







第2章 模型评估与选择<1>
1. 数据集在机器学习过程中的分类(训练集、验证集、测试集)
| 类型 | 定义或作用 |
|---|---|
| 训练集(Training set) | 用来训练模型。 |
| 验证集(Validation set) | 模型训练好后,为了找到可以使模型的效果达到最优的超参数,需要用验证集验证出超参数的哪个值比较好,即调参。 |
| 测试集(Test set) | 用模型在测试集上的误差拟合泛化误差,估计泛化性能。 |
(*如何划分见本文第3部分)
2. 过拟合/欠拟合
2.1 经验误差与泛化误差
| 误差类型 | 定义 |
|---|---|
| 经验误差 | 学习器在训练集上的误差,又称为“训练误差”。 |
| 泛化误差 | 学习器在新样本上的误差。 |
2.2 过拟合(定义、产生原因、解决办法)
2.2.1 过拟合的定义
(overfitting)
(1)感觉比较高大上的定义:给定一个假设空间H,一个假设h属于H,如果存在其他的假设h’属于H,使得在训练样例上h的错误率比h’小,但在整个实例分布上h’比h的错误率小,那么就说假设h过度拟合训练数据。
(2)简单的说:模型在训练集上表现的好,在测试集上表现的差。
2.2.2 过拟合的产生原因
- 训练集的样本选取有误,导致训练集数据不足以代表想要实现的分类规则。如样本数量太少、选样方法错误、样本标签错误等。
- 样本噪声干扰过大,使得机器将部分噪音认为是特征从而扰乱了预设的分类规则。
- 假设的模型无法合理存在,或者说是假设成立的条件实际并不成立。
- 参数太多,模型复杂度过高。
- 针对决策树模型:未进行剪枝等操作,导致树的叶子结点只包含单纯的事件数据或非事件数据,使模型可以很好的拟合训练集,无法适应其他的数据样本。
- 针对神经网络模型:
— 对数据样本可能存在分类决策面不唯一,随着学习的进行,BP算法使权值可能收敛过于复杂的决策面。
— 权值学习迭代次数足够多,拟合了训练数据中的噪声和训练样例中没有代表性的特征。
1.2.3 过拟合的解决办法
- 获得更多的训练数据:最有效的手段,更多的样本能够让模型学习到更多更有效的特征,减小噪声的影响。
- 降维:即丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如 PCA )。
- 正则化(regularization) :保留所有的特征,但是减少参数的大小(magnitude),它可以改善或者减少过拟合问题。
- 集成学习方法:把多个模型集成在一起,来降低单一模型的过拟合风险。
- 提前结束训练。
2.3 欠拟合(定义、产生原因、解决办法)
2.3.1 欠拟合的定义
- 模型过于简单不能较好地给出正确结果。
2.3.2 欠拟合的产生原因
- 模型复杂度过低。
- 特征量过少。
2.3.3 欠拟合的解决方法
- 添加新的特征:当特征不足或者现有特征与样本标签的相关性不强时,模型容易出现欠拟合。通过挖掘组合特征等新的特征,往往能够取得更好的效果。
- 增加模型复杂度:简单模型的学习能力较差,通过增加模型的复杂度可以使模型拥有更强的拟合能力。例如,在线性模型中添加高次项,在神经网络模型中增加网络层数或神经元个数等。
- 减小正则化系数:正则化是用来防止过拟合的,但当模型出现欠拟合现象时,则需要有针对性地减小正则化系数。
3.评估方法(即训练集/测试集的划分方法)
- 为什么要划分训练集和测试集:通过实验测试来对学习器的泛化误差进行评估并进而做出选择,为此需要一个测试集来测试学习器对新样本的判别能力,以测试集上的测试误差作为泛化误差的近似。
- 划分训练集和测试集的方法有:留出法(hold-out)、交叉验证法(cross-validation)、自助法(bootstrapping)
3.1 留出法(hold-out)
- 方法简述:直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S ,另一个作为测试集T ,即 D = S U T, S ∩ T = D .在S 上训练出模型后,用 T 来评估其测试误差,作为对泛化误差的估计.
