







决策树是常见的机器学习算法。类似于人类在面临决策问题时的自然处理机制,是基于树结构来进行决策的。例如,我们要对“这是好瓜吗?”的问题进行决策,通常会进行一系列的子决策:我们会先看“它是什么颜色?”,如果是青绿色,我们再看“它的根蒂是什么形态?”,如果是“蜷缩”,在判断“它敲起来是什么声音?”最后我们得出最终决策:这个是好瓜,或者不是好瓜。
一般的,一个决策树包含一个根节点、若干个内部节点和若干个根节点。根节点对应于决策结果,其余每个节点对应于一个属性测试,每个节点包含的样本集合根据属性测试的结果被划分到子节点中,根节点包含样本全集。从根节点到叶节点的路径对应了一个判定测试序列。
决策树学习的目的是为了产生一棵泛化能力强的决策树。决策树的生成算法有很多,后面逐个分析学习之。
1 决策树算法
决策树算法就是计算各个Feature的信息增益,选取拥有最大信息增益的Feature,将样本集合划分到Feature的子节点,然后对于Feature的子节点做进一步切分。
1.1 ID3算法
信息熵是度量样本集合纯度常用的一种指标。假设样本集合D中第k类样本所占比例为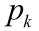
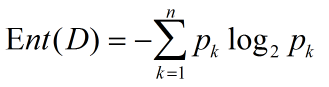
假设Feature A有V个可能的取值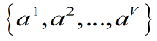
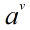
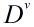
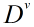
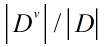
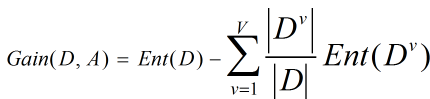
信息增益越大,意味着利用属性A进行划分所获得的纯度提升越大。
1.2 C4.5算法
信息增益率对于可取值数目较多的属性有所偏好,为减少这种偏好,C4.5算法不直接使用信息增益,而是使用增益率来选择最优划分属性。
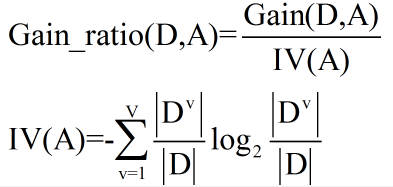
信息增益率对于可取值较少的属性有所偏好,因此C4.5算法并不是直接选择增益率较大的候选划分属性作为划分属性,而是先从划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
1.3 CART决策树算法
CART决策树算法采用Gini index(基尼系数)来选择划分属性,定义如下:
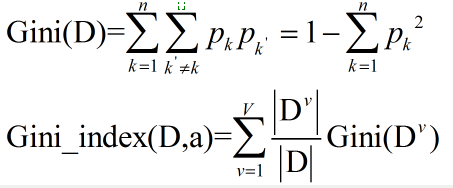
Gini(D)反映了从数据集中随机抽取两个样本,其类别标记为不一致的概率,越小代表数据D纯度越高。
2、剪枝处理
剪枝是决策树算法对付”过拟合”的主要手段,剪枝的基本策略有”预剪枝”和”后剪枝”。预剪枝是在决策树生成过程中,对每个节点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能的提升,则停止划分并将当前结点标记为叶节点;后剪枝则是先从农耕训练集生成一棵完整的决策树,然后自底向上对非叶节点进行考察,若将该节点对应的子树替换为叶节点能提升决策树的泛化能力,则将该子树替换为叶节点。
预剪枝虽然可以降低过拟合的风险,减少决策树的训练时间开销和测试时间开销,但可能导致欠拟合的风险。
后剪枝决策树欠拟合的风险很小,泛化性能往往优于预剪枝决策树,但训练时间开销比预剪枝决策树要大的多。
3、连续与缺失值
3.1 连续值处理
对于连续属性可采用连续属性离散化的方案(比如二分法的方案)对连续属性进行处理。
3.2 缺失值处理

如果样本x在划分属性a上的取值已知,则将x划入与其取值对应的子节点,且样本权重保持为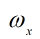















08-03
 1843
1843
1843
09-11
1310
1310
06-18
1185
1185
07-11
2096
2096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









