







正在补充…
参考资料
- EasyRL:github,Gitee(国内方便)
- 人人都能看懂的RL-PPO理论知识
- GAE Paper:HIGH-DIMENSIONAL CONTINUOUS CONTROL USING GENERALIZED ADVANTAGE ESTIMATION
- 【深度强化学习 CS285 2023】伯克利—中英字幕
- 强化学习算法梳理:从 PPO 到 GRPO 再到 DAPO
- https://huggingface.co/blog/NormalUhr/rlhf-pipeline#navigating-the-rlhf-landscape-from-policy-gradients-to-ppo-gae-and-dpo-for-llm-alignment
- 深度好文!从LLM的视角看策略梯度、PPO、GRPO
- 《强化学习的数学原理》
- 知乎:强化学习知识大讲堂
- 知乎:Actor-Critic算法小结
- PPO 算法的37个实现细节
- Policy Gradient Algorithms,Author: Lilian Weng
- A (Long) Peek into Reinforcement Learning
Policy Gradient
先跳过,待补充
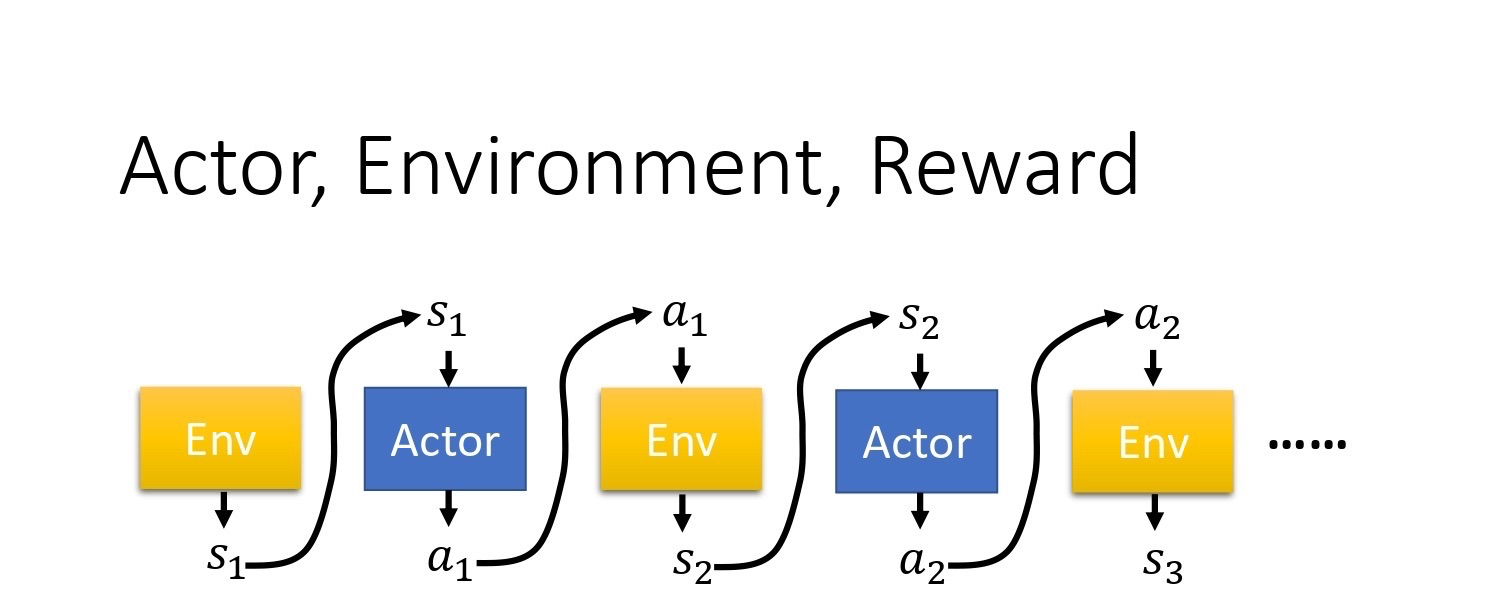
Trajectory τ = { s 1 , a 1 , s 2 , a 2 , ⋯ , s t , a t } \text { Trajectory } \tau=\left\{s_{1}, a_{1}, s_{2}, a_{2}, \cdots, s_{t}, a_{t}\right\} Trajectory τ={s1,a1,s2,a2,⋯,st,at}

















 1891
1891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









