







深度强化学习背景
为什么会有深度强化学习这个东东???为什么不使用监督学习???
从监督学习到强化学习
众所周知,监督学习可以描述为给定输入和预先设定好的ground truth(标签),训练一个完整的网络,从而完成输入向量到输出值的映射,使得预测值尽可能接近ground truth,之后迁移到新的场景中,大多数监督学习更多针对的是感知任务,但是仅有监督学习是难以被用于学习与环境的交互,原因有三点:
- 难以获得在与环境的交互中针对环境的situation应该采取的正确behavior(action);
- 难以获得在与环境的交互中足够多的具有代表性的situation-behavior对(即样本);
- 对于从未涉及过的领域,样本是很难获得的,agent只能根据自己的经历来学习如何与环境互动,即自己产生样本来让自己学习。
换句话说,仅仅能识别能预测对于AI来说还是不够智能,目前我们需要的是像人类一样进行决策的智能体,一个通知智能体应该同时具备感知、决策的能力,而强化学习做到了这一点。
想象一下你走在一个漆黑的游戏环境里面,你能看见的只有两米范围内的物体,而你需要仅仅凭借这些条件找到仅存的出口,如果通过监督学习来建模这个过程的话,根本无法定义标签值,即使预先训练一个监督学习模型也无法很好的play,因为状态和动作都具有随机性(不确定性)。在一个未知环境下,我们无法确定环境转态转变的状态转移的概率,这个是我们无法确定的,而且强化学习过程基本符合马尔科夫决策过程,即当前状态与过去的历史信息无关,而且产生动作也是一个概率密度/质量函数,具有不确定性(你行走时,当前状态是一个状态、动作累积的过程,可以通过概率表示,状态转移是从环境函数中得到,动作转移是从智能体的决策中得到概率,但是具有不一定的随机性)。

在这个过程中我们也无法去找到一个合适的评价标准去评价当前动作对于整个过程的影响。这个时候,我们就需要再环境中“摸爬滚打”了,例如只有一个游戏规则,往前走给你点食物,碰到墙了体力值减半。。。就这样我们按照规则走,维持自己的体力,边行动边记录,不断更新自己的“大脑”,直到我们找到终点或者体力耗尽完,然后循环往复这个过程慢慢地你学会了怎么抄近道,怎么更快更稳定的行走,直至我们可以很熟练的完成游戏里面任意一个位置都能到达终点,且我们可以如何决定当前动作来让整体的决策更优,逐渐让自己变得更强(当然这只是理想状态下,也有迷失自己的时候)。
监督学习和强化学习区别
以教智能体打游戏为例。分别用监督学习和强化学习去打游戏,核心区别就在于监督学习是试图让智能体复制数据集的行为(从预先提供的样本中学习),而强化学习是让智能体在与环境的交互中逐渐变强(自己产生样本来让自己学习)。具体表现如下:1)监督学习需要为每一帧游戏画面标注尽可能好的操作作为label,因为label的表现就是它的上限。但如果是用强化学习来教智能体打游戏,那就不必完美的操作作为标签,强化学习可以通过reward去鼓励好的操作、惩罚不好的操作,这从policy gradient方法和监督学习更新的梯度就可以看出。2)监督学习需要预先准备好大量“游戏画面-操作”样本作为训练集,如第1点所说,为了让这些样本足够正确,必须由优秀的玩家产生,如果是由正在学习的智能体产生的话并无意义,这只会让其表现原地踏步甚至恶化。强化学习具有针对action的奖惩机制,因此可以自己给自己产生样本,逐渐让自己变强。
深度强化学习
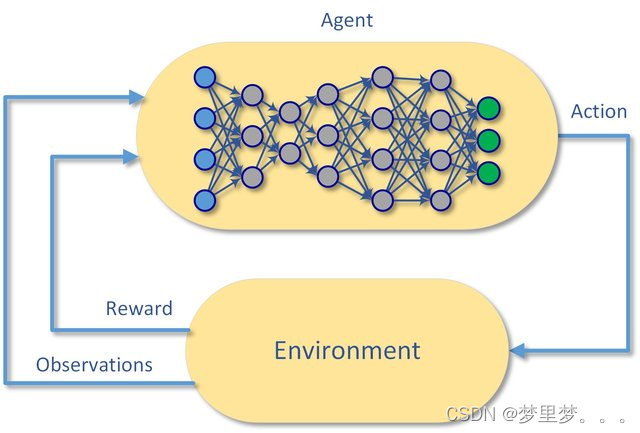
强化学习是机器学习的一个分支,相较于机器学习经典的有监督学习、无监督学习问题,强化学习最大的特点是在交互中学习(Learning from Interaction)。Agent在与环境的交互中根据获得的奖励或惩罚不断的学习知识,更加适应环境,其内核主要对比监督学习多了“探索”的过程,可以发现无法定义的策略任务。RL学习的范式非常类似于我们人类学习知识的过程,也正因此,RL被视为实现通用AI重要途径。
- 传统强化学习:使用基础的数学模型,如马尔可夫决策过程(MDP)来描述问题。常见算法有Q-learning、SARSA等。
- 深度强化学习:在传统强化学习的基础上,加入了深度学习(如卷积神经网络、循环神经网络等)来自动提取特征。
深度强化学习定义
接下来,咱们正式引入深度强化学习,深度强化学习我所理解的其实质是通过策略函数(数学模型,在给定情况下,以深度学习网络作为策略网络,通过特征提取网络、回归网络或者分类网络,采取不同策略的概率或决策方式。)完成状态空间->动作空间的映射。如下图直观地表示: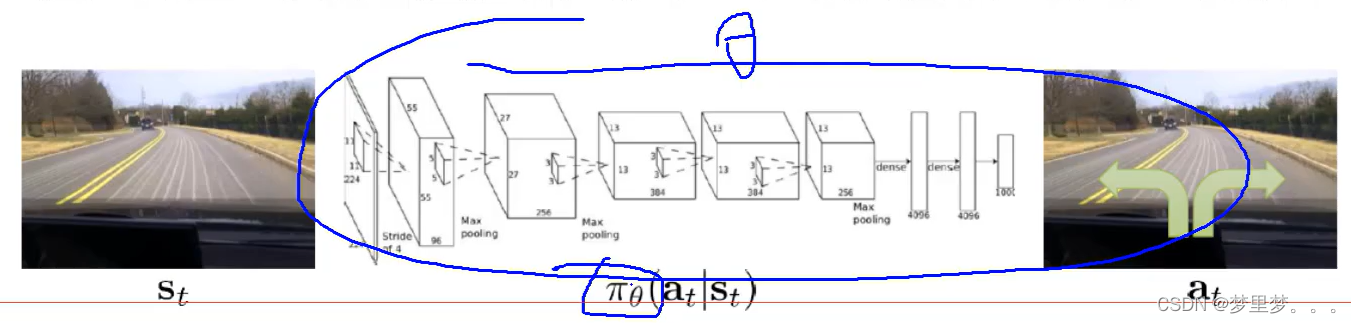
下一篇我们正式介绍深度强化学习















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









