
4.考虑类别不平衡问题,提升分类稳定性.在构建分类模型时,通过风险标签占比校准与分界值动态调整的方式,有效控制了“严重超额”类别的比例,有助于提升模型在实际业务中对极端索赔行为的识别能力。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.isotonic import IsotonicRegression
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决坐标轴负数显示问题
# 1. 数据加载与预处理
df_train = pd.read_excel('附件1.xlsx') # 读取附件1数据
df_test = pd.read_excel('附件2.xlsx') # 读取附件2数据
# 计算索赔差额
df_train['D'] = df_train['payment_real_money'] - df_train['payment_contract_money'] # 索赔差额 = 实际赔付金额 - 索赔金额
# 2. 分箱处理(用于计算风险标注)
# 根据实际赔付金额(payment_real_money)对数据进行等频分箱
df_train['A_bin'] = pd.qcut(df_train['payment_real_money'], q=20, duplicates='drop') # 使用20个等频箱
# 3. 计算每个分箱内的索赔差额的分位数(80%和97%)作为风险标注的边界
q1_series = df_train.groupby('A_bin')['D'].quantile(0.80) # 80%分位,作为合理/偏高的边界
q2_series = df_train.groupby('A_bin')['D'].quantile(0.97) # 97%分位,作为偏高/严重超额的边界
# 4. 提取每个分箱的中心点(即实际赔付金额的中位数)
A_mid = df_train.groupby('A_bin')['payment_real_money'].median()
# 5. 保序回归平滑
iso1 = IsotonicRegression(increasing=True) # 保序回归模型
iso2 = IsotonicRegression(increasing=True)
# 对第80分位和第97分位进行回归拟合
Q1 = iso1.fit_transform(A_mid.values, q1_series.values)
Q2 = iso2.fit_transform(A_mid.values, q2_series.values)
# 6. 使用回归模型计算Q1(A)和Q2(A)
def get_risk_label(row):
actual_comp = row['payment_real_money']
D = row['D']
# 使用回归模型计算对应的Q1(A)和Q2(A)
Q1_A = np.interp(actual_comp, A_mid.values, Q1)
Q2_A = np.interp(actual_comp, A_mid.values, Q2)
# 根据阈值划分类别
if D <= Q1_A:
return '合理诉求'
elif Q1_A < D <= Q2_A:
return '诉求偏高'
else:
return '严重超额'
# 7. 对训练数据进行风险标注
df_train['risk_label'] = df_train.apply(get_risk_label, axis=1)
# 8. 数据预处理:准备训练数据
# 将标注好的训练数据的“risk_label”转为分类变量(标签编码)
df_train['risk_label'] = df_train['risk_label'].map({'合理诉求': 0, '诉求偏高': 1, '严重超额': 2})
# 选择用于训练的特征(删除无关特征)
features = ['route_type', 'is_customer_to_customer', 'is_fresh_and_delv_promise', 'waybill_price_protect_money',
'start_city_id', 'end_city_id', 'consigner_id', 'receiver_id', 'is_staff',
'plan_delv_to_real_delv_diff', 'abnormal_reason', 'source', 'real_delv_to_case_create_diff',
'payment_contract_money', 'goods_category', 'goods_level', 'bc_source', 'customer_role',
'start_node_waybill_num', 'start_node_accident_rate', 'start_node_real_claim_num_ratio',
'end_node_waybill_num', 'end_node_accident_rate', 'end_node_real_claim_num_ratio']
X_train = df_train[features]
y_train = df_train['risk_label']
# 9. 特征处理
# 对数值特征进行标准化,对类别特征进行独热编码
numeric_features = X_train.select_dtypes(include=['float64', 'int64']).columns
categorical_features = X_train.select_dtypes(include=['object']).columns
numeric_transformer = StandardScaler()
categorical_transformer = OneHotEncoder(handle_unknown='ignore')
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
# 10. 创建模型:使用随机森林分类器进行预测
clf = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', RandomForestClassifier(n_estimators=100, random_state=42))
])
# 训练模型
clf.fit(X_train, y_train)

















 1448
1448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