- 注意一:训练/测试集的划分要尽可能保持数据分布的一致性,例如在分类任务中至少要保持样本的类别比例相似(可以看作是分层抽样)。
- 注意二:即便在给定训练/测试集的样本比例后,仍存在多种划分方式对初始数据集D进行分割。单次使用留出法得到的估计结果往往不够稳定可靠,在使用留出法时,一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
- 训练集与测试集的划分比例:常见做法是将大约2/3〜4/ 5的样本用于训练,剩余样本用于测试.
3.2 交叉验证法(cross-validation)
- 一般步骤:
- 先将数据集D 划分为k 个大小相似的互斥子集,每个子集Di 都尽可能保持数据分布的一致性,即从D中通过分层采样得到。
- 然后,每次用k - 1 个子集的并集作为训练集,余下的那个子集作为测试集。
- 这样就可获得k组训练/测试集,从而可进行k 次训练和测试,最终返回的是这k 个测试结果的均值。
- 为减小因样本划分不同而引入的差别,k 折交叉验证通常要随机使用不同的划分重复p 次,最终的评估结果是这p 次k 折交叉验证结果的均值,例如常见的有“ 10次10折交叉验证”.
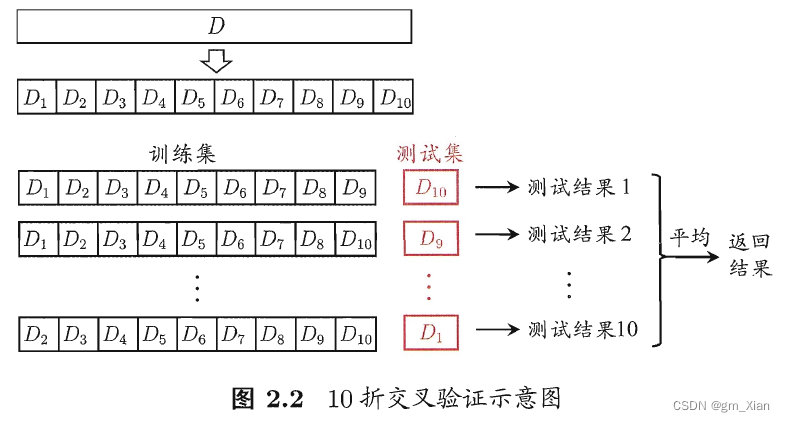
- 显然,交叉验证法评估结果的稳定性和保真性在很大程度上取决于k的取值。
3.3 留一法(交叉验证法的特例,Leave-One-Out,简称LOO)
- 假定数据集D 中包含m 个样本,若令k = m,则得到了交叉验证法的一个特例:
- 留一法不受随机样本划分方式的影响,因为m个样本只有唯一的方式划分为m个子集,每个子集包含一个样本。
- 留一法使用的训练集与初始数据集相比只少了一个样本,这就使得在绝大多数情况下,留一法中被实际评估的模型与期望评估的用D 训练出的模型很相似。因此,留一法的评估结果往往被认为比较准确.
- 缺陷:数据集很大时,开销很大。
- 在做脑电信号分析的时候(比如运动想象信号分类)用到的比较多,可以增加算法的可信度。
3.4 自助法(bootstrapping)
- 方法简述:给定包含 m 个样本的数据集D,我们对它进行采样产生数据集,每次随机从D中挑选一个样本,将其拷贝放入D’ ,然后再将该样本放回初始数据集D 中,使得该样本在下次采样时仍有可能被采到;这个过程重复执行m 次后,我们就得到了包含m个样本的数据集D’ , 这就是自助采样的结果。
- D中总有一部分样本会在D’中多次出现,而另一部分样本不出现(大约36.8%)
- 好处:自助法在数据集较小、难以有效划分训练/测试集时很有用;此外,自助法能从初始数据集中产生多个不同的训练集,这对集成学习等方法有很大的好处。
- 缺陷:自助法产生的数据集改变了初始数据集的分布,这会引入估计偏差.在初始数据量足够时,留出法和交叉验证法更常用一些。
参考文献:
[1]周志华.机器学习 [M].清华大学出版社, 2016.















 1608
1608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









